【MySQL笔记】窗口函数
什么是窗口函数
窗口函数(Window Function),又被叫做分析函数(Analytics Function)。
窗口函数允许用户在不显式分组查询的情况下对结果集进行分组和聚合计算。
窗口函数能够为结果集中的每一行计算类似排名、行号、百分比和移动聚合函数等值。
窗口函数原则上只能写在select子句中。
同时具有分组和排序的功能,不减少原表的行数
窗口函数语法
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)
<窗口函数>的位置,可以放以下两种函数:
1) 专用窗口函数,包括后面要讲到的rank, dense_rank, row_number等专用窗口函数。
2) 聚合函数,如sum. avg, count, max, min等
PARTITION BY:你只需将它看成GROUP BY子句,但是在窗口函数中,你要写PARTITION BY
ORDER BY:ORDER BY和普通查询语句中的ORDER BY没什么不同。
窗口函数
聚合窗口函数:
SUM(): 计算总和。
AVG(): 计算平均值。
COUNT(): 计算行数或非空值的数量。
MAX(): 计算最大值。
MIN(): 计算最小值。
排名窗口函数:
ROW_NUMBER(): 为结果集中的每一行分配一个唯一的序号。
RANK(): 为结果集中的每一行分配一个排名,可以出现并列的情况。
DENSE_RANK(): 类似于 RANK(),但不留 gaps,当有并列时,顺序不跳过数字。
NTILE(n): 将结果集分割成 n 个相等的部分,并为每部分分配一个编号。
偏移窗口函数:
LEAD(value, offset, default): 返回当前行之后的某一行的值。
LAG(value, offset, default): 返回当前行之前的某一行的值。
分析窗口函数:
CUME_DIST(): 计算当前行的累积分布。
PERCENT_RANK(): 返回当前行的百分比排名。
案例
案例1、获取性别的平均GPA
如果要按性别获取平均GPA,可以使用聚合函数并运行以下查询:
SELECT Gender, AVG(GPA) as avg_gpa FROM students GROUP BY Gender
然后再将结果join到初始表,但这需要两个步骤。
但如果我们使用窗口函数,我们则可以一步到位,并得到相同的结果:
SELECT *, AVG(GPA) OVER (PARTITION BY Gender) as avg_gpa FROM students
通过上面的查询,我们正在按性别对数据进行划分,并计算每种性别的平均GPA。然后,它将创建一个称为avg_gpa的新列,并为每行附加关联的平均GPA。
案例2、为每个班级学生按成绩排名
例如下图,是班级表中的内容
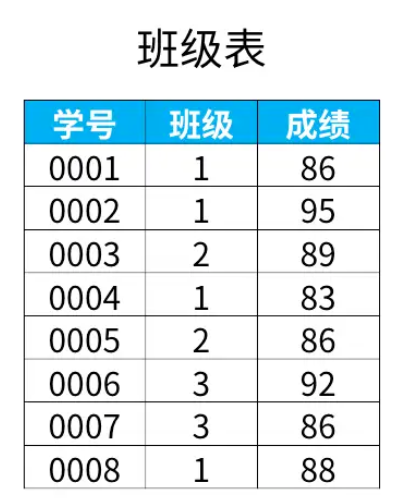
如果我们想在每个班级内按成绩排名,得到下面的结果
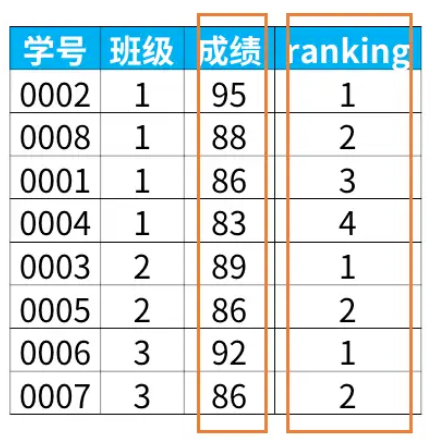
得到上面结果的sql语句代码如下:
select *,
rank() over (partition by 班级
order by 成绩 desc) as ranking
from 班级表
我们来解释下这个sql语句里的select子句。rank是排序的函数。要求是“每个班级内按成绩排名”,这句话可以分为两部分:
1)每个班级内:按班级分组
partition by用来对表分组。在这个例子中,所以我们指定了按“班级”分组(partition by 班级)
2)按成绩排名
order by子句的功能是对分组后的结果进行排序,默认是按照升序(asc)排列。在本例中(order by 成绩 desc)是按成绩这一列排序,加了desc关键词表示降序排列。
通过下图,我们就可以理解partiition by(分组)和order by(在组内排序)的作用了。

窗口函数具备了我们之前学过的group by子句分组的功能和order by子句排序的功能。那么,为什么还要用窗口函数呢?
