java基础 (一)之HashMap(jdk1.7)
HashMap的存储结构是由数组和单链表共同完成。Entry<K,V>[] ,Entry是单向链表。
1 HashMap数据结构
HashMap的底层主要是基于数组和链表来实现的,它之所以有相当快的查询速度主要是因为它是通过计算散列码来决定存储的位置。HashMap中主要是通过key的hashCode来计算hash值的,只要hashCode相同,计算出来的hash值就一样。如果存储的对象对多了,就有可能不同的对象所算出来的hash值是相同的,这就出现了所谓的hash冲突。学过数据结构的同学都知道,解决hash冲突的方法有很多,HashMap底层是通过链表来解决hash冲突的。

2 HashMap中put方法解析

HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置。当程序执行 map.put(String,Obect)方法 时,系统将调用String的 hashCode() 方法得到其 hashCode 值,每个 Java 对象都有 hashCode() 方法,都可通过该方法获得它的 hashCode 值。得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置。
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
//初始化
inflateTable(threshold);
}
//如果为空key 为空将元素放在table[0]
if (key == null)
return putForNullKey(value);
//据key计算得到key.hash = (h = k.hashCode()) ^ (h >>> 16);
int hash = hash(key);
//根据key.hash计算得到数组的索引index = key.hash & (table.length - 1),这样就找到该key的存放位置了
int i = indexFor(hash, table.length);
/*判断当前确定的索引位置是否存在相同hashcode和相同key的元素,如果存在相同的hashcode和相同的key的元素,那么新值覆盖原来的旧值,并返回旧值。
如果存在相同的hashcode,那么他们确定的索引位置就相同,这时判断他们的key是否相同,如果不相同,这时就是产生了hash冲突。
Key的hashcode相同,key不同会导致hash冲突; Hash冲突后,那么HashMap的单个bucket里存储的不是一个 Entry,而是一个 Entry 链。
系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
*/
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//hash值相同并且值相同 则新增覆盖旧值
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++;
addEntry(hash, key, value, i); return null; }
private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++;
//key 为空 hash值为0 addEntry(0, null, value, 0); return null; }
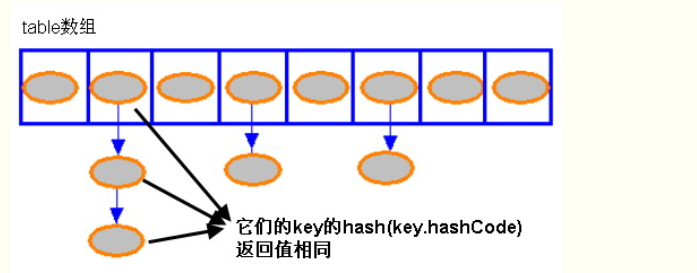
链表的核心代码如下:
void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); }
void createEntry(int hash, K key, V value, int bucketIndex) {
//系统总是将新添加的 Entry 对象放入 table 数组的 bucketIndex 索引处,如果 bucketIndex 索引处已经有了一个 Entry 对象,
//那新添加的 Entry 对象指向原有的 Entry 对象(产生一个 Entry 链),如果 bucketIndex 索引处没有 Entry 对象,
//也就是下面程序代码的 e 变量是 null,也就是新放入的 Entry 对象指向 null,也就是没有产生 Entry 链。 Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
/*
用来将原先table的元素全部移到newTable里面
再将newTable赋值给table
重新计算临界值
*/ void resize(int newCapacity) {
Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable, initHashSeedAsNeeded(newCapacity)); table = newTable; threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
3 HashMap的hash冲突
不同的key,计算出了同样的hash值
解决冲突方法:
1:链表法,链表法就是将相同hash值的对象组织成一个链表放在hash值对应的槽位;
2:开放地址法是通过一个探测算法,当某个槽位已经被占据的情况下继续查找下一个可以使用的槽位。java.util.HashMap采用的链表法的方式,链表是单向链表。
HashMap里面没有出现hash冲突时,没有形成单链表时,hashmap查找元素很快,get()方法能够直接定位到元素,但是出现单链表后,单个bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止;
如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素 (耗时)。
当创建 HashMap 时,有一个默认的负载因子(load factor),其默认值为 0.75,这是时间和空间成本上一种折衷:增大负载因子可以减少 Hash 表(就是那个 Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。
数组扩容:
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的长度是固定的。所以为了提高查询的效率,就要对HashMap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,这是一个常用的操作,而在HashMap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
为什么要将HashMap的长度要定义为2的幂
为什么这样能均匀分布减少碰撞呢?2的n次方实际就是1后面n个0,2的n次方-1 实际就是n个1;
例如长度为9时候,3&(9-1)=0 2&(9-1)=0 ,都在0上,碰撞了;
例如长度为8时候,3&(8-1)=3 2&(8-1)=2 ,不同位置上,不碰撞;

