常用项目方案总结
前言
在系统中经常存在一些 需要经过一定的计算/存储在某些较为昂贵的存储介质 才能得到的数据集,并且该数据集在一定时间内可以保持不变,或者说业务上对该数据的时效性不是那么的敏感,但是却对性能很敏感,
这时候我们就可以使用 JVM 的本地缓存来实现。
思考:
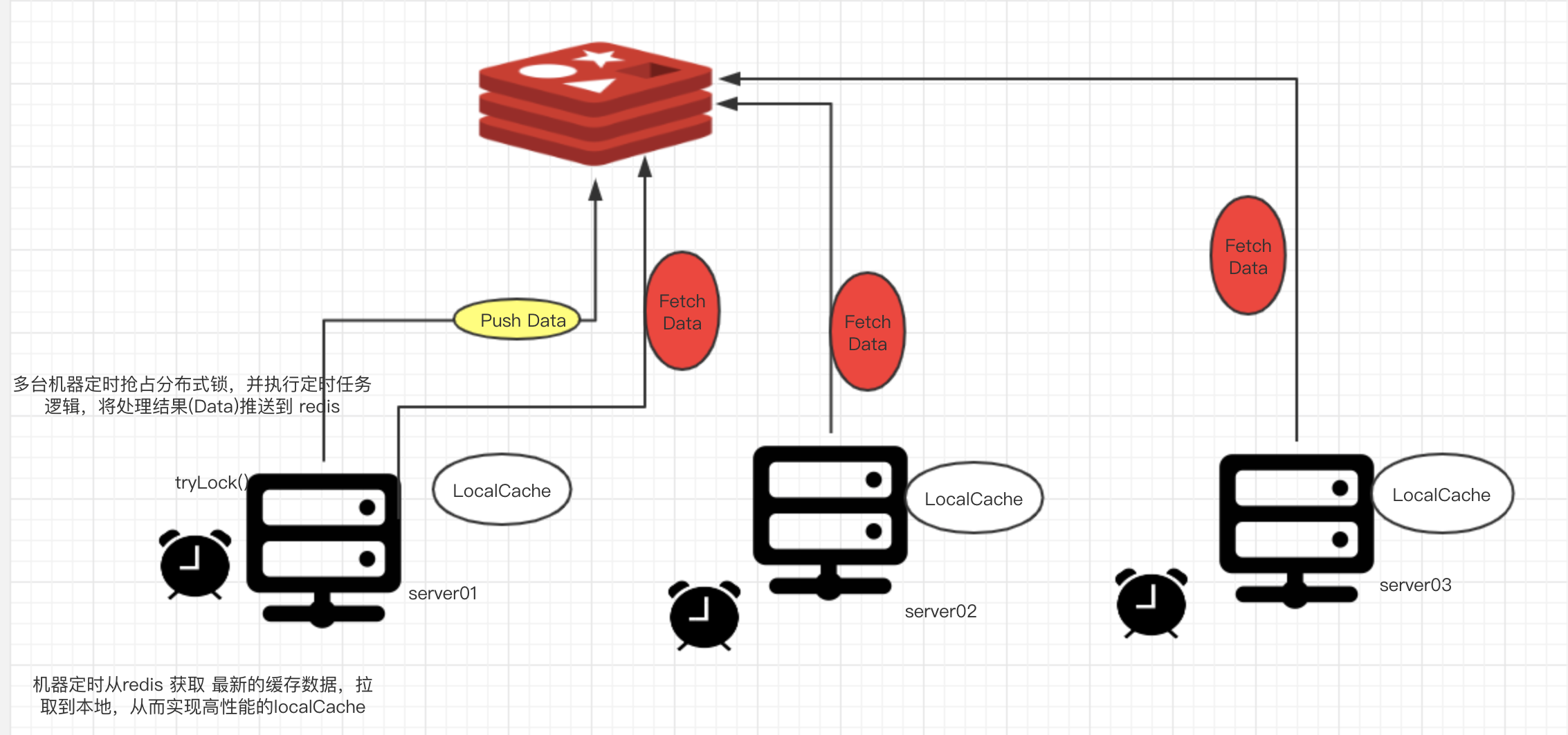
由于获取 该数据集 的成本较高(1. 需要经过复杂的计算;2.需要从其他较为昂贵的地方获取【例如 阿里云的 ots, 是 按照 CU 收费】), 并且系统中一般都是部署了多台机器,几十台甚至几百台机器,由于
每一台机器都需要缓存该数据,不可能每台机器都去 计算/拉取 数据集,然后缓存,大量的重复计算增加了系统的负载,并且这些计算都是重复的,没有必要的。为了不重复计算,我们可以让一台机器进行计算,然后推送至 redis
之后 其他机器 定时去 redis 拉取 数据集,在本地执行数据替换操作即可。
实现方式:
考虑该模式的 关键点 1.一台机器定时计算推送至redis;2. 其他机器定时拉取;
我们可以使用 争抢分布式 的方式来实现 关键点1;使用guava 的 LoadingCache 实现 关键点2;
模版代码如下;
// 定时刷新缓存,去redis 拉取最新内容
public final LoadingCache<String, Map<Integer, Set<Integer>>> localCache = CacheBuilder.newBuilder()
.refreshAfterWrite(30, TimeUnit.MINUTES).build(new CacheLoader<String, Map<Integer, Set<Integer>>() {
@Override
public Map<Integer, Set<Integer>> load(String s) throws Exception {
try {
Object cacheInfo = redisCacheUtil.get(cacheKey);
if (cacheInfo != null) {
return (Map<Integer, Set<Integer>>) cacheInfo;
}
} catch (Exception e) {
log.error("redis data structure is wrong.", e);
}
return Maps.newHashMap();
}
});
// 定时去争抢分布式锁,争抢到之后 执行复杂计算,获取数据集 推送至 redis 供其他机器拉取数据集
@Scheduled(cron = "0 0 0/3 * * ?")
public void Schedule(){
RLock lock = redissonClient.getLock(cacheKey);
if(lock.tryLock()) {
try {
Map<Integer, Set<Integer>> cacheMap = Maps.newHashMap();
// 去数据库加载数据
loadDbInfo(cacheMap);
// 去 ots 加载数据
loadOtsInfo(cacheMap);
// 执行复杂逻辑计算
complexComputeInfo(cacheMap);
// 将数据源 推送至 redis
redisCacheUtil.set(cacheKey, cacheMap, 12 * 60 * 60);
} finally {
lock.unlock();
}
}
}
注意点:
由于使用的 jvm 缓存,所以注意缓存的数据量不要太大,尽量不要超过 5 M。 尽量只缓存一些业务唯一主键,具体的内容可以再去补全即可;
定时计算和 LoadingCache 定时拉取 要注意时间的间隔问题,尽量把推送到 redis 远端的数据缓存时间设的长一点,避免因为本地计算延迟导致 拉取不到缓存数据,导致业务出错;
本地定时计算推送到远端的服务 要进行设置报警策略,当计算没有获取到数据或者计算异常的时候 发邮件/发短信 进行及时告警;
不一定只使用一台机器进行计算,对于要求较为精确的数据集,可以使用多台机器计算,本地拉取的时候进行两结果对照,对不一致的数据进行及时告警,联系相关人员排查;
图例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号