mysql基础知识笔记
mysql基础知识笔记
0. 介绍和安装
0.1 介绍
- RDBMS : 关系型数据库 ,代表产品: Oracle MySQL MSSQL PG
- NoSQL:非关系型的数据库,易拓展,大数据量,高性能,代表产品:MongoDB Redis ES
- NewSQL:不仅具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID(原子性、一致性、隔离性、持久性)和SQL(结构化查询语言)等特性
0.2 安装
官网:www.mysql.com
1.解压
bash
tar xf mysql-8.0.20-linux-glibc2.12-x86_64.tar.xz
2.建立软链接
bash
ln -s /opt/mysql-8.0.20-linux-glibc2.12-x86_64 /usr/local/mysql
3.修改环境变量
bash
vim /etc/profile
# 添加:
export PATH=/usr/local/mysql/bin:$PATH
# 刷新:
source /etc/profile
4.创建用户 目录 配置文件
bash
[root@localhost mysql]# useradd mysql
[root@localhost mysql]# mkdir -p /data/3306/data
[root@localhost mysql]# chown -R mysql.mysql /data
[root@localhost mysql]# vim /etc/my.cnf
[mysqld]
user=mysql
basedir=/usr/local/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
[mysql]
socket=/tmp/mysql.sock
5.初始化数据
如果没有配置文件:
bash
mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/data/3306/data
如果有配置文件:
bash
[root@localhost data]# mysqld --initialize-insecure
6.准备启动脚本
bash
[root@localhost ~]# cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
# 停止
[root@localhost ~]# /etc/init.d/mysqld stop
Shutting down MySQL... SUCCESS!
# 启动
[root@localhost ~]# /etc/init.d/mysqld start
Starting MySQL.. SUCCESS!
# 重启
[root@localhost ~]# /etc/init.d/mysqld restart
Shutting down MySQL.. SUCCESS!
Starting MySQL.. SUCCESS!
# 查看状态
[root@localhost ~]# /etc/init.d/mysqld status
SUCCESS! MySQL running (12134)
注:
bash
# 报错:
Starting MySQL..... ERROR! The server quit without updating PID file (/data/3306/data/node2.pid).
ps -ef|grep mysqld
kill -9 进程号 然后重启
1. 基础管理
1.1 用户管理
查询用户
bash
select user,host ,authentication_string ,plugin from mysql.user;
注:
plugin,加密插件,在8.0之后做了升级,caching_sha2_password,安全性增高了.
会导致很多老的客户端程序无法连接至MySQL.早期版本是mysql_native_password.
无法连接时,可手动将plugin字段改成mysql_native_password
创建用户
bash
create user root@'10.0.0.%' identified by '123';
# 将plugin字段指定成mysql_native_password
create user user1@'10.0.0.%' identified with mysql_native_password by '123';
修改用户
bash
# 修改密码并将plugin字段修改成mysql_native_password
alter user root@'10.0.0.%' identified with mysql_native_password by '123';
# 锁定用户
alter user user1@'10.0.0.%' account lock;
# 解锁用户
alter user user1@'10.0.0.%' account unlock;
删除用户
bash
drop user user1@'10.0.0.%';
注:
8.0 之后 ,只能先建用户后授权.
1.2 权限管理
权限列表
bash
# 查看所有权限
show privileges;
# 常用权限
select ,insert ,update ,delete
# all权限
不包含 grant option(给用户权限的权限)
授权
bash
grant all on *.* to root@'10.0.0.%';
# 权限作用范围
*.* : 所有库下所有表(用户存在mysql库的user表中)
lufi.*: 单库下的所有表(用户存在mysql库的db表中)
lufi.user: 单表(用户存在mysql库的tables_priv表中)
# 刷新权限,立刻生效
flush privileges
查询用户权限
bash
show grants for root@'10.0.0.%';
回收权限
bash
revoke dorp on *.* from root@'10.0.0.%';
1.3 连接管理
socket文件连接管理
bash
# 需要提前创建localhost白名单的用户
[root@localhost ~]# mysql -uroot -p -S /tmp/mysql.sock
TCP/IP方式
bash
# 需要将登陆客户端IP加入白名单
[root@localhost ~]# mysql -uroot -p123 -h 10.0.0.111 -P3306
1.4 配置管理
离线配置
步骤:修改配置文件,重启数据库.
bash
# 配置文件应用顺序
[root@localhost ~]# mysqld --help --verbose |grep my.cnf
/etc/my.cnf --->/etc/mysql/my.cnf ---> /usr/local/mysql/etc/my.cnf ---> ~/.my.cnf
# 配置文件结构
1.标签项: [xxx]
服务器端标签: [server] [mysqld] [mysqld_safe]
客户端标签 : [clinet] [mysql]
2.配置项: xxx = xxx
在线配置
bash
# 通过专用配置命令进行修改.
mysql> set global innodb_buffer_pool_size=16777216;
2. MySQL的体系结构
Server 层
-- 连接层
提供连接协议: Socket文件,TCP/IP
验证:授权表.
