
Dubbo总结(分布式理论 + 使用)
1. 分布式基础理论
1.1 什么是分布式系统?
分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统。分布式系统(distributed system)是建立在网络之上的软件系统
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,亟需一个治理系统确保架构有条不紊的演进
1.2 发展演变
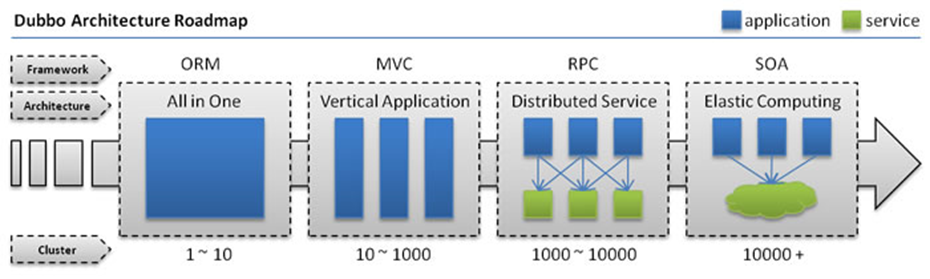
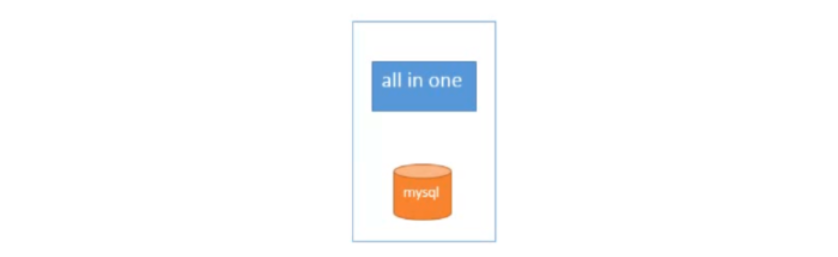
1.3 第一时期(单一应用架构)
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架(ORM)是关键
问题:
- 代码不具备可维护性
- 容错性差
- 当用户访问或某些原因发生异常,用户会直接看到异常信息,有些情况下,该错误可能会导致服务宕机
故障容许度(Fault tolerance),也称容错,容错性,是指系统在部分组件(一个或多个)发生故障时仍能正常运作的能力
1.3.1 第一时期后阶段
解决方案:
- 分层开发
- MVC 架构(基于Java WEB 应用的设计模式)
- 服务器分离部署
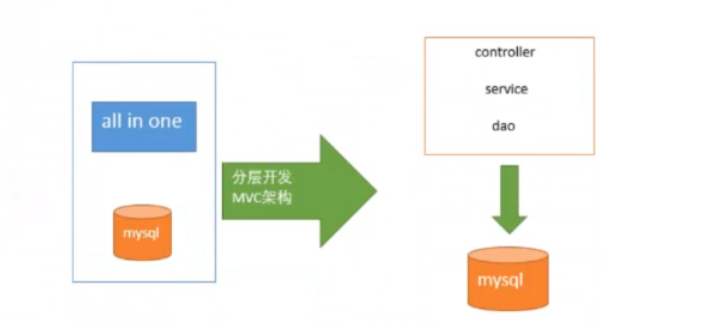
特点:
- MVC 分层开发(提高了维护性,解决了容错性问题)
- 数据库和项目分离部署
问题: 随着用户的访问量持续增加,单台应用服务器以及无法满足需求(高并发问题)
解决方案: 集群(集群方案解决)
1.3.2 会出现的如下问题
在互联网项目下,因单个 Tomcat 默认并发量有限制。如果请求量过大,会产生如下问题:
1.3.2.1 高并发( High Concurrency )
是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。高并发相关常用的一些指标有响应时间(Response TIme )、吞吐量 (Throughput )、每秒查询率QPS ( QueryPer Second ) 、并发用户数等
- 响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要 200ms,这个 200ms 就是系统的响应时间
- 吞吐量:单位时间内处理的请求数量