这是因为,group by分组汇总后改变了表的行数,一行只有一个类别。而partiition by和rank函数不会减少原表中的行数。
案例3、rank()、dense_rank()、row_number()
专用窗口函数rank, dense_rank, row_number有什么区别呢?
它们的区别我举个例子,你们一下就能看懂:
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num
from 班级表
得到结果:

从上面的结果可以看出:
rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
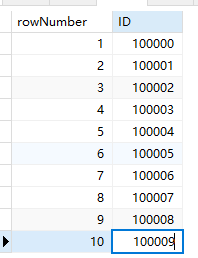
加行号
SELECT ROW_NUMBER() over (order by id) as rowNumber,order_master.ID from order_master limit 10;
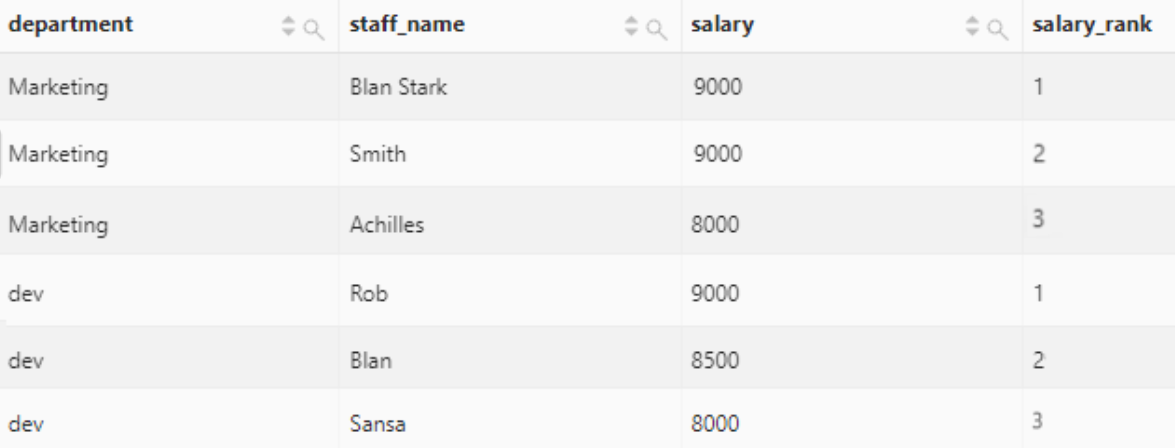
按照部门分区,计算员工薪水在部门内的排名:
select
department,
staff_name,
salary,
row_number() over(
partition by department
order by
salary desc
) as salary_rank
order by
department,
salary_rank
sum()函数
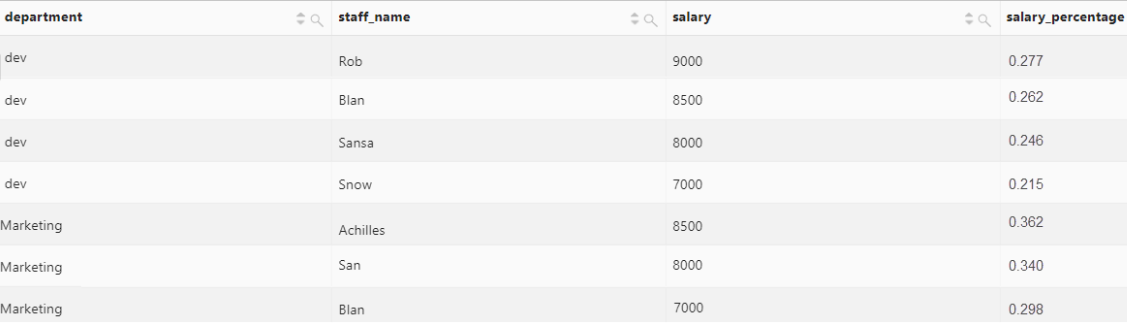
按照部门分区,获取每个员工薪水在部门内的占比。
SELECT
department,
staff_name,
salary,
round ( salary * 1.0 / sum(salary) over(partition by department), 3) AS salary_percentage
cume_dist函数