提供连接线程
-- SQL层 select id,name from t1 where id=10; ----> "关系代数" 与 或 非 过滤 投影
语法
语义
权限
语句解析
优化器 : 优化(逻辑优化,物理优化(索引)) ---> 执行计划
执行器: 执行SQL --->执行结果:你需要的数据在哪个磁盘的哪个位置上.给我拿上来.
Engine 层
负责和磁盘交互.
3.SQL
关系型数据库通用的语言.结构化查询语言.
3.1 SQL_MODE(严格模式)
bash
# 查看严格模式有哪些特性
mysql> select @@sql_mode;
#ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
# 说明:
ONLY_FULL_GROUP_BY(5.7版本新特性)
在执行GROUP_BY时,mysql首先按GROUP_BY后的字段排序,然后去重,为了维持表的一对一关系,在5.7版本之前是将第一个结果显示,在5.7之后会报错。可以通过聚合函数来显示。
3.2 数据类型
整型
bash
tinyint 1个字节 有符号(-128 ~ 127) 无符号(unsigned) (0 ~ 255) 小整型值
int 4个字节 有符号(-21亿 ~ 21亿 左右) 无符号(unsigned) (0 ~ 42亿) 大整型值
create table t1(id int , age tinyint );
insert into t1 values(2200000000,1) # error
insert into t1 values(2100000000,1)
insert into t1 values(2100000000,128) # error
insert into t1 values(2100000000,127)
浮点型
bash
float(255,30) 单精度
double(255,30) 双精度
decimal(65,30) 金钱类型,使用字符串的形式保存小数
"""默认存在四舍五入"""
create table t2(f1 float(5,2) , f2 double(5,2) , f3 decimal(5,2));
insert into t2 values(1.77777777777777777777777777,1.77777777777777777777777777,1.77777777777777777777777777);
"""float 默认小数保留5位,double小数位截取16位,decimal(10,0) 默认保留整数,存在四舍五入"""
create table t3(f1 float,f2 double ,f3 decimal);
insert into t3 values(1.77777777777777777777777777,1.77777777777777777777777777,1.77777777777777777777777777);
create table t4(f1 float(5,2));
insert into t4 values(12.34567889) # 12.35
insert into t4 values(123.34567889) # 123.35
insert into t4 values(1234.34567889) # error
字符串
bash
char 字符长度 255个
varchar 字符长度 21845个 (注意:总字节数不超过65535)
char(11) 定长 : 固定开辟11个字符长度的空间(手机号,身份证号,银行卡), 开辟空间速度上char速度更快
varchar(11) 变长 : 最多开辟11个字符长度的空间(评论,消息留言,地址), 开辟速度相较于char慢一点.
text 文本类型,存论文,小说,文章..
create table t5(c char(11), v varchar(11) , t text);
insert into t5 values('1111',"酸辣粉加上队列副经理开","sdfsdf234");
insert into t5 values('1111',"酸辣粉加上队列副经理2开","sdfsdf234"); error
# concat 拼接任意长度的字符串
select concat(c,":",v,":",t) from t5;
枚举 和 集合
bash
enum 枚举 : 从列出来的数据当中选一个(性别)
set 集合 : 从列出来的数据当中选多个(自动去重) 爱好
create table t6(
id int,
name varchar(10),
money float(6,3),
sex enum("男性","女性","禽兽","人妖","雌雄同体","半兽人","阿凡达"),
hobby set("吃肉","抽烟","喝酒","喝假酒")
);
时间类型
bash
date YYYY-MM-DD 年月日 (结婚纪念日,节假日)
time HH:MM:SS 时分秒 (体育竞赛)
year YYYY 年份值 (历史,酒的年份)
datetime YYYY-MM-DD HH:MM:SS 年月日 时分秒 (用户登录时间,下单时间)
create table t1(d date , t time , y year , dt datetime);
insert into t1 values("2020-08-25","08:25:30","2020","2020-08-25 08:25:30")
insert into t1 values(now(),now(),now(),now())
timestamp YYYYMMDDHHMMSS(时间戳) 自动更新时间(不需要手动,系统自动更新时间) 数据上一次的修改时间
create table t2(dt datetime , ts timestamp);
insert into t2 values(null,null);
insert into t2 values(20200825082530,20200825082530);
insert into t2 values(20200825082530,20380825082530); error 不能超过2038年的某一年
对字段的约束
bash
unsigned 无符号
not null 不为空
default 设置默认值
unique 唯一约束,数据唯一不重复
primary key 主键,标记数据的唯一特征(唯一且不为空)
auto_increment 自增加1(一般配合主键使用, 或 unique进行自增)
zerofill 零填充(配合整型int使用) int(11) , 位数不够11位,拿0补充
foreign key 外键,把多张表通过一个关联字段联合在一起,(这个字段可以加外键)
3.3 字符集
bash
utf8 最多存三字节字符
utf8mb4 最多存四字节字符 emoji
3.4 SQL 种类
DDL : 数据定义语言
DML : 数据操作语言
DDL 应用规范
bash
库:
create database
drop database
alter database
规范:
a. 生产系统禁用drop 操作
b. 库名不要使用系统预留字符,不要大写字母,不要数字开头.
