浏览器渲染原理
浏览器渲染原理
浏览器渲染原理
-
第一步:URL 地址解析。
-
第二步:缓存检查
- 通过一个 url 网址,首先得到的是一个 html。渲染过程中,遇到 link 标签向服务器发送拿到 css 代码,遇到 script 标签向服务器发送拿到 js 代码,遇到 img 标签向服务器发送拿到图片文件。
- 如果浏览器上有对应的路径文件的缓存,就直接拿,而不发送请求到服务器去拿。
- 针对静态资源文件:强缓存和协商缓存。
- 不论是强缓存还是协商缓存,都是由服务器进行设置,浏览器自动配合完成相应的缓存机制!
- 针对
ajax数据:本地存储。- 基于
ajax/fetch()从服务器获取的数据,不能设置强缓存和协商缓存,如果需要对不经常更新的数据进行缓存,需要开发者基于本地存储进行处理!- 最好的数据缓存方案是:
vuex/redux:既可以避免频繁向服务器发送请求。也可以保证在用户刷新后,可以及时从服务器获取到最新的信息。 - 但是对于
一些不经常更新的数据,基于localStorage来存储-即自己设定时效性,也是不错的选择!
- 最好的数据缓存方案是:
- 基于
- 通过一个 url 网址,首先得到的是一个 html。渲染过程中,遇到 link 标签向服务器发送拿到 css 代码,遇到 script 标签向服务器发送拿到 js 代码,遇到 img 标签向服务器发送拿到图片文件。
-
第三步:DNS 解析
- 所谓 DNS 解析,就是去
DNS服务器上基于域名获取服务器的外网IP地址-即主机地址。 DNS解析也是有缓存机制的:- 比如谷歌浏览器记录
DNS解析的缓存时间,大概是 1 分钟左右。
- 比如谷歌浏览器记录
- DNS 解析步骤:
- 基于
递归查询在本地缓存中查找DNS解析记录。 - 基于
迭代查询到DNS服务器上查找DNS解析记录。
- 基于
- 单纯这样看,减少
DNS的解析次数,会提高页面的加载速度!- 想要减少
DNS的解析次数,需要把所有的资源部署在相同服务器的相同服务下! - 在 DNS 解析次数增加的情况下,我们可以基于
dns-prefetch即DNS预解析,来提高网站的加载速度!<link rel="dns-prefetch" href="//dss0.bdstatic.com" />
- 想要减少
- 所谓 DNS 解析,就是去
-
第四步:TCP 三次握手
- 目的:根据
DNS解析出来的服务器主机地址,建立起和服务器之间的传输通道。 - 三次握手为什么不用两次,或者四次?
- TCP 作为一种可靠传输控制协议,其核心思想:既要保证数据可靠传输,又要提高传输的效率!
- 目的:根据
-
第五步:客户端和服务器之间的数据通信。
-
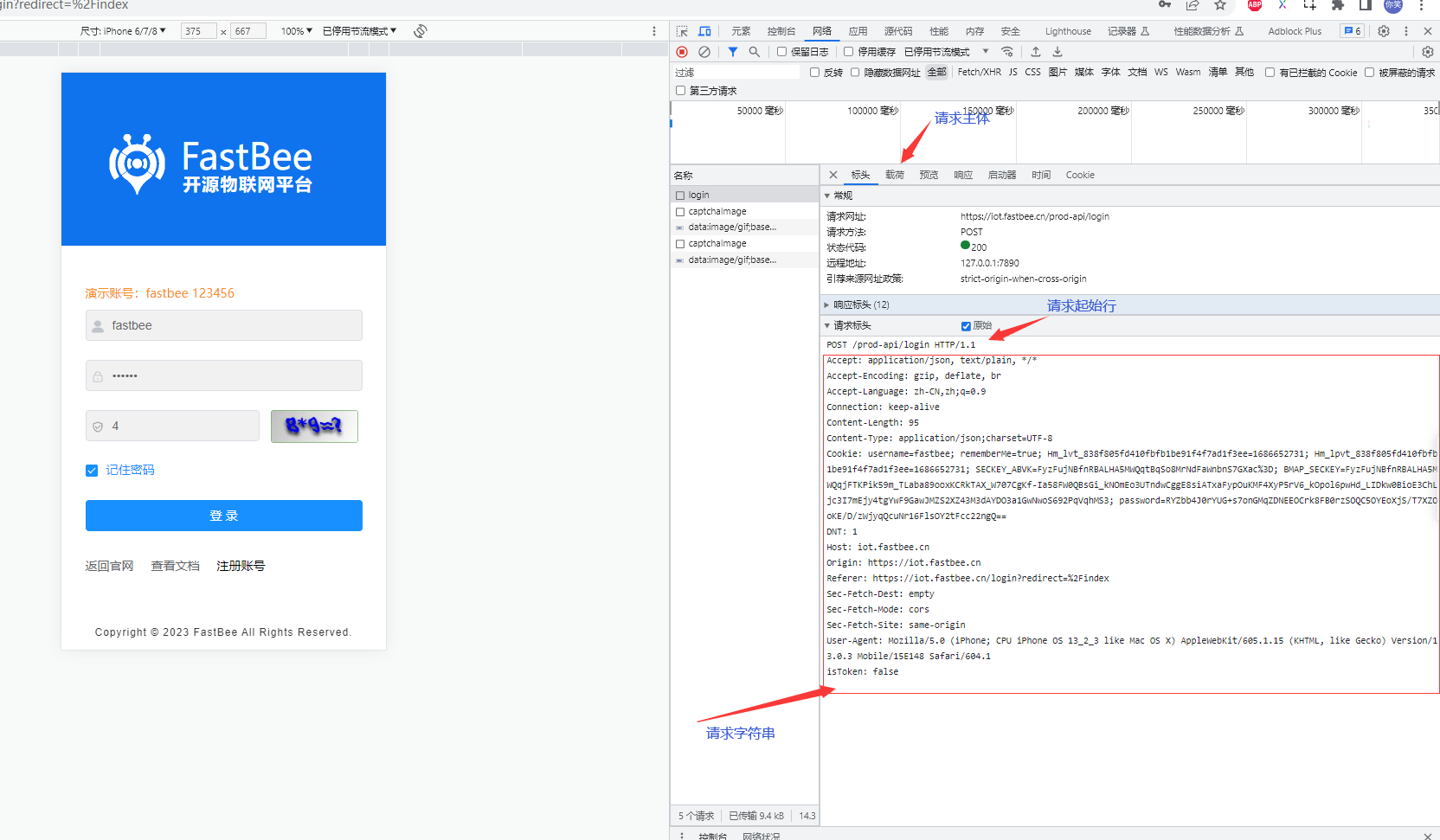
客户端向服务器发送请求,把一些信息传递给服务器。即
Request请求阶段。包含客户端信息的组成部分:- 请求起始行:
请求方式、请求地址(包括问号传参信息)、HTTP 协议的版本。 - 请求头:也叫
请求首部,各种各样的键值对如token、Content-Type、Cookie、User-Agent、Authorization...。 - 请求主体(
Request Payload):请求主体中的数据格式是有限制的。
- 请求起始行:
-
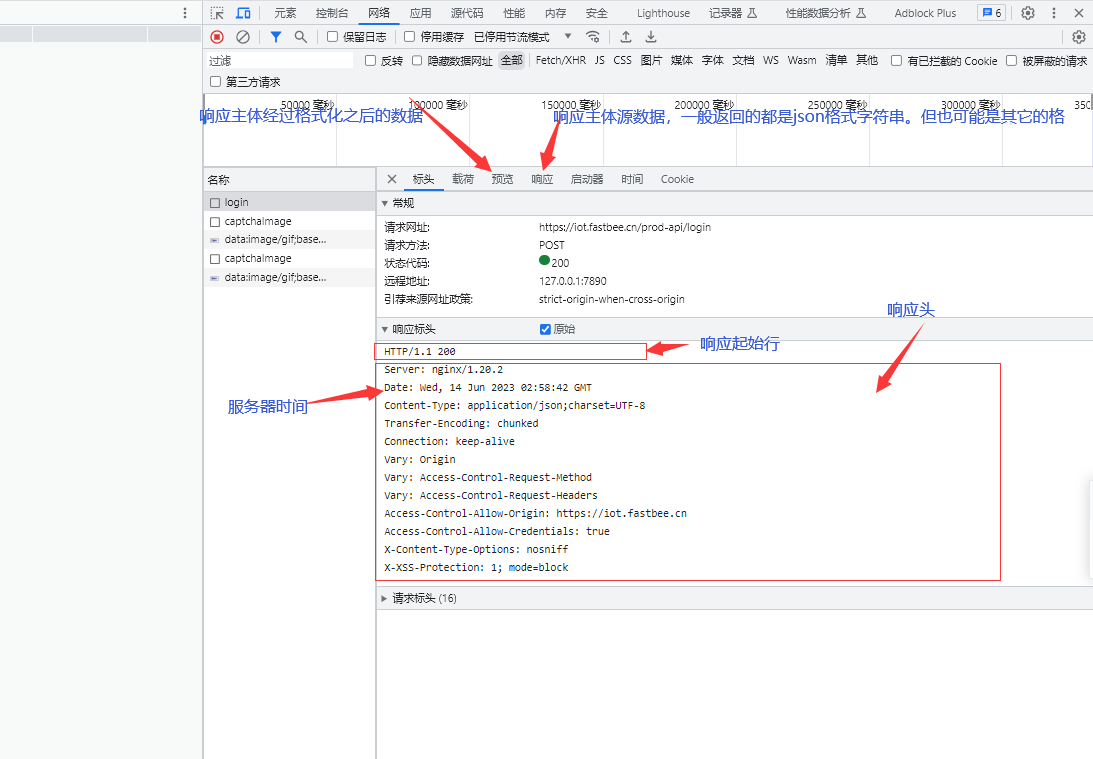
服务器接收客户端的请求,把客户端需要的信息返回给客户端。即Response响应阶段。包含服务器信息的组成部分:- 响应起始行:
HTTP协议的版本、HTTP响应状态码 - 响应头:
Connection: keep-alive、Date-服务器时间... - 响应主体:一般返回的都是
JSON格式字符串,但也有可能是其它的格式
- 响应起始行:
-
-
第六步:TCP 四次挥手
- 目的:把
建立好的传输通道释放掉。
- 目的:把
-
第七步:客户端渲染
-
浏览器把服务器返回的信息(包括html/css/js/图片/数据等)进行渲染,最后绘制出对应的页面! -
步骤:
-
构建
DOM-Tree即DOM树。-
当从
服务器获取HTML页面后,浏览器会分配GUI渲染线程。自上而下进行解析。- 遇到
<link>标签:分配一个新的HTTP网络线程去服务器获取样式资源,同时GUI继续向下渲染!- 不会阻碍
GUI的渲染。
- 不会阻碍
- 遇到
<style>标签:虽然不需要去服务器获取样式,但是此时的样式是不渲染的,只有等待DOM-Tree构建完毕后,并且其余基于<link>标签获取的样式也回来了,才会按照原定的顺序(编写的顺序)进行渲染!- 为了保证样式的权重和先后顺序的覆盖。
- 遇到
@import:也会分配一个 HTTP 线程去服务器获取样式资源,只不过其会阻碍 GUI 的渲染。- 只有
等待样式资源获取完毕后,GUI才会继续向下渲染!
