正则表达式
正则创建的两种方式:
1.字面量var pattern=//; 一般都用字面量方法,简单直接;

2. 构造函数var pattern=new RegExp();里面可接受两个参数,第一个是将要匹配的字符,第二是修饰符i;优势:可以用变量动态添加参数

三种模式修饰符:
i:不区分大小写,
g全局匹配,
m多行匹配
\n表示换行,多行匹配必须有一个全局匹配,没有m,只有g,系统则不会看见换行,只有一行
正则操作字符串方法:
pattern.test(str); 返回true/false,是否含有匹配的值

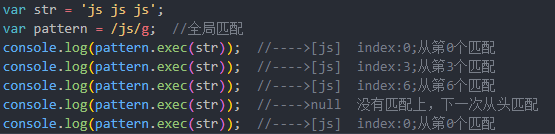
patter.exec(str) 将匹配的值,放入数组并返回,没找到返回null
非全局匹配下,exec()始终匹配第一个
全局匹配下,exec()也只是匹配一个,多次执行exec()会依次匹配项对应的值,直到null停止,再执行exec()又会从头执行
字符串操作正则的方法:
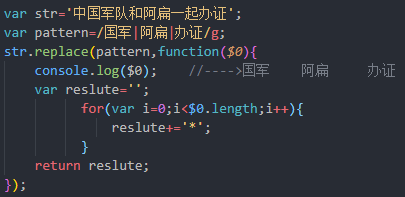
str.replace(pattern,替换的代码)
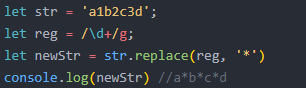
特殊点1:用$1来代替分组的内容,可在替换中设置CSS样式
![]()
特殊点2: 不管有没有分组,$0就表示pattern里的内容,匿名函数的返回值就是替换的文本,也有两个参数function(all,letter){},all表示str的内容,letter表示匹配到的值
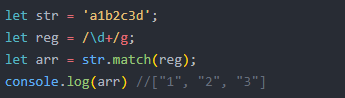
str.match(pattern); 不过找到一个或多个正则表达式的匹配时,会一次性返回一个数组
str.search(pattern); 仅仅只是返回匹配到的第一个下标,与是否有全局匹配无关,不存在返回-1
str.split(pattern); 将字符串转化为数组
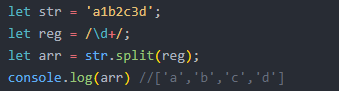
元字符:正则中有特殊含义的非字母字符
. * + ? $ ^ | \ () [] {}
1 . 匹配除了 \n \r \u2028或\u2029 以外所有的字符
2 * 0个或多个 + 至少1个 ?0个或1个
3 转义字符:反斜杠\
将特殊含义转化为字面量含义;
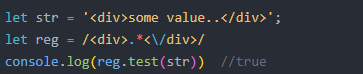
4 ^开头 $结尾

5 []字符集合,'或者'的含义 ; [^]取反
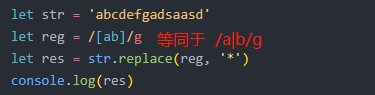
6 边界符: \b 非 \w(字母或数字或下划线)都被称为边界
7 分组 () ;
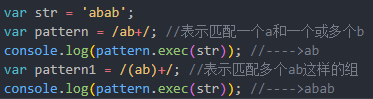
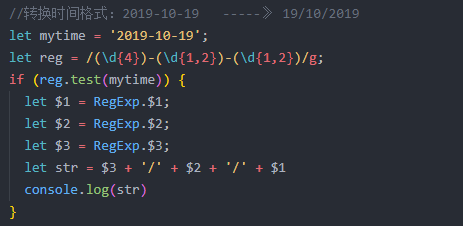
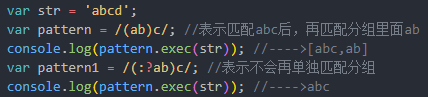
(?:)表示非捕获分组,不再单独匹配分组;
\1 \2

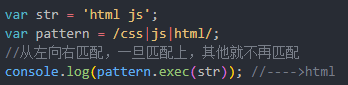
8 选择:| 也可以叫'或'
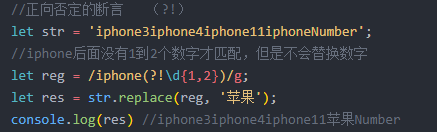
9 零宽断言:正向(后面) 负向(前面)

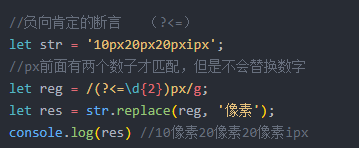
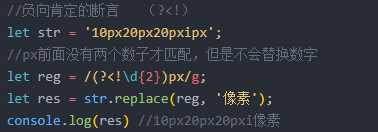
常用字符类:
/[a-z]/;在a~z的范围内匹配
/[\u4e00-\u9fa5]/;中文汉字匹配
/[a-zA-Z]/;同时在a~z大小写中匹配
/[a-zA-Z0-9]/; 可组合
常用字符类简写:
| \d | 匹配数字,相当于 /0-9/ |
| \D | 匹配非数字,相当于/^0-9/ |
| \w | 匹配字母或数字或下划线,不能匹配汉字,汉字:[\u4e00-\u9fa5] |
| \W | 匹配任意不是字母、数字、汉字或下划线的字符 |
| \s | 匹配任意的空白符,如空格、换行符、制表符等 |
| \S | 匹配任意不是空白符的字符 |
| .(号) | 匹配除了换行符以外的任意字符,大概就是匹配任意字符 |
| [] | 匹配方括号中的第一个字符 |
| [^] | 匹配非方括号中的所有字符的第一个 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号