c. 建库是显式设置字符集.
表:
create table
规范:
表名不要使用系统预留字符,不要大写字母,不要数字开头.ob_user;不要超过18字符.
数据类型: 合适的 简短的 足够的
每个表要有主键.
每个列尽可能非空,或者设置默认值
每个列要加注释.
存储引擎使用InnoDB 字符集 utf8mb4
alter table
添加列
删除列
加索引
删索引
该类型
prepare MDL X 阻塞所有DML写入 DDL (预处理状态)
exec S 降级共享锁 不阻塞DML , 阻塞DDL (执行状态)
commit MDL X 阻塞所有DML写入 DDL (提交状态)
8.0以前:
Online DDL 需要业务低估期间做. 或者使用PT-OSC.
8.0之后:
添加列可以直接做.
drop table
非必要不要使用.
3.5 SQL语句
库相关
bash
增
# 创建一个数据库
create database db0824 charset utf8;
查
# 查看所有数据库
show databases
# 查看建立数据库的语句
show create database db0824
改
alter database db0824_1 charset gbk
删
drop database db0824_1;
表相关
bash
# 先选择数据库
use 数据库名
增
# 字段名1 类型1 ,字段名2 类型2 , ... ...
create table t1(id int , name char);
查
# 查看所有表
show tables;
# 查看建表语句 配合\G 可以垂直显示
show create table t1;
# 查看表结构
desc t1
改
# modify 只能改变数据类型
alter table t1 modify name char(5)
# change 连字段名 + 类型一起改变
alter table t1 change name newname char(4)
# add 添加字段
alter table t1 add age int;
# drop 删除字段 column列
alter table t1 drop column age
# rename 更改表名
alter table t1 rename t1_2
删
drop table t1_2;
字段相关
bash
增
# 一次插入一条数据
'''insert into 表名(字段1,字段2,...) values(值1,值2, .... )'''
insert into t1_1(id,name) values(1,"xboy1");
# 一次插入多条数据
insert into t1_1(id,name) values(2,"xboy2"),(3,"xboy3"),(4,"xboy4");
# 不指定具体字段插入(默认把所有字段对应的值插一遍)
insert into t1_1 values(5,'xboy5');
# 指定单个字段插入数据
insert into t1_1(name) values('xboy6');
查
# 单表:
# * 代表所有
select * from t1_1;
# 指定字段进行查询
select id,name from t1_1;
#sql查询语句的完整语法
select .. from .. where .. group by .. having .. order by .. limit ..
# where:模糊查询 like "%" "_"
# 聚合函数
group_concat:按照分类的形式进行字段的拼接,count:统计总数,max:统计最大值,min:统计最小值,avg:统计平均值,sum:统计总和
# having:
分组之后过滤
# order by:
asc 升序: 从小到大(默认),desc 降序: 从大到小
# limit m,n:
m代表从第几条数据进行查询,0代表第一条,n代表的查询几条
# 多表:
# 内连接[两表或者多表满足条件的所有数据查询出来(两表之间的共有数据)]:
select 字段 from 表1 inner join 表2 on 必要的关联条件
# 外连接[左连接,右连接,全连接]:
# 1.左连接(左联查询 left join ) 以左表为主,右表为辅,完整查询左表所有数据,右表没有的补null
select * from employee left join department on employee.dep_id = department.id;
# 2.右连接(右联查询 right join ) 以右表为主,左表为辅,完整查询右表所有数据,左表没有的补null
select * from employee right join department on employee.dep_id = department.id;
# 3.全连接
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id
#改
# update 表名 set 字段=值 where 条件
update t1_1 set name="你真帅" where id = 1
# 切记更改时,加上条件,否则全都改掉了
update t1_1 set name="你真帅"
#删
# 指定id=2的这条数据删除
delete from t1_1 where id = 1
# 如果不加条件,删除所有数据
delete from t1_1
# 重置数据表 (删除数据 + 重置id)
truncate table t1_1;
4.索引
4.1 索引类型
BTREE : *****树形的数据结构(二叉树)
RTREE : 相对于BTREE,RTREE的优势在于范围查找.