- 只有
- 遇到
<img>标签/<audio>标签/<video>标签:和<link>标签一致。分配一个新的HTTP网络线程去服务器获取样式资源,同时GUI继续向下渲染!- 但是对于
<audio>标签/<video>标签音视频来讲,如果设置了preload="none"属性,则开始渲染页面的时候并不会去服务器获取音视频资源。
- 但是对于
- 遇到
<script>...</script>:立即把js代码执行。- 交给
js引擎线程渲染,但是GUI会暂停,也相当于阻碍了GUI渲染。
- 交给
- 遇到
<script src="">标签:阻碍GUI渲染,分配一个新的HTTP线程去服务器获取js资源,等待js代码获取到之后,交由js引擎去渲染,只有js代码执行完毕,才会继续GUI的渲染! - 遇到
<script src="" async>标签:分配一个新的HTTP线程去服务器获取js资源,此时GUI会继续渲染。但是等到js代码获取到之后,会立即停止GUI的渲染,先把js代码执行! - 遇到
<script src="" defer>标签:和<link>标签一致。会分配一个新的HTTP线程去服务器获取js资源,GUI会继续向下渲染。等待DOM-Tree渲染完毕,并且其它设置defer的js资源也获取到了,再按照编写的顺序,依次执行js代码!
- 遇到
-
当
把所有的HTML结构解析完毕后,会构建出DOM元素之间的层级关系,这就是DOM树。 -
在
DOM树构建完毕后,会触发一个事件:DOMContentLoaded。window.addEventListener(`DOMContentLoaded`, function () { //此函数中,一定可以获取到页面中已经渲染出来的DOM元素。 //... });DOMContentLoaded只能用DOM2级事件进行绑定。
-
-
构建
CSSOM-Tree即样式树。- 等待
样式资源从服务器获取到之后,会按照既定的顺序,开始渲染css样式,最后生成CSSOM-Tree! css样式被称之为层叠样式表,就是因为其具备:层级、权重、继承的特点。
- 等待
-
把
DOM-Tree与CSSOM-Tree合并在一直,创建Render-Tree即渲染树。渲染树中,已经非常清楚地知道了:DOM元素的层级和每一个元素的样式。
-
Layout即布局排列计算-对应回流/重排-Reflow。- 根据
当前视口的大小,计算元素在视口的位置,以及相关的样式!- 根据生成的渲染树,计算它们在
设备视口viewport内的确切位置和大小,这个计算的阶段就是回流;
- 根据生成的渲染树,计算它们在
- 根据
-
分层。
- 在一个页面中,不仅仅只有一层,它是一个
3D空间,会存在很多层。这就是所谓的脱离文档流。 - 而
分层的目的就是:把每一层及每一层中的元素样式都详细地规划好,包括具体的绘制步骤。
- 在一个页面中,不仅仅只有一层,它是一个
-
Painting绘制-对应重绘Repainting。- 根据渲染树以及回流得到的几何信息,得到节点的绝对像素 -> 绘制;
- 开始
一层层地按照规划好的步骤进行绘制,直到整个页面都被绘制完毕!
-
-

从输入 URL 地址到看到页面的步骤
-
从输入 URL 地址到看到页面,中间都经历了啥
-
第一步:URL 地址解析。
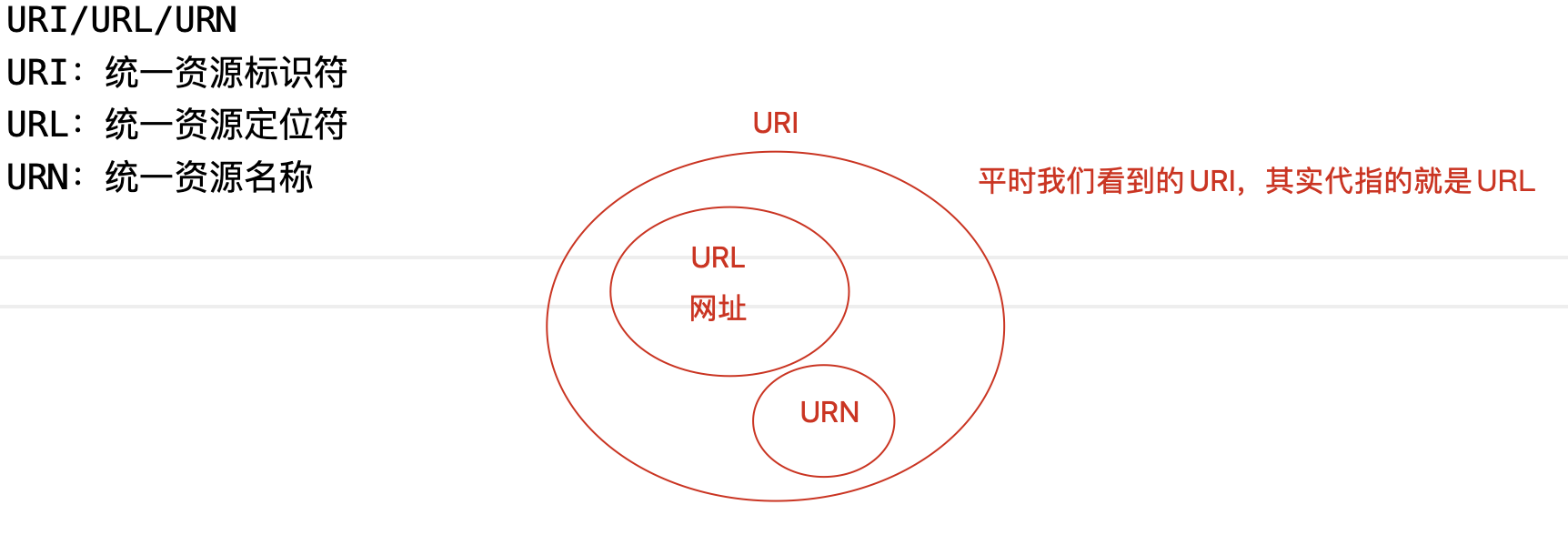
http://www.xxx.com:80/index.html?lx=1&from=weixin#video- URI/URL/URN
- URI: 统一资源标识符。
- URL 与 URN 的统称。
- 平时我们看到的 URI,其实
网络路径的就是 URL。
- 平时我们看到的 URI,其实
- URL 与 URN 的统称。
- URL:统一资源定位符。
- 网址。
- URN:统一资源名称。
- 如图书编号。
- URI: 统一资源标识符。
- 解析信息:
- 传输协议:
- 作用:负责客户端和服务器端之间信息的传输(可以理解为快递小哥)。
- 分类:
http:即HyperText Transfer Protocol,超文本传输协议。- 除传输文本内容外,还可传输图片和音视频等。
https:即Hypertext Transfer Protocol Secure,HTTP+SSL,更安全的传输协议,经过加密处理。ftp:即File Transfer Protocol,文件传输协议,主要用于往服务器上上传内容和下载内容。
- 域名:
- 端口号
- 作用:区分相同服务器上部署的不同项目的,取值范围