4 HashMap扩容 并发扩容导致的问题
当HashMap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,扩容是需要进行数组复制的,复制数组是非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
Entity
/** Entry是单向链表。
* 它是 “HashMap链式存储法”对应的链表。
*它实现了Map.Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数
**/
static class Entry<K,V> implements Map.Entry<K,V> {
final K key; V value; Entry<K,V> next; int hash; /** * 构造函数:输入参数包括"哈希值(h)", "键(k)", "值(v)", "下一节点(n)" */ Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } public final K getKey() { return key; } public final V getValue() { return value; } public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; }
// 判断两个Entry是否相等
// 若两个Entry的“key”和“value”都相等,则返回true。
// 否则,返回false
public final boolean equals(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry e = (Map.Entry)o; Object k1 = getKey(); Object k2 = e.getKey(); if (k1 == k2 || (k1 != null && k1.equals(k2))) { Object v1 = getValue(); Object v2 = e.getValue(); if (v1 == v2 || (v1 != null && v1.equals(v2))) return true; } return false; } public final int hashCode() { return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue()); } public final String toString() { return getKey() + "=" + getValue(); } /** * This method is invoked whenever the value in an entry is * overwritten by an invocation of put(k,v) for a key k that's already * in the HashMap. */ void recordAccess(HashMap<K,V> m) { } /** * This method is invoked whenever the entry is * removed from the table. */ void recordRemoval(HashMap<K,V> m) { } }
//从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
public V get(Object key) {
if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }
5 HashMap中的负载因子是干什么的?
作为扩容的临界值用的(DEFAULT_INITIAL_CAPACITY*DEFAULT_LOAD_FACTOR)
HashMap有一个初始容量大小,默认是16 static final int DEAFULT_INITIAL_CAPACITY = 1 << 4; // aka 16
为了减少冲突概率,当HashMap的数组长度达到一个临界值就会触发扩容,把所有元素rehash再放回容器中,这是一个非常耗时的操作。
而这个临界值由负载因子和当前的容量大小来决定:DEFAULT_INITIAL_CAPACITY*DEFAULT_LOAD_FACTOR,即默认情况下数组长度是16*0.75=12时,触发扩容操作。
6 为什么负载因子为0.75
当桶中元素(hash冲突,链表长度)到达8个的时候,概率已经变得非常小,也就是说用0.75作为负载因子,每个碰撞位置的链表长度超过8个是几乎不可能的。HashMap负载因子为0.75是空间和时间成本的一种折中。
当负载因子较大时,去给table数组扩容的可能性就会少,所以相对占用内存较少(空间上较少),但是每条entry链上的元素会相对较多,查询的时间也会增长(时间上较多)。
负载因子较少的时候,给table数组扩容的可能性就高,那么内存空间占用就多,但是entry链上的元素就会相对较少,查出的时间也会减少。所以才有了负载因子是时间和空间上的一种折中的说法。所以设置负载因子的时候要考虑自己追求的是时间还是空间上的少。
7 HashMap 汇总


 浙公网安备 33010602011771号
浙公网安备 33010602011771号