
设计模式之美总结(设计原则篇)
上一篇见:
上一篇介绍了面向对象相关的知识。接下来介绍一些经典的设计原则,其中包括 SOLID、KISS、YAGNI、DRY、LOD 等
1. 单一职责原则(SRP)
1.1 如何理解单一职责原则?
实际上,SOLID 原则并非单纯的 1 个原则,而是由 5个设计原则组成的,它们分别是:单一职责原则、开闭原则、里式替换原则、接口隔离原则和依赖反转原则,依次对应 SOLID 中的 S、O、L、I、D 这 5 个英文字母
单一职责原则的英文是 Single Responsibility Principle,缩写为 SRP
A class or module should have a single reponsibility.
一个类或者模块只负责完成一个职责(或者功能)
这个原则描述的对象包含两个,一个是类(Class),一个是模块(Module)。关于这两个概念,这里有两种理解方式。
- 一种理解是:把模块看作比类更加抽象的概念,类也可以看作模块
- 另一种理解是:把模块看作比类更加粗粒度的代码块,模块中包含多个类,多个类组成一个模块
不管哪种理解方式,单一职责原则在应用到这两个描述对象的时候,道理都是相通的。接下来只从“类”设计的角度,来结算如何应用这个设计原则。对于“模块”来说,可以自行引申
单一职责原则的定义描述非常简单,也不难理解。一个类只负责完成一个职责或者功能。也就是说,不要设计大而全的类,要设计粒度小、功能单一的类。换个角度来讲就是,一个类包含了两个或者两个以上业务不相干的功能,那就说它职责不够单一,应该将它拆分成多个功能更加单一、粒度更细的类
比如,一个类里既包含订单的一些操作,又包含用户的一些操作。而订单和用户是两个独立的业务领域模型,将两个不相干的功能放到同一个类中,那就违反了单一职责原则。为了满足单一职责原则,需要将这个类拆分成两个粒度更细、功能更加单一的两个类:订单类和用户类
1.2 如何判断类的职责是否足够单一?
从上面这个例子来看,单一职责原则看似不难应用。那是因为举的这个例子比较极端,一眼就能看出订单和用户毫不相干。但大部分情况下,类里的方法是归为同一类功能,还是归为不相关的两类功能,并不是那么容易判定的。在真实的软件开发中,对于一个类是否职责单一的判定,是很难拿捏的。如下例:
在一个社交产品中,用下面的 UserInfo 类来记录用户的信息。你觉得,UserInfo 类的设计是否满足单一职责原则呢?
public class UserInfo {
private long userId;
private String username;
private String email;
private String telephone;
private long createTime;
private long lastLoginTime;
private String avatarUrl;
private String provinceOfAddress; // 省
private String cityOfAddress; // 市
private String regionOfAddress; // 区
private String detailedAddress; // 详细地址
// ... 省略其他属性和方法...
}
对于这个问题,有两种不同的观点。一种观点是,UserInfo 类包含的都是跟用户相关的信息,所有的属性和方法都隶属于用户这样一个业务模型,满足单一职责原则;另一种观点是,地址信息在 UserInfo 类中,所占的比重比较高,可以继续拆分成独立的 UserAddress类,UserInfo 只保留除 Address 之外的其他信息,拆分之后的两个类的职责更加单一
实际上,要从中做出选择,不能脱离具体的应用场景。如果在这个社交产品中,用户的地址信息跟其他信息一样,只是单纯地用来展示,那 UserInfo 现在的设计就是合理的。但是,如果这个社交产品发展得比较好,之后又在产品中添加了电商的模块,用户的地址信息还会用在电商物流中,那最好将地址信息从 UserInfo 中拆分出来,独立成用户物流信息(或者叫地址信息、收货信息等)
再进一步延伸一下。如果做这个社交产品的公司发展得越来越好,公司内部又开发出了跟多其他产品(可以理解为其他 App)。公司希望支持统一账号系统,也就是用户一个账号可以在公司内部的所有产品中登录。这个时候,就需要继续对 UserInfo 进行拆分,将跟身份认证相关的信息(比如,Email、Telephone 等)抽取成独立的类
由此可以总结出,不同的应用场景、不同阶段的需求背景下,对同一个类的职责是否单一的判定,可能都是不一样的。在某种应用场景或者当下的需求背景下,一个类的设计可能已经满足单一职责原则了,但如果换个应用场景或着在未来的某个需求背景下,可能就不满足了,需要继续拆分成粒度更细的类
除此之外,从不同的业务层面去看待同一个类的设计,对类是否职责单一,也会有不同的认识。比如,例子中的 UserInfo 类。如果从“用户”这个业务层面来看,UserInfo 包含的信息都属于用户,满足职责单一原则。如果从更加细分的“用户展示信息”“地址信息”“登录认证信息”等等这些更细粒度的业务层面来看,那 UserInfo 就应该继续拆分
综上所述,评价一个类的职责是否足够单一,并没有一个非常明确的、可以量化的标准,可以说,这是件非常主观、仁者见仁智者见智的事情。实际上,在真正的软件开发中,也没必要过于未雨绸缪,过度设计。所以,可以先写一个粗粒度的类,满足业务需求。随着业务的发展,如果粗粒度的类越来越庞大,代码越来越多,这个时候,就可以将这个粗粒度的类,拆分成几个更细粒度的类。这就是所谓的持续重构
这里还有一些小技巧,能够很好地帮你,从侧面上判定一个类的职责是否够单一。而且,我个人觉得,下面这几条判断原则,比起很主观地去思考类是否职责单一,要更有指导意义、更具有可执行性:
- 类中的代码行数、函数或属性过多,会影响代码的可读性和可维护性,就需要考虑对类进行拆分
- 类依赖的其他类过多,或者依赖类的其他类过多,不符合高内聚、低耦合的设计思想,就需要考虑对类进行拆分
- 私有方法过多,就要考虑能否将私有方法独立到新的类中,设置为 public 方法,供更多的类使用,从而提高代码的复用性
- 比较难给类起一个合适名字,很难用一个业务名词概括,或者只能用一些笼统的 Manager、Context 之类的词语来命名,这就说明类的职责定义得可能不够清晰
- 类中大量的方法都是集中操作类中的某几个属性,比如,在 UserInfo 例子中,如果一半的方法都是在操作 address 信息,那就可以考虑将这几个属性和对应的方法拆分出来
此时可能会有这样的疑问:在上面的判定原则中提到类中的代码行数、函数或者属性过多,就有可能不满足单一职责原则。那多少行代码才算是行数过多呢?多少个函数、属性才称得上过多呢?
实际上,这个问题并不好定量地回答。比较宽泛的、可量化的标准,那就是一个类的代码行数最好不能超过 200 行,函数个数及属性个数都最好不要超过 10 个。实际上, 从另一个角度来看,当一个类的代码,读起来让你头大了,实现某个功能时不知道该用哪个函数了,想用哪个函数翻半天都找不到了,只用到一个小功能要引入整个类(类中包含很多无关此功能实现的函数)的时候,这就说明类的行数、函数、属性过多了
1.3 类的职责是否设计得越单一越好?
为了满足单一职责原则,是不是把类拆得越细就越好呢?答案是否定的。如下例,Serialization 类实现了一个简单协议的序列化和反序列功能,具体代码如下:
public class Serialization {
private static final String IDENTIFIER_STRING = "UEUEUE;";
private Gson gson;
public Serialization() {
this.gson = new Gson();
}
public String serialize(Map<String, String> object) {
StringBuilder textBuilder = new StringBuilder();
textBuilder.append(IDENTIFIER_STRING);
textBuilder.append(gson.toJson(object));
return textBuilder.toString();
}
public Map<String, String> deserialize(String text) {
if (!text.startsWith(IDENTIFIER_STRING)) {
return Collections.emptyMap();
}
String gsonStr = text.substring(IDENTIFIER_STRING.length());
return gson.fromJson(gsonStr, Map.class);
}
}
如果想让类的职责更加单一,对 Serialization 类进一步拆分,拆分成一个只负责序列化工作的 Serializer 类和另一个只负责反序列化工作的 Deserializer 类。拆分后的具体代码如下所示:
public class Serializer {
private static final String IDENTIFIER_STRING = "UEUEUE;";
private Gson gson;
public Serializer() {
this.gson = new Gson();
}
public String serialize(Map<String, String> object) {
StringBuilder textBuilder = new StringBuilder();
textBuilder.append(IDENTIFIER_STRING);
textBuilder.append(gson.toJson(object));
return textBuilder.toString();
}
}
public class Deserializer {
private static final String IDENTIFIER_STRING = "UEUEUE;";
private Gson gson;
public Deserializer() {
this.gson = new Gson();
}
public Map<String, String> deserialize(String text) {
if (!text.startsWith(IDENTIFIER_STRING)) {
return Collections.emptyMap();
}
String gsonStr = text.substring(IDENTIFIER_STRING.length());
return gson.fromJson(gsonStr, Map.class);
}
}
虽然经过拆分之后,Serializer 类和 Deserializer 类的职责更加单一了,但也随之带来了新的问题。如果修改了协议的格式,数据标识从“UEUEUE”改为“DFDFDF”,或者序列化方式从 JSON 改为了 XML,那 Serializer 类和 Deserializer 类都需要做相应的修改,代码的内聚性显然没有原来 Serialization 高了。而且,如果仅仅对 Serializer 类做了协议修改,而忘记了修改 Deserializer 类的代码,那就会导致序列化、反序列化不匹配,程序运行出错,也就是说,拆分之后,代码的可维护性变差了
实际上,不管是应用设计原则还是设计模式,最终的目的还是提高代码的可读性、可扩展性、复用性、可维护性等。在考虑应用某一个设计原则是否合理的时候,也可以以此作为最终的考量标准
2. 开闭原则(OCP)
作者个人觉得,开闭原则是 SOLID 中最难理解、最难掌握,同时也是最有用的一条原则
- 之所以说这条原则难理解,那是因为,“怎样的代码改动才被定义为‘扩展’?怎样的代码改动才被定义为‘修改’?怎么才算满足或违反‘开闭原则’?修改代码就一定意味着违反‘开闭原则’吗?”等等这些问题,都比较难理解
- 之所以说这条原则难掌握,那是因为,“如何做到‘对扩展开发、修改关闭’?如何在项目中灵活地应用‘开闭原则’,以避免在追求扩展性的同时影响到代码的可读性?”等等这些问题,都比较难掌握
- 之所以说这条原则最有用,那是因为,扩展性是代码质量最重要的衡量标准之一。在 23 种经典设计模式中,大部分设计模式都是为了解决代码的扩展性问题而存在的,主要遵从的设计原则就是开闭原则
2.1 如何理解“对扩展开放、修改关闭”?
开闭原则的英文全称是 Open Closed Principle,简写为 OCP
software entities (modules, classes, functions, etc.) should be open for extension, but closed for modification.
软件实体(模块、类、方法等)应该“对扩展开放、对修改关闭”
这个描述比较简略,如果详细表述一下,那就是,添加一个新的功能应该是,在已有代码基础上扩展代码(新增模块、类、方法等),而非修改已有代码(修改模块、类、方法等)。如下例,这是一段 API 接口监控告警的代码
其中,AlertRule 存储告警规则,可以自由设置。Notification 是告警通知类,支持邮件、短信、微信、手机等多种通知渠道。NotificationEmergencyLevel 表示通知的紧急程度,包括 SEVERE(严重)、URGENCY(紧急)、NORMAL(普通)、TRIVIAL(无关紧要),不同的紧急程度对应不同的发送渠道
public class Alert {
private AlertRule rule;
private Notification notification;
public Alert(AlertRule rule, Notification notification) {
this.rule = rule;
this.notification = notification;
}
public void check(String api, long requestCount, long errorCount, long duration) {
long tps = requestCount / durationOfSeconds;
if (tps > rule.getMatchedRule(api).getMaxTps()) {
notification.notify(NotificationEmergencyLevel.URGENCY, "...");
}
if (errorCount > rule.getMatchedRule(api).getMaxErrorCount()) {
notification.notify(NotificationEmergencyLevel.SEVERE, "...");
}
}
}
上面这段代码非常简单,业务逻辑主要集中在 check() 函数中。当接口的 TPS 超过某个预先设置的最大值时,以及当接口请求出错数大于某个最大允许值时,就会触发告警,通知接口的相关负责人或者团队
现在,如果需要添加一个功能,当每秒钟接口超时请求个数,超过某个预先设置的最大阈值时,也要触发告警发送通知。这个时候,该如何改动代码呢?主要的改动有两处:第一处是修改 check() 函数的入参,添加一个新的统计数据 timeoutCount,表示超时接口请求数;第二处是在 check() 函数中添加新的告警逻辑。具体的代码改动如下所示:
public class Alert {
// ... 省略 AlertRule/Notification 属性和构造函数...
// 改动一:添加参数 timeoutCount
public void check(String api, long requestCount, long errorCount, long timeoutCount) {
long tps = requestCount / durationOfSeconds;
if (tps > rule.getMatchedRule(api).getMaxTps()) {
notification.notify(NotificationEmergencyLevel.URGENCY, "...");
}
if (errorCount > rule.getMatchedRule(api).getMaxErrorCount()) {
notification.notify(NotificationEmergencyLevel.SEVERE, "...");
}
// 改动二:添加接口超时处理逻辑
long timeoutTps = timeoutCount / durationOfSeconds;
if (timeoutTps > rule.getMatchedRule(api).getMaxTimeoutTps()) {
notification.notify(NotificationEmergencyLevel.URGENCY, "...");
}
}
}
这样的代码修改实际上存在挺多问题的。一方面,对接口进行了修改,这就意味着调用这个接口的代码都要做相应的修改。另一方面,修改了 check() 函数,相应的单元测试都需要修改
上面的代码改动是基于“修改”的方式来实现新功能的。如果遵循开闭原则,也就是“对扩展开放、对修改关闭”。那如何通过“扩展”的方式,来实现同样的功能呢?
首先先重构一下之前的 Alert 代码,让它的扩展性更好一些。重构的内容主要包含两部分:
- 将
check()函数的多个入参封装成 ApiStatInfo 类; - 引入 handler 的概念,将 if 判断逻辑分散在各个 handler 中
具体的代码实现如下所示:
public class Alert {
private List<AlertHandler> alertHandlers = new ArrayList<>();
public void addAlertHandler(AlertHandler alertHandler) {
this.alertHandlers.add(alertHandler);
}
public void check(ApiStatInfo apiStatInfo) {
for (AlertHandler handler : alertHandlers) {
handler.check(apiStatInfo);
}
}
}
public class ApiStatInfo {// 省略 constructor/getter/setter 方法
private String api;
private long requestCount;
private long errorCount;
private long durationOfSeconds;
}
public abstract class AlertHandler {
protected AlertRule rule;
protected Notification notification;
public AlertHandler(AlertRule rule, Notification notification) {
this.rule = rule;
this.notification = notification;
}
public abstract void check(ApiStatInfo apiStatInfo);
}
public class TpsAlertHandler extends AlertHandler {
public TpsAlertHandler(AlertRule rule, Notification notification) {
super(rule, notification);
}
@Override
public void check(ApiStatInfo apiStatInfo) {
long tps = apiStatInfo.getRequestCount()/ apiStatInfo.getDurationOfSeconds
if (tps > rule.getMatchedRule(apiStatInfo.getApi()).getMaxTps()) {
notification.notify(NotificationEmergencyLevel.URGENCY, "...");
}
}
}
public class ErrorAlertHandler extends AlertHandler {
public ErrorAlertHandler(AlertRule rule, Notification notification){
super(rule, notification);
}
@Override
public void check(ApiStatInfo apiStatInfo) {
if (apiStatInfo.getErrorCount() > rule.getMatchedRule(apiStatInfo.getApi()) {
notification.notify(NotificationEmergencyLevel.SEVERE, "...");
}
}
}
上面的代码是对 Alert 的重构,重构之后的 Alert 该如何使用呢?如下,其中,ApplicationContext 是一个单例类,负责 Alert 的创建、组装(alertRule 和 notification 的依赖注入)、初始化(添加 handlers)工作
public class ApplicationContext {
private AlertRule alertRule;
private Notification notification;
private Alert alert;
public void initializeBeans() {
alertRule = new AlertRule(/*. 省略参数.*/); // 省略一些初始化代码
notification = new Notification(/*. 省略参数.*/); // 省略一些初始化代码
alert = new Alert();
alert.addAlertHandler(new TpsAlertHandler(alertRule, notification));
alert.addAlertHandler(new ErrorAlertHandler(alertRule, notification));
}
public Alert getAlert() { return alert; }
// 饿汉式单例
private static final ApplicationContext instance = new ApplicationContext();
private ApplicationContext() {
instance.initializeBeans();
}
public static ApplicationContext getInstance() {
return instance;
}
}
public class Demo {
public static void main(String[] args) {
ApiStatInfo apiStatInfo = new ApiStatInfo();
// ... 省略设置 apiStatInfo 数据值的代码
ApplicationContext.getInstance().getAlert().check(apiStatInfo);
}
}
再来看下,基于重构之后的代码,如果再添加上面讲到的那个新功能,每秒钟接口超时请求个数超过某个最大阈值就告警,又该如何改动代码呢?主要的改动有下面四处:
- 在 ApiStatInfo 类中添加新的属性 timeoutCount
- 添加新的 TimeoutAlertHander 类
- 在 ApplicationContext 类的 initializeBeans() 方法中,往 alert 对象中注册新的 timeoutAlertHandler
- 在使用 Alert 类的时候,需要给
check()函数的入参 apiStatInfo 对象设置 timeoutCount 的值
public class Alert { // 代码未改动... }
public class ApiStatInfo {// 省略 constructor/getter/setter 方法
private String api;
private long requestCount;
private long errorCount;
private long durationOfSeconds;
private long timeoutCount; // 改动一:添加新字段
}
public abstract class AlertHandler { // 代码未改动... }
public class TpsAlertHandler extends AlertHandler { // 代码未改动...}
public class ErrorAlertHandler extends AlertHandler { // 代码未改动...}
// 改动二:添加新的 handler
public class TimeoutAlertHandler extends AlertHandler { // 省略代码...}
public class ApplicationContext {
private AlertRule alertRule;
private Notification notification;
private Alert alert;
public void initializeBeans() {
alertRule = new AlertRule(/*. 省略参数.*/); // 省略一些初始化代码
notification = new Notification(/*. 省略参数.*/); // 省略一些初始化代码
alert = new Alert();
alert.addAlertHandler(new TpsAlertHandler(alertRule, notification));
alert.addAlertHandler(new ErrorAlertHandler(alertRule, notification));
// 改动三:注册 handler
alert.addAlertHandler(new TimeoutAlertHandler(alertRule, notification));
}
//... 省略其他未改动代码...