- QPS:每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显
- 开发用户数:同时承载正常使用系统功能的用户数量
1.3.2.2 高可用(High Availability )
通常来描述一个系统经过专门的设计,从而减少停工时间,而保持其服务的高度可用性
(一直都能用 99.9999%) --> docker --> k8s
https://www.idcbest.com/idcnews/11002927.html
1.3.2.3 高性能
是指服务响应时间快,(CPU / 处理器/内存)特别是在高并发下响应时间不会急剧增加
1.3.3 提高系统的并发能力
提高系统并发能力的方式,方法论上主要有两种︰垂直扩展(Scale Up )与水平扩展( Scale Out )
1.3.3.1 垂直扩展(提升单机处理能力)
垂直扩展的方式又有两种:
- 增强单机硬件性能,例如∶增加 CPU 核数如 32 核,升级更好的网卡如万兆,升级更好的硬盘如 SSD,扩充硬盘容量如 2T,扩充系统内存如 128 G
- 提升单机架构性能,例如∶使用 Cache 来减少 IO 次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间
在互联网业务发展非常迅猛的早期,如果预算不是问题,强烈建议使用“增强单机硬件性能”的方式提升系统并发能力,因为这个阶段,公司的战略往往是发展业务抢时间,而“增强单机硬件性能”往往是最快的方法
总结∶不管是提升单机硬件性能,还是提升单机架构性能,都有一个致命的不足∶单机性能总是有极限的。所以互联网分布式架构设计高并发终极解决方案还是水平扩展
1.3.3.2 水平扩展
水平扩展︰只要增加服务器数量,就能线性扩充系统性能。 水平扩展对系统架构设计是有要求的,难点在于:如何在架构各层进行可水平扩展的设计
1.3.4 集群操作
集群:同一个业务,部署在多个服务器上
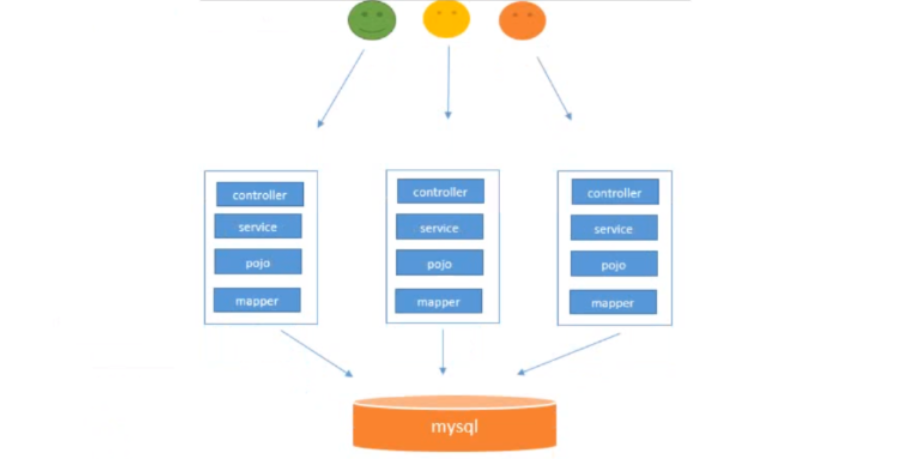
特点: 项目采用集群(多台服务器部署)
解决: 支持高并发、支持高可用
问题:
- (集群)用户的请求该往哪里进行转发?
- Session 如何共享
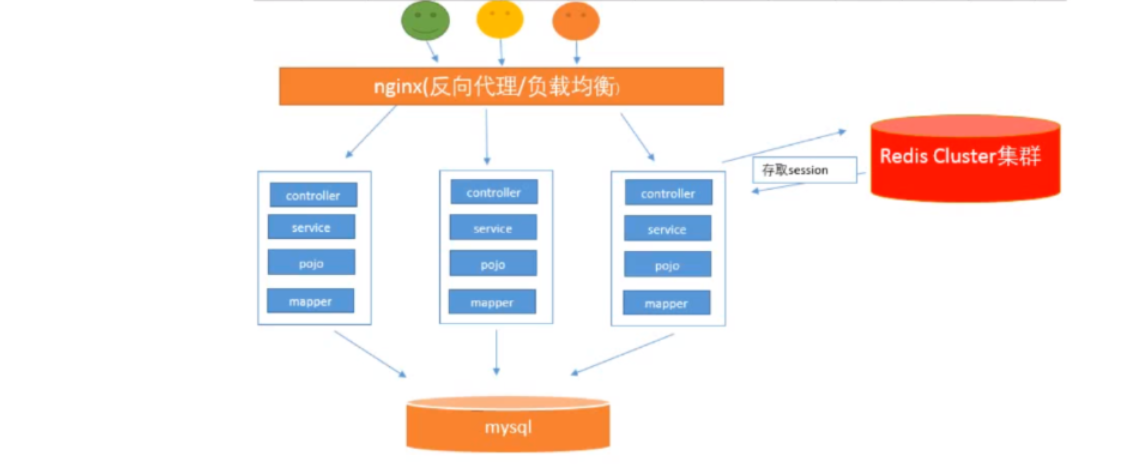
1.3.5 数据库压力变大
通过 Nginx + Tomcat 集群方案,支持高并发(应用的性能进行提升访问),但是数据库的负载能力慢慢增加
问题: 怎么减少数据库层面的访问压力?
