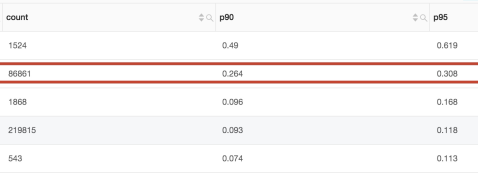
p90, p95 突然升高了 100ms问题排查过程
top -H 查询机器的cpu内存消耗情况,发现有一个Java进程的 cpu 利用率达到了 99%, 也就是说 跑满了一个 核心, 线上配置为 4核32G, 相当于直接消耗了 四分之一的性能,感觉已经定位到了这个原因了。
其中有一个 进程 跑到了 99.9%
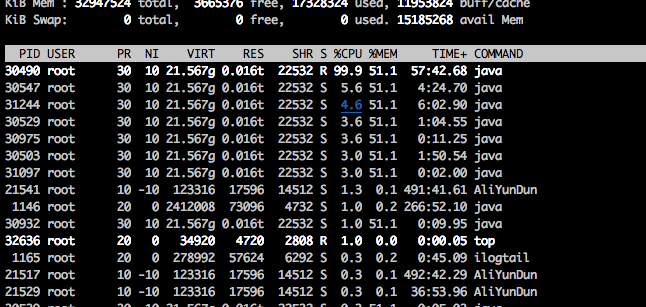
继续追下去,刚开始以为这个线程是业务线程, 使用 jps 查出 主进程号码。
之后使用 jstack pid | grep "cpu 99% 进程好的 16进制"
竟然发现这个线程是 g1 的垃圾收集器线程。
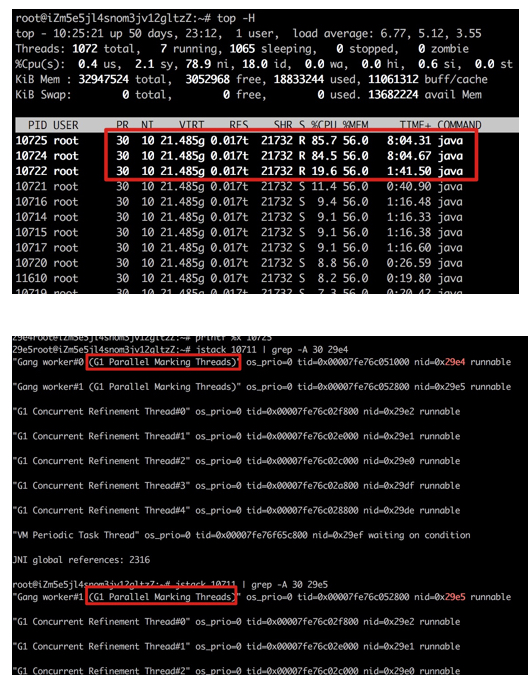
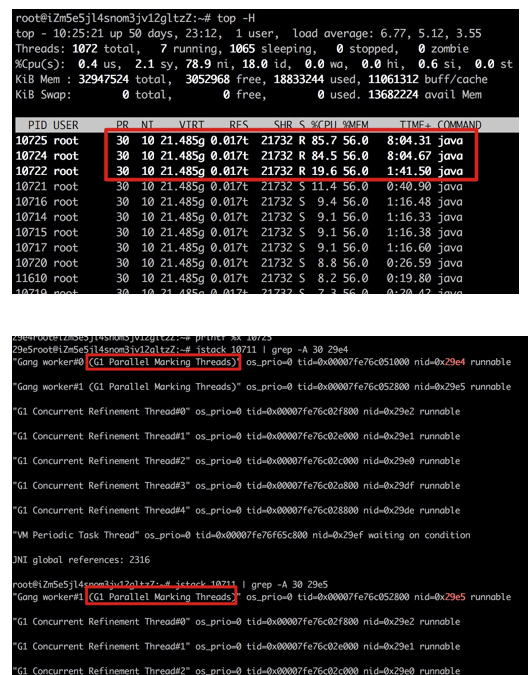
使用 jstack 查询 jvm 垃圾收集情况, 大概 10s 进行一次 young gc
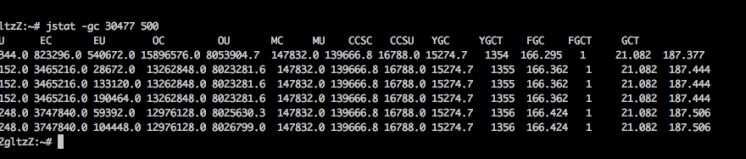
查看线程垃圾回收的日志信息,发现了一个很诡异的情况:

GC pause 很严重, 高的竟然有 1s 多,而这个阶段是 stw 的,所以这个情况很不正常
含义参考:

最后发现 在 3月27号,算法组 新上了一个模型, 该模型 大概 2G, 并且不能回收, 默认 g1 预留 30% 作为 担保分区, 所以在不停的 ygc 但是确没有回收任何的对象,从而造成了 jvm 的阻塞延长,从而拉低了服务的 p90.
