【MySQL笔记】索引
介绍
索引是帮助 MySQL 高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构上实现高级查询算法,这种数据结构就是索引。
优点
- 大大提高了查询速度,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
缺点
- 索引列也是要占用空间的
- 索引大大提高了查询效率,但降低了更新的速度,比如 INSERT、UPDATE、DELETE
数据结构
| 索引结构 | 描述 |
|---|---|
| B+Tree | 最常见的索引类型,大部分引擎都支持B+树索引 |
| Hash | 底层数据结构是用哈希表实现,只有精确匹配索引列的查询才有效,不支持范围查询 |
| R-Tree(空间索引) | 空间索引是 MyISAM 引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
| Full-Text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式,类似于 Lucene, Solr, ES |
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| R-Tree索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本后支持 | 支持 | 不支持 |
二叉树

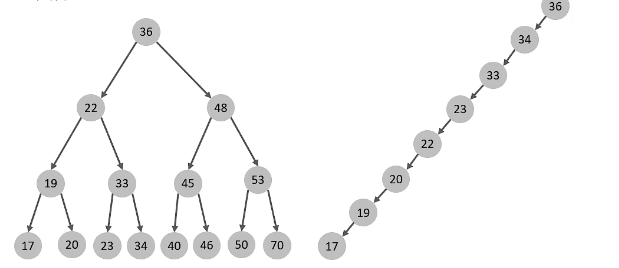
二叉树弊端:
顺序插入时,会形成一个链表,查询性能大大降低。大数据情况下层级较深,检索速度慢,如下:
红黑树解决二叉树平衡问题:
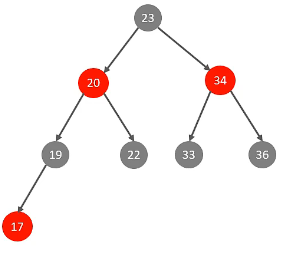
红黑树可以自动平衡数据,但是如果数据量太大,层级依然很深,减速速度慢。
B-Tree(多路平衡查找树)
为了解决上述问题,可以使用 B-Tree 结构。
因为二叉树、红黑树中每个节点只可以包含两个子节点,所以导致层级深,B-Tree中一个节点下可以包含多个子节点
B-Tree (多路平衡查找树) 以一棵最大度数(max-degree,指一个节点的子节点个数)为5(5阶)的 b-tree 为例(每个节点最多存储4个key,5个指针)
演示地址
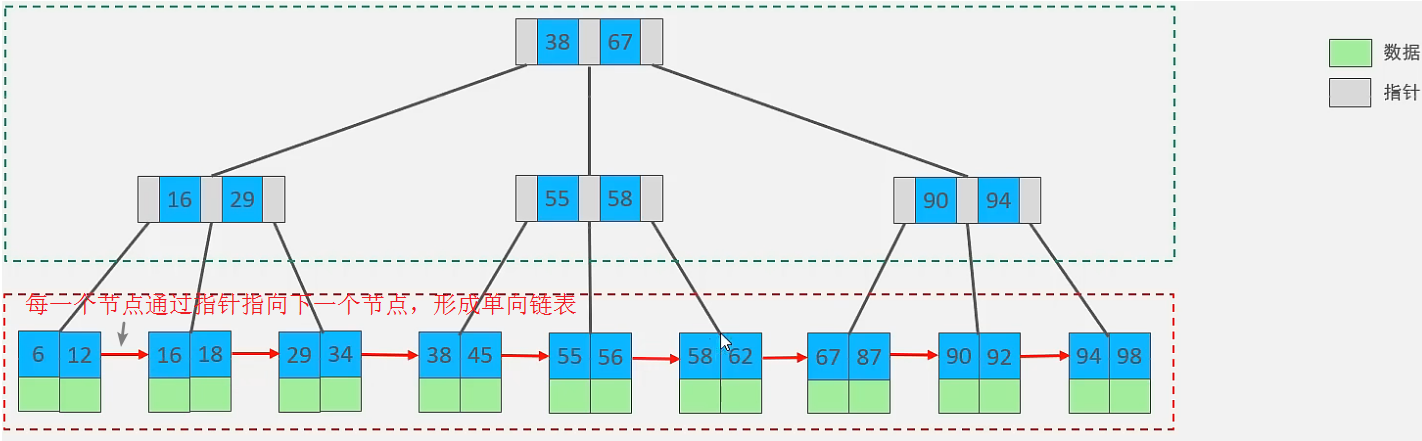
B+Tree
结构图:
演示地址
与 B-Tree 的区别:
- 所有的数据都会出现在叶子节点,非叶子节点只存储索引,可以放更多索引
- 叶子节点包含所有索引字段
- 叶子节点形成一个单向链表,区间访问性能
MySQL 索引数据结构对经典的 B+Tree 进行了优化。在原 B+Tree 的基础上,增加一个指向相邻叶子节点的链表指针(双向链表),就形成了带有顺序指针的 B+Tree,提高区间访问的性能。
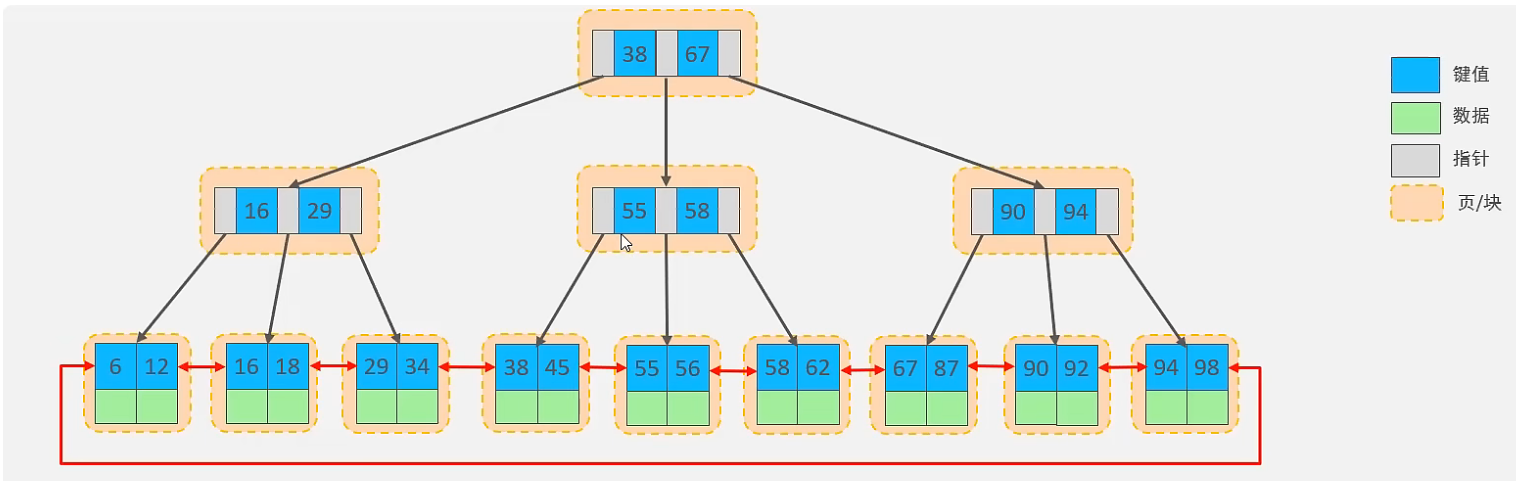
面试题:
为什么 InnoDB 存储引擎选择使用 B+Tree 索引结构?