解决方案:读写分离
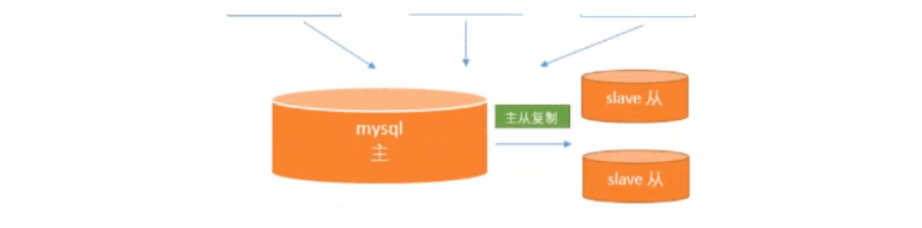
主从数据库之间进行数据同步,Master 主要负责增删改操作,Slave 负责读(查询)操作。 MySQL 本身就支持 Master + Slave 的功能(主从复制)
1.3.6 使用搜索引擎缓解数据库的访问压力 + 能力
数据库本身对大数据量查询效率慢,对模糊查询支持不是特别优秀,像电商类网站。搜索是非常核心的功能。(即使做了数据库读写分离),很多功能也不能有效解决(分词技术),针对于该问题,有必要引入全文检索服务器功能
目前市场上主流的搜索引擎技术:Solr、ElasticSearch
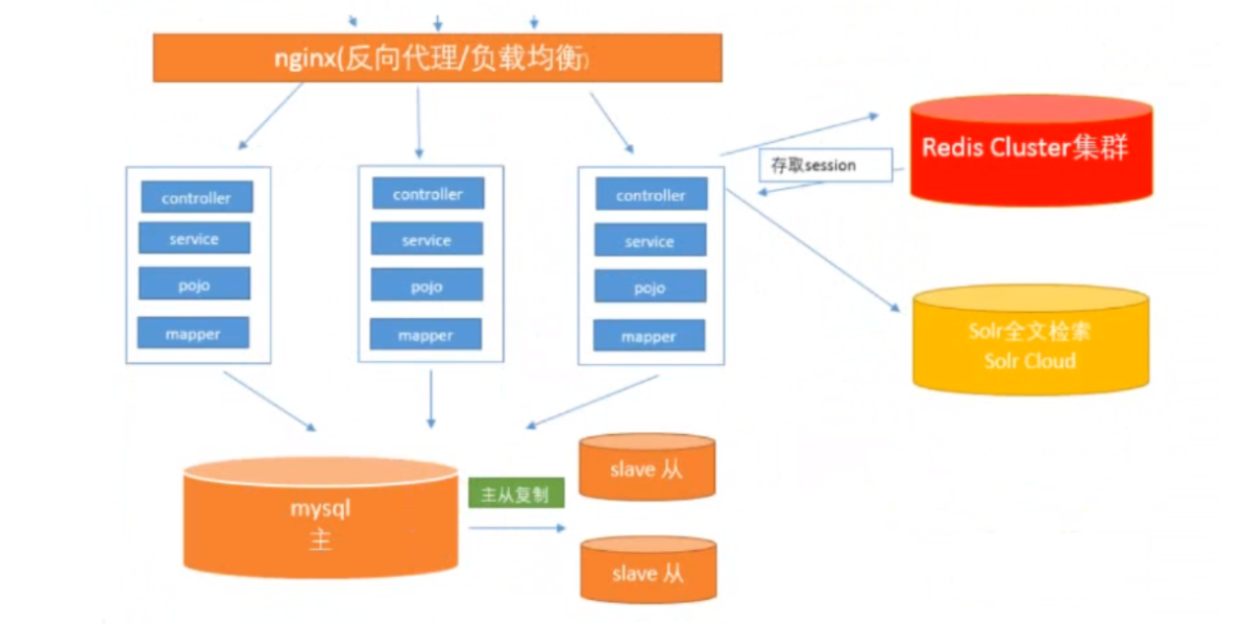
1.3.7 引入缓存机制减轻数据库的访问压力
随着访问量的持续增加(数据库的访问压力持续增大,甚至都无法满足需求),虽然做了主从复制,对于热点数据,如果每次都从数据中查询,数据库无法应对,导致无法对外提供服务