0~65535之间。- 浏览器有默认端口号机制:我们在地址栏中输入 URL 地址,如果没有写端口号,则浏览器会根据当前的传输协议,自动把端口号加上!
- http -> 80
- https -> 443
- ftp -> 21
- 作用:区分相同服务器上部署的不同项目的,取值范围
- 请求资源的路径名称。
- 问号传参信息
- 哈希值
- Hash 值。
- 传输协议:
-
第二步:缓存检查
-
通过一个 url 网址,首先得到的是一个 html。渲染过程中,遇到 link 标签向服务器发送拿到 css 代码,遇到 script 标签向服务器发送拿到 js 代码,遇到 img 标签向服务器发送拿到图片文件。
- 如果浏览器上有对应的路径文件的缓存,就直接拿,而不发送请求到服务器去拿。
-
针对静态资源文件:强缓存和协商缓存。
- 例如:html、css、js、图片、音频、视频...
-
缓存存储的位置:
- 虚拟内存(Memory Cache):存储全局变量、
- 如内存条、显卡内存、CPU 内存。
- 物理内存(Disk Cache):
- 硬盘:固态硬盘与机械硬盘。
- 一般情况下,物理内存与虚拟内存都存一份。
- 虚拟内存(Memory Cache):存储全局变量、
-
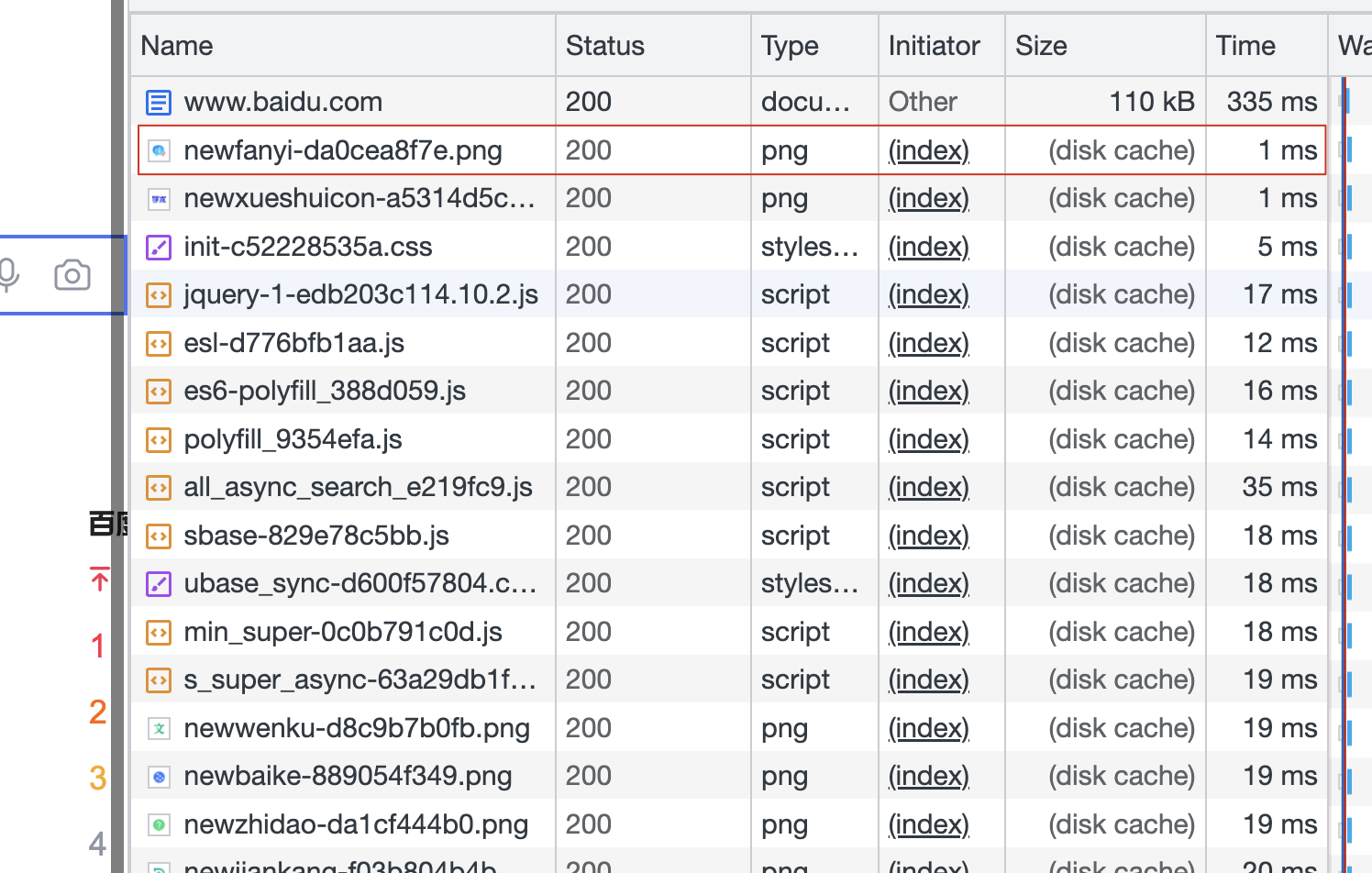
浏览器读取缓存的思路:
- 正常刷新页面:先从虚拟内存中获取,如果不存在,再去物理内存中查找。
- 关闭页面重新打开:直接去物理内存中查找。
- 强制刷新页面(ctrl+F5):直接去服务器获取最新的。
-
读取缓存的速度:
- 虚拟内存中读取:速度一般在 0ms。
- 物理内存中读取:速度较快,一般在 10ms 以外。
- 服务器中读取:速度最慢,在 20ms-1000ms 左右。
-
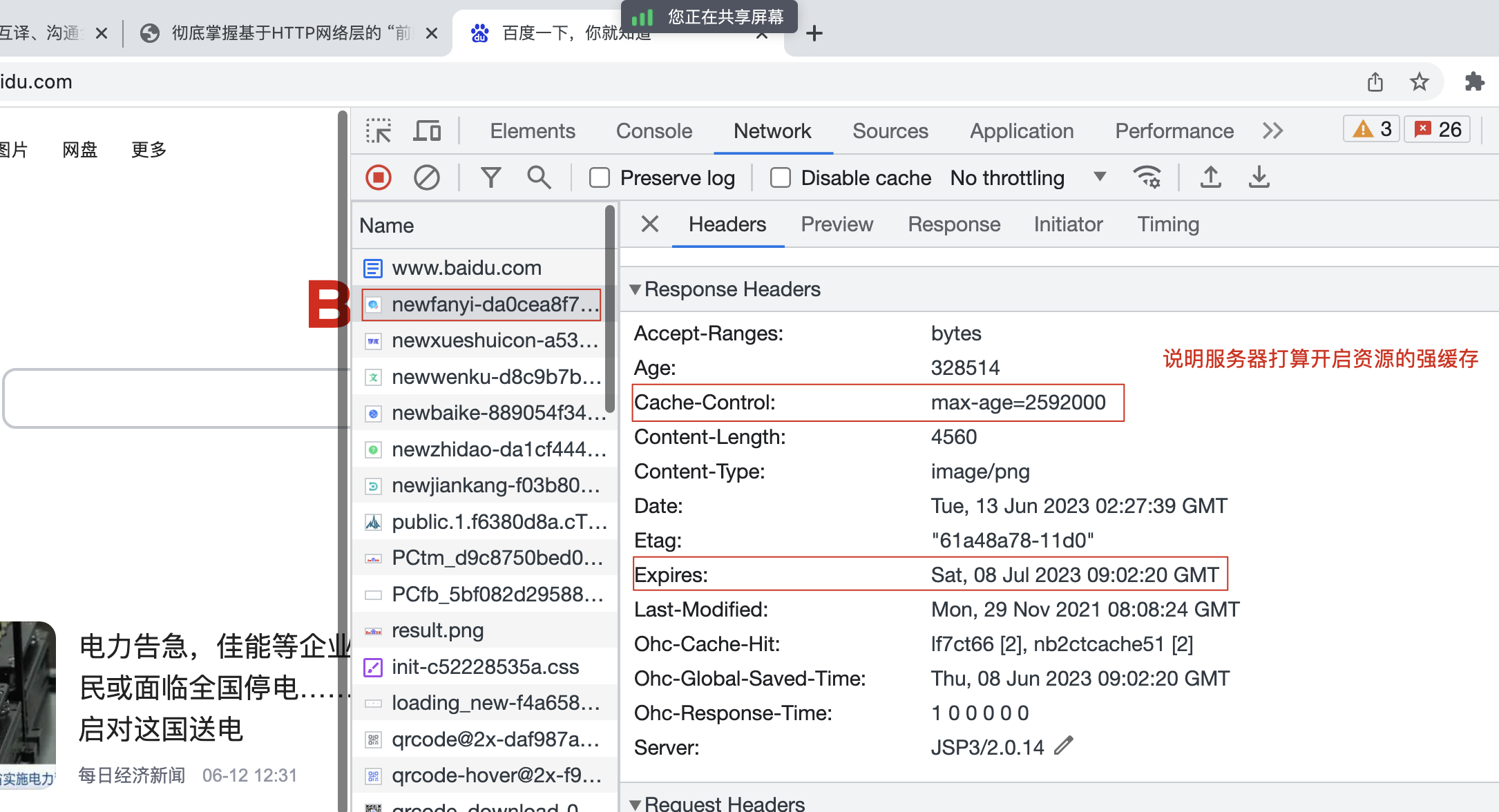
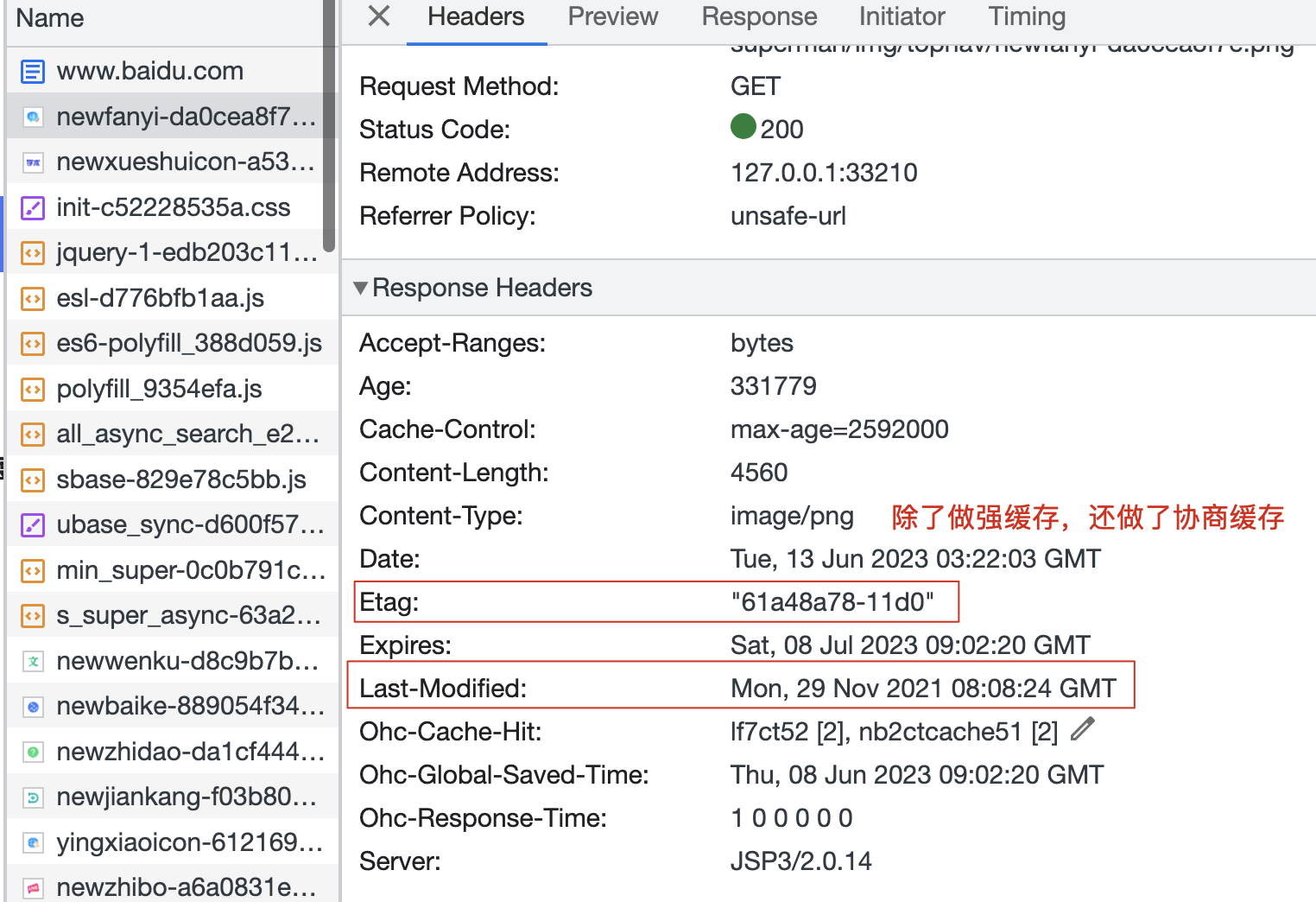
不论是强缓存还是协商缓存,都是由服务器进行设置,浏览器自动配合完成相应的缓存机制!
-
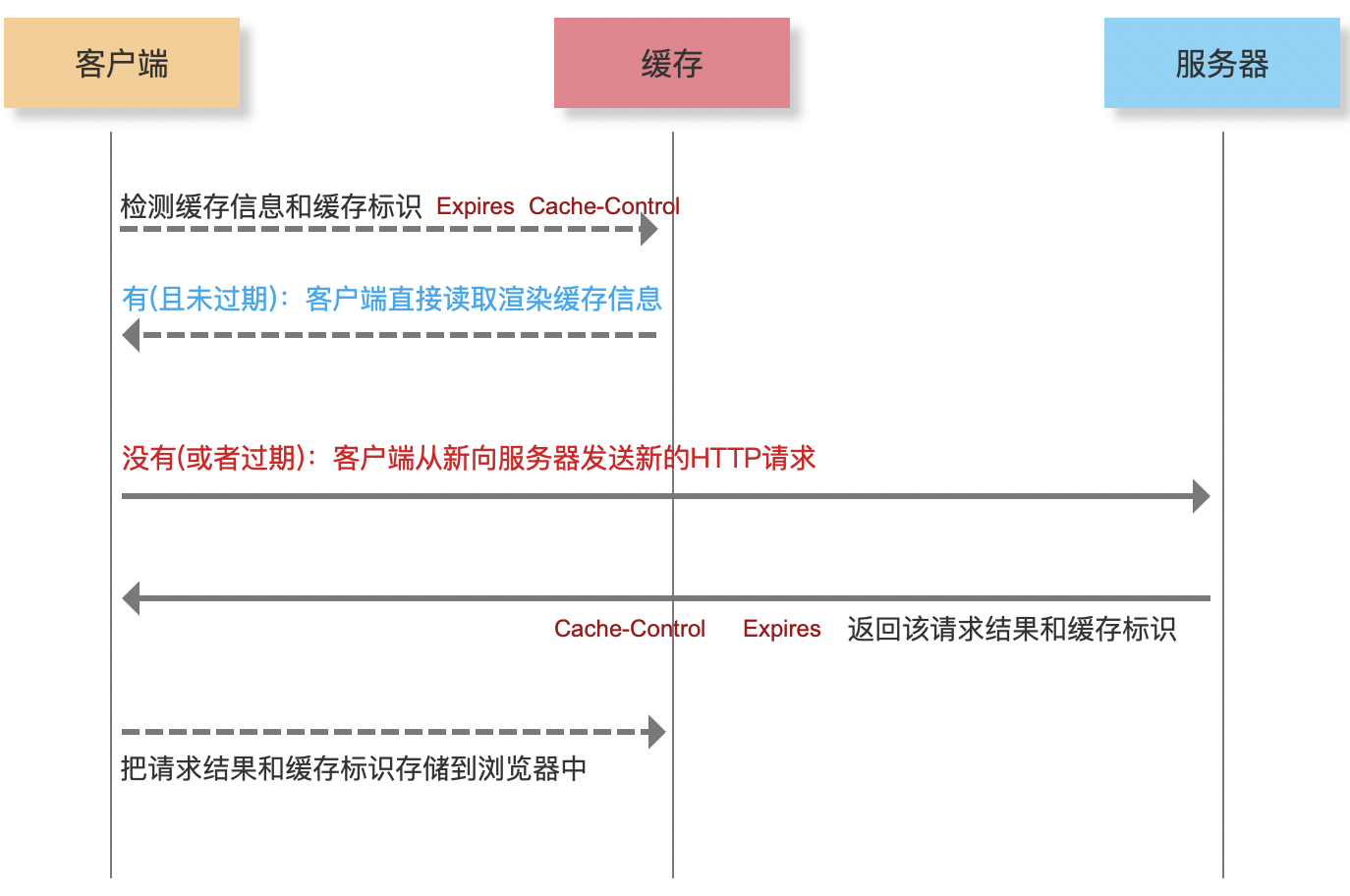
强缓存:
- 第一次访问网站,本地没有任何的缓存,需要向服务器发送请求;
- 服务器在返回相应资源信息的时候,如果想开启强缓存机制。
- 会在响应头中设置相关的字段:
Expires: 存储缓存过期的具体时间。这个是http/1.0版本的协议中需要设置的字段。Cache-Control: 存储过多久缓存将过期(单位:秒)或者其它信息。这个是http/1.1版本的协议中需要设置的字段。
- 后台一般这两个字段都返回。至少要设置一个,根据那个版本来做。如果两个都返回,浏览器两个都支持会以最新的
Cache-Control来设置。
- 会在响应头中设置相关的字段:
- 服务器在返回相应资源信息的时候,如果想开启强缓存机制。
- 当浏览器获取到服务器返回的资源信息,除了正常的渲染以外,还会去看响应头中是否有强缓存标识,即
Expires与Cache-Control字段。- 如果没有则啥都不处理。
- 如果有,则把本次获取的资源信息和这两个响应头信息,缓存在客户端本地!在虚拟内存和物理内存中都存储一份。
第二次及以后访问这个网站,首先看本地是否有具备在效期的缓存信息。没有具备/缓存过期了:重新向服务器发送请求,来获取最新的资源。- 有:则直接渲染缓存中的信息,无需再向服务器发送请求了。
-
强缓存的几个特点:
- 可以不和服务器通信,直接就能拿到资源文件了。
- 导致可能和服务器失联,用的都是第一次缓存的文件。
- 想拿到服务器上最新的资源文件:需要 html 不做强缓存,及用 webpack 打包文件时,给文件名加上根据内容所生成的 hash 值。
- 不论从
服务器还是缓存中获取,只要可以拿到,HTTP状态码都是200。 html页面千万不要做强缓存,以此来保证,即便本地有生效的缓存,但是只要服务器资源更新了,也要从服务器实时获取最新的资源进行渲染!- html 文件不做缓存,但 js 及 css 及图片等要做。
- 我们平时开发的时候,需要基于
webpack/vite等前端工具,对代码进行编译打包,把编译后的内容部署到服务器上!- 在
webpack编译的时候,我们可以设置一个规则:根据文件的内容,让生成的文件名带唯一hash值。- 例如:
main.sae3fd9jk.js。 - 在输入文件名称中加一个
[name].[hash:8].js。
- 这样只要
代码修改了,每次打包都会创建不同的文件出来,而html页面中导入的也是最新的文件!