解决方案, 减小 jvm G1ReservePercent 预留空间 到 15%, 或者增大堆内存, 同时做了实验,发现都是有效的 , cpu 利用率低了很多.
再出现这种情况以前,平时 20% , 到增加到 40%, 修复之后,cpu利用率也降低到了 20% p90, p95 也回落了下来。
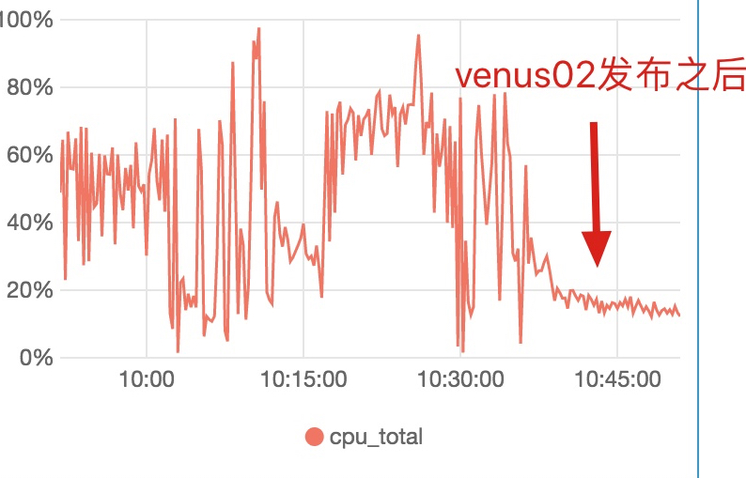
发布后cpu 利用率图:
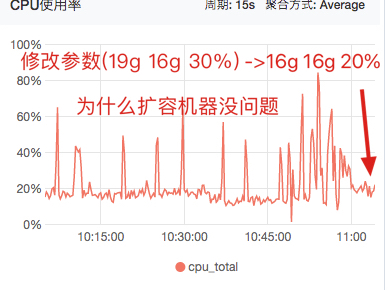
进一步实验
直接修改线上机器JVM参数,并做比较
实验1: 使用 venus01
实验:"-Xmx19g -Xms16g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=30 -XX:ConcGCThreads=2 -XX:MaxGCPauseMillis=500"
对照:-Xmx16g -Xms16g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=20
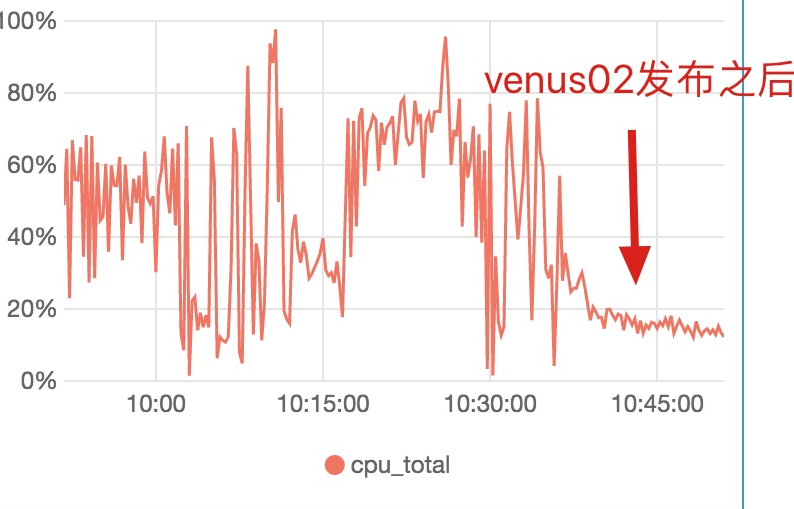
实验2:使用venus02
实验:-Xmx16g -Xms16g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=30
对照:GC_PARAM="-Xmx20g -Xms16g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=30 -XX:ConcGCThreads=2 -XX:MaxGCPauseMillis=500"
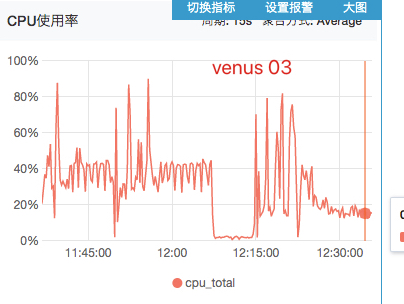
实验3:使用venus03
实验:-Xmx16g -Xms16g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=30
对照:"-Xmx20g -Xms20g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=20 -XX:ConcGCThreads=2 -XX:MaxGCPauseMillis=500"
