Python中的解决中文字符编码的问题
python3中str默认为Unicode的编码格式
python2中str默认为bytes类型的编码格式
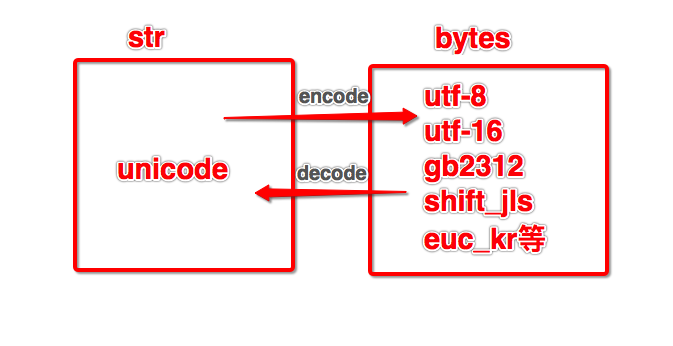
Unicode是一32位编码格式,不适合用来传输和存储,所以必须转换成utf-8,gbk等等
所以在Python3中必须将str类型转换成bytes类型的
在Python中使用encode的方式可以进行字符的编码
实际用法:
>>>a = "中国"
>>> a.encode("utf-8")
b'\xe4\xb8\xad\xe5\x9b\xbd'
>>> a.encode("gbk")
b'\xd6\xd0\xb9\xfa'

总结:
-
Python中str类型转bytes类型,相当与Unicode转gbk,utf-8。。。类型
-
b'代表字符编码格式为bytes,
-
utf-8默认24位占3个8位16进制数
-
gbk中国编码默认占16位2个8位16进制数字

 浙公网安备 33010602011771号
浙公网安备 33010602011771号