最住解决方案:Redis
- 读写性能非常好
- 提供了丰富的数据类型
- 原子性
1.3.8 数据库的表进行水平 / 垂直拆分
—张表里面有1千条数据,查询的性能很高。如果有100万数据,查询的性能很慢。单个表性能做提升。(能力终归还有限的)
1.3.8.1 垂直拆分表
假设一张表里面用户表(有30个字段)
id、姓名、年龄、身份证号、身高、体重、性别、手机号、家庭住址、爱好......
热数据 / 冷数据
user(id,姓名,身份证号,年龄,性别,手机号)
user_info(id,身高,体重)
1.3.8.2 水平拆分表
按需求进行拆分(省份、时间)
1.3.8.3 分库分表
垂直拆分数据库:按照业务将表进行分类,不同的表分布到不同的数据库上
水平拆分数据库:将一个表拆分到不同的数据库上
采用第三方数据库中间件:Mycat、Sharding-JDBC、DRDS
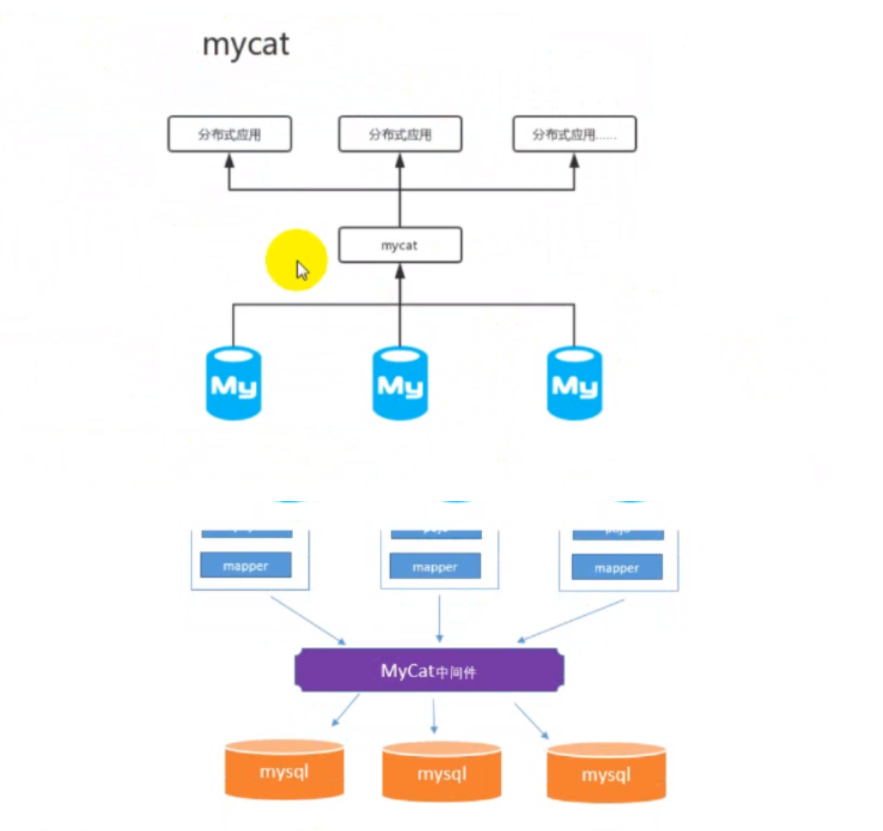
通过设计保证高并发、高可用。(不断对服务器进行扩容)
