ElasticSearch笔记-概念 & 原理
概述
目的是使全文检索变得简单,能够达到实时搜索,稳定,可靠,使用简单方便
- ES是一个基于Lucene构建的搜索引擎,隐藏了 Lucene 的复杂性。
- 分布式、易扩展、高可用、高实时的搜索与数据分析引擎
- 基于RESTful web接口
- 它用 Java 编写的
易扩展:指的是增加服务器节点,ES会分片再平衡,将部分分片自动移动到新服务器
应用场景
- 搜索:海量数据的查询
- 日志数据分析
- 实时数据分析
核心概念
- 倒排索引:将各个文档中的内容进行分词,形成词条。然后记录词条和数据的唯一标识(id)的对应关系,形成的产物称为倒排索引
- 索引(index):相当于数据库,它是分片的集合,每个分片就是一个lucene索引,lucene索引是segment的集合,segment是不可变的
- 映射(mapping):相当于关系型数据库中的表结构
每个表中字段的定义就叫mapping,如字段的数据类型、默认值、分析器、是否分析、是否索引等等 - 文档(document):相当于记录
- 类型(type):相当于数据表,es6开始不再支持多个type,默认type为_doc
索引不可变
落盘的es索引是不可变的,这里说的索引指的是segment
不需要锁。如果从来不需要更新一个索引,就不必担心多个程序同时尝试修改。
如何在保持不可变好处的同时更新倒排索引。答案是,使用多个索引。不是重写整个倒排索引,而是增加额外的索引反映最近的变化。每个倒排索引都可以按顺序查询,从最老的开始,最后把结果聚合。
那么更新和删除是如何进行的呢?
段是不可变的,所以文档既不能从旧的段中移除,旧的段也不能更新以反映文档最新的版本。相反,每一个提交点包括一个.del文件,包含了段上已经被删除的文档。当一个文档被删除,它实际上只是在.del文件中被标记为删除,依然可以匹配查询,但是最终返回之前会被从结果中删除。
文档的更新操作是类似的:当一个文档被更新,旧版本的文档被标记为删除,新版本的文档在新的段中索引。也许该文档的不同版本都会匹配一个查询,但是更老版本会从结果中删除。
节点和分片(Shard)
一个集群至少包含一个节点,而一个节点就是一个es进程,节点内可以有多个索引。
默认的如果你创建一个索引,那么这个索引会有5个分片构成,称为主分片,而每个分片又有一个副本,又称复制分片,这样就有10个分片。
实际上一个分片是一个Lucene索引,一个包含倒排索引的文件目录
分片的好处:允许我们水平切分/扩展容量;可在多个分片上进行分布式的、并行的操作,提高系统的性能和吞吐量。
副本的好处:高可用,一个主分片挂了,副本分片就顶上去;扩展搜索的并发能力、吞吐量。搜索可以在所有的副本上并行运行

需要注意的是,在业界有一个约定俗称的东西,单说一个单词shard一般指的是primary shard,而单说一个单词replica就是指的replica shard。
primary shard不能和replica shard在同一个节点上
原理
document索引过程
文档被索引的过程如上面所示,大致可以分为 内存缓冲区buffer、translog、filesystem cache、系统磁盘这几个部分,接下来我们梳理一下这个过程。
- 阶段1:
这个阶段很简单,一个document文档第一步会同时被写进内存缓冲区buffer和translog。 - 阶段2:
refresh:内存缓冲区的documents每隔一秒会被refresh(刷新)到filesystem cache中的一个新的segment中,segment就是索引的最小单位,此时segment将会被打开供检索。也就是说一旦文档被刷新到文件系统缓存中,其就能被检索使用了。这也是es近实时性(NRT)的关键。后面会详细介绍。 - 阶段3:
merge:每秒都会有新的segment生成,这将意味着用不了多久segment的数量就会爆炸,每个段都将十分消耗文件句柄、内存、和cpu资源。这将是系统无法忍受的,所以这时,我们急需将零散的segment进行合并。ES通过后台合并段解决这个问题。小段被合并成大段,再合并成更大的段。然后将新的segment打开供搜索,旧的segment删除。 - 阶段4:
flush:经过阶段3合并后新生成的更大的segment将会被flush到系统磁盘上。这样整个过程就完成了。但是这里留一个包袱就是flush的时机。在后面介绍translog的时候会介绍。
路由
当你索引一个文档,它被存储在单独一个主分片上。Elasticsearch是如何知道文档属于哪个分片的呢?
