Zookeeper初始(一)--未完待续
ZK是什么?
分布式服务框架,主要用来解决分布式应用中数据管理问题;如统一命名服务,集群管理,分布式应用配置管理等
zk是一个数据库,是一个拥有文件系统特点的数据库,是一个 解决了数据一致性问题的分布式数据库,是一个具有发布,订阅(watch)功能的分布式数据库
1.分布式一致性服务,最终一致性
CAP c一致性 a可用性 p分区容错性 ,cp
zookeeper在进行数据的同步时(C一致性 Leader-follower),不允许客户端读写,程序堵塞。
2.数据存储,基于文件系统
节点类型:
- 持久: 有序顺序递增(内部全局唯一节点)和无序,永久存储,存储在磁盘上
- 临时节点 :有序和无序,会话结束即删除节点,不能有子节点,存在冲突,当断开连接的时候临时节点会被删除 其他zk通过心跳维持连接
create -e -s /application/123 临时顺序节点
create -s 持久顺序节点
create 持久无序节点
数据在磁盘中的表示
树形结构: 每个节点是 key-vaLue
假设我们现在在Zookeeper中有一个数据节点,节点名为/datanode,内容为125,该节点是持久化节点,所以该节点信息会保存在文件中。
方法一:

方法二:快照+事务日志
当前快照:

当前事务日志:

Zookeeper集群中的节点在处理事务性请求时,需要将事务操作同步给其他节点,事务操作是一定要进行持久化的,以便在同步给其他节点时出现异常进行补偿。实际上事务日志还运行数据进行回滚,这个在两阶段提交中也是非常重要的。持久性节点存储在磁盘上每次查询需要IO操作,Zookeeper为了提高数据的查询速度,会在内存中也存储一份数据
数据在内存中的表示
Zookeeper中的数据在内存中的表示类似一颗树,必须以/开头,一颗具有父子层级的多叉树,在Zookeeper源码中叫DataTree:
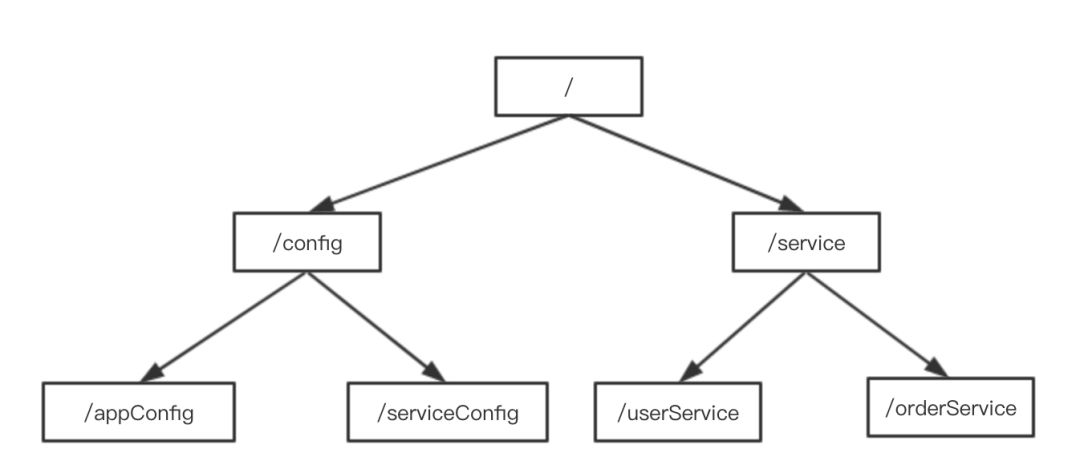
请求处理逻辑
请看下图:

请注意,对于上图,Zookeeper真正的底层实现,zk1是Leader,zk2和zk3是Learner,是根据领导者选举选出来的。
非事务性请求直接读取DataTree上的内容,DataTree是在内存中的,所以会非常快。
3.事件回调机制
client1创建节点 /lock/lock1,client2 创建/lock/lock2 监听/lock节点(父节点)
可以设置监听通知内容(比如节点删除通知,节点修改通知等)
当前节点父节点发生变化 会回调监听端

4.zk分布式锁
分布式锁解决?存在 1共享资源,2多任务环境 3共享资源互斥
排序,拿号 ,银行办业务(拿号顺序,1办完叫2 2完叫3)
client1创建 lock1,2创建lock2
lock2注册监听lock1事件,lock1删除节点回调lock2 (大节点监听小节点,小节点执行完删除自身节点通知大节点)

是否发生死锁?