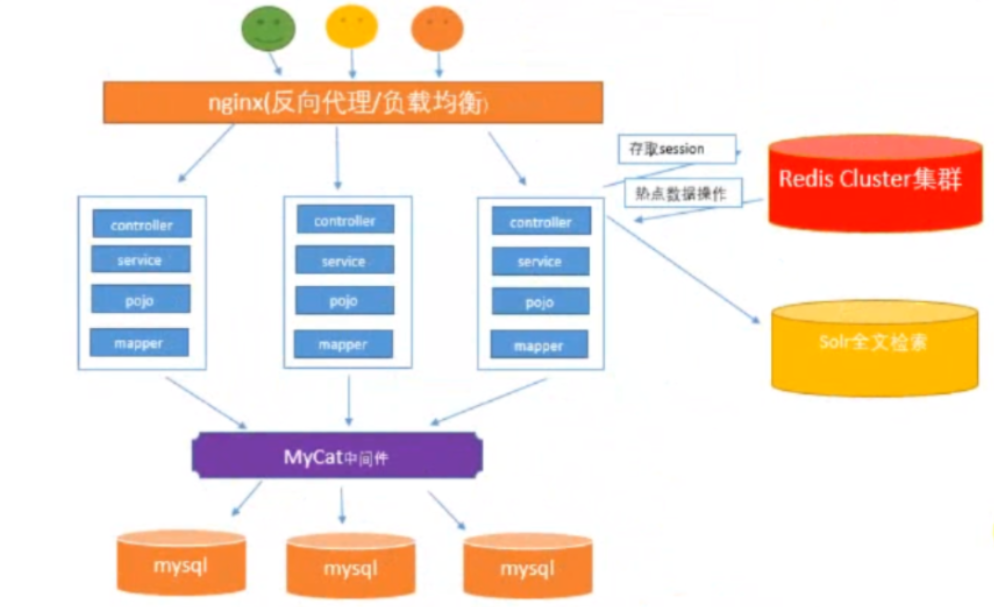
问题:
- 服务器价钱(忙闲不均匀问题、服务器的维护、人工成本、大量运维工程师)
- 可维护性差
- 可扩展性差(服务器)
- 协同开发不方便(大家都去修改相同业务代码,易发生代码冲突 / 错误问题)
- 单体架构(随着业务需求的不断增加,应用代码会变得越来越多)导致服务器部署时占用的硬盘也大
1.4 第二时期(垂直应用架构)
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的 Web 框架(MVC)是关键
1.4.1 水平拆分(横着拆)
将一个大的应用拆分成多个小应用。project(controller、service、mapper、pojo......)
问题1: 现在网站分为前台(给用户使用),后台(给管理员使用),是否需要拆成2个项目独立部署?如果需要拆的话,有一些前后台都需要公用的代码,这些代码怎么办?