HASH : 键值对(数学中的函数映射)
FTEXT : (FULLTEXT)全文索引
4.2 BTREE 结构
叶子节点(Leaf)
枝节点(No-Leaf)
根节点(ROOT)
4.3 MySQL如何应用Btree
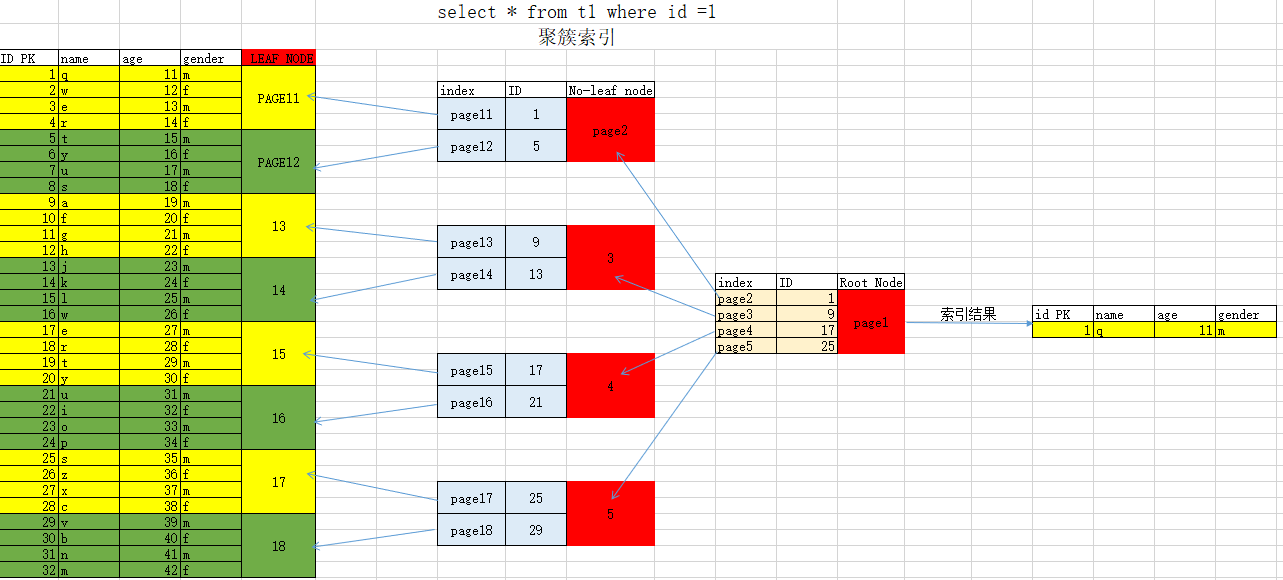
聚簇索引
组织和存储表的数据行.IOT 聚簇索引组织存储表.
a. 构建前提(依次寻找,构建)
PK 主键
UK NN 外键
ROWID 唯一的标识符
b. 构建细节
叶子节点(Leaf): 在录入数据时,会按照聚簇索引逻辑顺序,存储到物理上连续的多个数据页. 从而生成了叶子节点. 并且存储相邻叶子节点的双向指针.
枝节点(No-Leaf): 选取叶子节点的ID的范围+指针.
根节点(ROOT) : No-leaf节点的ID范围+指针
C. 优化效果
通过ID列作为查询条件时,会起到优化效果.
辅助索引
辅助索引需要人为创建
索引树如何生成?
叶子节点: 将索引列值+ID值取出,按照索引排序(默认从小到大).均匀存储到连续的数据页上.
非叶子节点:保存了叶子节点索引列支范围+指针.
根节点:保存非叶子节点的范围+指针.
如何进行查询优化?
当按照索引列作为查询条件时.
1. 扫描辅助索引,找到叶子节点.从而获取到条件值对应的ID
2. 根据ID在回到聚簇索引扫描,得到叶子节点.从而得到数据行(回表).
联合索引
使用场景:
bash
select * from t1 where name='x' and age=18 and gender='F';
联合索引相较于辅助索引,生成时索引树时,叶子节点:将联合的索引值都取出,非叶子节点和根节点保存最左侧字段.
辅助索引:
1611418906661
联合索引:
1611418969827
联合索引的最左原则?
a. 使用"基数"大的列作为最左列.
b. 查询条件中必须包含最左列条件
4.4 索引树高度影响因素
-
1.数据量
分区表. 定期归档数据. 分库分表.
-
2.索引列值长度
前缀索引.
-
3.主键长度过长
数字自增.
-
4.数据类型选择
合适的 简短的.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性