}
public class Demo {
public static void main(String[] args) {
ApiStatInfo apiStatInfo = new ApiStatInfo();
// ... 省略 apiStatInfo 的 set 字段代码
apiStatInfo.setTimeoutCount(289); // 改动四:设置 tiemoutCount 值
ApplicationContext.getInstance().getAlert().check(apiStatInfo);
}
}
重构之后的代码更加灵活和易扩展。如果要想添加新的告警逻辑,只需要基于扩展的方式创建新的 handler 类即可,不需要改动原来的 check() 函数的逻辑。而且,只需要为新的 handler 类添加单元测试,老的单元测试都不会失败,也不用修改
2.2 修改代码就意味着违背开闭原则吗?
看了上面重构之后的代码,可能还会有疑问:在添加新的告警逻辑的时候,尽管改动二(添加新的 handler 类)是基于扩展而非修改的方式来完成的,但改动一、三、四貌似不是基于扩展而是基于修改的方式来完成的,那改动一、三、四不就违背了开闭原则吗?
1、改动一:往 ApiStatInfo 类中添加新的属性 timeoutCount
实际上,不仅往 ApiStatInfo 类中添加了属性,还添加了对应的 getter/setter 方法。那这个问题就转化为:给类中添加新的属性和方法,算作“修改”还是“扩展”?
开闭原则的定义:软件实体(模块、类、方法等)应该“对扩展开放、对修改关闭”。从定义中,可以看出,开闭原则可以应用在不同粒度的代码中,可以是模块,也可以类,还可以是方法(及其属性)。同样一个代码改动,在粗代码粒度下,被认定为“修改”,在细代码粒度下,又可以被认定为“扩展”。比如,改动一,添加属性和方法相当于修改类,在类这个层面,这个代码改动可以被认定为“修改”;但这个代码改动并没有修改已有的属性和方法,在方法(及其属性)这一层面,它又可以被认定为“扩展”
实际上,也没必要纠结某个代码改动是“修改”还是“扩展”,更没必要太纠结它是否违反“开闭原则”。回到这条原则的设计初衷:只要它没有破坏原有的代码的正常运行,没有破坏原有的单元测试,就可以说,这是一个合格的代码改动
2、改动三和改动四:在 ApplicationContext 类的 initializeBeans() 方法中,往 alert 对象中注册新的 timeoutAlertHandler;在使用 Alert 类的时候,需要给 check() 函数的入参 apiStatInfo 对象设置 timeoutCount 的值
这两处改动都是在方法内部进行的,不管从哪个层面(模块、类、方法)来讲,都不能算是“扩展”,而是地地道道的“修改”。不过,有些修改是在所难免的,是可以被接受的。为什么这么说呢?
在重构之后的 Alert 代码中,核心逻辑集中在 Alert 类及其各个 handler 中,当在添加新的告警逻辑的时候,Alert 类完全不需要修改,而只需要扩展一个新 handler 类。如果把 Alert 类及各个 handler 类合起来看作一个“模块”,那模块本身在添加新的功能的时候,完全满足开闭原则
而且,添加一个新功能,不可能任何模块、类、方法的代码都不“修改”,这个是做不到的。类需要创建、组装、并且做一些初始化操作,才能构建成可运行的的程序,这部分代码的修改是在所难免的。要做的是尽量让修改操作更集中、更少、更上层,尽量让最核心、最复杂的那部分逻辑代码满足开闭原则
2.3 如何做到“对扩展开放、修改关闭”?
在刚刚的例子中,通过引入一组 handler 的方式来实现支持开闭原则。如果没有太多复杂代码的设计和开发经验,这样的代码设计思路可能想不到。能想到,靠的就是理论知识和实战经验,这些需要慢慢学习和积累
实际上,开闭原则讲的就是代码的扩展性问题,是判断一段代码是否易扩展的“金标准”。如果某段代码在应对未来需求变化的时候,能够做到“对扩展开放、对修改关闭”,那就说明这段代码的扩展性比较好。所以,问如何才能做到“对扩展开放、对修改关闭”,也就粗略地等同于在问,如何才能写出扩展性好的代码
在讲具体的方法论之前,先来看一些更加偏向顶层的指导思想。为了尽量写出扩展性好的代码,要时刻具备扩展意识、抽象意识、封装意识。这些“潜意识”可能比任何开发技巧都重要
在写代码的时候后,要多花点时间往前多思考一下,这段代码未来可能有哪些需求变更、如何设计代码结构,事先留好扩展点,以便在未来需求变更的时候,不需要改动代码整体结构、做到最小代码改动的情况下,新的代码能够很灵活地插入到扩展点上,做到“对扩展开放、对修改关闭”
还有,在识别出代码可变部分和不可变部分之后,要将可变部分封装起来,隔离变化,提供抽象化的不可变接口,给上层系统使用。当具体的实现发生变化的时候,只需要基于相同的抽象接口,扩展一个新的实现,替换掉老的实现即可,上游系统的代码几乎不需要修改
讲完了实现开闭原则的一些偏向顶层的指导思想,现在再来看下,支持开闭原则的一些更加具体的方法论
前面讲到,代码的扩展性是代码质量评判的最重要的标准之一。实际上,很多设计原则、设计思想、设计模式,都是以提高代码的扩展性为最终目的的。特别是 23 种经典设计模式,大部分都是为了解决代码的扩展性问题而总结出来的,都是以开闭原则为指导原则的
在众多的设计原则、思想、模式中,最常用来提高代码扩展性的方法有:多态、依赖注入、基于接口而非实现编程,以及大部分的设计模式(比如,装饰、策略、模板、职责链、状态等)。接下来重点讲一下,如何利用多态、依赖注入、基于接口而非实现编程,来实现“对扩展开放、对修改关闭”
实际上,多态、依赖注入、基于接口而非实现编程,以及前面提到的抽象意识,说的都是同一种设计思路,只是从不同的角度、不同的层面来阐述而已。这也体现了“很多设计原则、思想、模式都是相通的”这一思想
如下例,代码中通过 Kafka 来发送异步消息。对于这样一个功能的开发,要学会将其抽象成一组跟具体消息队列(Kafka)无关的异步消息接口。所有上层系统都依赖这组抽象的接口编程,并且通过依赖注入的方式来调用。当要替换新的消息队列的时候,比如将 Kafka 替换成 RocketMQ,可以很方便地拔掉老的消息队列实现,插入新的消息队列实现。具体代码如下所示:
// 这一部分体现了抽象意识
public interface MessageQueue { //... }
public class KafkaMessageQueue implements MessageQueue { //... }
public class RocketMQMessageQueue implements MessageQueue {//...}
public interface MessageFromatter { //... }
public class JsonMessageFromatter implements MessageFromatter {//...}
public class ProtoBufMessageFromatter implements MessageFromatter {//...}
public class Demo {
private MessageQueue msgQueue; // 基于接口而非实现编程
public Demo(MessageQueue msgQueue) { // 依赖注入
this.msgQueue = msgQueue;
}
// msgFormatter:多态、依赖注入
public void sendNotification(Notification notification, MessageFormatter msg) {
//...
}
}
2.4 如何在项目中灵活应用开闭原则?
写出支持“对扩展开放、对修改关闭”的代码的关键是预留扩展点。那问题是如何才能识别出所有可能的扩展点呢?
如果开发的是一个业务导向的系统,比如金融系统、电商系统、物流系统等,要想识别出尽可能多的扩展点,就要对业务有足够的了解,能够知道当下以及未来可能要支持的业务需求。如果开发的是跟业务无关的、通用的、偏底层的系统,比如,框架、组件、类库,需要了解“它们会被如何使用?今后你打算添加哪些功能?使用者未来会有哪些更多的功能需求?”等问题
不过,有一句话说得好,“唯一不变的只有变化本身”。即便对业务、对系统有足够的了解,那也不可能识别出所有的扩展点,即便能识别出所有的扩展点,为这些地方都预留扩展点,这样做的成本也是不可接受的。没必要为一些遥远的、不一定发生的需求去提前买单,做过度设计
最合理的做法是,对于一些比较确定的、短期内可能就会扩展,或者需求改动对代码结构影响比较大的情况,或者实现成本不高的扩展点,在编写代码的时候之后,就可以事先做些扩展性设计。但对于一些不确定未来是否要支持的需求,或者实现起来比较复杂的扩展点,可以等到有需求驱动的时候,再通过重构代码的方式来支持扩展的需求
而且,开闭原则也并不是免费的。有些情况下,代码的扩展性会跟可读性相冲突。比如之前举的 Alert 告警的例子。为了更好地支持扩展性,对代码进行了重构,重构之后的代码要比之前的代码复杂很多,理解起来也更加有难度。很多时候,都需要在扩展性和可读性之间做权衡。在某些场景下,代码的扩展性很重要,就可以适当地牺牲一些代码的可读性;在另一些场景下,代码的可读性更加重要,那就适当地牺牲一些代码的可扩展性
在之前举的 Alert 告警的例子中,如果告警规则并不是很多、也不复杂,那 check() 函数中的 if 语句就不会很多,代码逻辑也不复杂,代码行数也不多,那最初的第一种代码实现思路简单易读,就是比较合理的选择。相反,如果告警规则很多、很复杂,check() 函数的 if 语句、代码逻辑就会很多、很复杂,相应的代码行数也会很多,可读性、可维护性就会变差,那重构之后的第二种代码实现思路就是更加合理的选择了
3. 里式替换(LSP)
3.1 如何理解“里式替换原则”?
里式替换原则的英文翻译是:Liskov Substitution Principle,缩写为 LSP。这个原则最早是在 1986 年由 Barbara Liskov 提出,原文如下:
If S is a subtype of T, then objects of type T may be replaced with objects of type S, without breaking the program.
在 1996 年,Robert Martin 在他的 SOLID 原则中,重新描述了这个原则,原文如下:
Functions that use pointers of references to base classes must be able to use objects of derived classes without knowing it.
综合两者的描述,翻译成中文即:子类对象(object of subtype/derived class)能够替换程序(program)中父类对象(object of base/parent class)出现的任何地方,并且保证原来程序的逻辑行为(behavior)不变及正确性不被破坏
如下例,父类 Transporter 使用 org.apache.http 库中的 HttpClient 类来传输网络数据。子类 SecurityTransporter 继承父类 Transporter,增加了额外的功能,支持传输 appId 和 appToken 安全认证信息
public class Transporter {
private HttpClient httpClient;
public Transporter(HttpClient httpClient) {
this.httpClient = httpClient;
}
public Response sendRequest(Request request) {
// ...use httpClient to send request
}
}
public class SecurityTransporter extends Transporter {
private String appId;
private String appToken;
public SecurityTransporter(HttpClient httpClient, String appId, String appToken) {
super(httpClient);
this.appId = appId;
this.appToken = appToken;
}
@Override
public Response sendRequest(Request request) {
if (StringUtils.isNotBlank(appId) && StringUtils.isNotBlank(appToken)) {
request.addPayload("app-id", appId);
request.addPayload("app-token", appToken);
}
return super.sendRequest(request);
}
}
public class Demo {
public void demoFunction(Transporter transporter) {
Reuqest request = new Request();
//... 省略设置 request 中数据值的代码...
Response response = transporter.sendRequest(request);
//... 省略其他逻辑...
}
}
// 里式替换原则
Demo demo = new Demo();
demo.demofunction(new SecurityTransporter(/* 省略参数 */););
在上面的代码中,子类 SecurityTransporter 的设计完全符合里式替换原则,可以替换父类出现的任何位置,并且原来代码的逻辑行为不变且正确性也没有被破坏
这样一看,刚刚的代码设计不就是简单利用了面向对象的多态特性吗?多态和里式替换原则说的是不是一回事呢?从刚刚的例子和定义描述来看,里式替换原则跟多态看起来确实有点类似,但实际上它们完全是两回事。为什么这么说呢?
假如需要对 SecurityTransporter 类中 sendRequest() 函数稍加改造一下。改造前,如果 appId 或者 appToken 没有设置,就不做校验;改造后,如果 appId 或者 appToken 没有设置,则直接抛出NoAuthorizationRuntimeException 未授权异常。改造前后的代码对比如下所示:
// 改造前:
public class SecurityTransporter extends Transporter {
//... 省略其他代码..
@Override
public Response sendRequest(Request request) {
if (StringUtils.isNotBlank(appId) && StringUtils.isNotBlank(appToken)) {
request.addPayload("app-id", appId);
request.addPayload("app-token", appToken);
}
return super.sendRequest(request);
}
}
// 改造后:
public class SecurityTransporter extends Transporter {
//... 省略其他代码..
@Override
public Response sendRequest(Request request) {
if (StringUtils.isBlank(appId) || StringUtils.isBlank(appToken)) {
throw new NoAuthorizationRuntimeException(...);
}
request.addPayload("app-id", appId);
request.addPayload("app-token", appToken);
return super.sendRequest(request);
}
}
在改造之后的代码中,如果传递进 demoFunction() 函数的是父类 Transporter 对象,那 demoFunction() 函数并不会有异常抛出,但如果传递给 demoFunction() 函数的是子类 SecurityTransporter 对象,那 demoFunction() 有可能会有异常抛出。尽管代码中抛出的是运行时异常(Runtime Exception),可以不在代码中显式地捕获处理,但子类替换父类传递进 demoFunction 函数之后,整个程序的逻辑行为有了改变
虽然改造之后的代码仍然可以通过 Java 的多态语法,动态地用子类 SecurityTransporter 来替换父类 Transporter,也并不会导致程序编译或者运行报错。但是,从设计思路上来讲,SecurityTransporter 的设计是不符合里式替换原则的
虽然从定义描述和代码实现上来看,多态和里式替换有点类似,但它们关注的角度是不一样的。多态是面向对象编程的一大特性,也是面向对象编程语言的一种语法。它是一种代码实现的思路。而里式替换是一种设计原则,是用来指导继承关系中子类该如何设计的,子类的设计要保证在替换父类的时候,不改变原有程序的逻辑以及不破坏原有程序的正确性
3.2 哪些代码明显违背了 LSP?
实际上,里式替换原则还有另外一个更加能落地、更有指导意义的描述,那就是“Design By Contract”,中文翻译就是“按照协议来设计”
看起来比较抽象,进一步解读一下就是子类在设计的时候,要遵守父类的行为约定(或者叫协议)。父类定义了函数的行为约定,那子类可以改变函数的内部实现逻辑,但不能改变函数原有的行为约定。这里的行为约定包括:函数声明要实现的功能;对输入、输出、异常的约定;甚至包括注释中所罗列的任何特殊说明。实际上,定义中父类和子类之间的关系,也可以替换成接口和实现类之间的关系。几个违反里式替换原则的例子如下:
1、子类违背父类声明要实现的功能
父类中提供的 sortOrdersByAmount() 订单排序函数,是按照金额从小到大来给订单排序的,而子类重写这个 sortOrdersByAmount() 订单排序函数之后,是按照创建日期来给订单排序的。那子类的设计就违背里式替换原则
2、子类违背父类对输入、输出、异常的约定
在父类中,某个函数约定:运行出错的时候返回 null;获取数据为空的时候返回空集合(empty collection)。而子类重载函数之后,实现变了,运行出错返回异常(exception),获取不到数据返回 null。那子类的设计就违背里式替换原则
在父类中,某个函数约定,输入数据可以是任意整数,但子类实现的时候,只允许输入数据是正整数,负数就抛出,也就是说,子类对输入的数据的校验比父类更加严格,那子类的设计就违背了里式替换原则
在父类中,某个函数约定,只会抛出 ArgumentNullException 异常,那子类的设计实现中只允许抛出 ArgumentNullException 异常,任何其他异常的抛出,都会导致子类违背里式替换原则
3、子类违背父类注释中所罗列的任何特殊说明
父类中定义的 withdraw() 提现函数的注释是这么写的:“用户的提现金额不得超过账户余额……”,而子类重写 withdraw() 函数之后,针对 VIP 账号实现了透支提现的功能,也就是提现金额可以大于账户余额,那这个子类的设计也是不符合里式替换原则的
以上便是三种典型的违背里式替换原则的情况。除此之外,判断子类的设计实现是否违背里式替换原则,还有一个小窍门,那就是拿父类的单元测试去验证子类的代码。如果某些单元测试运行失败,就有可能说明,子类的设计实现没有完全地遵守父类的约定,子类有可能违背了里式替换原则
实际上,里式替换这个原则是非常宽松的。一般情况下都不怎么会违背它
4. 接口隔离原则(ISP)
4.1 如何理解“接口隔离原则”?
接口隔离原则的英文翻译是“ Interface Segregation Principle”,缩写为 ISP。Robert Martin 在 SOLID 原则中是这样定义它的:
Clients should not be forced to depend upon interfaces that they do not use.
客户端不应该强迫依赖它不需要的接口其中的“客户端”,可以理解为接口的调用者或者使用者
实际上,“接口”这个名词可以用在很多场合中。在软件开发中,既可以把它看作一组抽象的约定,也可以具体指系统与系统之间的 API 接口,还可以特指面向对象编程语言中的接口等。理解接口隔离原则的关键,就是理解其中的“接口”二字。在这条原则中,可以把“接口”理解为下面三种东西:
- 一组 API 接口集合
- 单个 API 接口或函数
- OOP 中的接口概念
4.1.1 把“接口”理解为一组 API 接口集合
如下例,微服务用户系统提供了一组跟用户相关的 API 给其他系统使用,比如:注册、登录、获取用户信息等。具体代码如下所示:
public interface UserService {
boolean register(String cellphone, String password);
boolean login(String cellphone, String password);
UserInfo getUserInfoById(long id);
UserInfo getUserInfoByCellphone(String cellphone);
}
public class UserServiceImpl implements UserService {
//...
}
现在,后台管理系统要实现删除用户的功能,希望用户系统提供一个删除用户的接口。这个时候该如何来做呢?可能会说只需要在 UserService 中新添加一个 deleteUserByCellphone() 或 deleteUserById() 接口就可以了。这个方法可以解决问题,但是也隐藏了一些安全隐患
删除用户是一个非常慎重的操作,只希望通过后台管理系统来执行,所以这个接口只限于给后台管理系统使用。如果把它放到 UserService 中,那所有使用到 UserService的系统,都可以调用这个接口。不加限制地被其他业务系统调用,就有可能导致误删用户
当然,最好的解决方案是从架构设计的层面,通过接口鉴权的方式来限制接口的调用。不过,如果暂时没有鉴权框架来支持,还可以从代码设计的层面,尽量避免接口被误用。参照接口隔离原则,调用者不应该强迫依赖它不需要的接口,将删除接口单独放到另外一个接口 RestrictedUserService 中,然后将 RestrictedUserService 只打包提供给后台管理系统来使用。具体的代码实现如下所示:
public interface UserService {
boolean register(String cellphone, String password);
boolean login(String cellphone, String password);
UserInfo getUserInfoById(long id);
UserInfo getUserInfoByCellphone(String cellphone);
}
public interface RestrictedUserService {
boolean deleteUserByCellphone(String cellphone);
boolean deleteUserById(long id);
}
public class UserServiceImpl implements UserService, RestrictedUserService {
// ... 省略实现代码...
