Mysql数据库索引IS NUll ,IS NOT NUll ,!= 是否走索引
声明在前面
总结就是 不能单纯说 走和不走,需要看数据库版本,数据量等 ,希望不要引起大家的误会,也不要被标题党误导了。
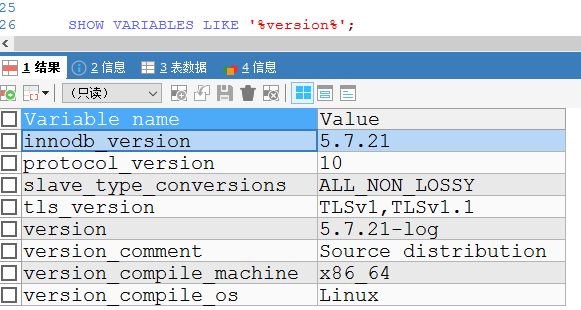
1 数据库版本:
2 建表语句
CREATE TABLE s1 ( id INT NOT NULL AUTO_INCREMENT, key1 VARCHAR(200), key2 VARCHAR(200), key3 VARCHAR(200), key_part1 VARCHAR(200), key_part2 VARCHAR(200), key_part3 VARCHAR(200), common_field VARCHAR(200), PRIMARY KEY (id) ) ENGINE=INNODB CHARSET=utf8;
3 建索引语句
CREATE INDEX isz_key1 ON s1(key1);
CREATE INDEX isz_key2 ON s1(key2);
CREATE INDEX isz_key3 ON s1(key3);
CREATE INDEX idx_key_part ON s1 (key_part1, key_part2, key_part3);
4 铺底数据
DELIMITER $$ CREATE PROCEDURE pre () BEGIN DECLARE i INT; SET i = 0; WHILE i < 9000 DO INSERT INTO s1 ( key1, key2, key3, key_part1, key_part2, key_part3, common_field ) VALUES ( 'a', '注意应收热热账款状态为有效状态下,资源编号与应热热付流水号一一对应,(已结佣、已热热、已失效3种情况为无效热热,其他均为有效状态)', 'cc', 'a应收账款状态为a', 'cc', '注意应erect账款状态为有效状态下,资源编号与应付流水号一一对应,(已结佣、已热热无效、已失效3种情况为热热状态,其他均为有效状态)', 'ddff' ); SET i = i + 1; END WHILE; END $$ CALL pre (); DROP PROCEDURE pre;
select COUNT(1)FROM s1;
IS NULL ,IS NOT NUll 是否走索引

EXPLAIN SELECT *FROM s1 WHERE s1.`key1` IS NULL; 表里 key1 为is null的总数为0 查询is null 走索引
 EXPLAIN SELECT *FROM s1 WHERE s1.`key1` IS not NULL; 表里 key1 的列 is not null 的总数为0,不存在值为null 查询is not null 不走索引
EXPLAIN SELECT *FROM s1 WHERE s1.`key1` IS not NULL; 表里 key1 的列 is not null 的总数为0,不存在值为null 查询is not null 不走索引
 Is null count为19012条 ,is not count为9条 实验结果 is null 和 is not null 都走索引
Is null count为19012条 ,is not count为9条 实验结果 is null 和 is not null 都走索引
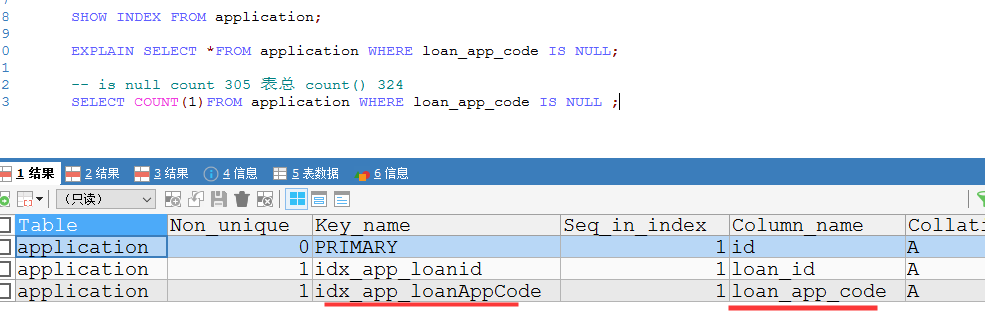
 测试application 表,is null count有305条,表总有324条 ,is null 不走索引
测试application 表,is null count有305条,表总有324条 ,is null 不走索引

总结: 并不是 is null ,is not null走和不走索引是和数据量或者和其他元素有关系(这里我只是测试到和数据量有关系) sql优化器在执行的时候会计算成本,其实和基数,选择性,直方图有关,其实就是看你所搜索的部分占全表的比例是走索引还是全表成本低。
!=走索引吗?
<> 和!= 是同一个意思 ,都是不等于
测试一 <> 走索引,存在<>的数据量有9条

测试二<>走索引存在不等于的数据量有305条
 测试三 <> 不走索引 值都是“abc”,不是“abc”的总条数为0
测试三 <> 不走索引 值都是“abc”,不是“abc”的总条数为0
SELECT COUNT(1)FROM s1 WHERE s1.`key3` ='abc'; -- 0
测试四 <>走索引
总结:并不能一句话说 走和不走,需要看条件,比如数据量,等于“abc”的数据量和不等于“abc”的量,mysql在执行的时候会判断走索引的成本和全表扫描的成本,然后选择成本小的那个

 浙公网安备 33010602011771号
浙公网安备 33010602011771号