MySQL(二)之B-Tree和B+Tree
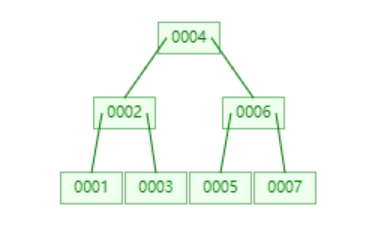
B-Tree
- 叶节点具有相同的深度,叶节点的指针为空
- 根节点存储数据
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
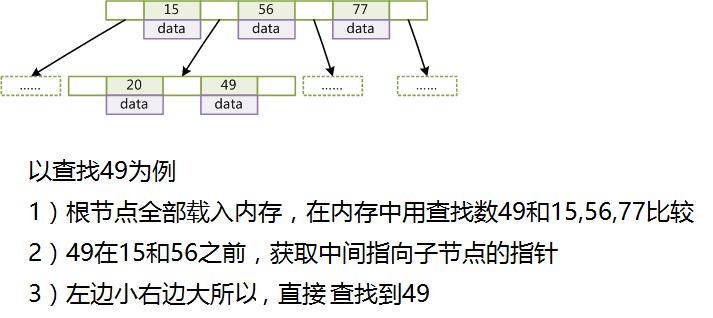
由于B-Tree的特性,在B-Tree中按key检索数据的算法非常直观:首先从根节点进行二分查找,如果找到则返回对应节点的data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或找到null指针,前者查找成功,后者查找失败。
例如一个度为d的B-Tree,设其索引N个key,则其树高h的上限为logd((N+1)/2),检索一个key,其查找节点个数的渐进复杂度为O(logdN)。从这点可以看出,B-Tree是一个非常有效率的索引数据结构。
另外,由于插入删除新的数据记录会破坏B-Tree的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质.
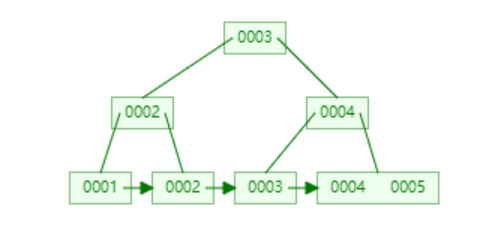
B+Tree(B-Tree变种)(mysql索引存储结构)
- 根节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问性能
- 叶子节点保存数据
为什么根节点不存储数据,叶子节点存储数据?
希望树的横向(根节点)能存储更多的索引,将具体的数据存储到叶子节点上
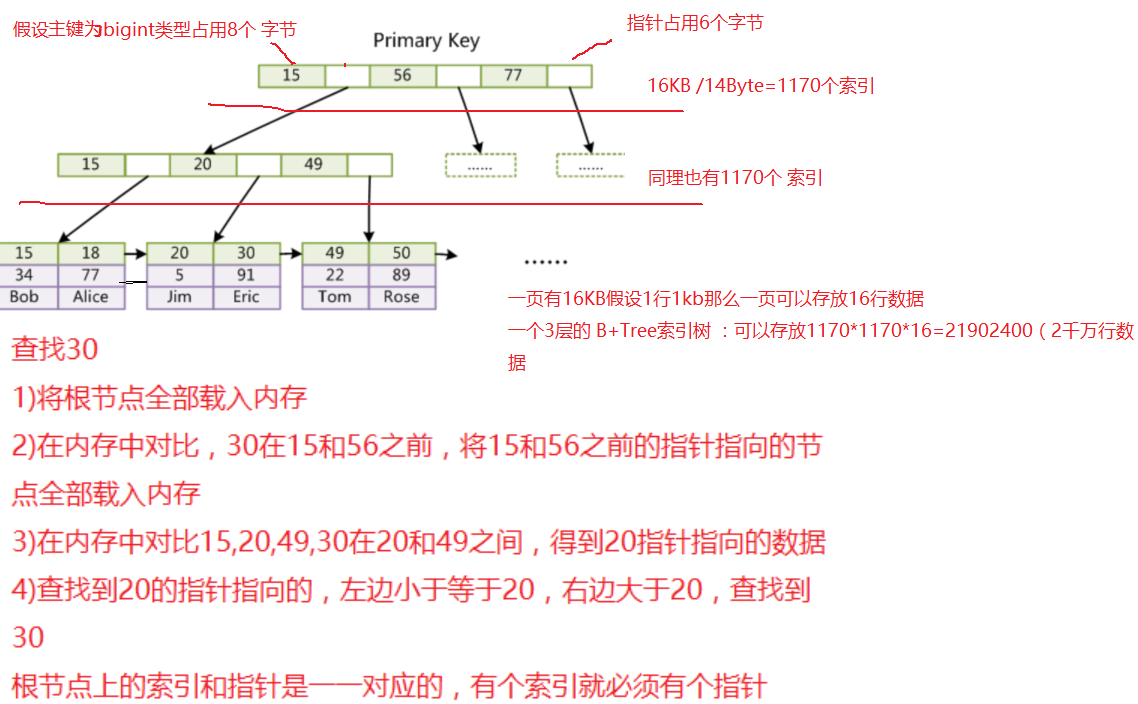
InnoDB一棵B+树可以存放多少行数据?
一般主键为bigint为8 Byte,指针为6 Byte,InnoDB存储引擎最小储存单元为页(Page),一个页的大小是16KB,16KB (16*1024)/(8+6)=1170个索引
树的深度h<=3,前两层为根,每层可以存放1171个索引,所以1170*1170*16 =21902400(约2千万)
为什么用B+Tree而不用B-Tree为索引结构?
1)B+Tree的根节点可以存放更多索引,而B-Tree包含了数据内存无法存放更多的索引
2)B-Tree
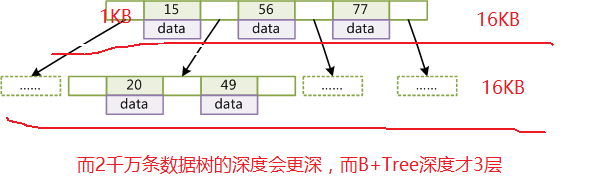
3)带有顺序访问指针的B+Tree。

在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。 

 浙公网安备 33010602011771号
浙公网安备 33010602011771号