- 相对于二叉树,层级更少,搜索效率高
- 对于 B-Tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针也跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低
- 相对于 Hash 索引,B+Tree 支持范围匹配及排序操作
Hash
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。
如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。
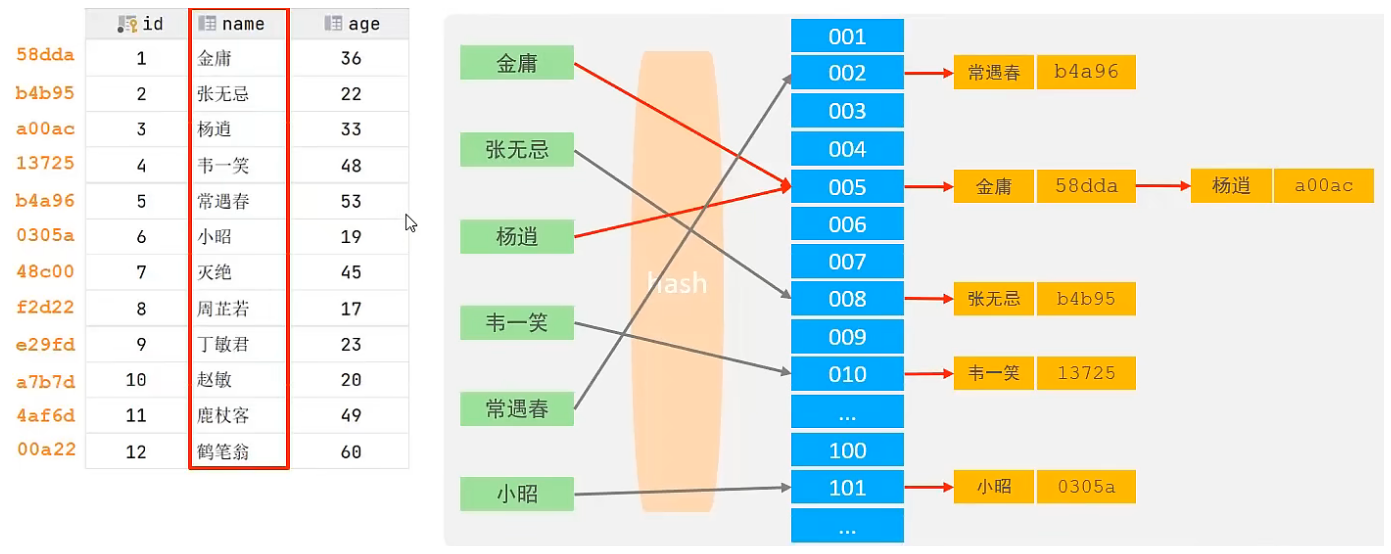
特点:
Hash索引只能用于对等比较(=、in),不支持范围查询(betwwn、>、<、…)
无法利用索引完成排序操作
查询效率高,通常只需要一次检索就可以了,效率通常要高于 B+Tree 索引
存储引擎支持:
- Memory
- InnoDB: 具有自适应hash功能,hash索引是存储引擎根据 B+Tree 索引在指定条件下自动构建的
索引类型
1.普通索引
2.唯一索引
3.主键索引
4.全文索引
5.组合索引
索引存储形式
在InnoDB存储引擎中,根据索引的存储形式又可以分为聚集索引、二级索引
聚集索引:将数据存储与索引放一块,索引结构的叶子节点保存了行数据。必须有,而且只能有一个
二级索引:也叫非聚集索引,将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键。可以存在多个
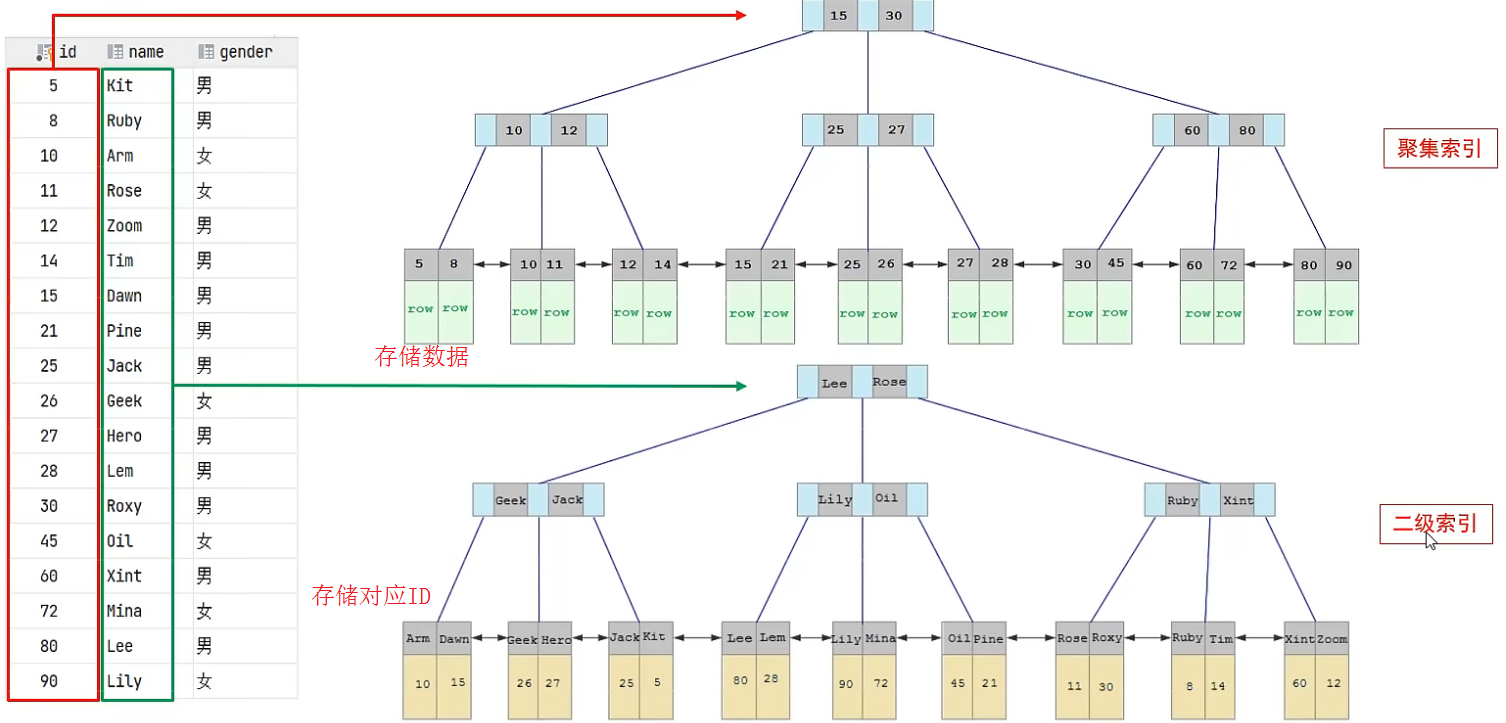
SELECT * FROM account WHERE name='fan'通过二级索引搜索,流程如下:
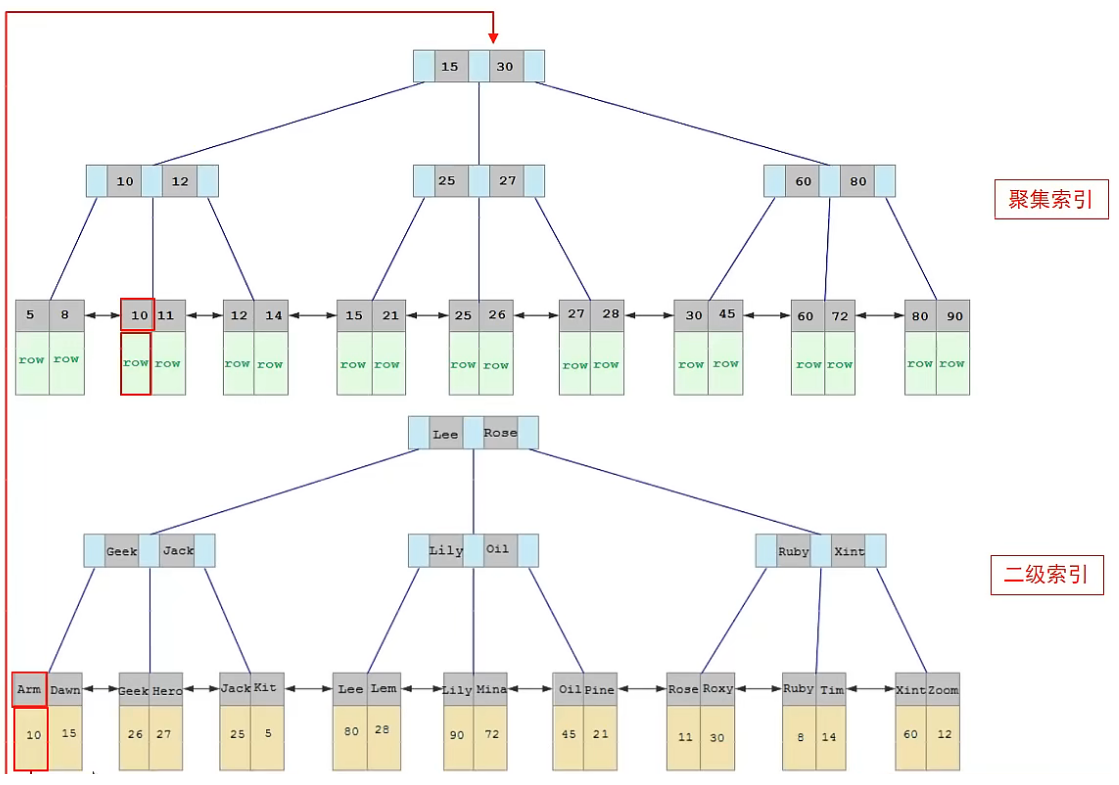
先通过name索引查找到对应行id,再通过行id查聚集索引
聚集索引选取规则
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引
- 如果表没有主键或没有合适的唯一索引,则 InnoDB 会自动生成一个 rowid 作为隐藏的聚集索引
索引语法
创建表的同时创建索引:
CREATE TABLE table_name[col_name data type]
[unique|fulltext][index|key][index_name](col_name[length])[asc|desc]
1.unique|fulltext为可选参数,分别表示唯一索引、全文索引
2.index和key为同义词,两者作用相同,用来指定创建索引
3.col_name为需要创建索引的字段列,该列必须从数据表中该定义的多个列中选择
4.index_name指定索引的名称,为可选参数,如果不指定,默认col_name为索引值
5.length为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度
6.asc或desc指定升序或降序的索引值存储
删除索引:
DROP INDEX [indexName] ON tableName
查看索引:
SHOW INDEX FROM tableName