- parent pom ------------ 父工程(放所有的 pom.xml)
- common.jar ------------ 公共库 相关工具类
- pojo.jar ------------------ Java Bean
- mapper.jar -------------- 数据持久层
- service.jar --------------- 业务逻辑层
- web.war ------------------ web 访问层
- manager.war ------------ 后台管理
解决问题:
- 模块复用
- 减少了服务器内容部署
1.4.2 垂直拆分(竖着拆)
按功能拆分
将一个大的应用按功能拆分成多个互不相干的小应用。每个应用都是独立的 WEB 应用程序
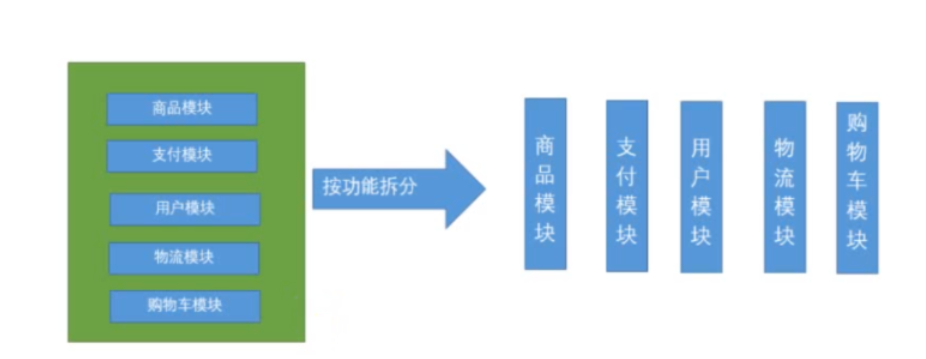
解决问题:
- 维护性(如果发生需求变更,只需要调整某个应用模块即可)
- 功能扩展(随着业务的不断增加,只需要创建新的WEB程序即可)
- 协同开发方便(不同的团队修改不同的代码)
- 部署内容大小(性能扩展),如果哪台访问量大,只需要对该服务多部署几台即可
问题:
- 客户对页面的要求会越来越高,(修改频繁)需要重新部署后台应用程序(每一个应用从头到尾都完整的)
- 随着业务需求不断增加,需要很多个互不相干应用部署,这些应用之间一定会需要业务交互
1.5 第三时期(分布式服务架构)
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式服务框架(RPC)是关键。
分布式:将一个业务拆分成多个子业务,部署在不用的服务器上
问题:
- 客户对页面的要求会越来越高,(修改频繁)需要重新部署后台应用程序(每一个应用从头到尾都完整的)
答:页面 + 业务代码(前后端分离开发 / 部署) - 随着业务需求不断增加,需要很多个互不相干应用部署,这些应用之间一定会需要业务交互
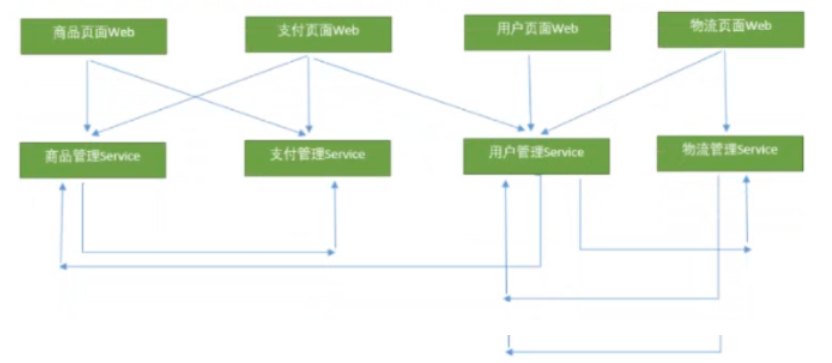
分析:
以前如果都在一台服务器上(模块之间通过依赖jar完成调用)。现在都是在不同的服务器上做的部署(分布式)。服务和服务之间通过进程间调用。
解决方案: RPC / HTTP / HttpClient
RPC ( Remote Procedure call ) -远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
架构的改变—定会带来—些新的技术和新的问题
问题:
- 分布式事务:两(二)阶段提交
- 分布式锁:Redis SetNX(Zookeeper)
- 分布式 Session:Redis Spring Session
- 分布式日志:ELK
问题:
-
当服务越来越多,服务和服务之间的调用非常的混乱(不知道你有哪些服务)
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现
-
例如∶支付管理访问量小,部署了100台服务器。物流管理访问量大,部署了50台服务器
1.8 第四时期(流动计算架构)
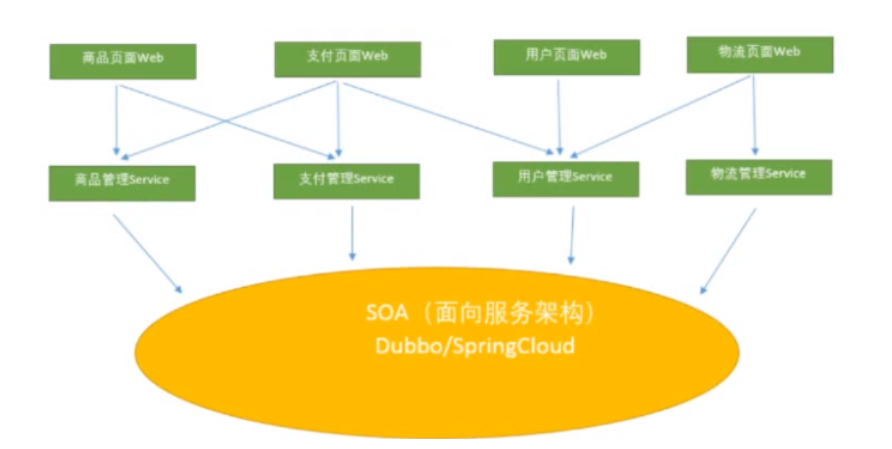
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键
SOA(面向服务的架构)--> 微服务架构
单体应用拆分成多个互不相干的小应用,每一个小的应用称为微服务
分布式服务治理(解决方案)中间件:Dubbo(底层是 RPC 协议) / SpringCloud(底层是 HTTP 协议)
基于访问压力实时管理集群容量,提高集群利用率
SOA ( Service oriented Architecture ) “面向服务的架构":他是一种设计方法,其中包含多个服务,服务之间通过相互依赖最终提供一系列的功能。一个服务通常以独立的形式存在与操作系统进程中。各个服务之间通过网络调用。微服务架构 = 80%的 SOA 服务架构思想+100% 的组件化架构思想+80% 的领域建模思想
以一个公司为例:有基层员工,有管理层,有老板。
最初大家都听老板指挥,谁干什么谁干什么,根据需要,你可能今天干A事情,明天干B事情,后来人越来越多了,事情也越来越多了,做事情的效率越来越多,管理也很混乱,
