
Java进阶使用记录
1. Asset 断言
用于对值进行判断,为真则运行,否则报错,多用于调试
Assert.isNull(null, "是否为空"); // 为空则运行
Assert.notNull("", "是否不为空"); // 不为空则运行
Assert.notEmpty(new ArrayList<>(), "数组是否不为空"); // 不为空则运行
可以使用 assert 进行更多判断操作,使用原则:
- 使用断言捕捉不应该发生的非法情况。不要混淆非法情况与错误情况之间的区别,后者是必然存在的并且是一定要作出处理的。
- 使用断言对函数的参数进行确认。
- 在编写函数时,要进行反复的考查,并且自问:“我打算做哪些假定?”一旦确定了的假定,就要使用断言对假定进行检查。
- 一般教科书都鼓励程序员们进行防错性的程序设计,但要这种编程风格会隐瞒错误。当进行防错性编程时,如果"不可能发生"的事情的确发生了,则要使用断言进行报警。
1.1 IDEA 开启 assert
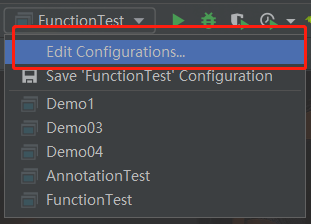
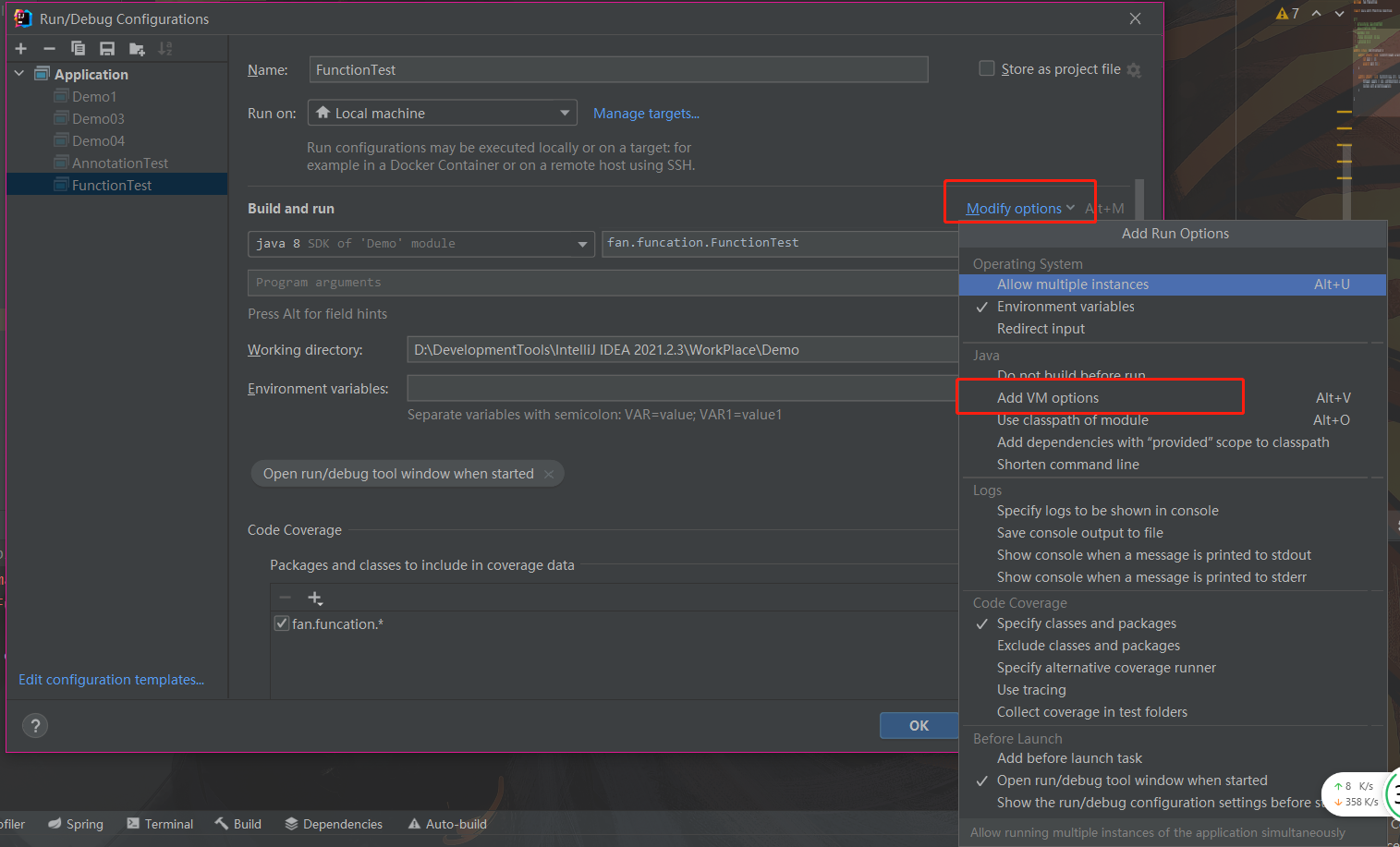