不会,假如client1挂掉,没有心跳会自动删除临时节点删除节点的时候一样会通知监听他的那个节点
集群何时选取Leader?
- 集群启动时选择Leader(服务器启动)
- Leader挂掉时选举
- follower挂掉后Leader发现没有过半follower跟随自己-不能对外提供服务(领导者选举)
如何选举?
投票->改票->选票
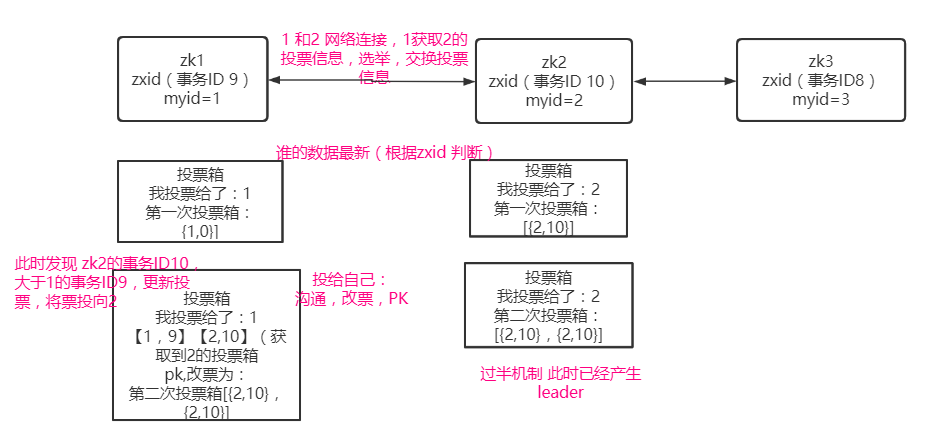
一致性?2PC机制,zk是保证CP
弱一致
强一致
最终一致
如何解决一致性问题?2PC机制
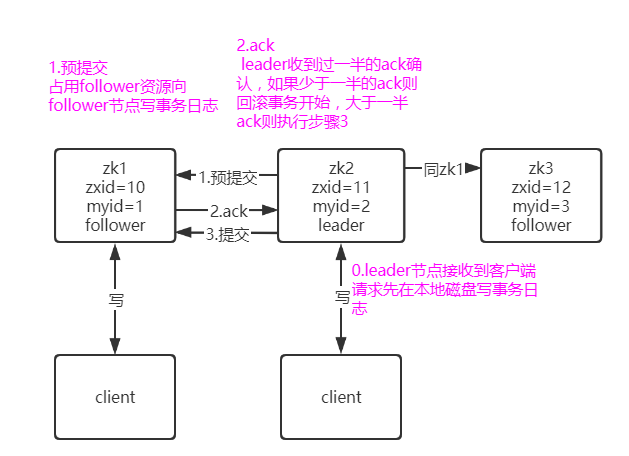
事务请求:事务性请求:create ,set ,deLete,update, 生成事务日志,zxid(自增的)
- 预提交占用follower资源(占用资源:其实是在follower节点上面写一条事务日志,事务日志先持久化到硬盘)
- 接收到大于一半的ack
- 提交:将磁盘内容读更新到内存的DataTree
事务请求,Leader 接受请求,然后将数据同步给其他节点,如果同步过程中异常,有一半(3个节点, 有一个成功)其他都异常则回滚改该请求,少于一半(3个节点, 有两个成功)则提交事务,整个集群挂掉,再次启动的时候 会主动同步数据
非事务性请求:get,exists,读请求是直接返回本节点数据
数据同步?启动时候同步数据
ZAB协议? 保证一致性
就是规定:如何领导选举,过半机制, 2pc的内容如何提交,数据同步等
问题?
过半机制当有一台已经收到ack ,另外响应慢怎么办?