- 例如:
- 这样只要 html 不做
强缓存,就可以保证,服务器资源一旦更新,我们获取的是最新资源,而不是本地缓存! 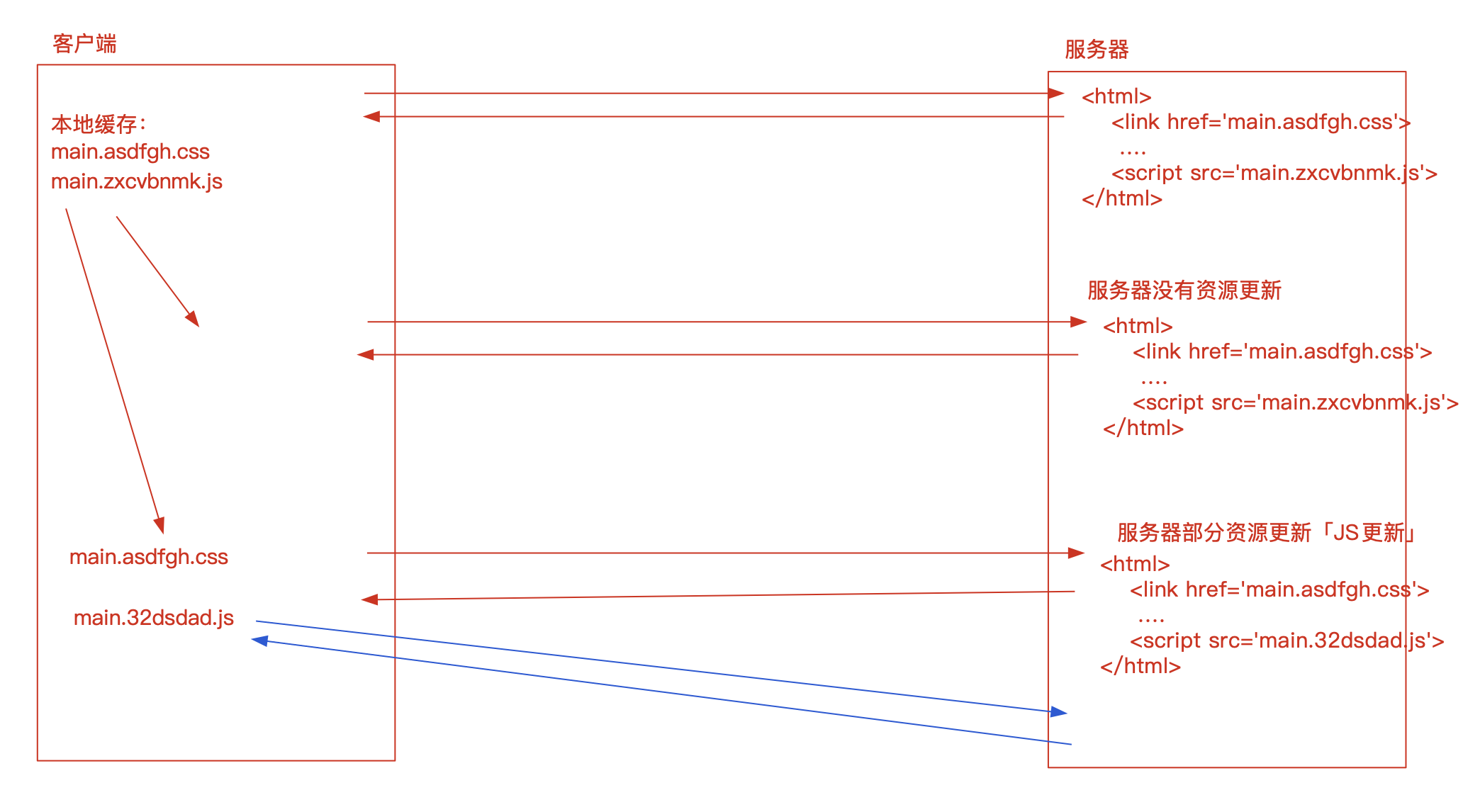
- 在
-
- 第一次访问网站,本地没有任何的缓存,需要向服务器发送请求;
-
协商缓存:- 该做通信还是要做的,只不过可能要返回的数据变少了。
- 不用做处理,都能保证浏览器渲染的资源是服务器上最新的。
协商缓存是强缓存的一种补充。- 如果
强缓存还在有效期,即便服务器设置了协商缓存,那么协商缓存的机制也不会触发。 - 只有
没有设置强缓存或者强缓存失效了,设置的协商缓存机制才会生效!
- 如果
- 步骤:
-
第一次访问网站,本地啥缓存都没有,需要从服务器获取。
- 如果
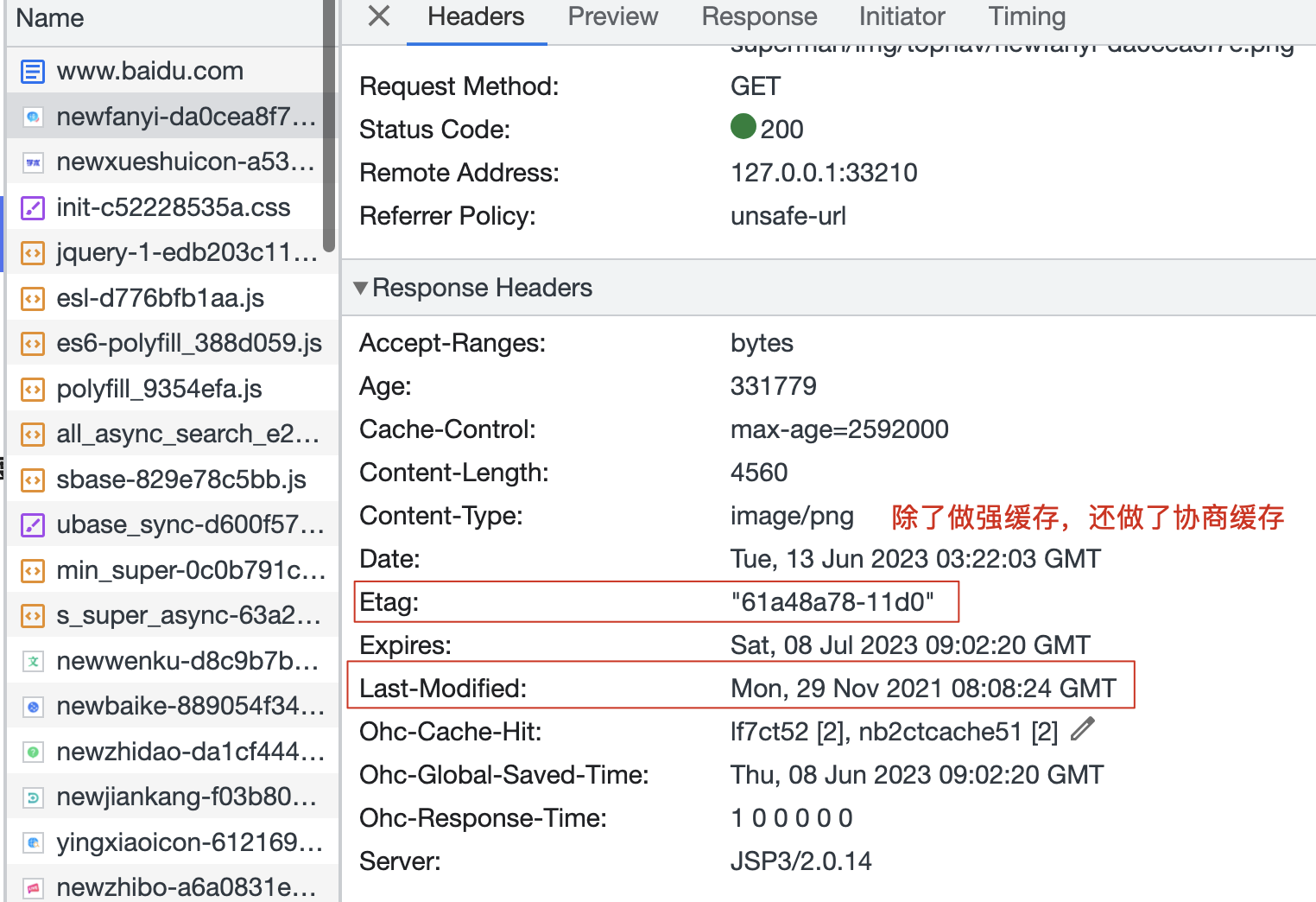
服务器想对当前的资源设置协商缓存,则在响应头中返回或设置相关的字段:Last-Modified:存储该资源在服务器最后一次修改的时间,HTTP/1.0。ETag:存储该资源在服务器中最后一次修改的唯一的标识,HTTP/1.1。
- 如果
-
浏览器获取资源信息的同时,观察响应头信息,如果具备这两个字段,则把资源和标识都缓存在本地!