}
在刚刚的这个例子中,把接口隔离原则中的接口,理解为一组接口集合,它可以是某个微服务的接口,也可以是某个类库的接口等等。在设计微服务或者类库接口的时候,如果部分接口只被部分调用者使用,那就需要将这部分接口隔离出来,单独给对应的调用者使用,而不是强迫其他调用者也依赖这部分不会被用到的接口
4.1.2 把“接口”理解为单个 API 接口或函数
把接口理解为单个接口或函数(这里简称为“函数”)。那接口隔离原则就可以理解为:函数的设计要功能单一,不要将多个不同的功能逻辑在一个函数中实现。如下例:
public class Statistics {
private Long max;
private Long min;
private Long average;
private Long sum;
private Long percentile99;
private Long percentile999;
//... 省略 constructor/getter/setter 等方法...
}
public Statistics count(Collection<Long> dataSet) {
Statistics statistics = new Statistics();
//... 省略计算逻辑...
return statistics;
}
在上面的代码中,count() 函数的功能不够单一,包含很多不同的统计功能,比如,求最大值、最小值、平均值等等。按照接口隔离原则,应该把 count() 函数拆成几个更小粒度的函数,每个函数负责一个独立的统计功能。拆分之后的代码如下所示:
public Long max(Collection<Long> dataSet) { //... }
public Long min(Collection<Long> dataSet) { //... }
public Long average(Colletion<Long> dataSet) { //... }
// ... 省略其他统计函数...
不过在某种意义上讲,count() 函数也不能算是职责不够单一,毕竟它做的事情只跟统计相关。在讲单一职责原则的时候,也提到过类似的问题。实际上,判定功能是否单一,除了很强的主观性,还需要结合具体的场景
如果在项目中,对每个统计需求,Statistics 定义的那几个统计信息都有涉及,那 count() 函数的设计就是合理的。相反,如果每个统计需求只涉及 Statistics 罗列的统计信息中一部分,比如,有的只需要用到 max、min、average 这三类统计信息,有的只需要用到 average、sum。而 count() 函数每次都会把所有的统计信息计算一遍,就会做很多无用功,势必影响代码的性能,特别是在需要统计的数据量很大的时候。所以,在这个应用场景下,count() 函数的设计就有点不合理了,应该按照第二种设计思路,将其拆分成粒度更细的多个统计函数
这里可以发现接口隔离原则跟单一职责原则有点类似,不过稍微还是有点区别。单一职责原则针对的是模块、类、接口的设计。而接口隔离原则相对于单一职责原则,一方面它更侧重于接口的设计,另一方面它的思考的角度不同。它提供了一种判断接口是否职责单一的标准:通过调用者如何使用接口来间接地判定。如果调用者只使用部分接口或接口的部分功能,那接口的设计就不够职责单一
4.1.3 把“接口”理解为 OOP 中的接口概念
把“接口”理解为 OOP 中的接口概念,比如 Java 中的 interface,如下例:
假设项目中用到了三个外部系统:Redis、MySQL、Kafka。每个系统都对应一系列配置信息,比如地址、端口、访问超时时间等。为了在内存中存储这些配置信息,供项目中的其他模块来使用,分别设计实现了三个 Configuration 类:RedisConfig、MysqlConfig、KafkaConfig。如下所示:
public class RedisConfig {
private ConfigSource configSource; // 配置中心(比如 zookeeper)
private String address;
private int timeout;
private int maxTotal;
// 省略其他配置: maxWaitMillis,maxIdle,minIdle...
public RedisConfig(ConfigSource configSource) {
this.configSource = configSource;
}
public String getAddress() {
return this.address;
}
//... 省略其他 get()、init() 方法...
public void update() {
// 从 configSource 加载配置到 address/timeout/maxTotal...
}
}
public class KafkaConfig { //... 省略... }
public class MysqlConfig { //... 省略... }
现在,有一个新的功能需求,希望支持 Redis 和 Kafka 配置信息的热更新。所谓“热更新(hot update)”就是,如果在配置中心中更改了配置信息,希望在不用重启系统的情况下,能将最新的配置信息加载到内存中(也就是 RedisConfig、KafkaConfig 类中)。但是,因为某些原因,并不希望对 MySQL 的配置信息进行热更新
为了实现这样一个功能需求,设计实现了一个 ScheduledUpdater 类,以固定时间频率(periodInSeconds)来调用 RedisConfig、KafkaConfig 的 update() 方法更新配置信息。具体的代码实现如下所示:
public interface Updater {
void update();
}
public class RedisConfig implemets Updater {
//... 省略其他属性和方法...
@Override
public void update() { //... }
}
public class KafkaConfig implements Updater {
//... 省略其他属性和方法...
@Override
public void update() { //... }
}
public class MysqlConfig { //... 省略其他属性和方法... }
public class ScheduledUpdater {
private final ScheduledExecutorService executor = Executors.newSingleThread
private long initialDelayInSeconds;
private long periodInSeconds;
private Updater updater;
public ScheduleUpdater(Updater updater, long initialDelayInSeconds, long periodInSeconds) {
this.updater = updater;
this.initialDelayInSeconds = initialDelayInSeconds;
this.periodInSeconds = periodInSeconds;
}
public void run() {
executor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
updater.update();
}
}, this.initialDelayInSeconds, this.periodInSeconds, TimeUnit.SECONDS)
}
}
public class Application {
ConfigSource configSource = new ZookeeperConfigSource(/* 省略参数 */);
public static final RedisConfig redisConfig = new RedisConfig(configSource);
public static final KafkaConfig kafkaConfig = new KakfaConfig(configSource);
public static final MySqlConfig mysqlConfig = new MysqlConfig(configSource);
public static void main(String[] args) {
ScheduledUpdater redisConfigUpdater = new ScheduledUpdater(redisConfig, 300);
redisConfigUpdater.run();
ScheduledUpdater kafkaConfigUpdater = new ScheduledUpdater(kafkaConfig, 60);
redisConfigUpdater.run();
}
}
刚刚的热更新的需求已经搞定了。现在,又有了一个新的监控功能需求。通过命令行来查看 Zookeeper 中的配置信息是比较麻烦的。所以,希望能有一种更加方便的配置信息查看方式
可以在项目中开发一个内嵌的 SimpleHttpServer,输出项目的配置信息到一个固定的 HTTP 地址,比如:http://127.0.0.1:2389/config 。只需要在浏览器中输入这个地址,就可以显示出系统的配置信息。不过,出于某些原因,只想暴露 MySQL 和 Redis 的配置信息,不想暴露 Kafka 的配置信息。为了实现这样一个功能,还需要对上面的代码做进一步改造。改造之后的代码如下所示:
public interface Updater {
void update();
}
public interface Viewer {
String outputInPlainText();
Map<String, String> output();
}
public class RedisConfig implemets Updater, Viewer {
//... 省略其他属性和方法...
@Override
public void update() { //... }
@Override
public String outputInPlainText() { //... }
@Override
public Map<String, String> output() { //...}
}
public class KafkaConfig implements Updater {
//... 省略其他属性和方法...
@Override
public void update() { //... }
}
public class MysqlConfig implements Viewer {
//... 省略其他属性和方法...
@Override
public String outputInPlainText() { //... }
@Override
public Map<String, String> output () { //...}
}
public class SimpleHttpServer {
private String host;
private int port;
private Map<String, List<Viewer>> viewers = new HashMap<>();
public SimpleHttpServer(String host, int port) {//...}
public void addViewers (String urlDirectory, Viewer viewer){
if (!viewers.containsKey(urlDirectory)) {
viewers.put(urlDirectory, new ArrayList<Viewer>());
}
this.viewers.get(urlDirectory).add(viewer);
}
public void run () { //... }
}
public class Application {
ConfigSource configSource = new ZookeeperConfigSource();
public static final RedisConfig redisConfig = new RedisConfig(configSource)
public static final KafkaConfig kafkaConfig = new KakfaConfig(configSource)
public static final MySqlConfig mysqlConfig = new MySqlConfig(configSource)
public static void main(String[] args) {
ScheduledUpdater redisConfigUpdater = new ScheduledUpdater(redisConfig, 300, 300);
redisConfigUpdater.run();
ScheduledUpdater kafkaConfigUpdater = new ScheduledUpdater(kafkaConfig, 60, 60);
redisConfigUpdater.run();
SimpleHttpServer simpleHttpServer = new SimpleHttpServer(“ 127.0 .0 .1”,2
simpleHttpServer.addViewer("/config", redisConfig);
simpleHttpServer.addViewer("/config", mysqlConfig);
simpleHttpServer.run();
}
}
至此,热更新和监控的需求就都实现了。设计了两个功能非常单一的接口:Updater 和 Viewer。ScheduledUpdater 只依赖 Updater 这个跟热更新相关的接口,不需要被强迫去依赖不需要的 Viewer 接口,满足接口隔离原则。同理,SimpleHttpServer 只依赖跟查看信息相关的 Viewer 接口,不依赖不需要的 Updater 接口,也满足接口隔离原则
如果不遵守接口隔离原则,不设计 Updater 和 Viewer 两个小接口,而是设计一个大而全的 Config 接口,让 RedisConfig、KafkaConfig、MysqlConfig 都实现这个 Config 接口,并且将原来传递给 ScheduledUpdater 的 Updater 和传递给 SimpleHttpServer 的 Viewer,都替换为 Config,那会有什么问题呢?先看一下按照这个思路来实现的代码是什么样的
public interface Config {
void update();
String outputInPlainText();
Map<String, String> output();
}
public class RedisConfig implements Config {
//... 需要实现 Config 的三个接口 update/outputIn.../output
}
public class KafkaConfig implements Config {
//... 需要实现 Config 的三个接口 update/outputIn.../output
}
public class MysqlConfig implements Config {
//... 需要实现 Config 的三个接口 update/outputIn.../output
}
public class ScheduledUpdater {
//... 省略其他属性和方法..
private Config config;
public ScheduleUpdater(Config config, long initialDelayInSeconds, long period) {
this.config = config;
//...
}
//...
}
public class SimpleHttpServer {
private String host;
private int port;
private Map<String, List<Config>> viewers = new HashMap<>();
public SimpleHttpServer(String host, int port) {//...}
public void addViewer (String urlDirectory, Config config){
if (!viewers.containsKey(urlDirectory)) {
viewers.put(urlDirectory, new ArrayList<Config>());
}
viewers.get(urlDirectory).add(config);
}
public void run () { //... }
}
这样的设计思路也是能工作的,但是对比前后两个设计思路,在同样的代码量、实现复杂度、同等可读性的情况下,第一种设计思路显然要比第二种好很多。为什么这么说呢?主要有两点原因
1、第一种设计思路更加灵活、易扩展、易复用
因为 Updater、Viewer 职责更加单一,单一就意味了通用、复用性好。比如,现在又有一个新的需求,开发一个 Metrics 性能统计模块,并且希望将 Metrics 也通过 SimpleHttpServer 显示在网页上,以方便查看。这个时候,尽管 Metrics 跟 RedisConfig 等没有任何关系,但仍然可以让 Metrics 类实现非常通用的 Viewer 接口,复用 SimpleHttpServer 的代码实现。具体的代码如下所示:
public class ApiMetrics implements Viewer {//...}
public class DbMetrics implements Viewer {//...}
public class Application {
ConfigSource configSource = new ZookeeperConfigSource();
public static final RedisConfig redisConfig = new RedisConfig(configSource)
public static final KafkaConfig kafkaConfig = new KakfaConfig(configSource)
public static final MySqlConfig mySqlConfig = new MySqlConfig(configSource)
public static final ApiMetrics apiMetrics = new ApiMetrics();
public static final DbMetrics dbMetrics = new DbMetrics();
public static void main(String[] args) {
SimpleHttpServer simpleHttpServer = new SimpleHttpServer(“127.0.0.1”, 2
simpleHttpServer.addViewer("/config", redisConfig);
simpleHttpServer.addViewer("/config", mySqlConfig);
simpleHttpServer.addViewer("/metrics", apiMetrics);
simpleHttpServer.addViewer("/metrics", dbMetrics);
simpleHttpServer.run();
}
}
2、第二种设计思路在代码实现上做了一些无用功
因为 Config 接口中包含两类不相关的接口,一类是 update(),一类是 output() 和 outputInPlainText()。理论上,KafkaConfig 只需要实现 update() 接口,并不需要实现 output() 相关的接口。同理,MysqlConfig 只需要实现 output() 相关接口,并需要实现 update() 接口。但第二种设计思路要求 RedisConfig、KafkaConfig、MySqlConfig 必须同时实现 Config 的所有接口函数(update、output、outputInPlainText)。除此之外,如果要往 Config 中继续添加一个新的接口,那所有的实现类都要改动。相反,如果接口粒度比较小,那涉及改动的类就比较少
5. 依赖反转(DIP)
前面讲到,单一职责原则和开闭原则的原理比较简单,但是,想要在实践中用好却比较难。依赖反转原则正好相反。这个原则用起来比较简单,但概念理解起来比较难。比如如下问题:
- “依赖反转”这个概念指的是“谁跟谁”的“什么依赖”被反转了?“反转”两个字该如何理解?
- 还有另外两个概念:“控制反转”和“依赖注入”。这两个概念跟“依赖反转”有什么区别和联系呢?它们说的是同一个事情吗?
- Spring 框架中的 IOC 跟这些概念又有什么关系呢?
5.1 控制反转(IOC)
控制反转的英文翻译是 Inversion Of Control,缩写为 IOC。如下例:
public class UserServiceTest {
public static boolean doTest() {
// ...
}
public static void main(String[] args) {// 这部分逻辑可以放到框架中
if (doTest()) {
System.out.println("Test succeed.");
} else {
System.out.println("Test failed.");
}
}
}
在上面的代码中,所有的流程都由程序员来控制。如果抽象出一个下面这样一个框架,再来看如何利用框架来实现同样的功能。具体的代码实现如下所示:
public abstract class TestCase {
public void run() {
if (doTest()) {
System.out.println("Test succeed.");
} else {
System.out.println("Test failed.");
}
}
public abstract void doTest();
}
public class JunitApplication {
private static final List<TestCase> testCases = new ArrayList<>();
public static void register(TestCase testCase) {
testCases.add(testCase);
}
public static final void main(String[] args) {
for (TestCase case: testCases) {
case.run();
}
}
}
把这个简化版本的测试框架引入到工程中之后,只需要在框架预留的扩展点,也就是 TestCase 类中的 doTest() 抽象函数中,填充具体的测试代码就可以实现之前的功能了,完全不需要写负责执行流程的 main() 函数了。 具体的代码如下所示:
public class UserServiceTest extends TestCase {
@Override
public boolean doTest() {
// ...
}
}
// 注册操作还可以通过配置的方式来实现,不需要程序员显示调用 register()
JunitApplication.register(new UserServiceTest();
上面这个例子,就是典型的通过框架来实现“控制反转”的例子。框架提供了一个可扩展的代码骨架,用来组装对象、管理整个执行流程。程序员利用框架进行开发的时候,只需要往预留的扩展点上,添加跟自己业务相关的代码,就可以利用框架来驱动整个程序流程的执行
这里的“控制”指的是对程序执行流程的控制,而“反转”指的是在没有使用框架之前,程序员自己控制整个程序的执行。在使用框架之后,整个程序的执行流程可以通过框架来控制。流程的控制权从程序员“反转”到了框架
实际上,实现控制反转的方法有很多,除了上面所示的类似于模板设计模式的方法之外,还有下面的依赖注入等方法,所以,控制反转并不是一种具体的实现技巧,而是一个比较笼统的设计思想,一般用来指导框架层面的设计
5.2 依赖注入(DI)
依赖注入跟控制反转恰恰相反,它是一种具体的编码技巧。依赖注入的英文翻译是 Dependency Injection,缩写为 DI。对于这个概念,有一个非常形象的说法,那就是:依赖注入是一个标价 25 美元,实际上只值 5 美分的概念。也就是说,这个概念听起来很“高大上”,实际上,理解、应用起来非常简单
依赖注入用一句话来概括就是:不通过 new() 的方式在类内部创建依赖类对象,而是将依赖的类对象在外部创建好之后,通过构造函数、函数参数等方式传递(或注入)给类使用
如下例,Notification 类负责消息推送,依赖 MessageSender 类实现推送商品促销、验证码等消息给用户。分别用依赖注入和非依赖注入两种方式来实现一下。具体的实现代码如下所示:
// 非依赖注入实现方式
public class Notification {
private MessageSender messageSender;
public Notification() {
this.messageSender = new MessageSender(); // 此处有点像 hardcode
}
public void sendMessage(String cellphone, String message) {
//... 省略校验逻辑等...
this.messageSender.send(cellphone, message);
}
}
public class MessageSender {
public void send(String cellphone, String message) {
//....
}
}
// 使用 Notification
Notification notification = new Notification();
// 依赖注入的实现方式
public class Notification {
private MessageSender messageSender;
// 通过构造函数将 messageSender 传递进来
public Notification(MessageSender messageSender) {
this.messageSender = messageSender;
}
public void sendMessage(String cellphone, String message) {
//... 省略校验逻辑等...
this.messageSender.send(cellphone, message);
}
}
// 使用 Notification
MessageSender messageSender = new MessageSender();
Notification notification = new Notification(messageSender);
通过依赖注入的方式来将依赖的类对象传递进来,这样就提高了代码的扩展性,可以灵活地替换依赖的类。这一点在我们之前讲“开闭原则”的时候也提到过。当然,上面代码还可以把 MessageSender 定义成接口,基于接口而非实现编程。改造后的代码如下所示:
public class Notification {
private MessageSender messageSender;
public Notification(MessageSender messageSender) {
this.messageSender = messageSender;
}
public void sendMessage(String cellphone, String message) {
this.messageSender.send(cellphone, message);
}
}
public interface MessageSender {
void send(String cellphone, String message);
}
// 短信发送类
public class SmsSender implements MessageSender {
@Override
public void send(String cellphone, String message) {
//....
}
}
// 站内信发送类
public class InboxSender implements MessageSender {
@Override
public void send(String cellphone, String message) {
//....