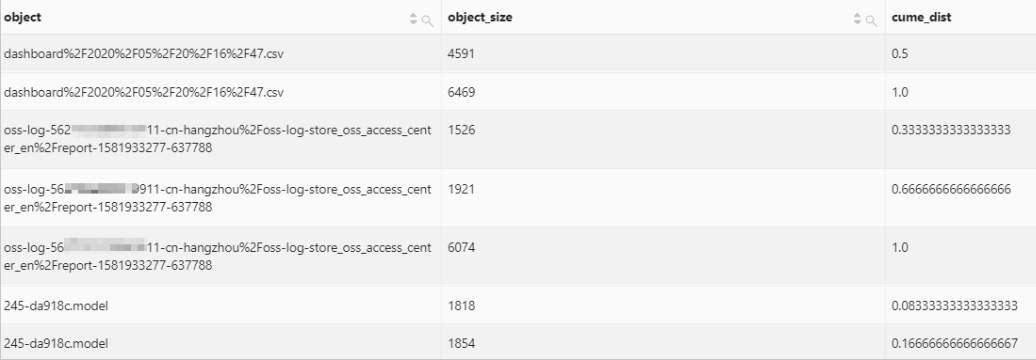
cume_dist函数用于统计窗口分区内各个值的累计分布。即计算窗口分区内值小于等于当前值的行数占窗口内总行数的比例。返回值范围为(0,1]。
select
object,
object_size,
cume_dist() over (
partition by object
order by
object_size
) as cume_dist
from oss-log-store
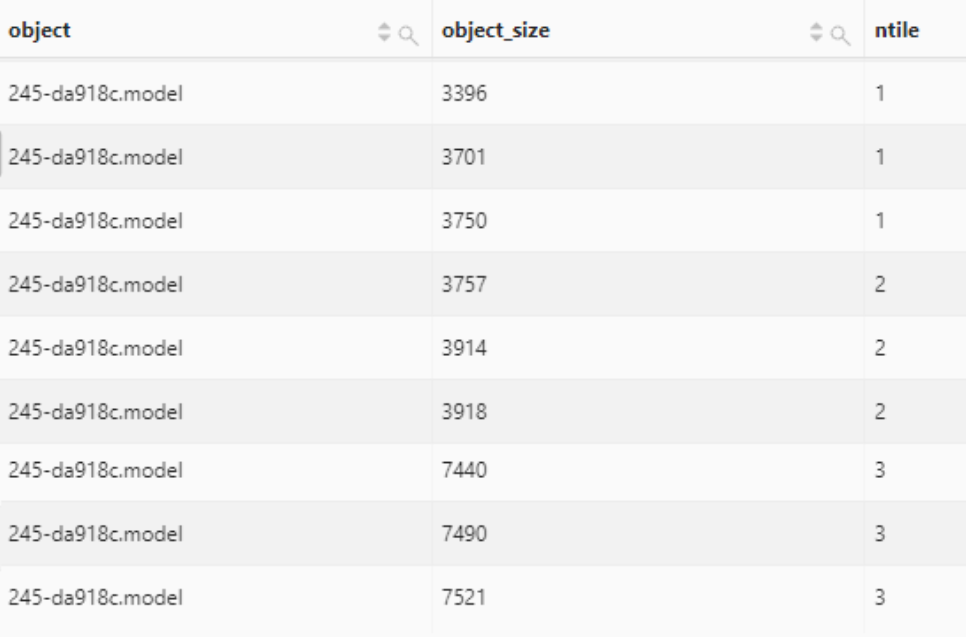
ntile函数
ntile函数用于将窗口分区内数据按照顺序分成N组。
语法:
ntile(n) over (
[partition by partition_expression]
[order by order_expression]
)
将指定对象中的数据分成3组。
select
object,
object_size,
ntile(3) over (
partition by object
order by
object_size
) as ntile
from oss-log-store
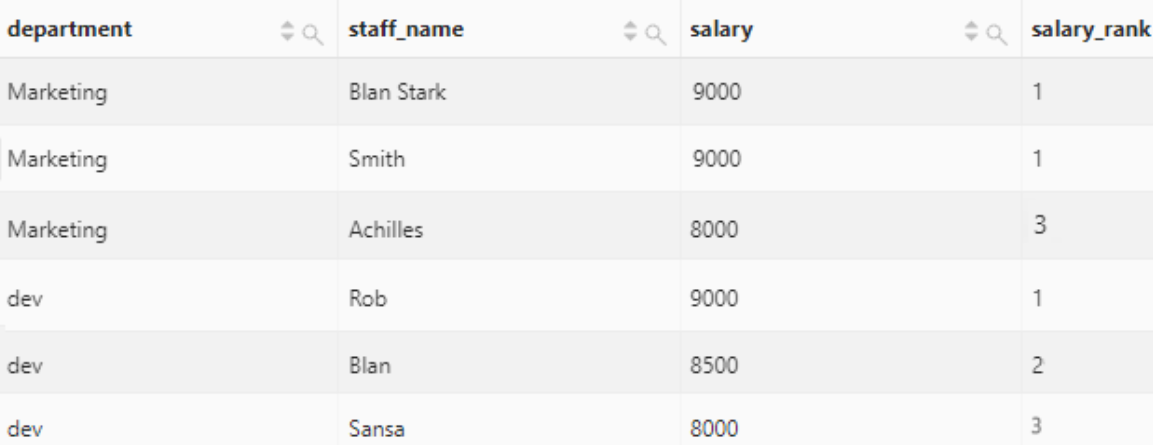
rank
函数用于窗口分区内值的排名。相同值拥有相同的排名,排名不是连续的,例如有两个相同值的排名为1,则下一个值的排名为3。
按照部门分区,计算员工薪水在部门内的排名。
select
department,
staff_name,
salary,
rank() over(
partition by department
order by
salary desc
) as salary_rank
order by
department,
salary_rank
first_value函数
first_value函数用于返回各个窗口分区内第一行的值。
获取目标OSS Bucket中各个对象的最小值。