-
第二次访问网站,不论本地缓存是否生效。
- 前提是:强缓存肯定是没有或者失效了!
-
都需要
重新向服务器发送请求。并且在请求头中携带两个字段:If-Modified-Since:存储的值是Last-Modified的值。If-None-Match:存储的值是ETag的值。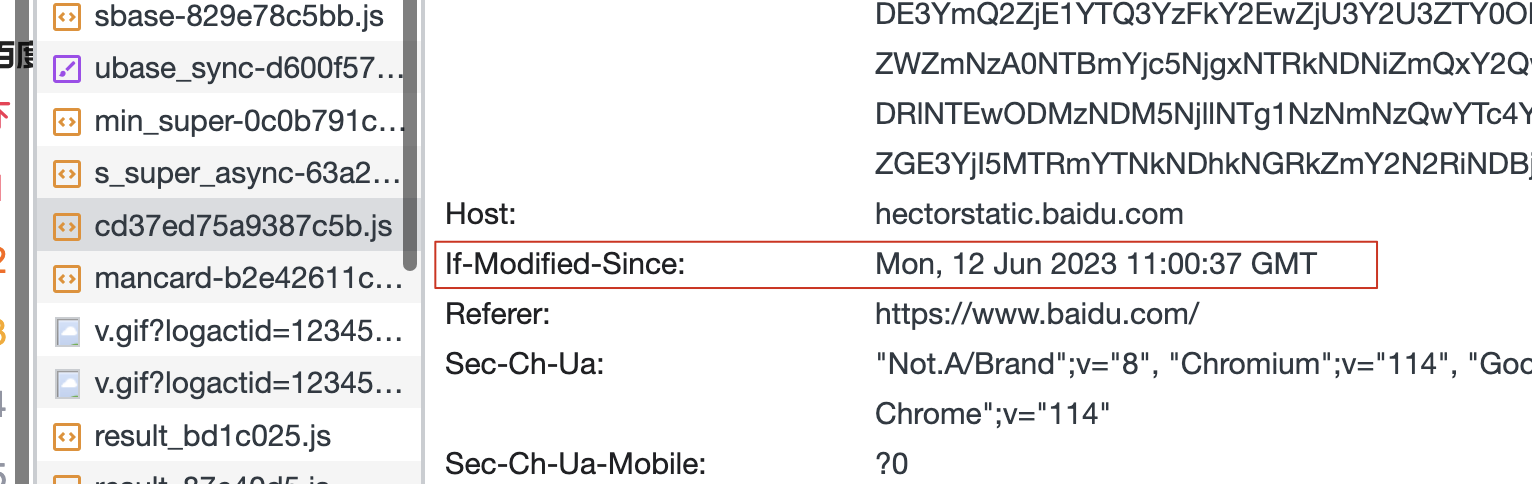
-
服务器接收
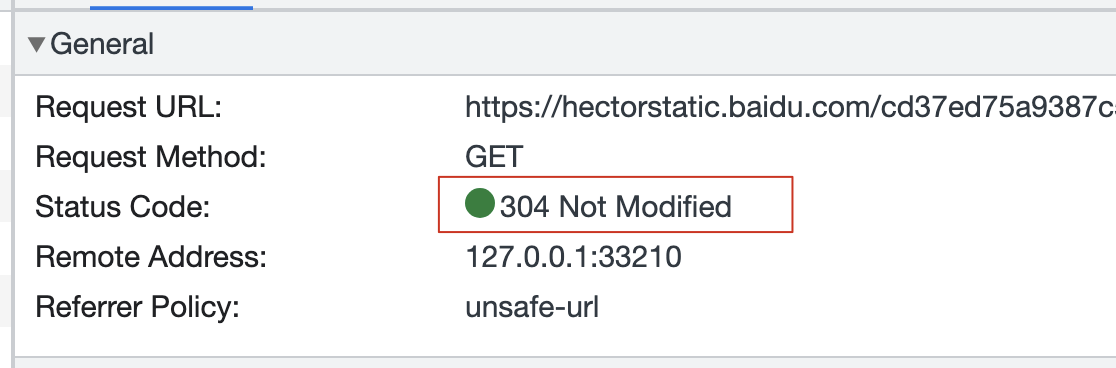
传递的信息及标识,用If-Modified-Since/If-None-Match和当前服务器上最新的资源进行对比。-
对比后是一样的:说明服务器上的这个资源没有更改过,则服务器直接返回304-即Not-Modified,浏览器接收到这个304状态码,则从本地缓存中获取资源信息进行渲染。 -
对比后是不一样的:说明服务器上的这个资源更改过,此时服务器返回状态码200、最新的资源信息、最新的Last-Modified值/最新的ETag值!浏览器获取最新的信息后,除了渲染,再把最新的信息和最新的标识缓存在本地!
-
-

-
建议:html 不设置强缓存,只设置协商缓存。其它资源如 js、css、图片等都设置强缓存及协商缓存。
-
-
针对
ajax数据:本地存储。-
基于
ajax/fetch()从服务器获取的数据,不能设置强缓存和协商缓存,如果需要对不经常更新的数据进行缓存,需要开发者基于本地存储进行处理!-
最好的数据缓存方案是:
vuex/redux;- 既可以避免
频繁向服务器发送请求。也可以保证在用户刷新后,可以及时从服务器获取到最新的信息。
- 既可以避免
-
但是对于
一些不经常更新的数据,基于localStorage来存储-即自己设定时效性,也是不错的选择!-
实现具备有效期的 localStorage 存储方案:
/* //实现具备有效期的localStorage存储方案; - localStorage.setItem()/localStorage.getItem()/localStorage.removeItem(); - 设置的值,都只能是字符串格式的; */ const storage = { // 存储信息的时候,记录一下存储的时间。 /** * @param {string} key * @param {any} value */ set(key, value) { let obj = { time: +new Date(), //存储时,当前日期的时间戳。 value: value, }; localStorage.setItem(key, JSON.stringify(obj)); }, // 获取存储信息的时候,判断一下时效性。 /** * @param {string} key */ get(key, expires = 30 * 24 * 60 * 60 * 1000) { let obj = localStorage.getItem(key); if (!obj) { return null; //传递的key压根不存在。 } let { time, value } = JSON.parse(obj); if (+new Date() - time > expires) { // 存储的信息已经地了指定的时效:移除存储的信息、返回null。 storage.remove(key); return null; } return value; }, // 移除指定信息。 /** * @param {string} key */ remove(key) { localStorage.removeItem(key); }, }; -
无缓存方案:
//无缓存方案: const query = async function query() { try { let result = await axios.get("/api/list", { params: { lx: "my", }, }); console.log(`result-->`, result); } catch (error) { console.log(`error-->`, error); } }; query(); -
有缓存方案-本地存储:
/* //实现具备有效期的localStorage存储方案; - localStorage.setItem()/localStorage.getItem()/localStorage.removeItem(); - 设置的值,都只能是字符串格式的; */ const storage = { // 存储信息的时候,记录一下存储的时间。 /** * @param {string} key * @param {any} value */ set(key, value) { let obj = { time: +new Date(), //存储时,当前日期的时间戳。 value: value, }; localStorage.setItem(key, JSON.stringify(obj)); }, // 获取存储信息的时候,判断一下时效性。 /** * @param {string} key */ get(key, expires = 30 * 24 * 60 * 60 * 1000) { let obj = localStorage.getItem(key); if (!obj) { return null; //传递的key压根不存在。 } let { time, value } = JSON.parse(obj); if (+new Date() - time > expires) { // 存储的信息已经地了指定的时效:移除存储的信息、返回null。 storage.remove(key); return null; } return value; }, // 移除指定信息。 /** * @param {string} key */ remove(key) { localStorage.removeItem(key); }, }; //有缓存方案-本地存储: const query = async function query() { let result = storage.get("CACHE", 7 * 24 * 60 * 60 * 1000); if (result) { //本地是具备有效缓存的,则停止向服务器发送请求。 console.log(`result-->`, result); return; } // 数据没有缓存过:则向服务器发送请求。 try { let result = await axios.get("/api/list", { params: { lx: "my", }, }); console.log(`result-->`, result); // 请求成功就:把请求的结果存储到本地。 storage.set("CACHE", result); } catch (error) { console.log(`error-->`, error); } }; query();
-
-
-
-
-
第三步:DNS 解析
-
所谓 DNS 解析,就是去
DNS服务器上基于域名获取服务器的外网IP地址-即主机地址。 -
DNS解析也是有缓存机制的:- 比如谷歌浏览器记录
DNS解析的缓存时间,大概是 1 分钟左右。 - dns 缓存刷新时间是多久?dns 本地缓存时间介绍
- 比如谷歌浏览器记录
-
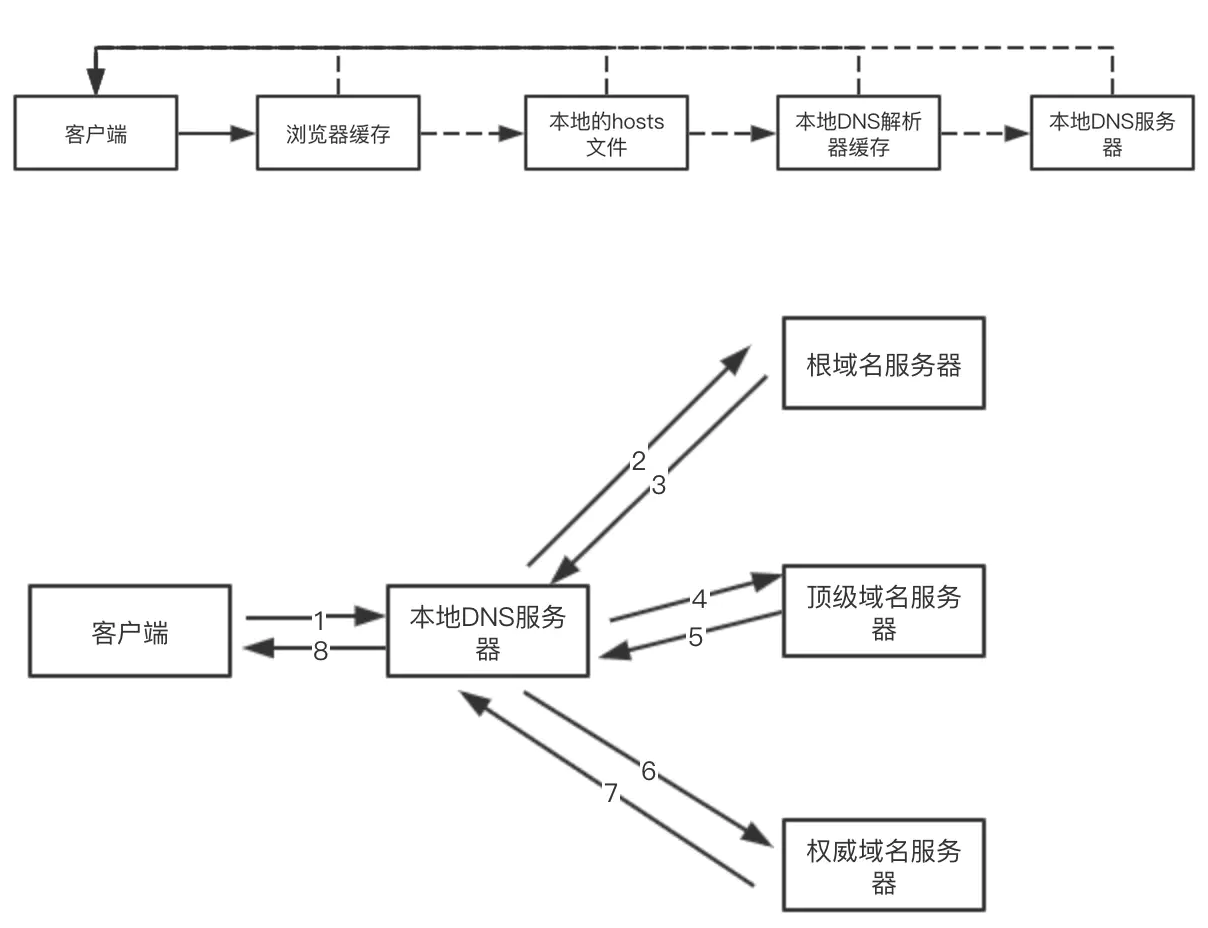
DNS 解析步骤:
-
基于
递归查询在本地缓存中查找DNS解析记录。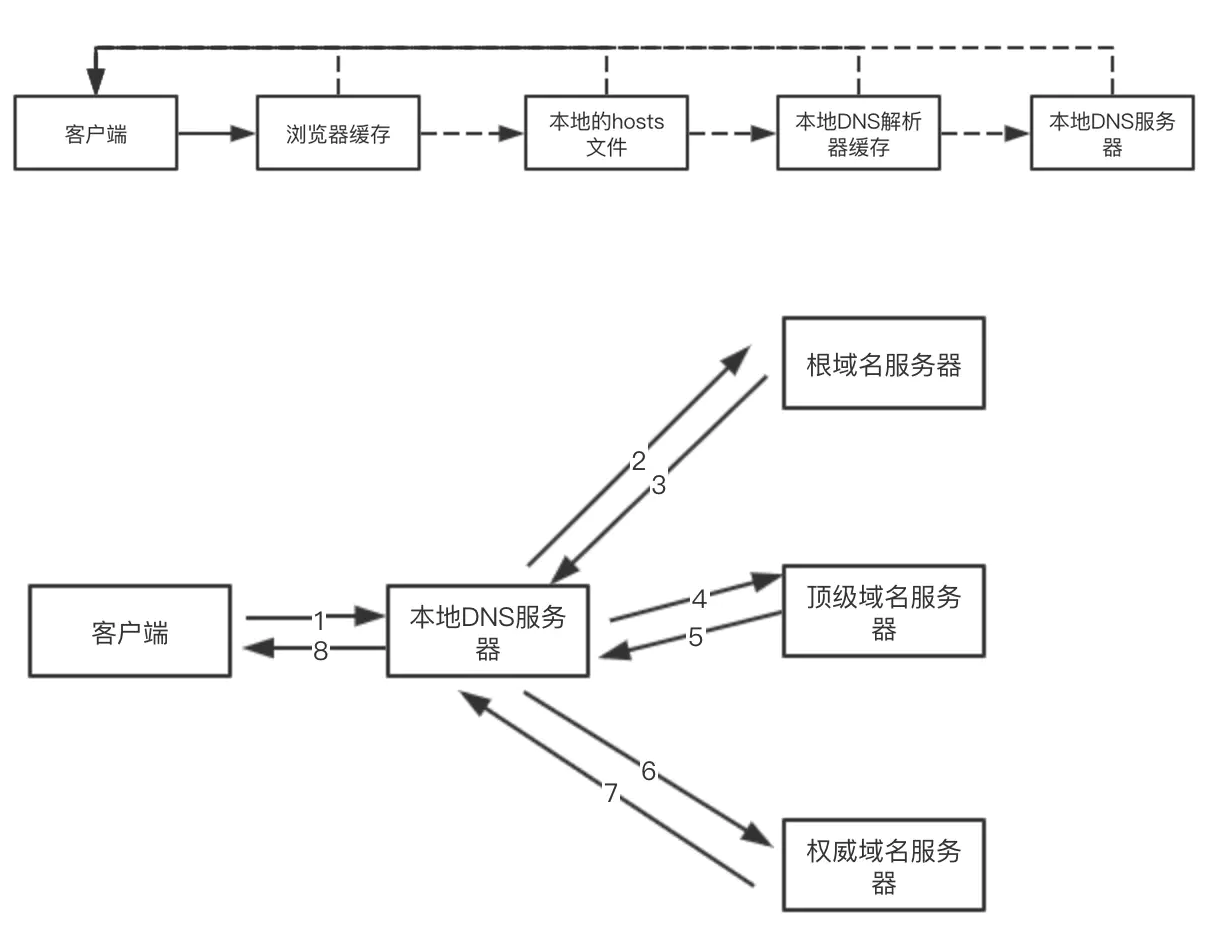
- 这个是找缓存的方式的。
- 浏览器的 DNS 解析缓存。
- 本地 Host 文件。
- 关于修改 host 文件:
- 假设个人在本地 host 中加一条记录:
www.qq.com 127.0.0.1 - 导致:以后只要在这台电脑上访问
www.qq.com,都相当于在访问127.0.0.1。 - 我在本地启动一个项目 ,假设
http://127.0.0.1:80/index.html为我开发的页面。 - 后期我基于
http://www.qq.com访问的也是本地的这个项目。
- 很久之前,也是基于这个方式来解决跨域问题的。
- 开发环境上才用的,部署到同源环境下。
- 假设个人在本地 host 中加一条记录:
- 关于修改 host 文件:
- 本地 DNS 解析器缓存。
- 本地 DNS 服务器。
-
基于
迭代查询到DNS服务器上查找DNS解析记录。- 根域名服务器。
- 顶级域名服务器。
- 权威域名服务器。
- 每一次 DNS 解析的时间,大概在 20~120 毫秒左右。
-
-
单纯这样看,减少
DNS的解析次数,会提高页面的加载速度!-
想要减少
DNS的解析次数,需要把所有的资源部署在相同服务器的相同服务下!- 比如 html 与 js 与 css 与图片等,都放在同一台服务器的同一个服务下。
- 这样一台服务器可以访问一个页面,就要十多个请求进该服务器了。
- 在线人数一多,该服务器的压力就比较大。服务器就可能有并发压力,比如一台服务器只能同时处理 2000 多个请求。
- 所以在
真实的项目中,我们往往要把不同的资源部署到不同的服务器上。- 例如:
- 静态资源服务器。
- 图片和音视频服务器。
- 数据请求服务器。
- ...
- 这样会导致网站中出现
多个域名请求,也就是需要多个DNS解析! - 这样做的好处:
- 资源的合理利用。
- 比如:
- 图片处理服务器:内存大的服务器。
网络需要带宽大。 - 数据处理服务器:要处理的压力比较大,CPU 要好。
- 图片处理服务器:内存大的服务器。
- 比如:
- 降低
单一服务器的压力,提高并发上限。 - ...
- 资源的合理利用。
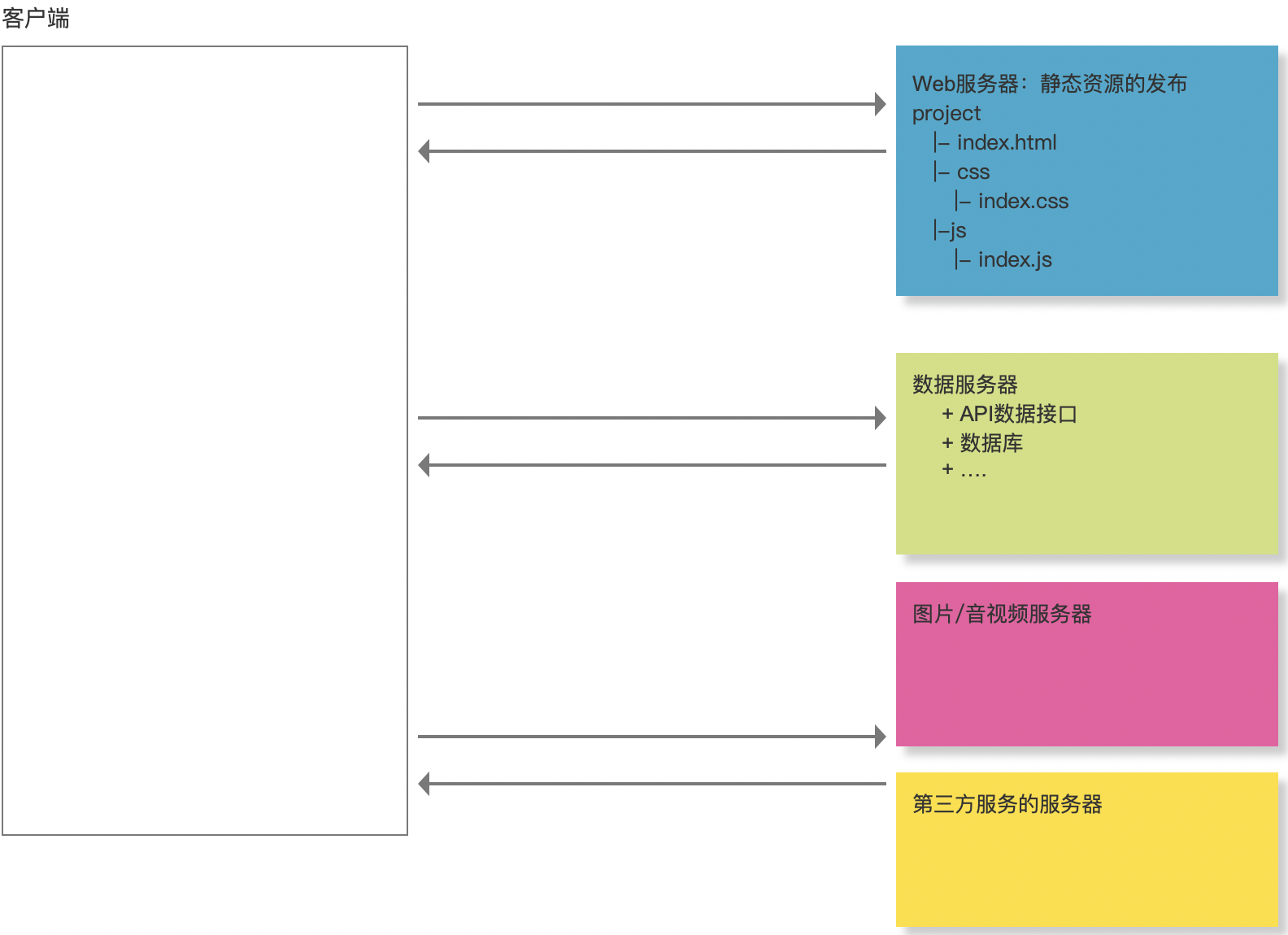
- 例如:
-
在 DNS 解析次数增加的情况下,我们可以基于
dns-prefetch即DNS预解析,来提高网站的加载速度!-
如:
<link rel="dns-prefetch" href="//dss0.bdstatic.com" /><link rel="dns-prefetch" href="//static.360buyimg.com" />- 浏览器解析时,看到
link标签,会分配一个线程去解析该link标签。拿到 DNS 地址。- 当渲染到 img 及 script 标签遇到那些域名时,就会使用之前所解析好的 DNS 地址去到指定 IP 地址去拿具体资源。
- 浏览器解析时,看到
-
-
...
-
DNS预解析的原理:- 就是利用
浏览器的多线程机制,在GUI渲染的同时,开辟新的线程去解析域名。解析的结果会缓存在浏览器中。
- 这样当
GUI渲染到一定的阶段,遇到新的资源请求的时候,可能域名已经解析过了,直接用缓存中存储的外网IP,去服务器发送请求即可,不用再去DNS服务器中解析找到IP地址了!
