豆瓣数据爬取项目——软件系统设计方案解决
一、概述
这篇文章主要是针对一个对于豆瓣的电影数据进行爬取的爬虫程序,将进行软件系统的分析和设计,阐述使用的设计模式、软件架构风格与策略,并采用视图来描述软件系统的模型。进行数据库和核心数据结构的设计分析,最终形成软件系统概念原型。
对于豆瓣爬虫,what shold we 考虑?怎么分析呢?豆瓣电影首页
这个首先的话尝试就可以啦,打开任意一部电影,这里以姜子牙为例。打开姜子牙你就会发现它是非动态渲染的页面,也就是传统的渲染方式,直接请求这个url即可获取数据。但是翻着翻着页面你就会发现:未登录用户只能访问优先的界面,登录的用户才能有权限去访问后面的页面。
所以这个流程应该是 登录——> 爬虫——>存储——>可视化分析。
当然这只是举例说明该爬虫项目的大概流程设计,经过具体完整项目设计方案,落实到具体项目里。
二、项目设计方案
1.系统架构
架构模式是一个通用的、可重用的解决方案,用于在给定上下文中的软件体系结构中经常出现的问题。架构模式与软件设计模式类似,但具有更广泛的范围。
模型-视图-控制器模式,也称为MVC模式(Model View Controller)。用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,
不需要重新编写业务逻辑。MVC被独特的发展起来用于映射传统的输入、处理和输出功能在一个逻辑的图形化用户界面的结构中。它把软件系统分为三个基本部分:
模型(Model):负责存储系统的中心数据。
视图(View):将信息显示给用户(可以定义多个视图)。
控制器(Controller):处理用户输入的信息。负责从视图读取数据,控制用户输入,并向模型发送数据,是应用程序中处理用户交互的部分。负责管理与用户交互交互控制。
视图和控制器共同构成了用户接口。
且每个视图都有一个相关的控制器组件。控制器接受输入,通常作为将鼠标移动、鼠标按钮的活动或键盘输入编码的时间。时间被翻译成模型或试图的服务器请求。用户仅仅通过控制器与系统交互。

2.分解视图
分解是构建软件架构模型的关键步骤,分解视图也是描述软件架构模型的关键视图,一般分解视图呈现为较为明晰的分解结构(breakdown structure)特点。分解视图用软件模块勾划出系统结构,