}
}
// 使用 Notification
MessageSender messageSender = new SmsSender();
Notification notification = new Notification(messageSender);
实际上,只需要掌握刚刚举的这个例子,就等于完全掌握了依赖注入。尽管依赖注入非常简单,但却非常有用,它是编写可测试性代码最有效的手段
5.3 依赖注入框架(DI Framework)
在采用依赖注入实现的 Notification 类中,虽然不需要用类似 hard code 的方式,在类内部通过 new 来创建 MessageSender 对象,但是,这个创建对象、组装(或注入)对象的工作仅仅是被移动到了更上层代码而已,还是需要程序员自己来实现。具体代码如下所示:
public class Demo {
public static final void main(String args[]) {
MessageSender sender = new SmsSender(); // 创建对象
Notification notification = new Notification(sender);// 依赖注入
notification.sendMessage("13918942177", " 短信验证码:2346");
}
}
在实际的软件开发中,一些项目可能会涉及几十、上百、甚至几百个类,类对象的创建和依赖注入会变得非常复杂。如果这部分工作都是靠程序员自己写代码来完成,容易出错且开发成本也比较高。而对象创建和依赖注入的工作,本身跟具体的业务无关,完全可以抽象成框架来自动完成
这个框架就是“依赖注入框架”。只需要通过依赖注入框架提供的扩展点,简单配置一下所有需要创建的类对象、类与类之间的依赖关系,就可以实现由框架来自动创建对象、管理对象的生命周期、依赖注入等原本需要程序员来做的事情
实际上,现成的依赖注入框架有很多,比如 Google Guice、Java Spring、Pico Container、Butterfly Container 等。不过,Spring 框架自己声称是控制反转容器(Inversion Of Control Container)
实际上,这两种说法都没错。只是控制反转容器这种表述是一种非常宽泛的描述,DI 依赖注入框架的表述更具体、更有针对性。因为前面讲到实现控制反转的方式有很多,除了依赖注入,还有模板模式等,而 Spring 框架的控制反转主要是通过依赖注入来实现的。不过这点区分并不是很明显,也不是很重要
5.4 依赖反转原则(DIP)
依赖反转原则。依赖反转原则的英文翻译是 Dependency Inversion Principle,缩写为 DIP。中文翻译有时候也叫依赖倒置原则。原文如下:
High-level modules shouldn’t depend on low-level modules. Both modules should depend on abstractions. In addition, abstractions shouldn’t depend on details. Details depend on abstractions.
高层模块(high-level modules)不要依赖低层模块(low-level)。高层模块和低层模块应该通过抽象(abstractions)来互相依赖。除此之外,抽象(abstractions)不要依赖具体实现细节(details),具体实现细节(details)依赖抽象(abstractions)
所谓高层模块和低层模块的划分,简单来说就是,在调用链上,调用者属于高层,被调用者属于低层。在平时的业务代码开发中,高层模块依赖底层模块是没有任何问题的。实际上,这条原则主要还是用来指导框架层面的设计,跟前面讲到的控制反转类似。拿 Tomcat这个 Servlet 容器作为例子来解释一下
Tomcat 是运行 Java Web 应用程序的容器。编写的 Web 应用程序代码只需要部署在 Tomcat 容器下,便可以被 Tomcat 容器调用执行。按照之前的划分原则,Tomcat 就是高层模块,编写的 Web 应用程序代码就是低层模块。Tomcat 和应用程序代码之间并没有直接的依赖关系,两者都依赖同一个“抽象”,也就是 Sevlet 规范。Servlet 规范不依赖具体的 Tomcat 容器和应用程序的实现细节,而 Tomcat 容器和应用程序依赖 Servlet 规范
6. KISS 原则
KISS 原则的英文描述有好几个版本,比如下面这几个:
- Keep It Simple and Stupid.
- Keep It Short and Simple.
- Keep It Simple and Straightforward.
不过,仔细看就会发现,它们要表达的意思其实差不多,翻译成中文就是:尽量保持简单
KISS 原则算是一个万金油类型的设计原则,可以应用在很多场景中。它不仅经常用来指导软件开发,还经常用来指导更加广泛的系统设计、产品设计等,比如,冰箱、建筑、iPhone 手机的设计等等。不过,这里重点讲解如何在编码开发中应用这条原则
代码的可读性和可维护性是衡量代码质量非常重要的两个标准。而 KISS 原则就是保持代码可读和可维护的重要手段。代码足够简单,也就意味着很容易读懂,bug 比较难隐藏。即便出现 bug,修复起来也比较简单
不过,这条原则只是告诉我们,要保持代码“Simple and Stupid”,但并没有讲到,什么样的代码才是“Simple and Stupid”的,更没有给出特别明确的方法论,来指导如何开发出“Simple and Stupid”的代码。所以,看着非常简单,但不能落地
6.1 代码行数越少就越“简单”吗?
先看一个例子。下面这三段代码可以实现同样一个功能:检查输入的字符串 ipAddress 是否是合法的 IP 地址。一个合法的 IP 地址由四个数字组成,并且通过“.”来进行分割。每组数字的取值范围是 0~255。第一组数字比较特殊,不允许为 0
// 第一种实现方式: 使用正则表达式
public boolean isValidIpAddressV1(String ipAddress) {
if (StringUtils.isBlank(ipAddress)) return false;
String regex = "^(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[1-9])\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)$";
return ipAddress.matches(regex);
}
// 第二种实现方式: 使用现成的工具类
public boolean isValidIpAddressV2(String ipAddress) {
if (StringUtils.isBlank(ipAddress)) return false;
String[] ipUnits = StringUtils.split(ipAddress, '.');
if (ipUnits.length != 4) {
return false;
}
for (int i = 0; i < 4; ++i) {
int ipUnitIntValue;
try {
ipUnitIntValue = Integer.parseInt(ipUnits[i]);
} catch (NumberFormatException e) {
return false;
}
if (ipUnitIntValue < 0 || ipUnitIntValue > 255) {
return false;
}
if (i == 0 && ipUnitIntValue == 0) {
return false;
}
}
return true;
}
// 第三种实现方式: 不使用任何工具类
public boolean isValidIpAddressV3(String ipAddress) {
char[] ipChars = ipAddress.toCharArray();
int length = ipChars.length;
int ipUnitIntValue = -1;
boolean isFirstUnit = true;
int unitsCount = 0;
for (int i = 0; i < length; ++i) {
char c = ipChars[i];
if (c == '.') {
if (ipUnitIntValue < 0 || ipUnitIntValue > 255) return false;
if (isFirstUnit && ipUnitIntValue == 0) return false;
if (isFirstUnit) isFirstUnit = false;
ipUnitIntValue = -1;
unitsCount++;
continue;
}
if (c < '0' || c > '9') {
return false;
}
if (ipUnitIntValue == -1) ipUnitIntValue = 0;
ipUnitIntValue = ipUnitIntValue * 10 + (c - '0');
}
if (ipUnitIntValue < 0 || ipUnitIntValue > 255) return false;
if (unitsCount != 3) return false;
return true;
}
第一种实现方式利用的是正则表达式,只用三行代码就把这个问题搞定了。它的代码行数最少,那是不是就最符合 KISS 原则呢?答案是否定的。虽然代码行数最少,看似最简单,实际上却很复杂。这正是因为它使用了正则表达式
一方面,正则表达式本身是比较复杂的,写出完全没有 bug 的正则表达本身就比较有挑战;另一方面,并不是每个程序员都精通正则表达式。对于不怎么懂正则表达式的同事来说,看懂并且维护这段正则表达式是比较困难的。这种实现方式会导致代码的可读性和可维护性变差,所以,从 KISS 原则的设计初衷上来讲,这种实现方式并不符合 KISS 原则
第二种实现方式使用了 StringUtils 类、Integer 类提供的一些现成的工具函数,来处理 IP地址字符串。第三种实现方式,不使用任何工具函数,而是通过逐一处理 IP 地址中的字符,来判断是否合法。从代码行数上来说,这两种方式差不多。但是,第三种要比第二种更加有难度,更容易写出 bug。从可读性上来说,第二种实现方式的代码逻辑更清晰、更好理解。所以,在这两种实现方式中,第二种实现方式更加“简单”,更加符合 KISS 原则
不过可能会说,第三种实现方式虽然实现起来稍微有点复杂,但性能要比第二种实现方式高一些啊。从性能的角度来说,选择第三种实现方式是不是更好些呢?
一般来说,工具类的功能都比较通用和全面,所以,在代码实现上,需要考虑和处理更多的细节,执行效率就会有所影响。而第三种实现方式,完全是自己操作底层字符,只针对 IP 地址这一种格式的数据输入来做处理,没有太多多余的函数调用和其他不必要的处理逻辑,所以,在执行效率上,这种类似定制化的处理代码方式肯定比通用的工具类要高些
不过,尽管第三种实现方式性能更高些,但还是更倾向于选择第二种实现方法。那是因为第三种实现方式实际上是一种过度优化。除非 isValidIpAddress() 函数是影响系统性能的瓶颈代码,否则,这样优化的投入产出比并不高,增加了代码实现的难度、牺牲了代码的可读性,性能上的提升却并不明显
6.2 代码逻辑复杂就违背 KISS 原则吗?
前面提到,并不是代码行数越少就越“简单”,还要考虑逻辑复杂度、实现难度、代码的可读性等。那如果一段代码的逻辑复杂、实现难度大、可读性也不太好,是不是就一定违背 KISS 原则呢?先看下面的代码:
// KMP algorithm: a, b 分别是主串和模式串;n, m 分别是主串和模式串的长度。
public static int kmp(char[] a, int n, char[] b, int m) {
int[] next = getNexts(b, m);
int j = 0;
for (int i = 0; i < n; ++i) {
while (j > 0 && a[i] != b[j]) { // 一直找到 a[i] 和 b[j]
j = next[j - 1] + 1;
}
if (a[i] == b[j]) {
++j;
}
if (j == m) { // 找到匹配模式串的了
return i - m + 1;
}
}
return -1;
}
// b 表示模式串,m 表示模式串的长度
private static int[] getNexts(char[] b, int m) {
int[] next = new int[m];
next[0] = -1;
int k = -1;
for (int i = 1; i < m; ++i) {
while (k != -1 && b[k + 1] != b[i]) {
k = next[k];
}
if (b[k + 1] == b[i]) {
++k;
}
next[i] = k;
}
return next;
}
这段代码完全符合刚提到的逻辑复杂、实现难度大、可读性差的特点,但它并不违反 KISS 原则。为什么这么说呢?
KMP 算法以快速高效著称。当需要处理长文本字符串匹配问题(几百 MB 大小文本内容的匹配),或者字符串匹配是某个产品的核心功能(比如 Vim、Word 等文本编辑器),又或者字符串匹配算法是系统性能瓶颈的时候,就应该选择尽可能高效的 KMP算法。而 KMP 算法本身具有逻辑复杂、实现难度大、可读性差的特点。本身就复杂的问题,用复杂的方法解决,并不违背 KISS 原则
不过,平时的项目开发中涉及的字符串匹配问题,大部分都是针对比较小的文本。在这种情况下,直接调用编程语言提供的现成的字符串匹配函数就足够了。如果非得用 KMP 算法、BM 算法来实现字符串匹配,那就真的违背 KISS 原则了。也就是说,同样的代码,在某个业务场景下满足 KISS 原则,换一个应用场景可能就不满足了
6.3 如何写出满足 KISS 原则的代码?
- 不要使用同事可能不懂的技术来实现代码。比如前面例子中的正则表达式,还有一些编程语言中过于高级的语法等
- 不要重复造轮子,要善于使用已经有的工具类库。经验证明,自己去实现这些类库,出 bug 的概率会更高,维护的成本也比较高
- 不要过度优化。不要过度使用一些奇技淫巧(比如,位运算代替算术运算、复杂的条件语句代替 if-else、使用一些过于底层的函数等)来优化代码,牺牲代码的可读性
实际上,代码是否足够简单是一个挺主观的评判。同样的代码,有的人觉得简单,有的人觉得不够简单。而往往自己编写的代码,自己都会觉得够简单。所以,评判代码是否简单,还有一个很有效的间接方法,那就是 code review。如果在 code review 的时候,同事对你的代码有很多疑问,那就说明你的代码有可能不够“简单”,需要优化
在做开发的时候,一定不要过度设计,不要觉得简单的东西就没有技术含量。实际上,越是能用简单的方法解决复杂的问题,越能体现一个人的能力
7. YAGNI
YAGNI 原则的英文全称是:You Ain’t Gonna Need It。直译就是:你不会需要它。这条原则也算是万金油了。当用在软件开发中的时候,它的意思是:不要去设计当前用不到的功能;不要去编写当前用不到的代码。实际上,这条原则的核心思想就是:不要做过度设计
比如,系统暂时只用 Redis 存储配置信息,以后可能会用到 ZooKeeper。根据 YAGNI 原则,在未用到 ZooKeeper 之前,没必要提前编写这部分代码。当然,这并不是说就不需要考虑代码的扩展性。还是要预留好扩展点,等到需要的时候,再去实现 ZooKeeper 存储配置信息这部分代码
再比如,不要在项目中提前引入不需要依赖的开发包。对于 Java 程序员来说,经常使用 Maven 或者 Gradle 来管理依赖的类库(library)。有些同事为了避免开发中 library 包缺失而频繁地修改 Maven 或者 Gradle 配置文件,提前往项目里引入大量常用的 library 包。实际上,这样的做法也是违背 YAGNI 原则的
YAGNI 原则跟 KISS 原则并非一回事儿。KISS 原则讲的是“如何做”的问题(尽量保持简单),而 YAGNI 原则说的是“要不要做”的问题(当前不需要的就不要做)
8. DRY 原则
英文描述为:Don’t Repeat Yourself。中文直译为:不要重复自己。将它应用在编程中,可以理解为:不要写重复的代码
但只要两段代码长得一样,那就是违反 DRY 原则了吗?答案是否定的。这是很多人对这条原则存在的误解。实际上,重复的代码不一定违反 DRY 原则,而且有些看似不重复的代码也有可能违反 DRY 原则。三种典型的代码重复情况,它们分别是:
- 实现逻辑重复
- 功能语义重复
- 代码执行重复
这三种代码重复,有的看似违反 DRY,实际上并不违反;有的看似不违反,实际上却违反了
8.1 实现逻辑重复
public class UserAuthenticator {
public void authenticate(String username, String password) {
if (!isValidUsername(username)) {
// ...throw InvalidUsernameException...
}
if (!isValidPassword(password)) {
// ...throw InvalidPasswordException...
}
//... 省略其他代码...
}
private boolean isValidUsername(String username) {
// check not null, not empty
if (StringUtils.isBlank(username)) {
return false;
}
// check length: 4~64
int length = username.length();
if (length < 4 || length > 64) {
return false;
}
// contains only lowcase characters
if (!StringUtils.isAllLowerCase(username)) {
return false;
}
// contains only a~z,0~9,dot
for (int i = 0; i < length; ++i) {
char c = username.charAt(i);
if (!(c >= 'a' && c <= 'z') || (c >= '0' && c <= '9') || c == '.') {
return false;
}
}
return true;
}
private boolean isValidPassword(String password) {
// check not null, not empty
if (StringUtils.isBlank(password)) {
return false;
}
// check length: 4~64
int length = password.length();
if (length < 4 || length > 64) {
return false;
}
// contains only lowcase characters
if (!StringUtils.isAllLowerCase(password)) {
return false;
}
// contains only a~z,0~9,dot
for (int i = 0; i < length; ++i) {
char c = password.charAt(i);
if (!(c >= 'a' && c <= 'z') || (c >= '0' && c <= '9') || c == '.') {
return false;
}
}
return true;
}
}
在上面的代码中,有两处非常明显的重复的代码片段:isValidUserName() 函数和 isValidPassword() 函数。重复的代码被敲了两遍,或者简单 copy-paste 了一下,看起来明显违反 DRY 原则。为了移除重复的代码,对上面的代码做下重构,将 isValidUserName() 函数和 isValidPassword() 函数,合并为一个更通用的函数 isValidUserNameOrPassword()。重构后的代码如下所示:
public class UserAuthenticatorV2 {
public void authenticate(String userName, String password) {
if (!isValidUsernameOrPassword(userName)) {
// ...throw InvalidUsernameException...
}
if (!isValidUsernameOrPassword(password)) {
// ...throw InvalidPasswordException...
}
}
private boolean isValidUsernameOrPassword(String usernameOrPassword) {
// 省略实现逻辑
// 跟原来的 isValidUsername() 或 isValidPassword() 的实现逻辑一样...
return true;
}
}
经过重构之后,代码行数减少了,也没有重复的代码了,是不是更好了呢?答案是否定的
单从名字上看就能发现,合并之后的 isValidUserNameOrPassword() 函数,负责两件事情:验证用户名和验证密码,违反了“单一职责原则”和“接口隔离原则”。实际上,即便将两个函数合并成 isValidUserNameOrPassword(),代码仍然存在问题
因为 isValidUserName() 和 isValidPassword() 两个函数,虽然从代码实现逻辑上看起来是重复的,但是从语义上并不重复。所谓“语义不重复”指的是:从功能上来看,这两个函数干的是完全不重复的两件事情,一个是校验用户名,另一个是校验密码。尽管在目前的设计中,两个校验逻辑是完全一样的,但如果按照第二种写法,将两个函数的合并,那就会存在潜在的问题。在未来的某一天,如果修改了密码的校验逻辑,比如,允许密码包含大写字符,允许密码的长度为 8 到 64 个字符,那这个时候,isValidUserName() 和
isValidPassword() 的实现逻辑就会不相同。就要把合并后的函数,重新拆成合并前的那两个函数
尽管代码的实现逻辑是相同的,但语义不同,判定它并不违反 DRY 原则。对于包含重复代码的问题,可以通过抽象成更细粒度函数的方式来解决。比如将校验只包含 a~z、0~9、dot 的逻辑封装成 boolean onlyContains(String str, String charlist); 函数
8.2 功能语义重复
在同一个项目代码中有下面两个函数:isValidIp() 和 checkIfIpValid()。尽管两个函数的命名不同,实现逻辑不同,但功能是相同的,都是用来判定 IP 地址是否合法的
之所以在同一个项目中会有两个功能相同的函数,那是因为这两个函数是由两个不同的同事开发的,其中一个同事在不知道已经有了 isValidIp() 的情况下,自己又定义并实现了同样用来校验 IP 地址是否合法的 checkIfIpValid() 函数。那在同一项目代码中,存在如下两个函数,是否违反 DRY 原则呢?
public boolean isValidIp(String ipAddress) {
if (StringUtils.isBlank(ipAddress)) return false;
String regex = "^(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[1-9])\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)$";
return ipAddress.matches(regex);
}
public boolean checkIfIpValid(String ipAddress) {
if (StringUtils.isBlank(ipAddress)) return false;
String[] ipUnits = StringUtils.split(ipAddress, '.');
if (ipUnits.length != 4) {
return false;
}
for (int i = 0; i < 4; ++i) {
int ipUnitIntValue;
try {
ipUnitIntValue = Integer.parseInt(ipUnits[i]);
} catch (NumberFormatException e) {
return false;
}
if (ipUnitIntValue < 0 || ipUnitIntValue > 255) {
return false;
}
if (i == 0 && ipUnitIntValue == 0) {
return false;
}
}
return true;
}
这个例子跟上个例子正好相反。上一个例子是代码实现逻辑重复,但语义不重复,并不认为它违反了 DRY 原则。而在这个例子中,尽管两段代码的实现逻辑不重复,但语义重复,也就是功能重复,认为它违反了 DRY 原则。应该在项目中,统一一种实现思路,所有用到判断 IP 地址是否合法的地方,都统一调用同一个函数
假设不统一实现思路,那有些地方调用了 isValidIp() 函数,有些地方又调用了 checkIfIpValid() 函数,这就会导致代码看起来很奇怪,相当于给代码“埋坑”,给不熟悉这部分代码的同事增加了阅读的难度。同事有可能研究了半天,觉得功能是一样的,但又有点疑惑,觉得是不是有更高深的考量,才定义了两个功能类似的函数,最终发现居然是代码设计的问题
除此之外,如果哪天项目中 IP 地址是否合法的判定规则改变了,比如:255.255.255.255 不再被判定为合法的了,相应地,对 isValidIp() 的实现逻辑做了相应的修改,但却忘记了修改 checkIfIpValid() 函数。又或者,压根就不知道还存在一个功能相同的 checkIfIpValid() 函数,这样就会导致有些代码仍然使用老的 IP 地址判断逻辑,导致出现一些莫名其妙的 bug
8.3 代码执行重复
前两个例子一个是实现逻辑重复,一个是语义重复,再来看第三个例子。其中,UserService 中 login() 函数用来校验用户登录是否成功。如果失败,就返回异常;如果成功,就返回用户信息。具体代码如下所示:
public class UserService {
private UserRepo userRepo;// 通过依赖注入或者 IOC 框架注入
public User login(String email, String password) {
boolean existed = userRepo.checkIfUserExisted(email, password);
if (!existed) {
// ... throw AuthenticationFailureException...