普通索引
是最基本的索引,它没有任何限制。它有以下几种创建方式:
- 直接创建索引
CREATE INDEX index_name ON table(column(length))
- 修改表结构的方式创建索引
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
- 创建表的时候同时创建索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
PRIMARY KEY (`id`), -- 主键索引
INDEX index_name (title(length)) -- 普通索引
)
唯一索引
当给某个字段加了唯一约束,自动为这个字段创建唯一索引
与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
- 创建唯一索引
CREATE UNIQUE INDEX indexName ON tableName(columnName)
案例:
CREATE UNIQUE INDEX ix_UserName ON user_info(UserName)
- 修改表结构
ALTER TABLE table_name ADD UNIQUE indexName(columnName)
- 创建表的时候直接指定
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
UNIQUE indexName (title)
);
主键索引
是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引:
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) NOT NULL ,
PRIMARY KEY (`id`)
);
组合索引
指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合
ALTER TABLE `table` ADD INDEX name_city_age (name,city,age);
全文索引
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like。它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多。
- 创建表的适合添加全文索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
FULLTEXT (content)
);
- 修改表结构添加全文索引
ALTER TABLE article ADD FULLTEXT index_content(content)
- 直接创建索引
CREATE FULLTEXT INDEX index_content ON article(content)
- 全文索引查询
使用MATCH()和AGAINST()来执行全文搜索。以下是一个搜索包含单词"article"和"SQL"的例子:
-- 匹配任意一个关键词
SELECT * FROM articles
WHERE MATCH(title, body) AGAINST('article');