往往会通过不同抽象层级的软件模块形成层次化的结构。由于前述分解方法中已经明确呈现出了分解视图的特征,我们这里简要了解一下分解视图中常见的软件模块术语。
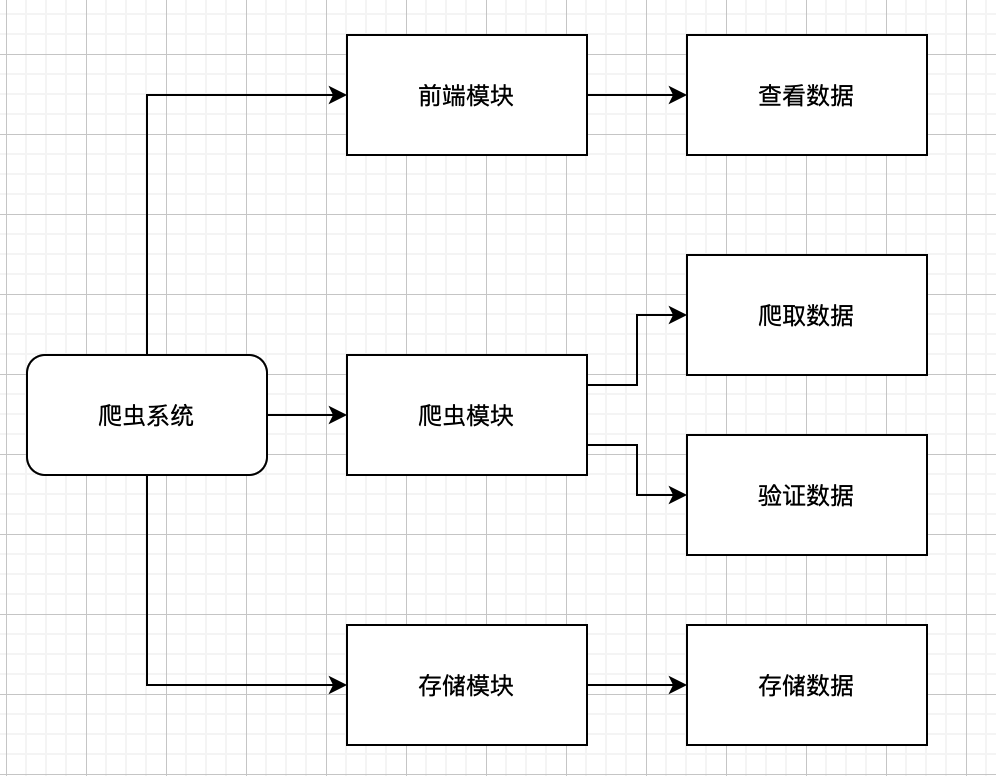
1) 用requests模块向豆瓣网发起GET请求,获得网页返回的信息;
2) 把上一步返回的信息用BeautifulSoup模块进行分析,如果还需要进一步匹配过滤,传给re模块进一步加工,否则直接传给MySQLdb模块;
3) re模块对BeautifulSoup传过来的信息进行匹配处理,最后传给MySQLdb;
4) 用MySQLdb连接mysql数据库,将获得的书籍信息持久化到mysql中;
5) 用logging模块负责系统日志的输出和维护。
(图片来源网络)
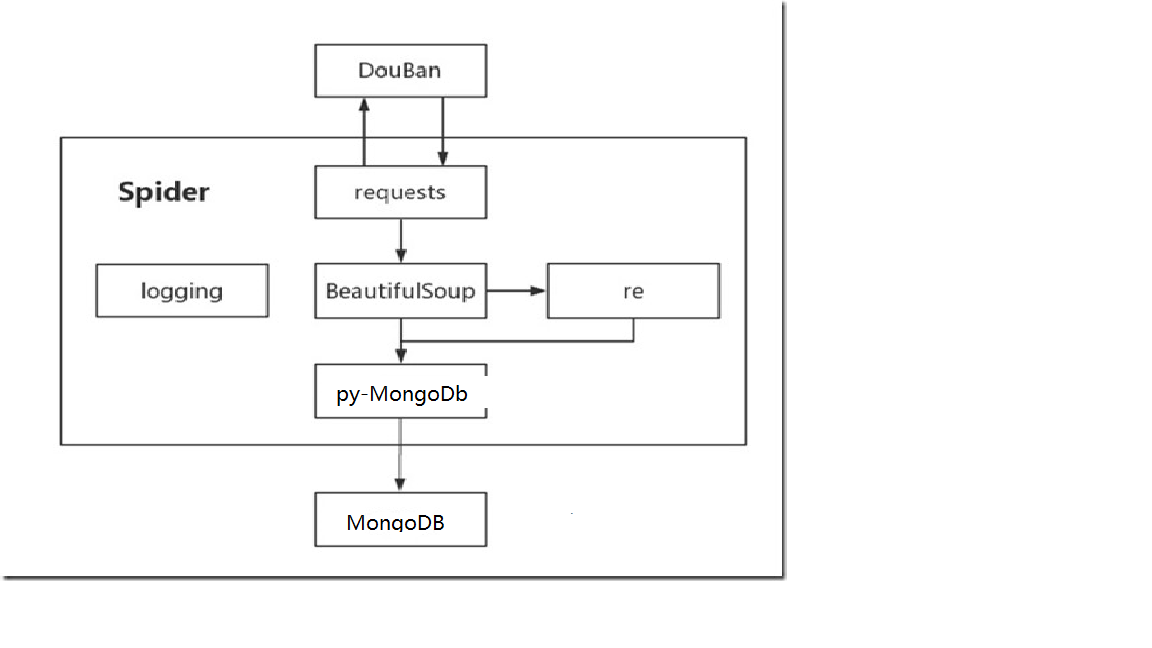
3.依赖视图
依赖视图展现了软件模块之间的依赖关系。比如一个软件模块A调用了另一个软件模块B,那么我们说软件模块A直接依赖软件模块B。如果一个软件模块依赖另一个软件模块产生的数据,
那么这两个软件模块也具有一定的依赖关系。
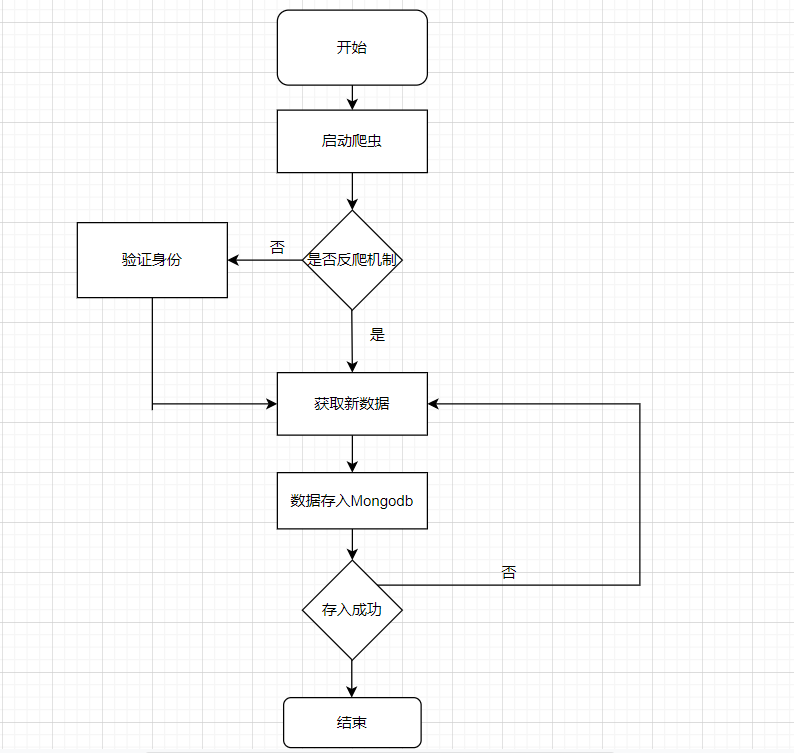
4.执行视图
执行视图展示了系统运行时的时序结构特点,比如流程图、时序图等。执行视图中的每一个执行实体,一般称为组件(Component),都是不同于其他组件的执行实体。如果有相同或相似的执行实体那么就把它们
合并成一个。
执行实体可以最终分解到软件的基本元素和软件的基本结构,因而与软件代码具有比较直接的映射关系。在设计与实现过程中,我们一般将执行视图转换为伪代码之后,再进一步转换为实现代码。
5.工作分配视图
工作分配视图将系统分解成可独立完成的工作任务,以便分配给各项目团队和成员。工作分配视图有利于跟踪不同项目团队和成员的工作任务的进度,也有利于在个项目团队和成员之间合理地分配和调整项目资源,甚至在项目计划阶段工作分配视图对于进度规划、项目评估和经费预算都能起到有益的作用。

6.用例图
在开发体系结构时,用例图可以帮助设计者找到体系结构的构件和它们之间的作用关系。可以用用例图来分析一个特定的视图,或描述不同视图构件间是如何相互作用的。