过一半提交, 少于一半则回滚
当提交的时候是所有Folower都提交之后,Leader才提交吗?
Leader会把要发送的数据放到队列里面,循环follower节点从队列里面获取数据发送(线程异步发送),然后提交自己节点数据包,如果follower节点发送比较慢,不会影响最终Leader响应用户的速度(不会等待所有follower节点都执行成功,follower节点是异步执行的)
查看谁是Leader?
status
为什么是 >n/2 而不是>=haLf ?
public QuorumMaj(int n){
this.half = n/2;
}
担心有两个Leader
zk 保证的是CP机制
//followerSet 的数量
if (self.getQuorumVerifier().containsQuorum(followerSet)) {
}
public boolean containsQuorum(HashSet<Long> set){
//判断set的大小是否超过一半
//half 的计算逻辑?如果有7台机器,3台参与者,4台observer,怎么算过半
//QuorumPeerConfig->parseProperties
return (set.size() > half);
}
为什么是推荐奇数节点?
过半机制
5 台机器可以有2台挂掉
6台机器也可以有2台挂掉 那为什么要用6台呢?
zk有哪些节点:
- Leader节点
- follower机器越多:提高读性能,降低写性能(第一:选举Leader,每多一个follower都需要投票 ,第二:每个follower都需要发送ack请求)那怎么提高性能?使用观察者节点
- 观察者节点(obser):可以处理读写请求(写请求转发给Leader,读请求直接返回本节点数据),不参与Leader选举投票,提高读请求,不影响写请求性能
Leader是如何提交的,即如何submit?
- 发送follower提交请求(事务ID)将数据包发入到队列里面,有单独线程发送submit请求给follower
- 同步信息给观察者节点(是直接发送数据包)
- Leader节点提交
synchronized public void processAck(long sid, long zxid, SocketAddress followerAddr) { if ((zxid & 0xffffffffL) == 0) { /* * We no longer process NEWLEADER ack by this method. However, * the learner sends ack back to the leader after it gets UPTODATE * so we just ignore the message. */ return; } if (lastCommitted >= zxid) { // The proposal has already been committed return; } Proposal p = outstandingProposals.get(zxid); if (p == null) { LOG.warn("Trying to commit future proposal: zxid 0x{} from {}", Long.toHexString(zxid), followerAddr); return; } p.ackSet.add(sid); if (self.getQuorumVerifier().containsQuorum(p.ackSet)){ if (zxid != lastCommitted+1) { LOG.warn("Commiting zxid 0x{} from {} not first!", Long.toHexString(zxid), followerAddr); LOG.warn("First is 0x{}", Long.toHexString(lastCommitted + 1)); } outstandingProposals.remove(zxid); if (p.request != null) { toBeApplied.add(p); } if (p.request == null) { LOG.warn("Going to commmit null request for proposal: {}", p); } //follower 发送事务ID
//Follower 提交 所有follower 节点发送消息(将要发送的消息加入到了队列,这里并没有真正的 发送)
//异步发送(网络不好不影响 因为是异步,只是加入队列,后续通过线程发送)不影响leader的commit
//同步的是zxid
commit(zxid); //obser 直接发送数据包
//Observer 同步
//通 Follower 也是将消息加入到队列
// Observer 是直接同步的消息 提供读写性能
inform(p);
//leader 执行commit zk.commitProcessor.commit(p.request); if(pendingSyncs.containsKey(zxid)){ for(LearnerSyncRequest r: pendingSyncs.remove(zxid)) { sendSync(r); } } } }
//commit
public void commit(long zxid) {
synchronized(this){
lastCommitted = zxid;
}
org.apache.zookeeper.server.quorum.QuorumPacket qp = new org.apache.zookeeper.server.quorum.QuorumPacket(Leader.COMMIT, zxid, null, null);
sendPacket(qp);
}
//inform
public void inform(Proposal proposal) {
org.apache.zookeeper.server.quorum.QuorumPacket qp = new org.apache.zookeeper.server.quorum.QuorumPacket(Leader.INFORM, proposal.request.zxid,
proposal.packet.getData(), null);
sendObserverPacket(qp);
}
端口 默认2181
1.Leader-follower-observer
2.Leader选取 :?有哪些算法?