select
object,
object_size,
first_value(object_size) over (
partition by object
order by
object_size
range between unbounded preceding and unbounded following
) as first_value
from oss-log-store

last_value函数
last_value函数用于返回各个窗口分区内最后一行的值。同上
lag函数
lag函数用于返回窗口分区内位于当前行上方第offset行的值。
语法:
lag(x, offset, default_value) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)
参数说明:
- x:列名,可以为任意数据类型。
- offset:偏离量。如果offset为0,则返回当前行的值。
- default_value:如果不存在指定的偏离行,则返回default_value。
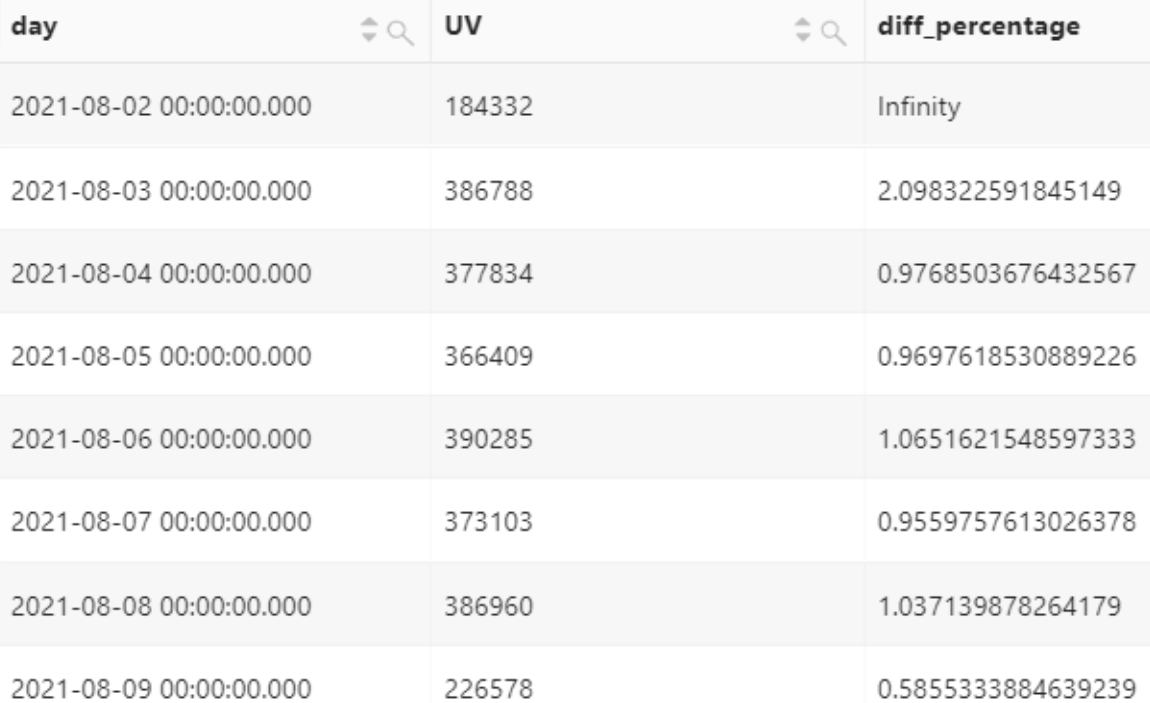
按天统计网站访问UV,获取每天网站访问UV相比前一天的增长情况。
select
day,
UV,
UV * 1.0 /(lag(UV, 1, 0) over()) as diff_percentage
from (
select
approx_distinct(client_ip) as UV,
date_trunc('day', __time__) as day
from log
group by
day
order by
day asc
)
lead函数
函数用于返回窗口分区内位于当前行下方第offset行的值。
语法
lead(x, offset, default_value) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)