7.实现视图
实现视图是描述软件架构与源文件之间的映射关系。一般我们通过目录和源文件的命名来对应软件架构中的包、类等静态结构单元,然后由软件项目的源文件目录树来呈现典型的实现视图。
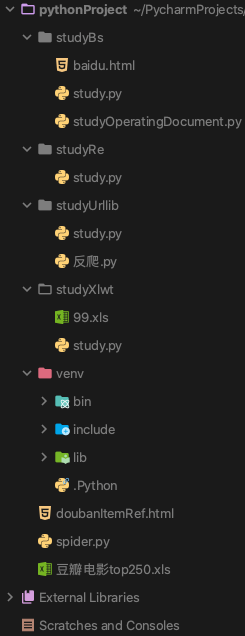
(该项目由项目组四名成员共同完成)
三、概念原型与核心工作机制
1.概念原型的核心工作机制
概念是人对能代表某种事物或发展过程的特点及意义所形成的思维结论,概念原型是一种虚拟化的、理想化的软件产品形式。也就是说,概念原型 = 用例 + 数据模型。
软件架构代表了软件系统的整体设计结构,它应该是所有这些视图的集合。但我们不会将不同角度的这些视图整合起来,因为不便于阅读和更新。不过我们会有意识地将不同角度的
视图之间的映射关系和重叠部分了然于胸,从而深刻理解软件架构内在的一致性和完整性,这就是系统概念原型。
因此基于以上分析和建模,我们就可以总结出此项目的概念原型,同时对此概念模型的工作过程进行分析。
通过之前的分析与设计可以总结出项目的概念原型工作过程:用python编写爬虫,绕过反爬身份验证,在爬取过程中线程并行执行爬取豆瓣上的电影信息。数据爬取完就要考虑存储,我们将数据暂时储存到cvs中,并持久化到Mongodb数据库。最后将数据库中信息分类创建前端展示页面,最终向用户呈现出豆瓣电影排行分类等信息。
2.软件系统运行环境和技术选型说明
软件系统主要运行在WINDOWS 10平台上
需要环境:python、python IDE(Pycharm)、cmd命令行开发工具、Mongodb数据库、http-server、flask-mongo
使用python语言作为项目的主要语言。基于Scrapy库实现爬虫的爬取,旨在快速、便捷的实现一个有一定并发量的爬取数据部分。数据存储部分则使用MongoDB非关系型数据库来存储获得到的数据。实现前后端的分离操作。前端展示主要利用Flask-Mongo框架,搭载简单的前端html页面,展示爬取后存入Monodb数据库中的内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号