- 就是利用
-
-
-
第四步:TCP 三次握手
-
目的:根据
DNS解析出来的服务器主机地址,建立起和服务器之间的传输通道。-
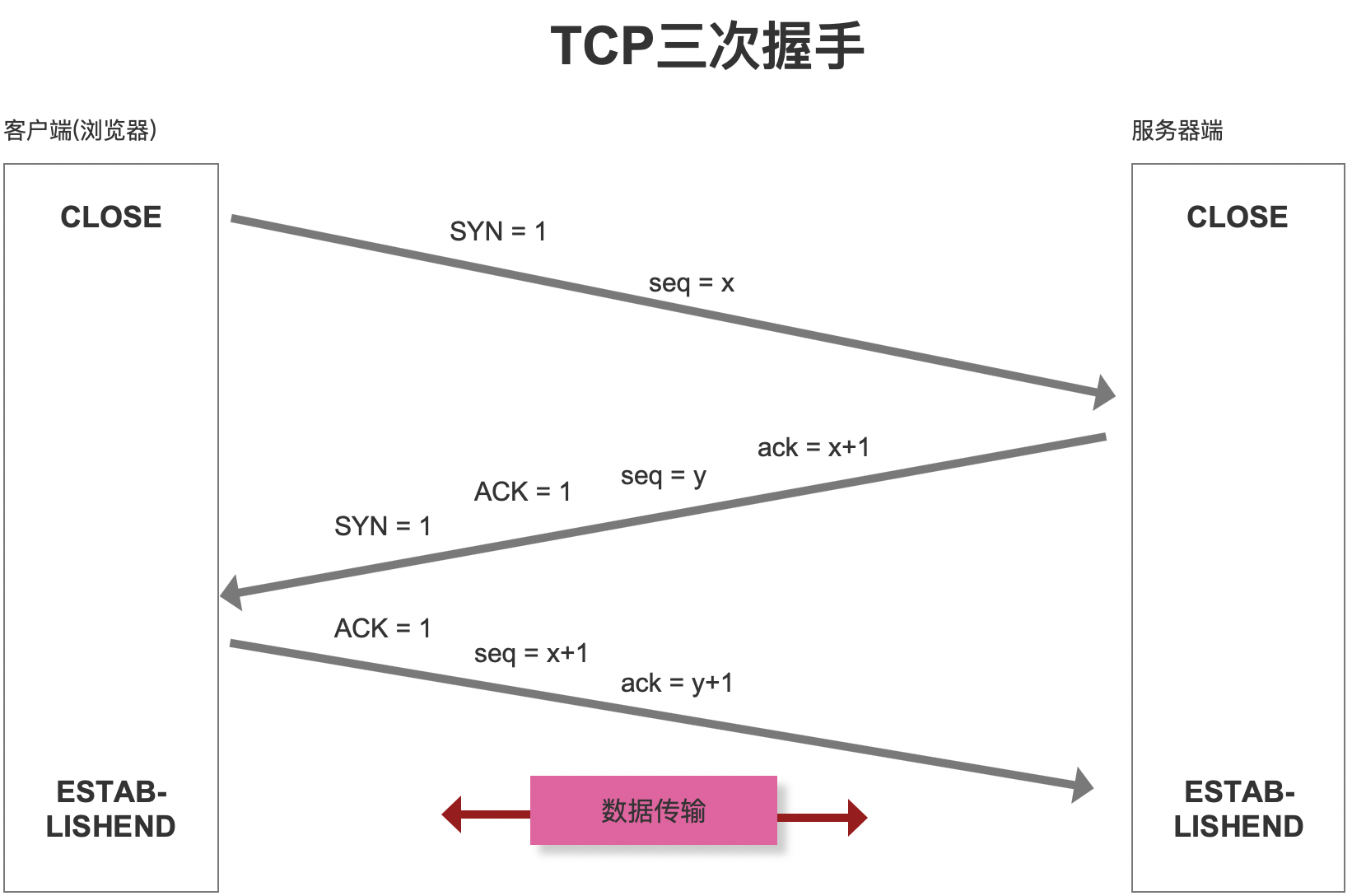
- seq 序号,用来标识从 TCP 源端向目的端发送的字节流,发起方发送数据时对此进行标记
- 标志位:
- ACK:确认序号有效
- RST:重置连接
- SYN:发起一个新连接
- FIN:释放一个连接
- ...
- ack 确认序号,只有 ACK 标志位为 1 时,确认序号字段才有效,ack=seq+1
-
-
为了保证
传输通道的稳定性,需要进行三次握手。-
第一次:
客户端发送一个信息,服务器接收请求。- 对于
客户端:- 知道了
客户端可以正常发信息。 - ...
- 知道了
- 对于服务端:
- 知道了
客户端可以正常发信息。 - 知道了
服务器可以正常接收信息。 - ...
- 知道了
- 对于
-
第二次:
服务器发送一个信息,客户端接收请求。- 对于
客户端:- 知道了
服务器可以正常接收信息。 - 知道了
服务器可以正常发信息。 - 知道了
客户端可以正常接收信息。 - ...
- 知道了
- 对于服务端:
- 知道了
服务器可以正常发信息。 - ...
- 知道了
- 对于
-
第三次:
客户端发送一个信息,服务器接收请求。- 对于
客户端:- ...
- 对于服务端:
- 知道了
客户端可以正常接收信息。 - ...
- 知道了
- 对于
-
-
三次握手为什么不用两次,或者四次?
- TCP 作为一种可靠传输控制协议,其核心思想:既要保证数据可靠传输,又要提高传输的效率!
-
-
第五步:客户端和服务器之间的数据通信。
-
客户端向服务器发送请求,把一些信息传递给服务器。即
Request请求阶段。包含客户端信息的组成部分:- 请求起始行:
请求方式、请求地址(包括问号传参信息)、HTTP 协议的版本。 - 请求头:也叫
请求首部,各种各样的键值对如token、Content-Type、Cookie、User-Agent、Authorization...。 - 请求主体(
Request Payload):请求主体中的数据格式是有限制的。- 支持
字符串:JSON格式的字符串:Content-Type:application/json。urlencoded格式的字符串:如xxx=xxx&xxx=xxx,Content-Type:application/x-www-form-urlencoded。普通字符串:Content-Type:text/plain。
- 支持
FormData格式对象:Content-Type:multipart/form-data。- 主要用于文件上传。
- 支持
Buffer/二进制等格式数据。 - ...
- 不支持
其余的对象格式- 如果
请求主体中,我们传递的是普通对象,则浏览器默认会把其变为普通字符串传递给服务器。- 浏览器默认会把
普通对象变为如"[object Object]"的普通字符串; - 在
axios内部,如果我们传递的是普通对象,其内部会默认把普通对象变为JSON格式字符串,基于请求主体传递给服务器。
- 浏览器默认会把
- 如果
- 支持
- 请求起始行:
-
服务器接收客户端的请求,把客户端需要的信息返回给客户端。即Response响应阶段。包含服务器信息的组成部分:- 响应起始行:
HTTP协议的版本、HTTP响应状态码 - 响应头:
Connection: keep-alive、Date-服务器时间... - 响应主体:一般返回的都是
JSON格式字符串,但也有可能是其它的格式- 例如:
xmlbuffer- ...
- 例如:
- 响应起始行:
-
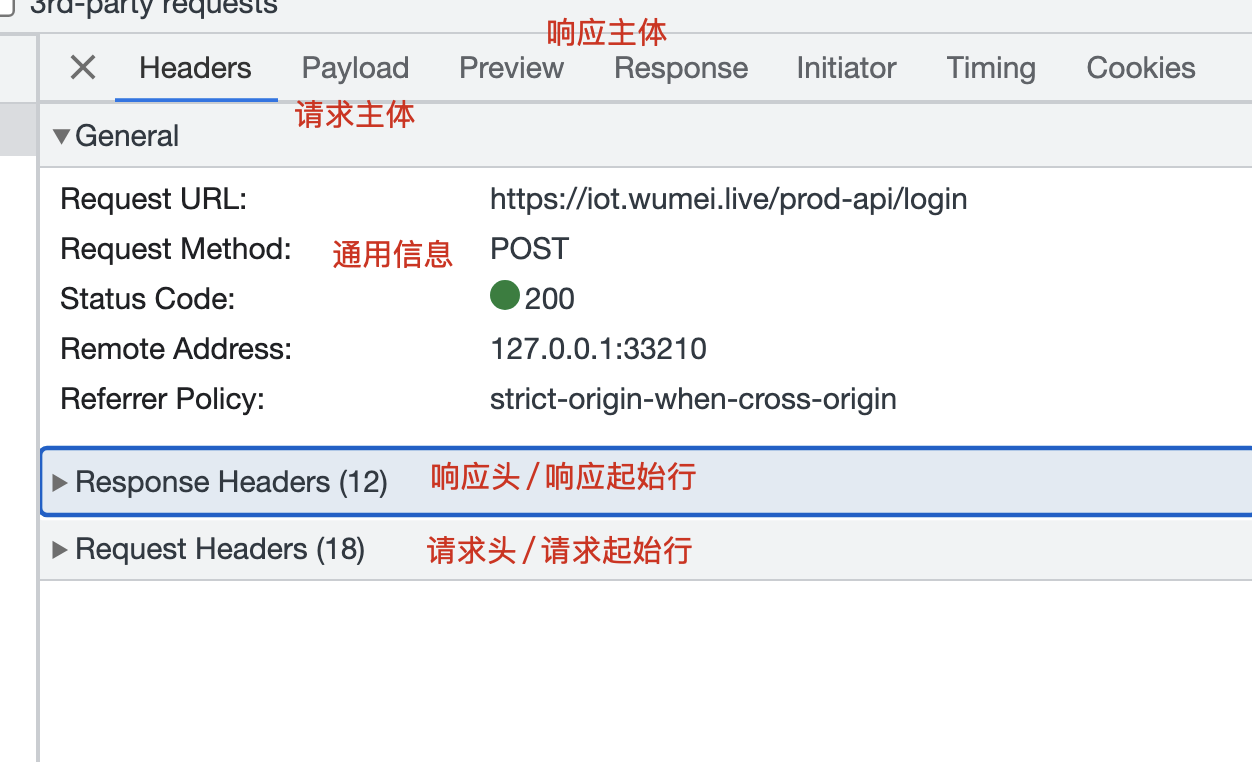
HTTP事务:Request+Response。 -
HTTP报文:请求起始行/请求头/请求主体/响应起始行/响应头/响应主体,统称为HTTP报文!- 在
控制台的Network中可查看详细的报文信息 -
- 在
-
-
第六步:TCP 四次挥手
-
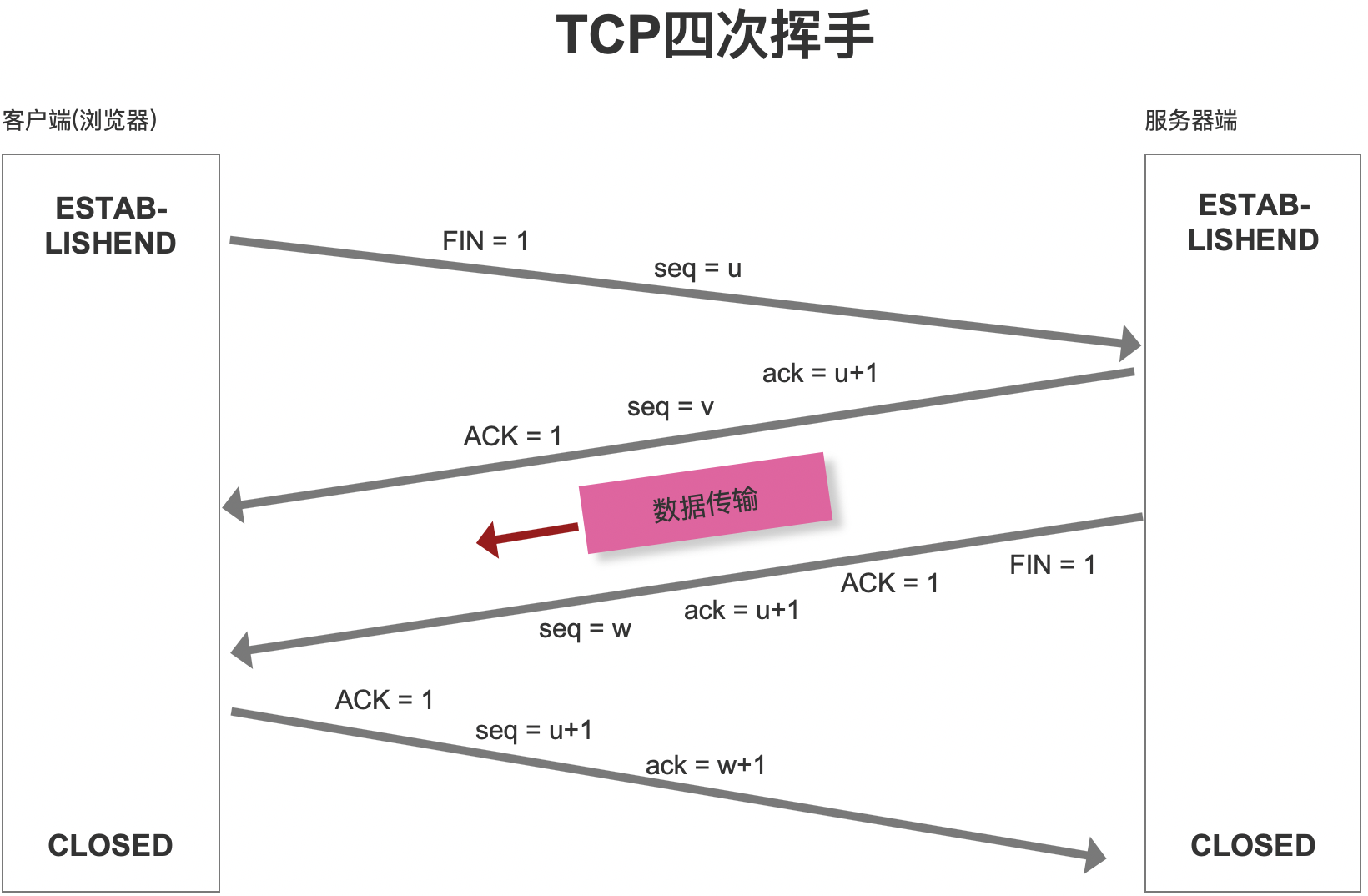
目的:把
建立好的传输通道释放掉。 -
流程:
- 当
客户端把信息发送给服务器后,紧接着就发起了第一次挥手:我把信息给你了,你记得接收哈。 服务器接收到客户端的请求和传递的信息后:服务器端发起第二次挥手:请求我收到了,你稍等一会吧,我现在去给你准备东西。- 之后
服务器根据客户端的信息:- 准备
客户端需要的信息。 - 把
客户端需要的信息返回给客户端。
- 准备
服务器端发起第三次挥手:东西已经合你了,你记得接收一下,我这边打算关闭通道了!