}
User user = userRepo.getUserByEmail(email);
return user;
}
}
public class UserRepo {
public boolean checkIfUserExisted(String email, String password) {
if (!EmailValidation.validate(email)) {
// ... throw InvalidEmailException...
}
if (!PasswordValidation.validate(password)) {
// ... throw InvalidPasswordException...
}
//...query db to check if email&password exists...
}
public User getUserByEmail(String email) {
if (!EmailValidation.validate(email)) {
// ... throw InvalidEmailException...
}
//...query db to get user by email...
}
}
上面这段代码,既没有逻辑重复,也没有语义重复,但仍然违反了 DRY 原则。这是因为代码中存在“执行重复”。我们一块儿来看下,到底哪些代码被重复执行了?
重复执行最明显的一个地方,就是在 login() 函数中,email 的校验逻辑被执行了两次。一次是在调用 checkIfUserExisted() 函数的时候,另一次是调用 getUserByEmail() 函数的时候。这个问题解决起来比较简单,只需要将校验逻辑从 UserRepo 中移除,统一放到 UserService 中就可以了
除此之外,代码中还有一处比较隐蔽的执行重复,实际上,login() 函数并不需要调用 checkIfUserExisted() 函数,只需要调用一次 getUserByEmail() 函数,从数据库中获取到用户的 email、password 等信息,然后跟用户输入的 email、password 信息做对比,依次判断是否登录成功
实际上,这样的优化是很有必要的。因为 checkIfUserExisted() 函数和 getUserByEmail() 函数都需要查询数据库,而数据库这类的 I/O 操作是比较耗时的。在写代码的时候,应当尽量减少这类 I/O 操作
按照刚刚的修改思路,把代码重构一下,移除“重复执行”的代码,只校验一次 email 和 password,并且只查询一次数据库。重构之后的代码如下所示:
public class UserService {
private UserRepo userRepo;// 通过依赖注入或者 IOC 框架注入
public User login(String email, String password) {
if (!EmailValidation.validate(email)) {
// ... throw InvalidEmailException...
}
if (!PasswordValidation.validate(password)) {
// ... throw InvalidPasswordException...
}
User user = userRepo.getUserByEmail(email);
if (user == null || !password.equals(user.getPassword()) {
// ... throw AuthenticationFailureException...
}
return user;
}
}
public class UserRepo {
public boolean checkIfUserExisted(String email, String password) {
//...query db to check if email&password exists
}
public User getUserByEmail(String email) {
//...query db to get user by email...
}
}
8.4 代码复用性(Code Reusability)
8.4.1 什么是代码的复用性?
首先来区分三个概念:代码复用性(Code Reusability)、代码复用(Code Resue)和 DRY 原则
- 代码复用表示一种行为:在开发新功能的时候,尽量复用已经存在的代码
- 代码的可复用性表示一段代码可被复用的特性或能力:在编写代码的时候,让代码尽量可复用
- DRY 原则是一条原则:不要写重复的代码
从定义描述上,它们好像有点类似,但深究起来,三者的区别还是蛮大的
“不重复”并不代表“可复用”
在一个项目代码中,可能不存在任何重复的代码,但也并不表示里面有可复用的代码,不重复和可复用完全是两个概念。所以,从这个角度来说,DRY 原则跟代码的可复用性讲的是两回事
“复用”和“可复用性”关注角度不同
代码“可复用性”是从代码开发者的角度来讲的,“复用”是从代码使用者的角度来讲的。比如,A 同事编写了一个 UrlUtils 类,代码的“可复用性”很好。B 同事在开发新功能的时候,直接“复用”A 同事编写的 UrlUtils 类
尽管复用、可复用性、DRY 原则这三者从理解上有所区别,但实际上要达到的目的都是类似的,都是为了减少代码量,提高代码的可读性、可维护性。除此之外,复用已经经过测试的老代码,bug 会比从零重新开发要少
“复用”这个概念不仅可以指导细粒度的模块、类、函数的设计开发,实际上,一些框架、类库、组件等的产生也都是为了达到复用的目的。比如,Spring 框架、Google Guava 类库、UI 组件等等
8.4.2 怎么提高代码复用性?
- 减少代码耦合
对于高度耦合的代码,当希望复用其中的一个功能,想把这个功能的代码抽取出来成为一个独立的模块、类或者函数的时候,往往会发现牵一发而动全身。移动一点代码,就要牵连到很多其他相关的代码。所以,高度耦合的代码会影响到代码的复用性,我们要尽量减少代码耦合 - 满足单一职责原则
如果职责不够单一,模块、类设计得大而全,那依赖它的代码或者它依赖的代码就会比较多,进而增加了代码的耦合。根据上一点,也就会影响到代码的复用性。相反,越细粒度的代码,代码的通用性会越好,越容易被复用 - 模块化
这里的“模块”,不单单指一组类构成的模块,还可以理解为单个类、函数。要善于将功能独立的代码,封装成模块。独立的模块就像一块一块的积木,更加容易复用,可以直接拿来搭建更加复杂的系统 - 业务与非业务逻辑分离
越是跟业务无关的代码越是容易复用,越是针对特定业务的代码越难复用。所以,为了复用跟业务无关的代码,将业务和非业务逻辑代码分离,抽取成一些通用的框架、类库、组件等 - 通用代码下沉
从分层的角度来看,越底层的代码越通用、会被越多的模块调用,越应该设计得足够可复用。一般情况下,在代码分层之后,为了避免交叉调用导致调用关系混乱,只允许上层代码调用下层代码及同层代码之间的调用,杜绝下层代码调用上层代码。所以,通用的代码尽量下沉到更下层 - 继承、多态、抽象、封装
在讲面向对象特性的时候讲到,利用继承,可以将公共的代码抽取到父类,子类复用父类的属性和方法。利用多态,可以动态地替换一段代码的部分逻辑,让这段代码可复用。除此之外,抽象和封装,从更加广义的层面、而非狭义的面向对象特性的层面来理解的话,越抽象、越不依赖具体的实现,越容易复用。代码封装成模块,隐藏可变的细节、暴露不变的接口,就越容易复用 - 应用模板等设计模式
一些设计模式,也能提高代码的复用性。比如,模板模式利用了多态来实现,可以灵活地替换其中的部分代码,整个流程模板代码可复用
除了上面这几点,还有一些跟编程语言相关的特性,也能提高代码的复用性,比如泛型编程等。实际上,除了上面讲到的这些方法之外,复用意识也非常重要。在写代码的时候,要多去思考一下,这个部分代码是否可以抽取出来,作为一个独立的模块、类或者函数供多处使用。在设计每个模块、类、函数的时候,要像设计一个外部 API 那样,去思考它的复用性
8.5 辩证思考和灵活应用
实际上,编写可复用的代码并不简单。如果在编写代码的时候,已经有复用的需求场景,那根据复用的需求去开发可复用的代码,可能还不算难。但是,如果当下并没有复用的需求,只是希望现在编写的代码具有可复用的特点,能在未来某个同事开发某个新功能的时候复用得上。在这种没有具体复用需求的情况下,就需要去预测将来代码会如何复用,这就比较有挑战了
实际上,除非有非常明确的复用需求,否则,为了暂时用不到的复用需求,花费太多的时间、精力,投入太多的开发成本,并不是一个值得推荐的做法。这也违反之前讲到的 YAGNI 原则
除此之外,有一个著名的原则,叫作“Rule of Three”。这条原则可以用在很多行业和场景中。如果把这个原则用在这里,那就是说,在第一次写代码的时候,如果当下没有复用的需求,而未来的复用需求也不是特别明确,并且开发可复用代码的成本比较高,那就不需要考虑代码的复用性。在之后开发新的功能的时候,发现可以复用之前写的这段代码,那我们就重构这段代码,让其变得更加可复用
也就是说,第一次编写代码的时候,不考虑复用性;第二次遇到复用场景的时候,再进行重构使其复用。需要注意的是,“Rule of Three”中的“Three”并不是真的就指确切的“三”,这里就是指“二”
9. 迪米特法则(LOD)
9.1 何为“高内聚、松耦合”?
“高内聚、松耦合”是一个非常重要的设计思想,能够有效地提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围。实际上,很多设计原则都以实现代码的“高内聚、松耦合”为目的,比如单一职责原则、基于接口而非实现编程等
实际上,“高内聚、松耦合”是一个比较通用的设计思想,可以用来指导不同粒度代码的设计与开发,比如系统、模块、类,甚至是函数,也可以应用到不同的开发场景中,比如微服务、框架、组件、类库等。这里以“类”作为这个设计思想的应用对象来展开讲解
在这个设计思想中,“高内聚”用来指导类本身的设计,“松耦合”用来指导类与类之间依赖关系的设计。不过,这两者并非完全独立不相干。高内聚有助于松耦合,松耦合又需要高内聚的支持
什么是“高内聚”?
所谓高内聚,就是指相近的功能应该放到同一个类中,不相近的功能不要放到同一个类中。相近的功能往往会被同时修改,放到同一个类中,修改会比较集中,代码容易维护。实际上,前面讲过的单一职责原则是实现代码高内聚非常有效的设计原则
什么是“松耦合”?
所谓松耦合是说,在代码中,类与类之间的依赖关系简单清晰。即使两个类有依赖关系,一个类的代码改动不会或者很少导致依赖类的代码改动。实际上,前面讲的依赖注入、接口隔离、基于接口而非实现编程,以及迪米特法则,都是为了实现代码的松耦合
“内聚”和“耦合”之间的关系
“高内聚”有助于“松耦合”,同理,“低内聚”也会导致“紧耦合”。如下图,图中左边部分的代码结构是“高内聚、松耦合”;右边部分正好相反,是“低内聚、紧耦合”
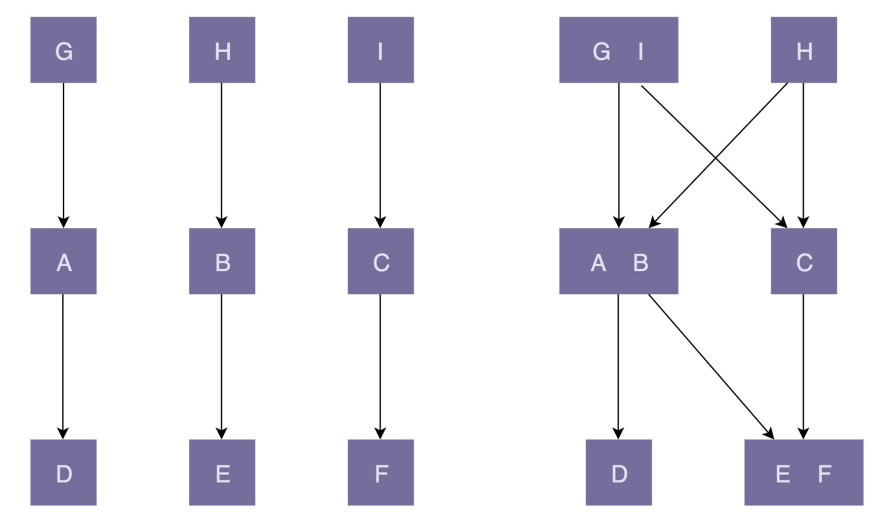
图中左边部分的代码设计中,类的粒度比较小,每个类的职责都比较单一。相近的功能都放到了一个类中,不相近的功能被分割到了多个类中。这样类更加独立,代码的内聚性更好。因为职责单一,所以每个类被依赖的类就会比较少,代码低耦合。一个类的修改,只会影响到一个依赖类的代码改动。只需要测试这一个依赖类是否还能正常工作就行了
图中右边部分的代码设计中,类粒度比较大,低内聚,功能大而全,不相近的功能放到了一个类中。这就导致很多其他类都依赖这个类。当修改这个类的某一个功能代码的时候,会影响依赖它的多个类。需要测试这三个依赖类,是否还能正常工作。这也就是所谓的“牵一发而动全身”
除此之外,从图中也可以看出,高内聚、低耦合的代码结构更加简单、清晰,相应地,在可维护性和可读性上确实要好很多
9.2 “迪米特法则”理论描述
迪米特法则的英文翻译是:Law of Demeter,缩写是 LOD。单从这个名字上来看,完全猜不出这个原则讲的是什么。不过,它还有另外一个更加达意的名字,叫作最小知识原则,英文翻译为:The Least Knowledge Principle。原文如下:
Each unit should have only limited knowledge about other units: only units “closely” related to the current unit. Or: Each unit should only talk to its friends; Don’t talk to strangers.
每个模块(unit)只应该了解那些与它关系密切的模块(units: only units “closely”related to the current unit)的有限知识(knowledge)。或者说,每个模块只和自己的朋友“说话”(talk),不和陌生人“说话”(talk)
大部分设计原则和思想都非常抽象,有各种各样的解读,要想灵活地应用到实际的开发中,需要有实战经验的积累。迪米特法则也不例外。这里对刚刚的定义重新描述一下。为了统一,把定义描述中的“模块”替换成了“类”
不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口(也就是定义中的“有限知识”)
从上面的描述中,可以看出,迪米特法则包含前后两部分,这两部分讲的是两件事情
9.2.1 不该有直接依赖关系的类之间,不要有依赖
如下例,这个例子实现了简化版的搜索引擎爬取网页的功能。代码中包含三个主要的类。其中,NetworkTransporter 类负责底层网络通信,根据请求获取数据;HtmlDownloader 类用来通过 URL 获取网页;Document 表示网页文档,后续的网页内容抽取、分词、索引都是以此为处理对象。具体的代码实现如下所示:
public class NetworkTransporter {
// 省略属性和其他方法...
public Byte[] send(HtmlRequest htmlRequest) {
//...
}
}
public class HtmlDownloader {
private NetworkTransporter transporter;// 通过构造函数或 IOC 注入
public Html downloadHtml(String url) {
Byte[] rawHtml = transporter.send(new HtmlRequest(url));
return new Html(rawHtml);
}
}
public class Document {
private Html html;
private String url;
public Document(String url) {
this.url = url;
HtmlDownloader downloader = new HtmlDownloader();
this.html = downloader.downloadHtml(url);
}
//...
}
这段代码虽然“能用”,能实现我们想要的功能,但是它不够“好用”,有比较多的设计缺陷
1、首先来看 NetworkTransporter 类
作为一个底层网络通信类,它的功能应尽可能通用,而不只是服务于下载 HTML,所以,不应该直接依赖太具体的发送对象 HtmlRequest。从这一点上讲 NetworkTransporter 类的设计违背迪米特法则,依赖了不该有直接依赖关系的 HtmlRequest 类
应该如何进行重构,让 NetworkTransporter 类满足迪米特法则呢?这里有个形象的比喻。假如你现在要去商店买东西,你肯定不会直接把钱包给收银员,让收银员自己从里面拿钱,而是你从钱包里把钱拿出来交给收银员。这里的 HtmlRequest 对象就相当于钱包,HtmlRequest 里的 address 和 content 对象就相当于钱。应该把 address 和 content 交给 NetworkTransporter,而非直接把 HtmlRequest 交给 NetworkTransporter。根据这个思路,NetworkTransporter 重构之后的代码如下所示:
public class NetworkTransporter {
// 省略属性和其他方法...
public Byte[] send(String address, Byte[] data) {
//...
}
}
2、再来看 HtmlDownloader 类
这个类的设计没有问题。不过修改了 NetworkTransporter 的 send() 函数的定义,而这个类用到了 send() 函数,所以需要对它做相应的修改,修改后的代码如下所示:
public class HtmlDownloader {
private NetworkTransporter transporter;// 通过构造函数或 IOC 注入
// HtmlDownloader 这里也要有相应的修改
public Html downloadHtml(String url) {
HtmlRequest htmlRequest = new HtmlRequest(url);
Byte[] rawHtml = transporter.send(
htmlRequest.getAddress(), htmlRequest.getContent().getBytes());
return new Html(rawHtml);
}
}
3、最后看下 Document 类
这个类的问题比较多,主要有三点。第一,构造函数中的 downloader.downloadHtml() 逻辑复杂,耗时长,不应该放到构造函数中,会影响代码的可测试性。第二,HtmlDownloader 对象在构造函数中通过 new 来创建,违反了基于接口而非实现编程的设计思想,也会影响到代码的可测试性。第三,从业务含义上来讲,Document 网页文档没必要依赖 HtmlDownloader 类,违背了迪米特法则
虽然 Document 类的问题很多,但修改起来比较简单,只要一处改动就可以解决所有问题。修改之后的代码如下所示:
public class Document {
private Html html;
private String url;
public Document(String url, Html html) {
this.html = html;
this.url = url;
}
//...