shard = hash(routing) % number_of_primary_shards
它根据以上算法决定:
routing值是一个任意字符串,它默认是 _id 但也可以自定义。这个 routing 字符串通过哈 希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远 是 0 到 number_of_primary_shards - 1 ,这个数字就是特定文档所在的分片。
这也解释了为什么主分片的数量只能在创建索引时定义且不能修改:如果主分片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
增删改过程分析
新建、索引和删除请求都是写(write)操作,它们必须在primary shard上成功完成才能复制到相关的replica shard分片上。
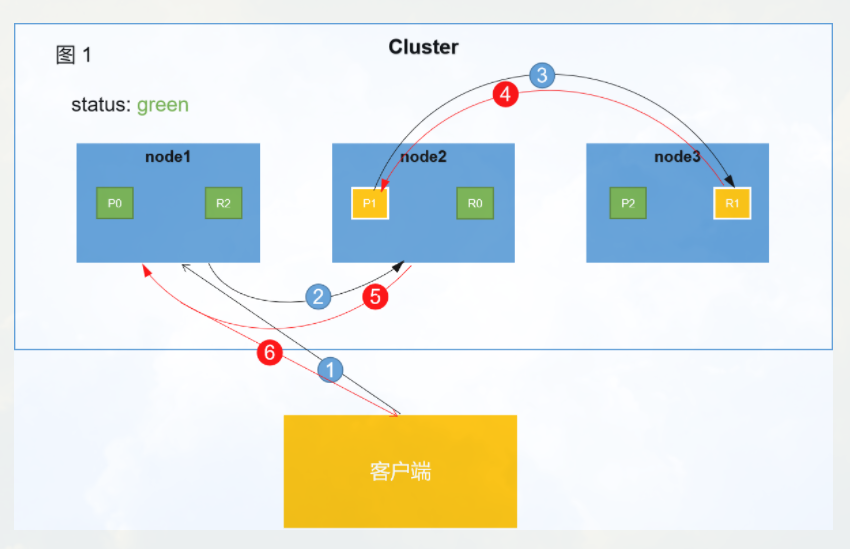
如上图所示,从客户端发起请求到es集群向客户端响应大致可以分为以上6个阶段。
- 阶段1:
客户端向node1发起增、删、改请请求。node1将作为协调节点(coordinate node)进行相关工作。 - 阶段2:
node1根据文档 _id 计算出命中的primary shard为P1,然后将请求转发到node2,P1分片位于node2上面。 - 阶段3:
node2在P1上处理该请求。如果请求处理成功,node2将会把请求继续转发到其副本R1上。R1位于node3。 - 阶段4:
node3在R1上处理完该请求,如果成功,node3会将处理成功的消息返回给node2。 - 阶段5:
node2收到P1副本处理成功的消息,也就意味着该请求已经处理完成。然后将处理结果返回给node1节点。 - 阶段6:
协调节点node1收到响应结果后,将该结果返回给客户端。
检索过程分析
- 阶段1:
客户端向node1发送检索请求。node1将作为协调节点(coordinate node)进行相关工作。 - 阶段2:
node1根据文档 _id 计算出命中的primary shard为P1,node1会找到P1的所有副本,然后通过round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡。假如此时随机选取的是P1,node1会将该请求转发到P1对应的节点上。 - 阶段3:
P1处理完该请求将结果返回给协调节点node1。 - 阶段4:
协调节点node1收到该node2的相应结果,进而将该结果返回给客户端。
集群管理
集群的健康值状态
Green:所有primary和Replica均为active,集群健康
Yellow:至少有一个replica不可用,但是所有primary均为active,数据仍然可以保证完整性
Red:至少有一个primary不可用,数据不完整,集群不可用
参考:
https://www.cnblogs.com/hello-shf/category/1550315.html (原理)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号