客户端收到服务器返回的内容后,再次给服务器一个回馈(第四次挥手):东西我收到了,谢谢,我这边也关闭了。
- 当
-
如果
每一次请求都重新地进行三握四挥,这样太浪费性能和时间了。- 我们期望
第一次请求,把传输通道建立好后,当HTTP事务完成后,这个通道先不要关闭,保留一段时间,让后面的请求,继续基于这个通信通信即可!- 解决方案:
请求头/响应头中设置Connection:keep-alive,保持TCP通道的长链接即可。- 在
HTTP/1.1版本中,自动就设置了keep-alive长链接机制,服务器端可以修改长链接的时间或者次数。
- 在
- 解决方案:
- 我们期望
-
-
第七步:客户端渲染
-
浏览器把服务器返回的信息(包括html/css/js/图片/数据等)进行渲染,最后绘制出对应的页面! -
步骤:
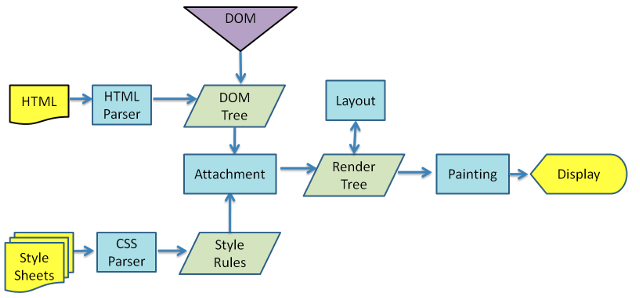
-
构建
DOM-Tree即DOM树。-
当从
服务器获取HTML页面后,浏览器会分配GUI渲染线程。自上而下进行解析。- 遇到
<link>标签:分配一个新的HTTP网络线程去服务器获取样式资源,同时GUI继续向下渲染!- 不会阻碍
GUI的渲染。
- 不会阻碍
- 遇到
<style>标签:虽然不需要去服务器获取样式,但是此时的样式是不渲染的,只有等待DOM-Tree构建完毕后,并且其余基于<link>标签获取的样式也回来了,才会按照原定的顺序(编写的顺序)进行渲染!- 为了保证样式的权重和先后顺序的覆盖。
- 遇到
@import:也会分配一个 HTTP 线程去服务器获取样式资源,只不过其会阻碍 GUI 的渲染。- 只有
等待样式资源获取完毕后,GUI才会继续向下渲染!
- 只有
- 遇到
<img>标签/<audio>标签/<video>标签:和<link>标签一致。分配一个新的HTTP网络线程去服务器获取样式资源,同时GUI继续向下渲染!- 但是对于
<audio>标签/<video>标签音视频来讲,如果设置了preload="none"属性,则开始渲染页面的时候并不会去服务器获取音视频资源。
- 但是对于
- 遇到
<script>...</script>:立即把js代码执行。- 交给
js引擎线程渲染,但是GUI会暂停,也相当于阻碍了GUI渲染。
- 交给
- 遇到
<script src="">标签:阻碍GUI渲染,分配一个新的HTTP线程去服务器获取js资源,等待js代码获取到之后,交由js引擎去渲染,只有js代码执行完毕,才会继续GUI的渲染! - 遇到
<script src="" async>标签:分配一个新的HTTP线程去服务器获取js资源,此时GUI会继续渲染。但是等到js代码获取到之后,会立即停止GUI的渲染,先把js代码执行! - 遇到
<script src="" defer>标签:和<link>标签一致。会分配一个新的HTTP线程去服务器获取js资源,GUI会继续向下渲染。等待DOM-Tree渲染完毕,并且其它设置defer的js资源也获取到了,再按照编写的顺序,依次执行js代码!
- 遇到
-
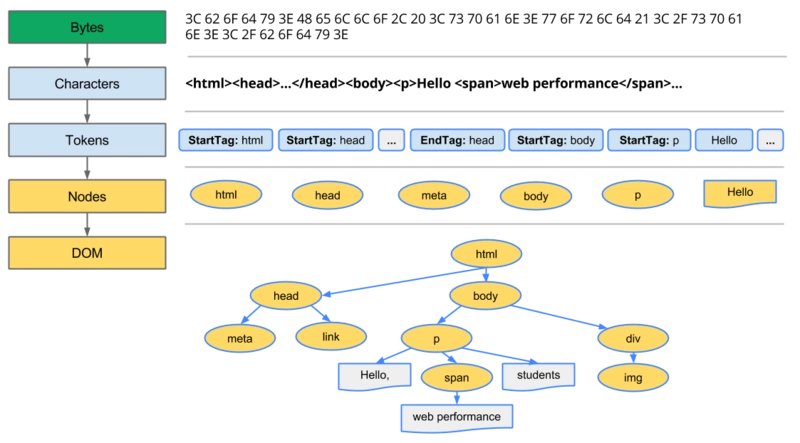
当
把所有的HTML结构解析完毕后,会构建出DOM元素之间的层级关系,这就是DOM树。DOM元素之间的层级关系就是DOM树。
-

-
在
DOM树构建完毕后,会触发一个事件:DOMContentLoaded。window.addEventListener(`DOMContentLoaded`, function () { //此函数中,一定可以获取到页面中已经渲染出来的DOM元素。 //... });DOMContentLoaded只能用DOM2级事件进行绑定。
-
-
-
构建
CSSOM-Tree即样式树。- 等待
样式资源从服务器获取到之后,会按照既定的顺序,开始渲染css样式,最后生成CSSOM-Tree! css样式被称之为层叠样式表,就是因为其具备:层级、权重、继承的特点。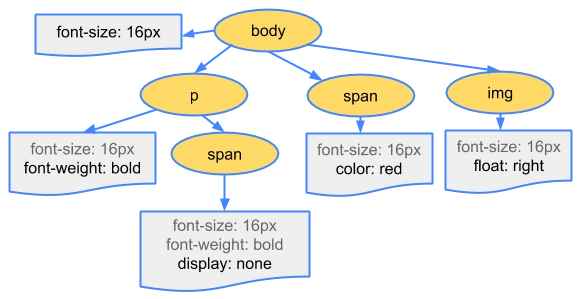
- 等待
-
把
DOM-Tree与CSSOM-Tree合并在一直,创建Render-Tree即渲染树。渲染树中,已经非常清楚地知道了:DOM元素的层级和每一个元素的样式。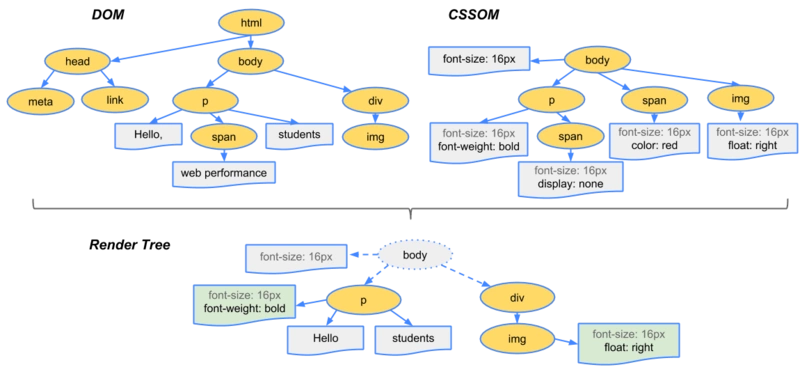
-
Layout即布局排列计算-对应回流/重排-Reflow。- 根据
当前视口的大小,计算元素在视口的位置,以及相关的样式!- 根据生成的渲染树,计算它们在
设备视口viewport内的确切位置和大小,这个计算的阶段就是回流;
- 根据生成的渲染树,计算它们在
- 根据
-
分层。
-
在一个页面中,不仅仅只有一层,它是一个
3D空间,会存在很多层。这就是所谓的脱离文档流。 -
而
分层的目的就是:把每一层及每一层中的元素样式都详细地规划好,包括具体的绘制步骤。
-
-
Painting绘制-对应重绘Repainting。- 根据渲染树以及回流得到的几何信息,得到节点的绝对像素 -> 绘制;
- 开始
一层层地按照规划好的步骤进行绘制,直到整个页面都被绘制完毕!
-
-
-
根据这种 HTTP 网络进行优化,这就是CRP 关键渲染路径。
- CRP(Critical [ˈkrɪtɪkl] Rendering [ˈrendərɪŋ] Path)。