}
// 通过一个工厂方法来创建 Document
public class DocumentFactory {
private HtmlDownloader downloader;
public DocumentFactory(HtmlDownloader downloader) {
this.downloader = downloader;
}
public Document createDocument(String url) {
Html html = downloader.downloadHtml(url);
return new Document(url, html);
}
}
9.2.2 有依赖关系的类之间,尽量只依赖必要的接口
如下例,Serialization 类负责对象的序列化和反序列化
public class Serialization {
public String serialize(Object object) {
String serializedResult = ...;
//...
return serializedResult;
}
public Object deserialize(String str) {
Object deserializedResult = ...;
//...
return deserializedResult;
}
}
单看这个类的设计,没有一点问题。不过,如果把它放到一定的应用场景里,那就还有继续优化的空间。假设在项目中,有些类只用到了序列化操作,而另一些类只用到反序列化操作。那基于迪米特法则后半部分“有依赖关系的类之间,尽量只依赖必要的接口”,只用到序列化操作的那部分类不应该依赖反序列化接口。同理,只用到反序列化操作的那部分类不应该依赖序列化接口
根据这个思路,应该将 Serialization 类拆分为两个更小粒度的类,一个只负责序列化(Serializer 类),一个只负责反序列化(Deserializer 类)。拆分之后,使用序列化操作的类只需要依赖 Serializer 类,使用反序列化操作的类只需要依赖 Deserializer 类。拆分之后的代码如下所示:
public class Serializer {
public String serialize(Object object) {
String serializedResult = ...;
...
return serializedResult;
}
}
public class Deserializer {
public Object deserialize(String str) {
Object deserializedResult = ...;
...
return deserializedResult;
}
}
尽管拆分之后的代码更能满足迪米特法则,但却违背了高内聚的设计思想。高内聚要求相近的功能要放到同一个类中,这样可以方便功能修改的时候,修改的地方不至于过于分散。对于上面这个例子来说,如果修改了序列化的实现方式,比如从 JSON 换成了 XML,那反序列化的实现逻辑也需要一并修改。在未拆分的情况下,只需要修改一个类即可。在拆分之后,需要修改两个类。显然,这种设计思路的代码改动范围变大了
如果既不想违背高内聚的设计思想,也不想违背迪米特法则,那该如何解决这个问题呢?实际上,通过引入两个接口就能轻松解决这个问题,具体的代码如下所示:
public interface Serializable {
String serialize(Object object);
}
public interface Deserializable {
Object deserialize(String text);
}
public class Serialization implements Serializable, Deserializable {
@Override
public String serialize(Object object) {
String serializedResult = ...;
...
return serializedResult;
}
@Override
public Object deserialize(String str) {
Object deserializedResult = ...;
...
return deserializedResult;
}
}
public class DemoClass_1 {
private Serializable serializer;
public Demo(Serializable serializer) {
this.serializer = serializer;
}
//...
}
public class DemoClass_2 {
private Deserializable deserializer;
public Demo(Deserializable deserializer) {
this.deserializer = deserializer;
}
//...
}
尽管还是要往 DemoClass_1 的构造函数中,传入包含序列化和反序列化的 Serialization 实现类,但是依赖的 Serializable 接口只包含序列化操作,DemoClass_1 无法使用 Serialization 类中的反序列化接口,对反序列化操作无感知,这也就符合了迪米特法则后半部分所说的“依赖有限接口”的要求
实际上,上面的的代码实现思路,也体现了“基于接口而非实现编程”的设计原则,结合迪米特法则,可以总结出一条新的设计原则,那就是“基于最小接口而非最大实现编程”。实际上,新的设计模式和设计原则就是在大量的实践中,针对开发痛点总结归纳出来的套路
9.3 辩证思考与灵活应用
对应序列化与反序列化这个例子,整个类只包含序列化和反序列化两个操作,只用到序列化操作的使用者,即便能够感知到仅有的一个反序列化函数,问题也不大。那为了满足迪米特法则,将一个非常简单的类,拆分出两个接口,是否有点过度设计的意思呢?
设计原则本身没有对错,只有能否用对之说。不要为了应用设计原则而应用设计原则,在应用设计原则的时候,一定要具体问题具体分析
对于刚刚这个 Serialization 类来说,只包含两个操作,确实没有太大必要拆分成两个接口。但是,如果对 Serialization 类添加更多的功能,实现更多更好用的序列化、反序列化函数,来重新考虑一下这个问题。修改之后的具体的代码如下:
public class Serializer { // 参看 JSON 的接口定义
public String serialize(Object object) { //... }
public String serializeMap(Map map) { //... }
public String serializeList(List list) { //... }
public Object deserialize(String objectString) { //... }
public Map deserializeMap(String mapString) { //... }
public List deserializeList(String listString) { //... }
}
在这种场景下,第二种设计思路要更好些。因为基于之前的应用场景来说,大部分代码只需要用到序列化的功能。对于这部分使用者,没必要了解反序列化的“知识”,而修改之后的 Serialization 类,反序列化的“知识”,从一个函数变成了三个。一旦任一反序列化操作有代码改动,都需要检查、测试所有依赖 Serialization 类的代码是否还能正常工作。为了减少耦合和测试工作量,应该按照迪米特法则,将反序列化和序列化的功能隔离开来
10. 针对业务系统的开发,如何做需求分析和设计?
对于一个工程师来说,如果要追求长远发展,就不能一直只把自己放在执行者的角色,不能只是一个代码实现者,还要有独立负责一个系统的能力,能端到端(end to end)开发一个完整的系统。这其中的工作就包括:前期的需求沟通分析、中期的代码设计实现、后期的系统上线维护等
大部分工程师都是做业务开发的。很多工程师都觉得,做业务开发没啥技术含量,没有成长,就是简单的 CRUD,翻译业务逻辑,根本用不上专栏中讲的设计原则、思想、模式
这里通过一个积分兑换系统的开发实战,一方面展示一个业务系统从需求分析到上线维护的整个开发套路,借此能举一反三地应用到所有其他系统的开发中,另一方面展示在看似没有技术含量的业务开发中,实际上都蕴含了哪些设计原则、思想、模式
10.1 需求分析
积分是一种常见的营销手段,很多产品都会通过它来促进消费、增加用户粘性,比如淘宝积分、信用卡积分、商场消费积分等等。假设你是一家类似淘宝这样的电商平台的工程师,平台暂时还没有积分系统。Leader 希望由你来负责开发这样一个系统,你会如何来做呢?
作为技术人,该怎么做产品设计呢?首先,一定不要自己一个人闷头想。一方面,这样做很难想全面。另一方面,从零开始设计也比较浪费时间。所以,要学会“借鉴”。爱因斯坦说过,“创造的一大秘诀是要懂得如何隐藏你的来源”
可以找几个类似的产品,比如淘宝,看看他们是如何设计积分系统的,然后借鉴到自己的产品中。或者可以自己亲自用用淘宝,看看积分是怎么使用的,也可以直接百度一下“淘宝积分规则”。基于这两个输入,基本上就大致能摸清楚积分系统该如何设计了。除此之外,还要充分了解自己公司的产品,将借鉴来的东西糅合在自己的产品中,并做适当的微创新
笼统地来讲,积分系统无外乎就两个大的功能点,一个是赚取积分,另一个是消费积分。赚取积分功能包括积分赚取渠道,比如下订单、每日签到、评论等;还包括积分兑换规则,比如订单金额与积分的兑换比例,每日签到赠送多少积分等。消费积分功能包括积分消费渠道,比如抵扣订单金额、兑换优惠券、积分换购、参与活动扣积分等;还包括积分兑换规则,比如多少积分可以换算成抵扣订单的多少金额,一张优惠券需要多少积分来兑换等等
上面给出的只是非常笼统、粗糙的功能需求。在实际情况中,肯定还有一些业务细节需要考虑,比如积分的有效期问题。对于这些业务细节,还是那句话,闷头拍脑袋想是想不全面的。以防遗漏,还是要有方法可寻。除了刚刚讲的“借鉴”的思路之外,还可以通过产品的线框图、用户用例(user case )或者叫用户故事(user story)来细化业务流程,挖掘一些比较细节的、不容易想到的功能点
用户用例有点儿类似单元测试用例。它侧重情景化,其实就是模拟用户如何使用产品,描述用户在一个特定的应用场景里的一个完整的业务操作流程。所以,它包含更多的细节,且更加容易被人理解。比如,有关积分有效期的用户用例,可以进行如下的设计:
- 用户在获取积分的时候,会告知积分的有效期
- 用户在使用积分的时候,会优先使用快过期的积分
- 用户在查询积分明细的时候,会显示积分的有效期和状态(是否过期)
- 用户在查询总可用积分的时候,会排除掉过期的积分
10.1.1 积分赚取和兑换规则
积分的赚取渠道包括:下订单、每日签到、评论等
积分兑换规则可以是比较通用的。比如,签到送 10 积分。再比如,按照订单总金额的 10% 兑换成积分,也就是 100 块钱的订单可以积累 10 积分。除此之外,积分兑换规则也可以是比较细化的。比如,不同的店铺、不同的商品,可以设置不同的积分兑换比例
对于积分的有效期,可以根据不同渠道,设置不同的有效期。积分到期之后会作废;在消费积分的时候,优先使用快到期的积分
10.1.2 积分消费和兑换规则
积分的消费渠道包括:抵扣订单金额、兑换优惠券、积分换购、参与活动扣积分等
可以根据不同的消费渠道,设置不同的积分兑换规则。比如,积分换算成消费抵扣金额的比例是 10%,也就是 10 积分可以抵扣 1 块钱;100 积分可以兑换 15 块钱的优惠券等
10.1.3 积分及其明细查询
查询用户的总积分,以及赚取积分和消费积分的历史记录
10.2 系统设计
面向对象设计聚焦在代码层面(主要是针对类),那系统设计就是聚焦在架构层面(主要是针对模块),两者有很多相似之处。很多设计原则和思想不仅仅可以应用到代码设计中,还能用到架构设计中。实际上,也可以借鉴面向对象设计的四个步骤来做系统设计
10.2.1 合理地将功能划分到不同模块
面向对象设计的本质就是把合适的代码放到合适的类中。合理地划分代码可以实现代码的高内聚、低耦合,类与类之间的交互简单清晰,代码整体结构一目了然,那代码的质量就不会差到哪里去。类比面向对象设计,系统设计实际上就是将合适的功能放到合适的模块中。合理地划分模块也可以做到模块层面的高内聚、低耦合,架构整洁清晰
对于前面罗列的所有功能点,有下面三种模块划分方法:
1、积分赚取渠道及兑换规则、消费渠道及兑换规则的管理和维护(增删改查),不划分到积分系统中,而是放到更上层的营销系统中
这样积分系统就会变得非常简单,只需要负责增加积分、减少积分、查询积分、查询积分明细等这几个工作
比如,用户通过下订单赚取积分。订单系统通过异步发送消息或者同步调用接口的方式,告知营销系统订单交易成功。营销系统根据拿到的订单信息,查询订单对应的积分兑换规则(兑换比例、有效期等),计算得到订单可兑换的积分数量,然后调用积分系统的接口给用户增加积分
2、积分赚取渠道及兑换规则、消费渠道及兑换规则的管理和维护,分散在各个相关业务系统中,比如订单系统、评论系统、签到系统、换购商城、优惠券系统等
用户下订单成功之后,订单系统根据商品对应的积分兑换比例,计算所能兑换的积分数量,然后直接调用积分系统给用户增加积分
3、所有的功能都划分到积分系统中,包括积分赚取渠道及兑换规则、消费渠道及兑换规则的管理和维护
用户下订单成功之后,订单系统直接告知积分系统订单交易成功,积分系统根据订单信息查询积分兑换规则,给用户增加积分
怎么判断哪种模块划分合理呢?实际上,可以反过来通过看它是否符合高内聚、低耦合特性来判断。如果一个功能的修改或添加,经常要跨团队、跨项目、跨系统才能完成,那说明模块划分的不够合理,职责不够清晰,耦合过于严重
除此之外,为了避免业务知识的耦合,让下层系统更加通用,一般来讲,不希望下层系统(也就是被调用的系统)包含太多上层系统(也就是调用系统)的业务信息,但是,可以接受上层系统包含下层系统的业务信息。比如,订单系统、优惠券系统、换购商城等作为调用积分系统的上层系统,可以包含一些积分相关的业务信息。但是,反过来,积分系统中最好不要包含太多跟订单、优惠券、换购等相关的信息
所以,综合考虑,更倾向于第一种和第二种模块划分方式。但是,不管选择这两种中的哪一种,积分系统所负责的工作是一样的,只包含积分的增、减、查询,以及积分明细的记录和查询
10.2.2 设计模块与模块之间的交互关系
在面向对象设计中,类设计好之后,需要设计类之间的交互关系。类比到系统设计,系统职责划分好之后,接下来就是设计系统之间的交互,也就是确定有哪些系统跟积分系统之间有交互以及如何进行交互
比较常见的系统之间的交互方式有两种,一种是同步接口调用,另一种是利用消息中间件异步调用。第一种方式简单直接,第二种方式的解耦效果更好
比如,用户下订单成功之后,订单系统推送一条消息到消息中间件,营销系统订阅订单成功消息,触发执行相应的积分兑换逻辑。这样订单系统就跟营销系统完全解耦,订单系统不需要知道任何跟积分相关的逻辑,而营销系统也不需要直接跟订单系统交互
除此之外,上下层系统之间的调用倾向于通过同步接口,同层之间的调用倾向于异步消息调用。比如,营销系统和积分系统是上下层关系,它们之间就比较推荐使用同步接口调用
10.2.3 设计模块的接口、数据库、业务模型
完成了模块的功能划分,模块之间的交互的设计,接下来再来看,模块本身如何来设计。实际上,业务系统本身的设计无外乎有这样三方面的工作要做:接口设计、数据库设计和业务模型设计
10.3 代码实现
前面把积分赚取和消费的渠道和规则的管理维护工作,划分到了上层系统中,所以,积分系统的功能变得非常简单。相应地,代码实现也比较简单。如果有一定的项目开发经验,那实现这样一个系统并不是件难事。所以,这里重点并不是如何来实现积分系统的每个功能、每个接口,更不是如何编写 SQL 语句来增删改查数据,而是展示一些更普适的开发思想。比如,为什么要分 MVC 三层来开发?为什么要针对每层定义不同的数据对象?以及这其中都蕴含哪些设计原则和思想,知其然知其所以然,做到真正地透彻理解
业务开发包括哪些工作?
实际上,平时做业务系统的设计与开发,无外乎有这样三方面的工作要做:接口设计、数据库设计和业务模型设计(也就是业务逻辑)
数据库和接口的设计非常重要,一旦设计好并投入使用之后,这两部分都不能轻易改动。改动数据库表结构,需要涉及数据的迁移和适配;改动接口,需要推动接口的使用者作相应的代码修改。这两种情况,即便是微小的改动,执行起来都会非常麻烦。因此,在设计接口和数据库的时候,一定要多花点心思和时间,切不可过于随意。相反,业务逻辑代码侧重内部实现,不涉及被外部依赖的接口,也不包含持久化的数据,所以对改动的容忍性更大
10.3.1 设计数据库
数据库的设计比较简单。实际上,只需要一张记录积分流水明细的表就可以了。表中记录积分的赚取和消费流水。用户积分的各种统计数据,比如总积分、总可用积分等,都可以通过这张表来计算得到
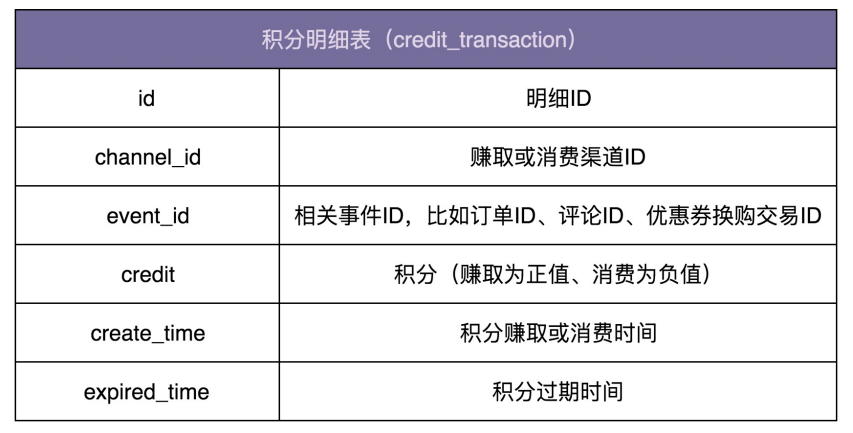
10.3.2 设计接口
接口设计要符合单一职责原则,粒度越小通用性就越好。但是,接口粒度太小也会带来一些问题。比如,一个功能的实现要调用多个小接口,一方面如果接口调用走网络(特别是公网),多次远程接口调用会影响性能;另一方面,本该在一个接口中完成的原子操作,现在分拆成多个小接口来完成,就可能会涉及分布式事务的数据一致性问题(一个接口执行成功了,但另一个接口执行失败了)。所以,为了兼顾易用性和性能,可以借鉴 facade(外观)设计模式,在职责单一的细粒度接口之上,再封装一层粗粒度的接口给外部使用
积分系统需要设计如下这样几个接口:
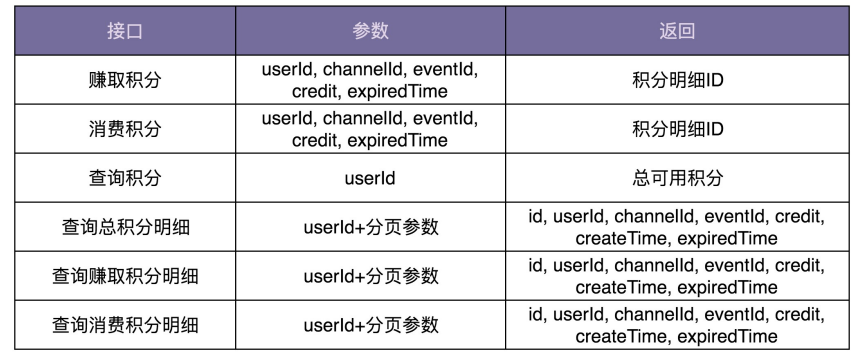
10.3.3 业务模型的设计
从代码实现角度来说,大部分业务系统的开发都可以分为 Controller、Service、Repository 三层。Controller 层负责接口暴露,Repository 层负责数据读写,Service 层负责核心业务逻辑,也就是这里说的业务模型
除此之外,前面还提到两种开发模式,基于贫血模型的传统开发模式和基于充血模型的 DDD 开发模式(见:设计模式之美总结(面向对象篇)_凡 223 的博客)。前者是一种面向过程的编程风格,后者是一种面向对象的编程风格。不管是 DDD 还是 OOP,高级开发模式的存在一般都是为了应对复杂系统,应对系统的复杂性。对于这里要开发的积分系统来说,因为业务相对比较简单,所以,选择简单的基于贫血模型的传统开发模式就足够了
从开发的角度来说,可以把积分系统作为一个独立的项目,来独立开发,也可以跟其他业务代码(比如营销系统)放到同一个项目中进行开发。从运维的角度来说,可以将它跟其他业务一块部署,也可以作为一个微服务独立部署。具体选择哪种开发和部署方式,可以参考公司当前的技术架构来决定
实际上,积分系统业务比较简单,代码量也不多,更倾向于将它跟营销系统放到一个项目中开发部署。只要做好代码的模块化和解耦,让积分相关的业务代码跟其他业务代码之间边界清晰,没有太多耦合,后期如果需要将它拆分成独立的项目来开发部署,那也并不困难
10.4 为什么要分 MVC 三层开发?