就开始做部门划分(服务化),专门部门做专门事情的,IT部门只做研发,人事部门只做招聘﹔这个时候就无法避免的发生跨部门协作(服务器调用),但是你怎么知道有这样一个部门可以做这个事情呢,就要依赖行政部门(注册中心),新成立的部门要在行政哪里做一个备案(服务注册),然后公布一下,让其他部门知道了(服务发布),大家就可以在新的工作秩序里面上班,这个时候依然是在公司的组织架构中运转
优点:
- 微服务对服务的拆分变的更细(复用性强),提高开发效率
- 可根据需求使用最新的技术(选择新的技术)
- 适用于互联网项目(迭代周期短。开发效率快)
缺点:
- 微服务过多,服务的管理(治理)成本高。
- 不利于服务的部署( Docker --> K8S)
- 技术难点在增加(分布式事务、锁、Session、日志)
- 对程序员的技术要求也高(Dubbo / SpringCloud)
2. 使用
2.1 服务提供者
2.1.1 POM
<!-- Dubbo 依赖-->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>3.0.2</version>
</dependency>
<!-- Dubbo 注解进 Nacos 的依赖-->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-registry-nacos</artifactId>
<version>3.0.2</version>
</dependency>
2.1.2 YML
// zookeeper
dubbo:
application:
name: user-service-provider
registry:
address: zookeeper://127.0.0.1:2181
protocol:
name: dubbo
port: 20880
// nacos
dubbo:
registry:
address: nacos://127.0.0.1:8848
protocol:
name: dubbo
port: 20880
# application:
# name: user-service-provider
spring:
application:
name: user-service-provider # 也可以在 dubbo 里定义 application.name
2.1.3 实现类
import org.apache.dubbo.config.annotation.DubboService;
@DubboService
public class UserServiceImpl implements UserService {
@Override
public User getUser() {
User user = new User(1, "七七");
return user;
}
}
2.1.4 启动类
import org.apache.dubbo.config.spring.context.annotation.EnableDubbo;
@SpringBootApplication
@EnableDubbo
public class UserServiceProviderApplication {
public static void main(String[] args) {
SpringApplication.run(UserServiceProviderApplication.class, args);
}
}
2.2 服务消费者
2.2.1 POM
<!-- Dubbo 依赖 -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>3.0.2</version>
</dependency>
2.2.2 YML
spring:
application:
name: user-service-consumer
2.2.3 调用
// 通过 @DubboReference 注入,url 为服务提供者的地址和端口
@Service
public class MeetingServiceImpl implements MeetingService {
@DubboReference(url = "dubbo://127.0.0.1:20880")
private UserService userService;
@Override
public Meeting getMeeting() {
User user = userService.getUser(); // 调用方法
Meeting meeting = new Meeting(11, "会议","Dubbo",user);
return meeting;
}
}