数据库默认持久化多次是时间
7天
既然是分布式,集群,一个请求只能有一台机器接接收并处理,其他机器如何同步消息?
数据同步怎么办?事务请求走Leader,非事务走所有节点,增删改由Leader节点处理,处理完同步到非Leader;使用了节点zab协议(原子广播协议):数据同步,Leader选取,原子广播。
Zookeeper集群中,(其他非leader节点接受到增删改请求时,将请求转发给leader节点)当某一个集群节点接收到一个写请求操作时,该节点需要将这个写请求操作发送给其他节点,以使其他节点同步执行这个写请求操作,从而达到各个节点上的数据保持一致,也就是数据一致性。我们通常说Zookeeper保证CAP理论中的CP就只这个意思。何为CAP
Zookeeper集群底层是怎么保证数据一致性的,用的两阶段提交+过半机制来保证的。
事务性请求包括:更新操作、新增操作、删除操作。
非事务性请求:查询操作。
zookeeper 应用:
1.分布式锁:(节点抢占,顺序节点)
- 节点抢占 :同级节点是唯一的(同时创建同一个节点,多个应用创建肯定只有一个成功)失败的节点怎么办?watcher:客户端可以监控某一个节点的变化
- 监听方式3中:get exists getchiLdren 设置监控: get /mic true 对mic 节点监控 监控删除事件如 app2可以watcher app1新建的节点事件,如果app1新建的节点有修改会给所有监控对象app2,app3发通知(只触发一次,如果失败则丢掉事件)会发生 惊群问题?会触发所有节点
- 顺序节点:创建顺序节点,最小节点获取锁 1 2 3 ;2监控1 3监控2 ,每个节点监控上一个节点

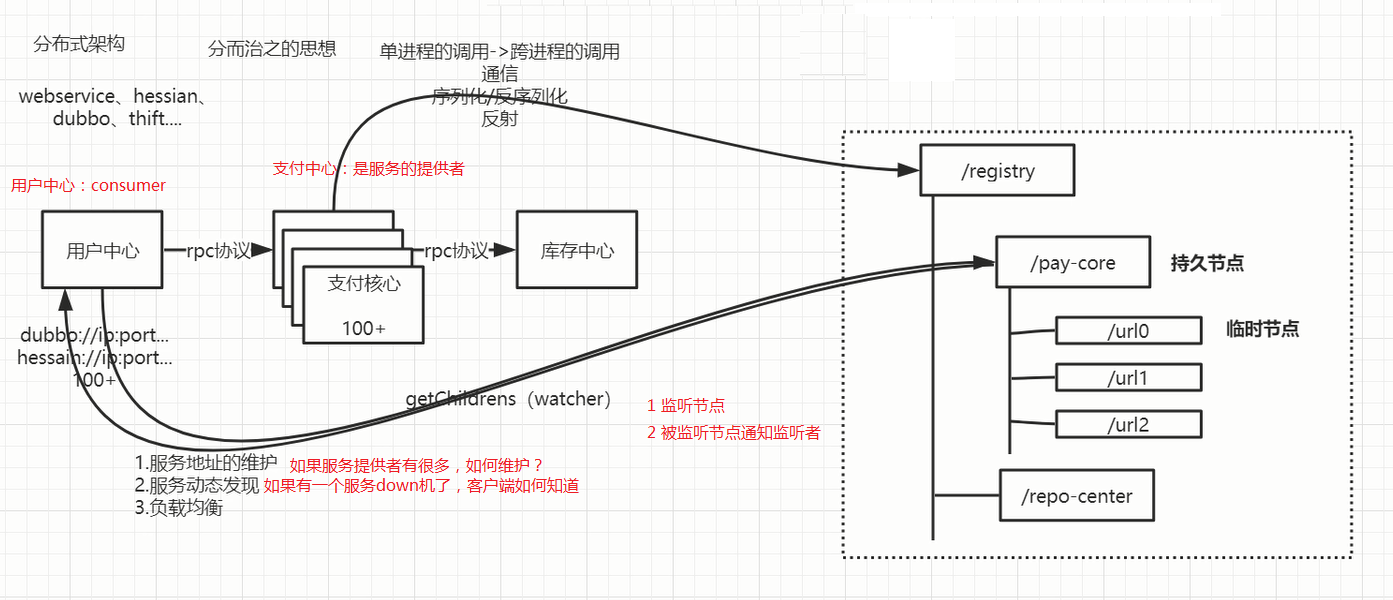
2.服务注册:
各个服务通信:rpc协议远程过程服务调用rpc 协议有 hession,dubbo,webservice 框架,服务直接通信用到:序列化/反序列化,反射
ZAB协议
1.消息广播
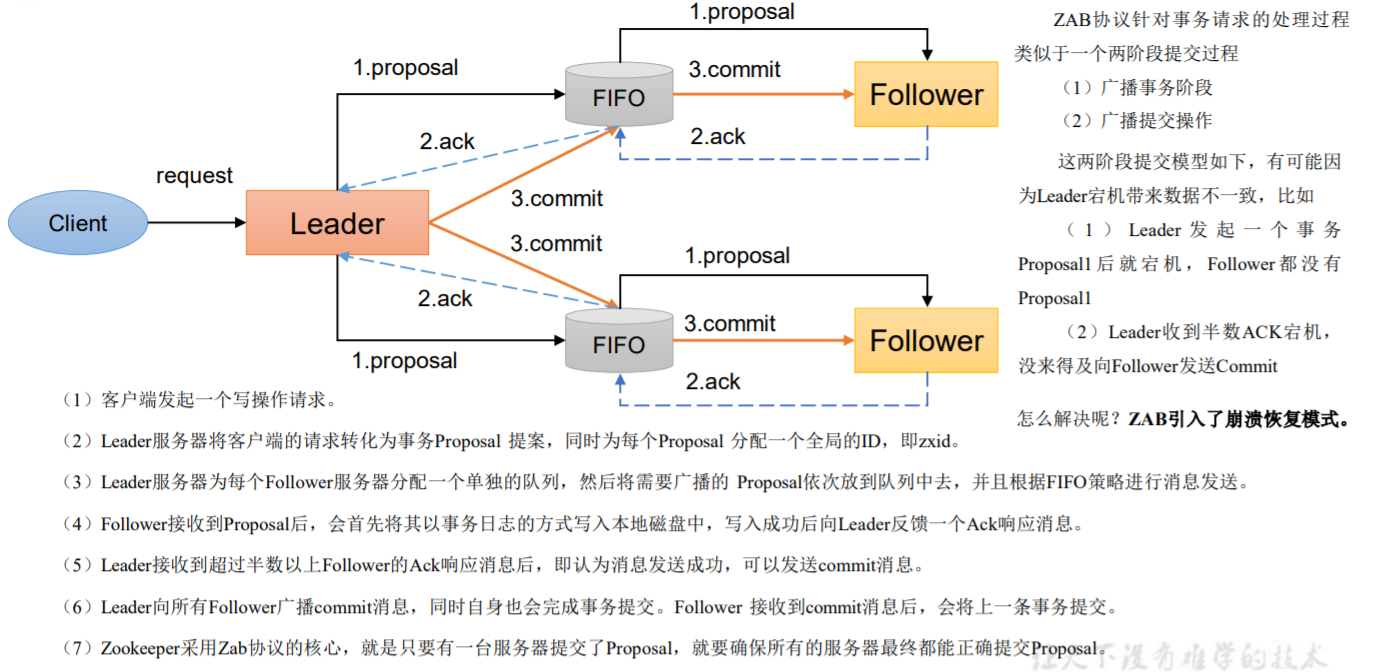
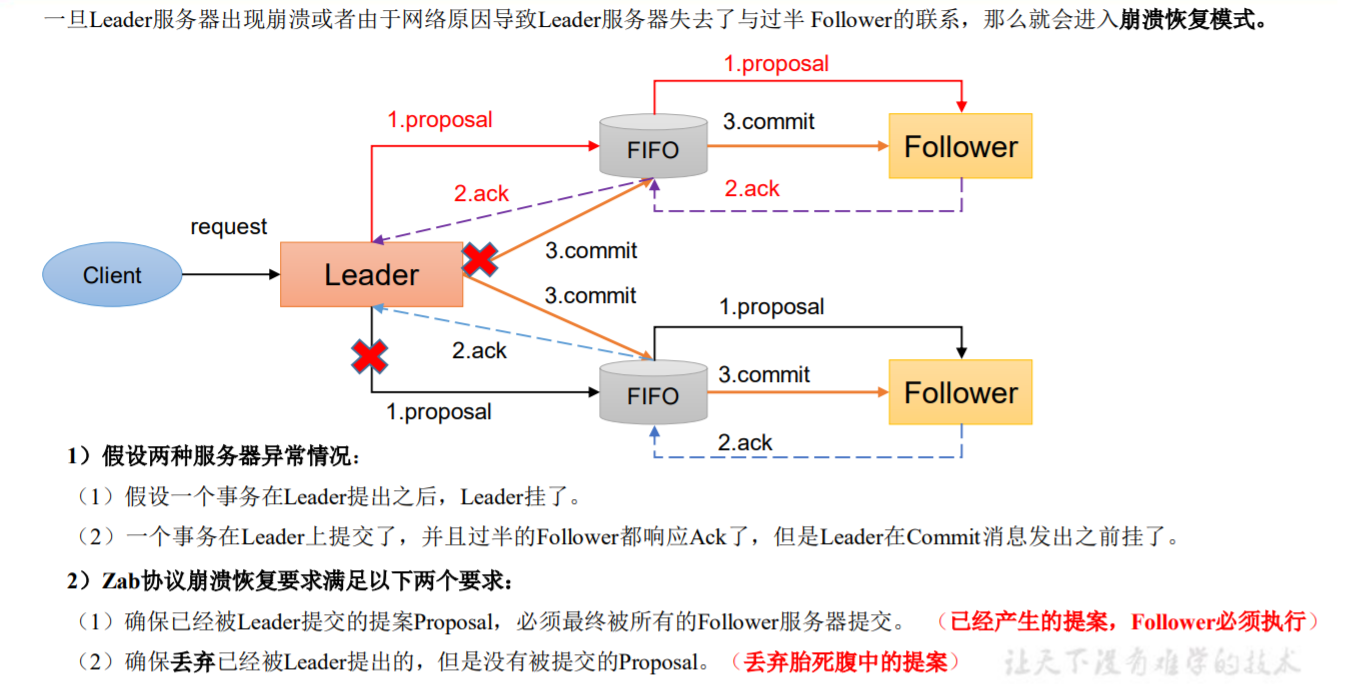
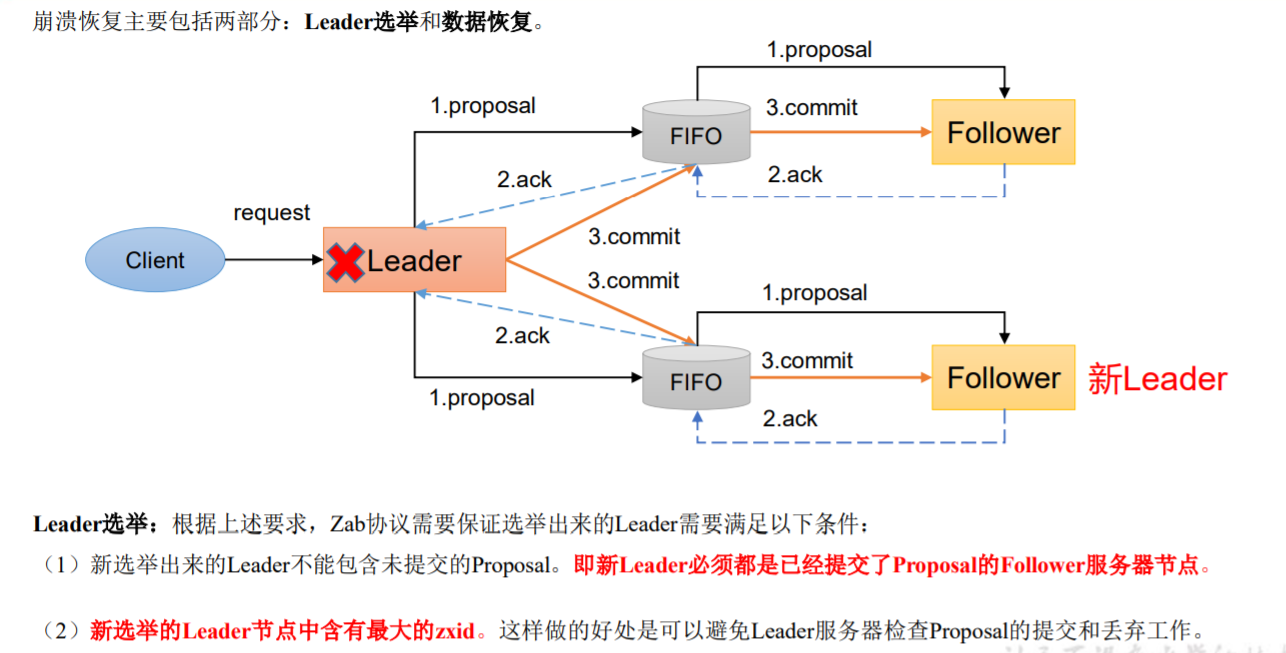
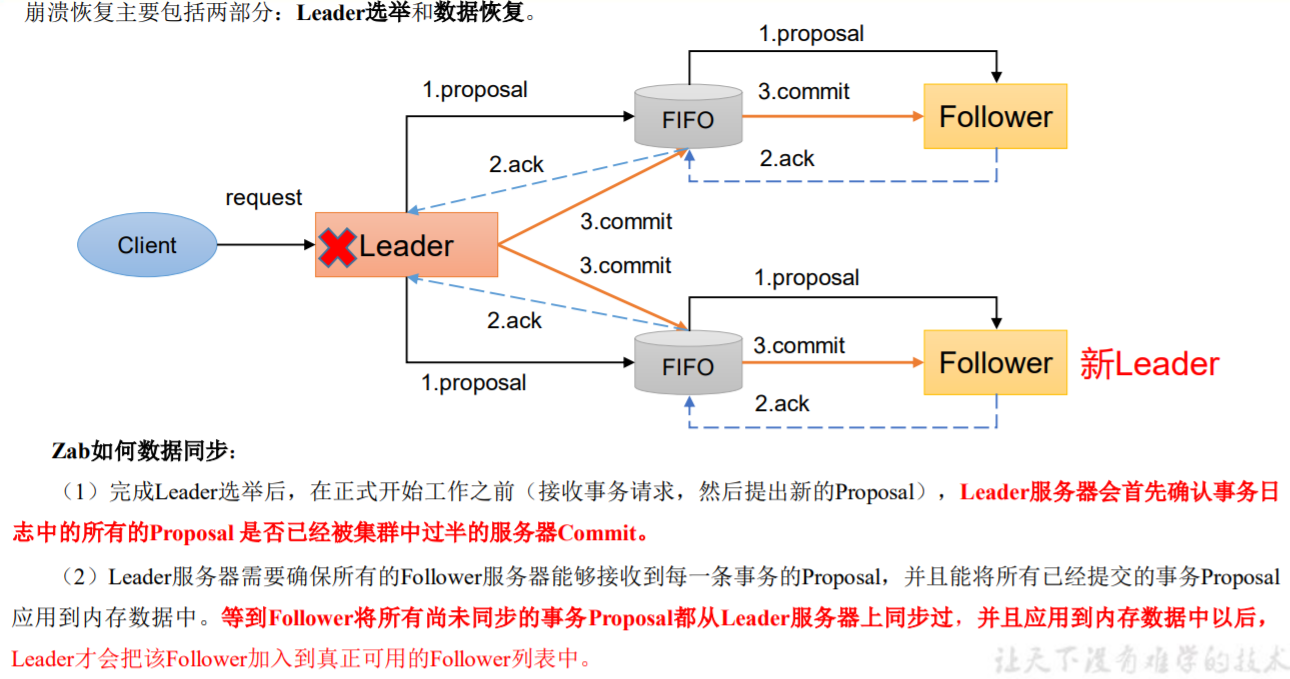
2.崩溃恢复

 浙公网安备 33010602011771号
浙公网安备 33010602011771号