-- 匹配所有关键词
SELECT * FROM articles
WHERE MATCH(title, body) AGAINST('article SQL' IN BOOLEAN MODE);
使用布尔模式:
在布尔模式下,你可以使用更复杂的搜索条件,例如,使用+和-符号来强制要求包含或排除某些词:
SELECT * FROM articles
WHERE MATCH(title, body) AGAINST('+article -advanced' IN BOOLEAN MODE);
注意:默认情况下,MySQL对全文索引的最小词长度为4个字符,也就是说,短于4个字符的词将不会被索引。可以通过配置ft_min_word_len系统变量修改此设置。
前缀索引
当字段类型为字符串(varchar、text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时浪费大量的磁盘IO,影响查询效率。此时可以只将字符串一部分前缀建立索引,这样可以大大节约索引空间,提高检索效率
CREATE UNIQUE INDEX indexName ON tableName(columnName(length))
length表示前缀长度
其他
技巧和注意事项
- 不使用
not in,推荐使用NOT EXISTS
-- 原NOT IN查询
SELECT * FROM t1 WHERE phone NOT IN (SELECT phone FROM t2);
-- 优化为NOT EXISTS
SELECT * FROM t1 WHERE NOT EXISTS (SELECT 1 FROM t2 WHERE t2.phone = t1.phone);
方案2:使用LEFT JOIN + IS NULL
- 不使用
<>,建议改用>或<等可索引操作符
-- 原低效查询
SELECT * FROM employees WHERE salary <> 5000;
-- 改用范围查询(若适用)
SELECT * FROM employees WHERE salary > 5000 OR salary < 5000;
- 使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个char(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。 - 索引列排序
查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。 - like语句操作
一般情况下不推荐使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%”不会使用索引而like “aaa%”可以使用索引。 - 不要在列上进行运算
这将导致索引失效而进行全表扫描,例如SELECT * FROM table_name WHERE YEAR(column_name)<2017
哪些字段应该创建索引
主键(自动创建唯一索引)
频繁作为查询条件的字段
用于关联表的字段
排序字段
查询中统计或分组的字段

 浙公网安备 33010602011771号
浙公网安备 33010602011771号