大部分业务系统的开发都可以分为三层:Contoller 层、Service 层、Repository 层。对于这种分层方式,大部分人都很认同,甚至成为了一种开发习惯,但为什么要分层开发?很多业务都比较简单,一层代码搞定所有的数据读取、业务逻辑、接口暴露不好吗?
1、分层能起到代码复用的作用
同一个 Repository 可能会被多个 Service 来调用,同一个 Service 可能会被多个 Controller 调用。比如,UserService 中的 getUserById() 接口封装了通过 ID 获取用户信息的逻辑,这部分逻辑可能会被 UserController 和 AdminController 等多个 Controller 使用。如果没有 Service 层,每个 Controller 都要重复实现这部分逻辑,显然会违反 DRY 原则
2、分层能起到隔离变化的作用
分层体现了一种抽象和封装的设计思想。比如,Repository 层封装了对数据库访问的操作,提供了抽象的数据访问接口。基于接口而非实现编程的设计思想,Service 层使用 Repository 层提供的接口,并不关心其底层依赖的是哪种具体的数据库。当需要替换数据库的时候,比如从 MySQL 到 Oracle,从 Oracle 到 Redis,只需要改动 Repository层的代码,Service 层的代码完全不需要修改
除此之外,Controller、Service、Repository 三层代码的稳定程度不同、引起变化的原因不同,所以分成三层来组织代码,能有效地隔离变化。比如,Repository 层基于数据库表,而数据库表改动的可能性很小,所以 Repository 层的代码最稳定,而 Controller 层提供适配给外部使用的接口,代码经常会变动。分层之后,Controller 层中代码的频繁改动并不会影响到稳定的 Repository 层
3、分层能起到隔离关注点的作用
Repository 层只关注数据的读写。Service 层只关注业务逻辑,不关注数据的来源。Controller 层只关注与外界打交道,数据校验、封装、格式转换,并不关心业务逻辑。三层之间的关注点不同,分层之后,职责分明,更加符合单一职责原则,代码的内聚性更好
4、分层能提高代码的可测试性
单元测试不依赖不可控的外部组件,比如数据库。分层之后,Repsitory 层的代码通过依赖注入的方式供 Service 层使用,当要测试包含核心业务逻辑的 Service 层代码的时候,可以用 mock 的数据源替代真实的数据库,注入到 Service 层代码中
5、分层能应对系统的复杂性
所有的代码都放到一个类中,那这个类的代码就会因为需求的迭代而无限膨胀。当一个类或一个函数的代码过多之后,可读性、可维护性就会变差。那就要想办法拆分。拆分有垂直和水平两个方向。水平方向基于业务来做拆分,就是模块化;垂直方向基于流程来做拆分,就是这里说的分层
不管是分层、模块化,还是 OOP、DDD,以及各种设计模式、原则和思想,都是为了应对复杂系统,应对系统的复杂性。对于简单系统来说,其实是发挥不了作用的,就是俗话说的“杀鸡焉用牛刀”
10.5 BO、VO、Entity 存在的意义是什么?
针对 Controller、Service、Repository 三层,每层都会定义相应的数据对象,它们分别是 VO(View Object)、BO(Business Object)、Entity,例如 UserVo、UserBo、UserEntity。在实际的开发中,VO、BO、Entity 可能存在大量的重复字段,甚至三者包含的字段完全一样。在开发的过程中,经常需要重复定义三个几乎一样的类,显然是一种重复劳动
相对于每层定义各自的数据对象来说,是不是定义一个公共的数据对象更好些呢?
实际上,更加推荐每层都定义各自的数据对象这种设计思路,主要有以下 3 个方面的原因:
- VO、BO、Entity 并非完全一样。比如,可以在 UserEntity、UserBo 中定义 Password 字段,但显然不能在 UserVo 中定义 Password 字段,否则就会将用户的密码暴露出去
- VO、BO、Entity 三个类虽然代码重复,但功能语义不重复,从职责上讲是不一样的。所以,也并不能算违背 DRY 原则。在前面讲到 DRY 原则的时候,针对这种情况,如果合并为同一个类,那也会存在后期因为需求的变化而需要再拆分的问题
- 为了尽量减少每层之间的耦合,把职责边界划分明确,每层都会维护自己的数据对象,层与层之间通过接口交互。数据从下一层传递到上一层的时候,将下一层的数据对象转化成上一层的数据对象,再继续处理。虽然这样的设计稍微有些繁琐,每层都需要定义各自的数据对象,需要做数据对象之间的转化,但是分层清晰。对于非常大的项目来说,结构清晰是第一位的!
既然 VO、BO、Entity 不能合并,那如何解决代码重复的问题呢?
从设计的角度来说,VO、BO、Entity 的设计思路并不违反 DRY 原则,为了分层清晰、减少耦合,多维护几个类的成本也并不是不能接受的。但是,对于代码重复的问题,也有一些办法来解决
继承可以解决代码重复问题。可以将公共的字段定义在父类中,让 VO、BO、Entity 都继承这个父类,各自只定义特有的字段。因为这里的继承层次很浅,也不复杂,所以使用继承并不会影响代码的可读性和可维护性。后期如果因为业务的需要,有些字段需要从父类移动到子类,或者从子类提取到父类,代码改起来也并不复杂
在讲“多用组合,少用继承”设计思想的时候,提到组合也可以解决代码重复的问题,所以,这里还可以将公共的字段抽取到公共的类中,VO、BO、Entity 通过组合关系来复用这个类的代码
代码重复问题解决了,那不同分层之间的数据对象该如何互相转化呢?
当下一层的数据通过接口调用传递到上一层之后,需要将它转化成上一层对应的数据对象类型。比如,Service 层从 Repository 层获取的 Entity 之后,将其转化成 BO,再继续业务逻辑的处理。所以,整个开发的过程会涉及“Entity 到 BO”和“BO 到 VO”这两种转化
最简单的转化方式是手动复制。自己写代码在两个对象之间,一个字段一个字段的赋值。但这样的做法显然是没有技术含量的低级劳动。Java 中提供了多种数据对象转化工具,比如 BeanUtils、Dozer 等(可见:MapStruct 总结_凡 223 的博客),可以大大简化繁琐的对象转化工作。如果是用其他编程语言来做开发,也可以借鉴 Java 这些工具类的设计思路,自己在项目中实现对象转化工具类
VO、BO、Entity 都是基于贫血模型的,而且为了兼容框架或开发库(比如 MyBatis),还需要定义每个字段的 set 方法。这些都违背 OOP 的封装特性,会导致数据被随意修改。那到底该怎么办好呢?
前面也提到过,Entity 和 VO 的生命周期是有限的,都仅限在本层范围内。而对应的 Repository 层和 Controller 层也都不包含太多业务逻辑,所以也不会有太多代码随意修改数据,即便设计成贫血、定义每个字段的 set 方法,相对来说也是安全的
不过,Service 层包含比较多的业务逻辑代码,所以 BO 就存在被任意修改的风险了。但是,设计的问题本身就没有最优解,只有权衡。为了使用方便,只能做一些妥协,放弃 BO 的封装特性,由程序员自己来负责这些数据对象的不被错误使用
10.6 用到的设计原则和思想
| 高内聚、松耦合 | 将不同的功能划分到不同的模块,遵从的划分原则就是尽量让模块本身高内聚,让模块之间松耦合 |
| 单一职责原则 | 模块的设计要尽量职责单一,符合单一职责原则。分层的一个目的也是为了更加符合单一职责原则 |
| 依赖注入 | 在 MVC 三层结构的代码实现中,下一层的类通过依赖注入的方式注入到上一层代码中 |
| 依赖反转原则 | 在业务系统开发中,如果通过类似 Spring IOC 这样的容器来管理对象的创建、生命周期,那就用到了依赖反转原则 |
| 基于接口而非实现编程 | 在 MVC 三层结构的代码实现中,Service 层使用 Repository 层提供的接口,并不关心其底层是依赖的哪种具体的数据库,遵从基于接口而非实现编程的设计思想 |
| 封装、抽象 | 分层体现了抽象和封装的设计思想,能够隔离变化,隔离关注点。尽管 VO、BO、Entity 存在代码重复,但功能语义不同,并不违反 DRY 原则 |
| DRY 与继承和组合 | 为了解决三者之间的代码重复问题,还用到了继承或组合 |
| DRY 面向对象设计 | 系统设计的过程可以参照面向对象设计的步骤来做。面向对象设计本质是将合适的代码放到合适的类中。系统设计是将合适的功能放到合适的模块中 |
11. 针对非业务的通用框架开发,如何做需求分析和设计?
11.1 项目背景
希望设计开发一个小的框架,能够获取接口调用的各种统计信息,比如,响应时间的最大值(max)、最小值(min)、平均值(avg)、百分位值(percentile)、接口调用次数(count)、频率(tps) 等,并且支持将统计结果以各种显示格式(比如:JSON 格式、网页格式、自定义显示格式等)输出到各种终端(Console 命令行、HTTP 网页、Email、日志文件、自定义输出终端等),以方便查看
如果开发这样一个通用的框架,应用到各种业务系统中,支持实时计算、查看数据的统计信息,如何设计和实现呢?
11.2 需求分析
性能计数器作为一个跟业务无关的功能,完全可以把它开发成一个独立的框架或者类库,集成到很多业务系统中。而作为可被复用的框架,除了功能性需求之外,非功能性需求也非常重要。所以,从这两个方面来做需求分析:
11.2.1 功能性需求分析
相对于一大长串的文字描述,人脑更容易理解短的、罗列的比较规整、分门别类的列表信息。显然,刚才那段需求描述不符合这个规律。需要把它拆解成一个一个的“干条条”:
- 接口统计信息:包括接口响应时间的统计信息,以及接口调用次数的统计信息等
- 统计信息的类型:max、min、avg、percentile、count、tps 等
- 统计信息显示格式:Json、Html、自定义显示格式
- 统计信息显示终端:Console、Email、HTTP 网页、日志、自定义显示终端
除此之外,还可以借助设计产品的时候,经常用到的线框图,把最终数据的显示样式画出来,会更加一目了然。具体的线框图如下所示:
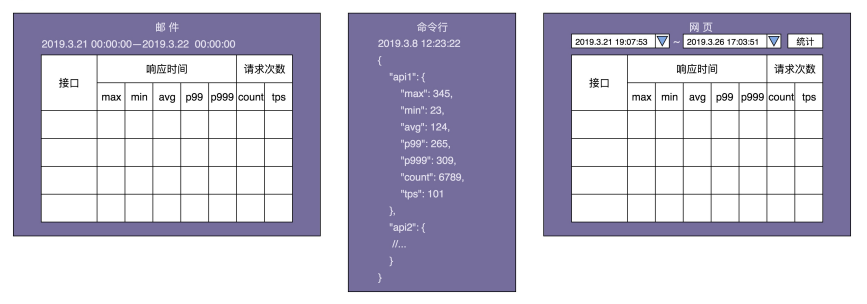
实际上,从线框图中,还能挖掘出了下面几个隐藏的需求:
- 统计触发方式:包括主动和被动两种
主动表示以一定的频率定时统计数据,并主动推送到显示终端,比如邮件推送。被动表示用户触发统计,比如用户在网页中选择要统计的时间区间,触发统计,并将结果显示给用户 - 统计时间区间:框架需要支持自定义统计时间区间
比如统计最近 10 分钟的某接口的 tps、访问次数,或者统计 12 月 11 日 00 点到 12 月 12 日 00 点之间某接口响应时间的最大值、最小值、平均值等 - 统计时间间隔:对于主动触发统计,还要支持指定统计时间间隔
也就是多久触发一次统计显示。比如,每间隔 10s 统计一次接口信息并显示到命令行中,每间隔 24 小时发送一封统计信息邮件
11.2.2 非功能性需求分析
对于这样一个通用的框架的开发,还需要考虑很多非功能性的需求。具体来说有以下几个比较重要的方面:
-
易用性
易用性听起来更像是一个评判产品的标准。在开发这样一个技术框架的时候,也要有产品意识。框架是否易集成、易插拔、跟业务代码是否松耦合、提供的接口是否够灵活等等,都是应该花心思去思考和设计的。有的时候,文档写得好坏甚至都有可能决定一个框架是否受欢迎 -
性能
对于需要集成到业务系统的框架来说,不希望框架本身的代码执行效率,对业务系统有太多性能上的影响。对于性能计数器这个框架来说,一方面,希望它是低延迟的,也就是说,统计代码不影响或很少影响接口本身的响应时间;另一方面,希望框架本身对内存的消耗不能太大 -
扩展性
这里说的扩展性跟之前讲到的代码的扩展性有点类似,都是指在不修改或尽量少修改代码的情况下添加新的功能。但是这两者也有区别。之前讲到的扩展是从框架代码开发者的角度来说的。这里所说的扩展是从框架使用者的角度来说的,特指使用者可以在不修改框架源码,甚至不拿到框架源码的情况下,为框架扩展新的功能。这就有点类似给框架开发插件。如下例:
feign 是一个 HTTP 客户端框架,可以在不修改框架源码的情况下,用如下方式来扩展自己的编解码方式、日志、拦截器等Feign feign = Feign.builder() .logger(new CustomizedLogger()) .encoder(new FormEncoder(new JacksonEncoder())) .decoder(new JacksonDecoder()) .errorDecoder(new ResponseErrorDecoder()) .requestInterceptor(new RequestHeadersInterceptor()).build(); public class RequestHeadersInterceptor implements RequestInterceptor { @Override public void apply(RequestTemplate template) { template.header("appId", "..."); template.header("version", "..."); template.header("timestamp", "..."); template.header("token", "..."); template.header("idempotent-token", "..."); template.header("sequence-id", "..."); } } public class CustomizedLogger extends feign.Logger { //... } public class ResponseErrorDecoder implements ErrorDecoder { @Override public Exception decode(String methodKey, Response response) { //... } } -
容错性
对于性能计数器框架来说,不能因为框架本身的异常导致接口请求出错。所以,要对框架可能存在的各种异常情况都考虑全面,对外暴露的接口抛出的所有运行时、非运行时异常都进行捕获处理 -
通用性
为了提高框架的复用性,能够灵活应用到各种场景中。框架在设计的时候,要尽可能通用。要多去思考一下,除了接口统计这样一个需求,还可以适用到其他哪些场景中,比如是否还可以处理其他事件的统计信息,比如 SQL 请求时间的统计信息、业务统计信息(比如支付成功率)等
11.3 框架设计
对于稍微复杂系统的开发,很多人觉得不知从何开始。作者个人喜欢借鉴 TDD(测试驱动开发)和 Prototype(最小原型)的思想,先聚焦于一个简单的应用场景,基于此设计实现一个简单的原型。尽管这个最小原型系统在功能和非功能特性上都不完善,但它能够看得见、摸得着,比较具体、不抽象,能够很有效地帮助我缕清更复杂的设计思路,是迭代设计的基础
这就好比做算法题目。当想要一下子就想出一个最优解法时,可以先写几组测试数据,找找规律,再先想一个最简单的算法去解决它。虽然这个最简单的算法在时间、空间复杂度上可能都不令人满意,但是可以基于此来做优化,这样思路就会更加顺畅
对于性能计数器这个框架的开发来说,可以先聚焦于一个非常具体、简单的应用场景,比如统计用户注册、登录这两个接口的响应时间的最大值和平均值、接口调用次数,并且将统计结果以 JSON 的格式输出到命令行中。现在这个需求简单、具体、明确,设计实现起来难度降低了很多
// 应用场景:统计下面两个接口 (注册和登录)的响应时间和访问次数
public class UserController {
public void register(UserVo user) {
//...
}
public UserVo login(String telephone, String password) {
//...
}
}
要输出接口的响应时间的最大值、平均值和接口调用次数,首先要采集每次接口请求的响应时间,并且存储起来,然后按照某个时间间隔做聚合统计,最后才是将结果输出。在原型系统的代码实现中,可以把所有代码都塞到一个类中,暂时不用考虑任何代码质量、线程安全、性能、扩展性等等问题,怎么简单怎么来就行
最小原型的代码实现如下所示。其中,recordResponseTime() 和 recordTimestamp() 两个函数分别用来记录接口请求的响应时间和访问时间。startRepeatedReport() 函数以指定的频率统计数据并输出结果
public class Metrics {
// Map 的 key 是接口名称,value 对应接口请求的响应时间或时间戳;
private Map<String, List<Double>> responseTimes = new HashMap<>();
private Map<String, List<Double>> timestamps = new HashMap<>();
private ScheduledExecutorService executor = Executors.newSingleThreadSchedule;
public void recordResponseTime(String apiName, double responseTime) {
responseTimes.putIfAbsent(apiName, new ArrayList<>());
responseTimes.get(apiName).add(responseTime);
}
public void recordTimestamp(String apiName, double timestamp) {
timestamps.putIfAbsent(apiName, new ArrayList<>());
timestamps.get(apiName).add(timestamp);
}
public void startRepeatedReport(long period, TimeUnit unit) {
executor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
Gson gson = new Gson();
Map<String, Map<String, Double>> stats = new HashMap<>();
for (Map.Entry<String, List<Double>> entry : responseTimes.entrySet())
String apiName = entry.getKey();
List<Double> apiRespTimes = entry.getValue();
stats.putIfAbsent(apiName, new HashMap<>());
stats.get(apiName).put("max", max(apiRespTimes));
stats.get(apiName).put("avg", avg(apiRespTimes));
}
for(Map.Entry<String, List<Double>> entry :timestamps.entrySet()) {
String apiName = entry.getKey();
List<Double> apiTimestamps = entry.getValue();
stats.putIfAbsent(apiName, new HashMap<>());
stats.get(apiName).put("count", (double) apiTimestamps.size());
}
System.out.println(gson.toJson(stats));
}
},0,period,unit);
}
private double max(List<Double> dataset) { // 省略代码实现 }
private double avg (List < Double > dataset) { // 省略代码实现 }
}
通过不到 50 行代码就实现了最小原型。接下来再来看,如何用它来统计注册、登录接口的响应时间和访问次数。具体的代码如下所示:
// 应用场景:统计下面两个接口 (注册和登录)的响应时间和访问次数
public class UserController {
private Metrics metrics = new Metrics();
public UserController() {
metrics.startRepeatedReport(60, TimeUnit.SECONDS);
}
public void register(UserVo user) {
long startTimestamp = System.currentTimeMillis();
metrics.recordTimestamp("regsiter", startTimestamp);
//...
long respTime = System.currentTimeMillis() - startTimestamp;
metrics.recordResponseTime("register", respTime);
}
public UserVo login(String telephone, String password) {
long startTimestamp = System.currentTimeMillis();
metrics.recordTimestamp("login", startTimestamp);
//...
