
倒排索引概念
举例子:
Java is the best programming language.
PHP is the best programming language.
Javascript is the best programming language.
为了创建倒排索引,我们通过分词器将每个文档的内容域拆分成单独的词(我们称它为词条或 Term),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。

这种结构由文档中所有不重复词的列表构成,对于其中每个词都有一个文档列表与之关联。这种由属性值来确定记录的位置的结构就是倒排索引。带有倒排索引的文件我们称为倒排文件。
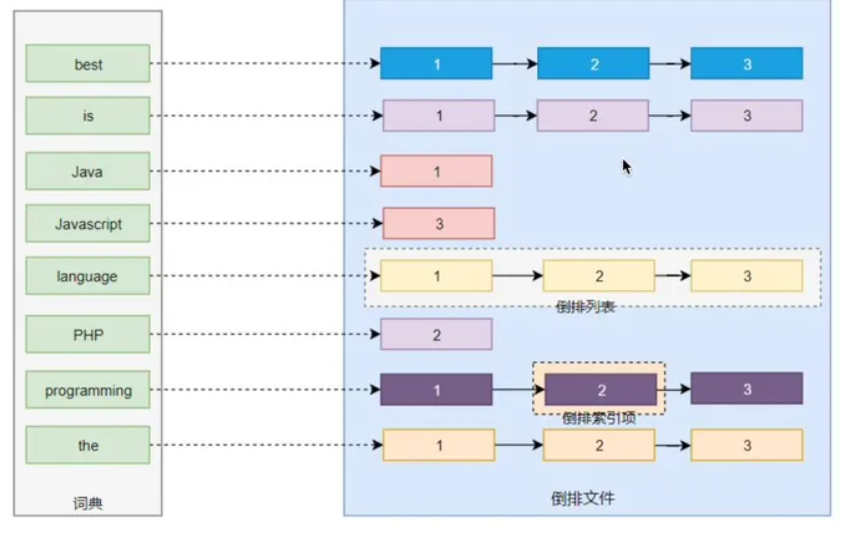
词条(Term): 索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
词典(Term Dictionary): 或字典,是词条 Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排表(Post list): 一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置。每条记录称为一个倒排项(Posting)。倒排表记录的不单是文档编号,还存储了词频等信息。
倒排文件(Inverted File): 所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
倒排索引主要由两个部分组成:
- 词典
- 倒排文件
词典和倒排表是 Lucene 中很重要的两种数据结构,是实现快速检索的重要基石。词典和倒排文件是分两部分存储的,词典在内存中而倒排文件存储在磁盘上。
不管是 Solr 还是 Elasticsearch 底层都是依赖于 Lucene,而 Lucene 能实现全文搜索主要是因为它实现了倒排索引的查询结构。
倒排索引的底层实现是基于: FST( Finite State Transducer) 数据结构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号