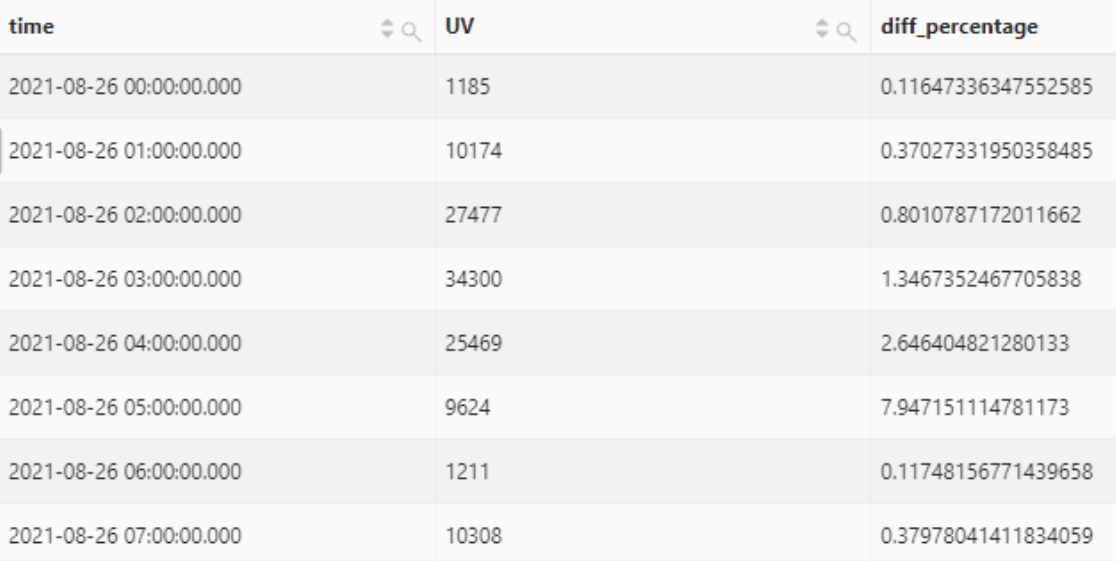
计算2021-08-26当天,当前一小时网站访问UV与后一小时的占比情况。
select
time,
UV,
UV * 1.0 /(lead(UV, 1, 0) over()) as diff_percentage
from (
select
approx_distinct(client_ip) as uv,
date_trunc('hour', __time__) as time
from log
group by
time
order by
time asc
)
nth_value函数
nth_value函数用于返回窗口分区中第offset行的值。
语法
nth_value(x, offset) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)
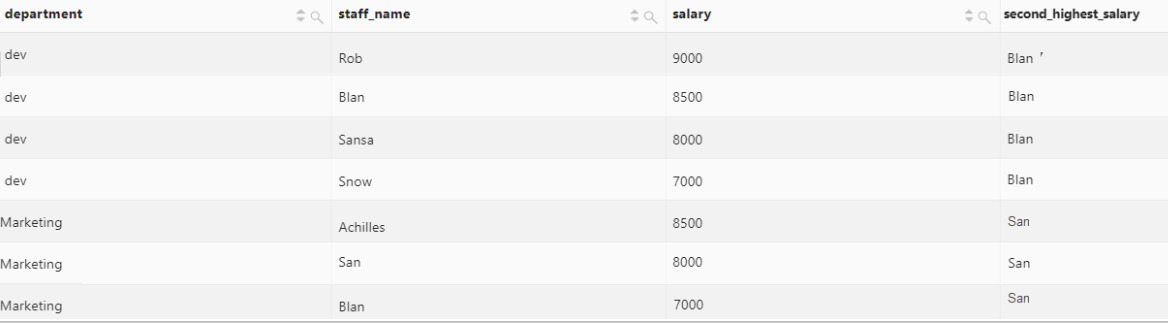
按照部门分区,统计各个部门中薪水第二高的员工。
select
department,
staff_name,
salary,
nth_value(staff_name, 2) over(
partition by department
order by
salary desc
range between unbounded preceding and unbounded following
) as second_highest_salary from log
参考:
https://help.aliyun.com/zh/sls/user-guide/window-functions






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2020-10-23 Newtonsoft.Json笔记 -JsonConverter
2020-10-23 Newtonsoft.Json笔记-JsonPropertyAttribute