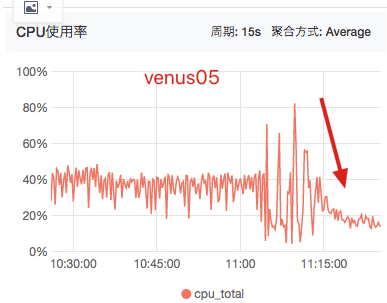
实验4:使用机器05
实验:-Xmx16g -Xms16g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=30
对照:-Xmx20g -Xms20g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=20
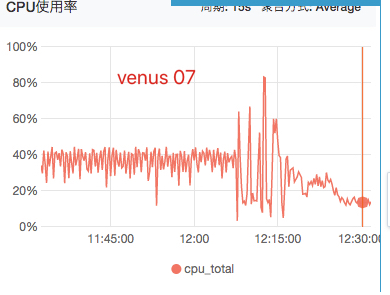
实验5:使用机器07
实验:"-Xmx16g -Xms16g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=30"
对照:"-Xmx20g -Xms20g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=30"
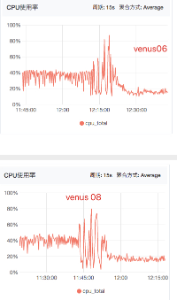
实验6:使用机器6,8,9
实验:"-Xmx16g -Xms16g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=30"
对照:"-Xmx20g -Xms20g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=20 -XX:ConcGCThreads=2 -XX:MaxGCPauseMillis=500"
实验7:使用机器1,4
venus04:-Xmx22g -Xms22g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=20 -XX:ConcGCThreads=2 -XX:MaxGCPauseMillis=500
venus01:-Xmx22g -Xms22g -XX:G1HeapRegionSize=2m -XX:G1ReservePercent=30 -XX:ConcGCThreads=2 -XX:MaxGCPauseMillis=500
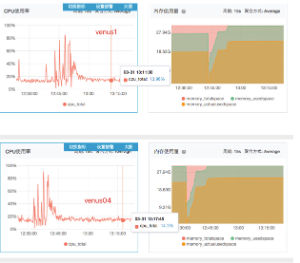
结论:
堆预留空间


 浙公网安备 33010602011771号
浙公网安备 33010602011771号