long respTime = System.currentTimeMillis() - startTimestamp;
metrics.recordResponseTime("login", respTime);
}
}
最小原型的代码实现虽然简陋,但它却帮我们将思路理顺了很多,现在就基于它做最终的框架设计。下面是针对性能计数器框架画的一个粗略的系统设计图。图可以非常直观地体现设计思想,并且能有效地帮助我们释放更多的脑空间,来思考其他细节问题
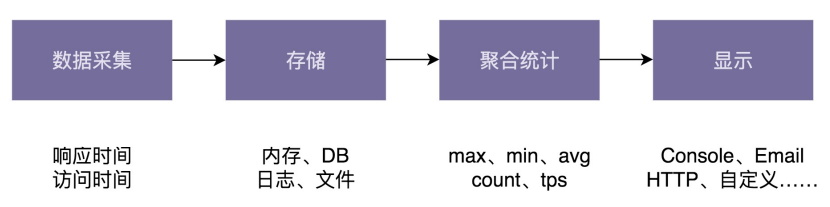
如图所示,把整个框架分为四个模块:数据采集、存储、聚合统计、显示。每个模块负责的工作简单罗列如下:
1、数据采集
负责打点采集原始数据,包括记录每次接口请求的响应时间和请求时间。数据采集过程要高度容错,不能影响到接口本身的可用性。除此之外,因为这部分功能是暴露给框架的使用者的,所以在设计数据采集 API 的时候,也要尽量考虑其易用性
2、存储
负责将采集的原始数据保存下来,以便后面做聚合统计。数据的存储方式有多种,比如:Redis、MySQL、HBase、日志、文件、内存等。数据存储比较耗时,为了尽量地减少对接口性能(比如响应时间)的影响,采集和存储的过程异步完成
3、聚合统计
负责将原始数据聚合为统计数据,比如:max、min、avg、pencentile、count、tps 等。为了支持更多的聚合统计规则,代码希望尽可能灵活、可扩展
4、显示
负责将统计数据以某种格式显示到终端,比如:输出到命令行、邮件、网页、自定义显示终端等
前面讲到面向对象分析、设计和实现的时候,讲到设计阶段最终输出的是类的设计,同时也讲到,软件设计开发是一个迭代的过程,分析、设计和实现这三个阶段的界限划分并不明显
11.4 小步快跑、逐步迭代
在上面,将整个框架分为数据采集、存储、聚合统计、显示这四个模块。除此之外,关于统计触发方式(主动推送、被动触发统计)、统计时间区间(统计哪一个时间段内的数据)、统计时间间隔(对于主动推送方法,多久统计推送一次)也做了简单的设计
虽然最小原型为我们奠定了迭代开发的基础,但离我们最终期望的框架的样子还有很大的距离。我自己在写这篇文章的时候,试图去实现上面罗列的所有功能需求,希望写出一个完美的框架,发现这是件挺烧脑的事情,在写代码的过程中,一直有种“脑子不够使”的感觉。我这个有十多年工作经验的人尚且如此,对于没有太多经验的开发者来说,想一下子把所有需求都实现出来,更是一件非常有挑战的事情。一旦无法顺利完成,可能就会有很强的挫败感,就会陷入自我否定的情绪中
不过,即便你有能力将所有需求都实现,可能也要花费很大的设计精力和开发时间,迟迟没有产出,你的 leader 会因此产生很强的不可控感。对于现在的互联网项目来说,小步快跑、逐步迭代是一种更好的开发模式。所以,应该分多个版本逐步完善这个框架。第一个版本可以先实现一些基本功能,对于更高级、更复杂的功能,以及非功能性需求不做过高的要求,在后续的 v2.0、v3.0……版本中继续迭代优化
针对这个框架的开发,在 v1.0 版本中,暂时只实现下面这些功能。剩下的功能留在 v2.0、v3.0 版本
- 数据采集:负责打点采集原始数据,包括记录每次接口请求的响应时间和请求时间
- 存储:负责将采集的原始数据保存下来,以便之后做聚合统计。数据的存储方式有很多种,暂时只支持 Redis 这一种存储方式,并且,采集与存储两个过程同步执行
- 聚合统计:负责将原始数据聚合为统计数据,包括响应时间的最大值、最小值、平均值、99.9 百分位值、99 百分位值,以及接口请求的次数和 tps
- 显示:负责将统计数据以某种格式显示到终端,暂时只支持主动推送给命令行和邮件。命令行间隔 n 秒统计显示上 m 秒的数据(比如,间隔 60s 统计上 60s 的数据)。邮件每日统计上日的数据
现在这个版本的需求比之前的要更加具体、简单了,实现起来也更加容易一些。实际上,学会结合具体的需求,做合理的预判、假设、取舍,规划版本的迭代设计开发,也是一个资深工程师必须要具备的能力
在之前,是把面向对象设计与实现分开来讲解,界限划分比较明显。在实际的软件开发中,这两个过程往往是交叉进行的。一般是先有一个粗糙的设计,然后着手实现,实现的过程发现问题,再回过头来补充修改设计。所以,对于这个框架的开发来说,把设计和实现放到一块来讲解
最小原型的实现,所有的代码都耦合在一个类中,这显然是不合理的。接下来,就按照之前讲的面向对象设计的几个步骤,来重新划分、设计类
11.4.1 划分职责进而识别出有哪些类
根据需求描述,先大致识别出下面几个接口或类。这一步不难,完全就是翻译需求
- MetricsCollector 类负责提供 API,来采集接口请求的原始数据。可以为 MetricsCollector 抽象出一个接口,但这并不是必须的,因为暂时只能想到一个 MetricsCollector 的实现方式
- MetricsStorage 接口负责原始数据存储,RedisMetricsStorage 类实现 MetricsStorage 接口。这样做是为了今后灵活地扩展新的存储方法,比如用 HBase 来存储
- Aggregator 类负责根据原始数据计算统计数据
- ConsoleReporter 类、EmailReporter 类分别负责以一定频率统计并发送统计数据到命令行和邮件。至于 ConsoleReporter 和 EmailReporter 是否可以抽象出可复用的抽象类,或者抽象出一个公共的接口,暂时还不能确定
11.4.2 定义类及类与类之间的关系
接下来就是定义类及属性和方法,定义类与类之间的关系。这两步没法分得很开,所以,将它们合在一起来讲解
大致地识别出几个核心的类之后,可以先在 IDE 中创建好这几个类,然后开始试着定义它们的属性和方法。在设计类、类与类之间交互的时候,不断地用之前学过的设计原则和思想来审视设计是否合理,比如,是否满足单一职责原则、开闭原则、依赖注入、KISS 原则、DRY 原则、迪米特法则,是否符合基于接口而非实现编程思想,代码是否高内聚、低耦合,是否可以抽象出可复用代码等等
MetricsCollector 类的定义非常简单,具体代码如下所示。对比最小原型的代码,MetricsCollector 通过引入 RequestInfo 类来封装原始数据信息,用一个采集函数代替了之前的两个函数
public class MetricsCollector {
private MetricsStorage metricsStorage; // 基于接口而非实现编程
// 依赖注入
public MetricsCollector(MetricsStorage metricsStorage) {
this.metricsStorage = metricsStorage;
}
// 用一个函数代替了最小原型中的两个函数
public void recordRequest(RequestInfo requestInfo) {
if (requestInfo == null || StringUtils.isBlank(requestInfo.getApiName())) {
return;
}
metricsStorage.saveRequestInfo(requestInfo);
}
}
public class RequestInfo {
private String apiName;
private double responseTime;
private long timestamp;
//... 省略 constructor/getter/setter 方法...
}
MetricsStorage 类和 RedisMetricsStorage 类的属性和方法也比较明确。具体的代码实现如下所示。注意,一次性取太长时间区间的数据,可能会导致拉取太多的数据到内存中,有可能会撑爆内存。对于 Java 来说,就有可能会触发 OOM(Out Of Memory)。而且,即便不出现 OOM,内存还够用,但也会因为内存吃紧,导致频繁的 Full GC,进而导致系统接口请求处理变慢,甚至超时
public interface MetricsStorage {
void saveRequestInfo(RequestInfo requestInfo);
List<RequestInfo> getRequestInfos(String apiName, long startTimeInMillis, long endTimeInMillis);
Map<String, List<RequestInfo>> getRequestInfos(long startTimeInMillis, long endTimeInMillis);
}
public class RedisMetricsStorage implements MetricsStorage {
//... 省略属性和构造函数等...
@Override
public void saveRequestInfo(RequestInfo requestInfo) {
//...
}
@Override
public List<RequestInfo> getRequestInfos(String apiName, long startTimestamp) {
//...
}
@Override
public Map<String, List<RequestInfo>> getRequestInfos(long startTimestamp, long endTimeInMillis) {
//...
}
}
MetricsCollector 类和 MetricsStorage 类的设计思路比较简单,不同的人给出的设计结果应该大差不差。但是,统计和显示这两个功能就不一样了,可以有多种设计思路。实际上,如果把统计显示所要完成的功能逻辑细分一下的话,主要包含下面 4 点:
- 根据给定的时间区间,从数据库中拉取数据
- 根据原始数据,计算得到统计数据
- 将统计数据显示到终端(命令行或邮件)
- 定时触发以上 3 个过程的执行
实际上,如果用一句话总结一下的话,面向对象设计和实现要做的事情,就是把合适的代码放到合适的类中。所以,现在要做的工作就是,把以上的 4 个功能逻辑划分到几个类中。划分的方法有很多种,比如,可以把前两个逻辑放到一个类中,第 3 个逻辑放到另外一个类中,第 4 个逻辑作为上帝类(God Class)组合前面两个类来触发前 3 个逻辑的执行。当然,也可以把第 2 个逻辑单独放到一个类中,第 1、3、4 都放到另外一个类中
至于到底选择哪种排列组合方式,判定的标准是,让代码尽量地满足低耦合、高内聚、单一职责、对扩展开放对修改关闭等之前讲到的各种设计原则和思想,尽量地让设计满足代码易复用、易读、易扩展、易维护
这里暂时选择把第 1、3、4 逻辑放到 ConsoleReporter 或 EmailReporter 类中,把第 2 个逻辑放到 Aggregator 类中。其中,Aggregator 类负责的逻辑比较简单,把它设计成只包含静态方法的工具类。具体的代码实现如下所示:
public class Aggregator {
public static RequestStat aggregate(List<RequestInfo> requestInfos, long duration) {
double maxRespTime = Double.MIN_VALUE;
double minRespTime = Double.MAX_VALUE;
double avgRespTime = -1;
double p999RespTime = -1;
double p99RespTime = -1;
double sumRespTime = 0;
long count = 0;
for (RequestInfo requestInfo : requestInfos) {
++count;
double respTime = requestInfo.getResponseTime();
if (maxRespTime < respTime) {
maxRespTime = respTime;
}
if (minRespTime > respTime) {
minRespTime = respTime;
}
sumRespTime += respTime;
}
if (count != 0) {
avgRespTime = sumRespTime / count;
}
long tps = (long) (count / durationInMillis * 1000);
Collections.sort(requestInfos, new Comparator<RequestInfo>() {
@Override
public int compare(RequestInfo o1, RequestInfo o2) {
double diff = o1.getResponseTime() - o2.getResponseTime();
if (diff < 0.0) {
return -1;
} else if (diff > 0.0) {
return 1;
} else {
return 0;
}
}
});
int idx999 = (int) (count * 0.999);
int idx99 = (int) (count * 0.99);
if (count != 0) {
p999RespTime = requestInfos.get(idx999).getResponseTime();
p99RespTime = requestInfos.get(idx99).getResponseTime();
}
RequestStat requestStat = new RequestStat();
requestStat.setMaxResponseTime(maxRespTime);
requestStat.setMinResponseTime(minRespTime);
requestStat.setAvgResponseTime(avgRespTime);
requestStat.setP999ResponseTime(p999RespTime);
requestStat.setP99ResponseTime(p99RespTime);
requestStat.setCount(count);
requestStat.setTps(tps);
return requestStat;
}
}
public class RequestStat {
private double maxResponseTime;
private double minResponseTime;
private double avgResponseTime;
private double p999ResponseTime;
private double p99ResponseTime;
private long count;
private long tps;
//... 省略 getter/setter 方法...
}
ConsoleReporter 类相当于一个上帝类,定时根据给定的时间区间,从数据库中取出数据,借助 Aggregator 类完成统计工作,并将统计结果输出到命令行。具体的代码实现如下所示:
public class ConsoleReporter {
private MetricsStorage metricsStorage;
private ScheduledExecutorService executor;
public ConsoleReporter(MetricsStorage metricsStorage) {
this.metricsStorage = metricsStorage;
this.executor = Executors.newSingleThreadScheduledExecutor();
}
// 第 4 个代码逻辑:定时触发第 1、2、3 代码逻辑的执行;
public void startRepeatedReport(long periodInSeconds, long durationInSeconds) {
executor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
// 第 1 个代码逻辑:根据给定的时间区间,从数据库中拉取数据;
long durationInMillis = durationInSeconds * 1000;
long endTimeInMillis = System.currentTimeMillis();
long startTimeInMillis = endTimeInMillis - durationInMillis;
Map<String, List<RequestInfo>> requestInfos =
metricsStorage.getRequestInfos(startTimeInMillis, endTimeInMillis);
Map<String, RequestStat> stats = new HashMap<>();
for (Map.Entry<String, List<RequestInfo>> entry : requestInfos.entrySet) {
String apiName = entry.getKey();
List<RequestInfo> requestInfosPerApi = entry.getValue();
// 第 2 个代码逻辑:根据原始数据,计算得到统计数据;
RequestStat requestStat = Aggregator.aggregate(requestInfosPerApi, durationInMillis);
stats.put(apiName, requestStat);
}
// 第 3 个代码逻辑:将统计数据显示到终端(命令行或邮件);
System.out.println("Time Span: ["+startTimeInMillis +", "+endTimeInmillis);
Gson gson = new Gson();
System.out.println(gson.toJson(stats));
}
},0,periodInSeconds,TimeUnit.SECONDS);
}
}
public class EmailReporter {
private static final Long DAY_HOURS_IN_SECONDS = 86400L;
private MetricsStorage metricsStorage;
private EmailSender emailSender;
private List<String> toAddresses = new ArrayList<>();
public EmailReporter(MetricsStorage metricsStorage) {
this(metricsStorage, new EmailSender(/* 省略参数 */));
}
public EmailReporter(MetricsStorage metricsStorage, EmailSender emailSender) {
this.metricsStorage = metricsStorage;
this.emailSender = emailSender;
}
public void addToAddress(String address) {
toAddresses.add(address);
}
public void startDailyReport() {
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.DATE, 1);
calendar.set(Calendar.HOUR_OF_DAY, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
Date firstTime = calendar.getTime();
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
long durationInMillis = DAY_HOURS_IN_SECONDS * 1000;
long endTimeInMillis = System.currentTimeMillis();
long startTimeInMillis = endTimeInMillis - durationInMillis;
Map<String, List<RequestInfo>> requestInfos =
metricsStorage.getRequestInfos(startTimeInMillis, endTimeInMillis);
Map<String, RequestStat> stats = new HashMap<>();
for (Map.Entry<String, List<RequestInfo>> entry : requestInfos.entrySet) {
String apiName = entry.getKey();
List<RequestInfo> requestInfosPerApi = entry.getValue();
RequestStat requestStat = Aggregator.aggregate(requestInfosPerApi, durationInMillis);
stats.put(apiName, requestStat);
}
// TODO: 格式化为 html 格式,并且发送邮件
}
}, firstTime, DAY_HOURS_IN_SECONDS * 1000);
}
}
11.4.3 将类组装起来并提供执行入口
因为这个框架稍微有些特殊,有两个执行入口:一个是 MetricsCollector 类,提供了一组 API 来采集原始数据;另一个是 ConsoleReporter 类和 EmailReporter 类,用来触发统计显示。框架具体的使用方式如下所示:
public class Demo {
public static void main(String[] args) {
MetricsStorage storage = new RedisMetricsStorage();
ConsoleReporter consoleReporter = new ConsoleReporter(storage);
consoleReporter.startRepeatedReport(60, 60);
EmailReporter emailReporter = new EmailReporter(storage);
emailReporter.addToAddress("wangzheng@xzg.com");
emailReporter.startDailyReport();
MetricsCollector collector = new MetricsCollector(storage);
collector.recordRequest(new RequestInfo("register", 123, 10234));
collector.recordRequest(new RequestInfo("register", 223, 11234));
collector.recordRequest(new RequestInfo("register", 323, 12334));
collector.recordRequest(new RequestInfo("login", 23, 12434));
collector.recordRequest(new RequestInfo("login", 1223, 14234));
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
11.4.4 Review 设计与实现
前面讲到了 SOLID、KISS、DRY、YAGNI、LOD 等设计原则,基于接口而非实现编程、多用组合少用继承、高内聚低耦合等设计思想。现在就来看下,上面的代码实现是否符合这些设计原则和思想
1、MetricsCollector
MetricsCollector 负责采集和存储数据,职责相对来说还算比较单一。它基于接口而非实现编程,通过依赖注入的方式来传递 MetricsStorage 对象,可以在不需要修改代码的情况下,灵活地替换不同的存储方式,满足开闭原则
2、MetricsStorage、RedisMetricsStorage
MetricsStorage 和 RedisMetricsStorage 的设计比较简单。当需要实现新的存储方式的时候,只需要实现 MetricsStorage 接口即可。因为所有用到 MetricsStorage 和 RedisMetricsStorage 的地方,都是基于相同的接口函数来编程的,所以,除了在组装类的地方有所改动(从 RedisMetricsStorage 改为新的存储实现类),其他接口函数调用的地方都不需要改动,满足开闭原则
3、Aggregator
Aggregator 类是一个工具类,里面只有一个静态函数,有 50 行左右的代码量,负责各种统计数据的计算。当需要扩展新的统计功能的时候,需要修改 aggregate() 函数代码,并且一旦越来越多的统计功能添加进来之后,这个函数的代码量会持续增加,可读性、可维护性就变差了。所以,从刚刚的分析来看,这个类的设计可能存在职责不够单一、不易扩展等问题,需要在之后的版本中,对其结构做优化
4、ConsoleReporter、EmailReporter
ConsoleReporter 和 EmailReporter 中存在代码重复问题。在这两个类中,从数据库中取数据、做统计的逻辑都是相同的,可以抽取出来复用,否则就违反了 DRY 原则。而且整个类负责的事情比较多,职责不是太单一。特别是显示部分的代码,可能会比较复杂(比如 Email 的展示方式),最好是将显示部分的代码逻辑拆分成独立的类。除此之外,因为代码中涉及线程操作,并且调用了 Aggregator 的静态函数,所以代码的可测试性不好
这里给出的代码实现还是有诸多问题的,在后面会慢慢优化,展示整个设计演进的过程,这比直接给出最终的最优方案要有意义得多!实际上,优秀的代码都是重构出来的,复杂的代码都是慢慢堆砌出来的