新版 IDEA 默认把 VM Options 去掉了,需要手动加进来
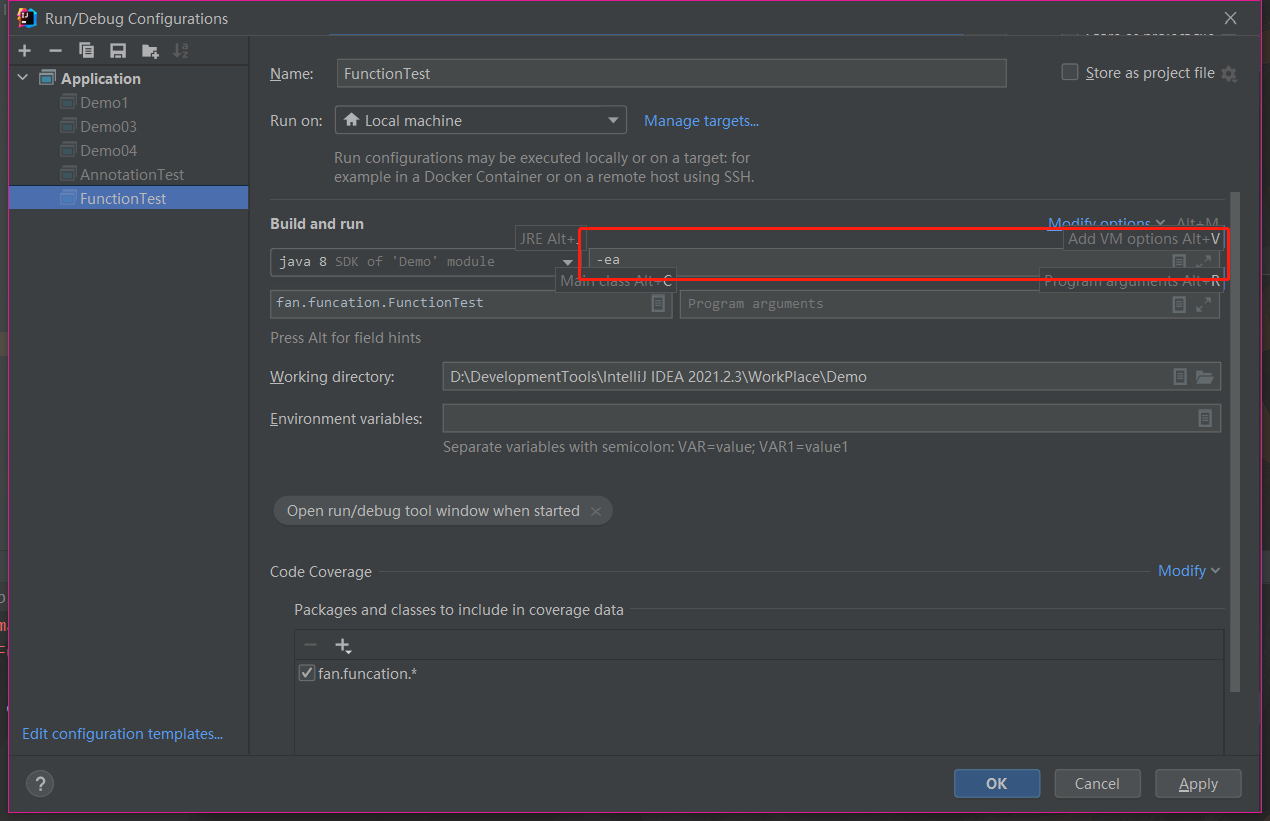
在 VM Options 里输入 -ea 开启断言
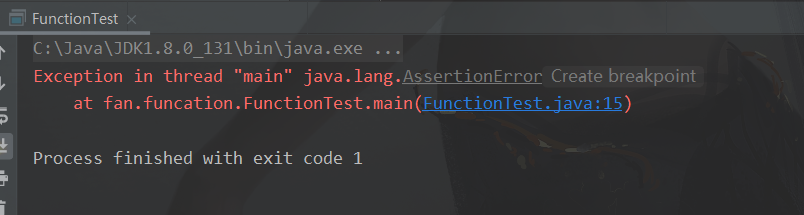
1.2 assert 使用
public static void main(String[] args) {
int num = 10;
// 判断 num 是否大于 12,不大于则为假,报错;大于则为真,继续运行
assert num > 12;
System.out.println("运行");
}
也可以在后面定义错误信息
public static void main(String[] args) {
int i = 10;
// 假如 i < 10,则 i++,否则则报错
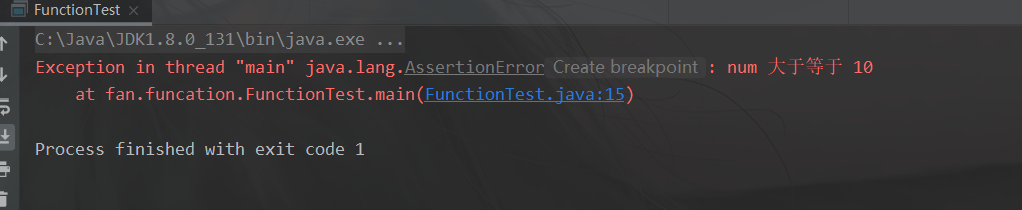
assert (i++ < 10) : "num 大于等于 10";
System.out.println(i);
}
2. 泛型
- ? 表示不确定的 Java类型
- T (type)表示 Java类型
- K 代表 Java 键值中的 Key
- V 代表 Java 键值中的Value
- E 代表 Element
2.1 定义和使用泛型类
[修饰符] class 类名<代表泛型的变量>
// 定义泛型类
class User<Fan>{
private Fan type;
public User(Fan type) {
this.type = type;
}
@Override
public String toString() {
return "User{" +
"type=" + type +
'}';
}
public Fan getType() {
return type;
}
public void setType(Fan type) {
this.type = type;
}
}
// 使用
public static void main(String[] args) {
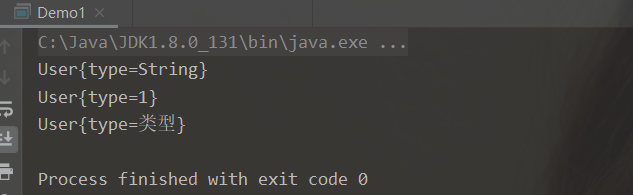
User<String> stringUser = new User<>("String"); // 可以限制泛型为 String
System.out.println(stringUser); // 输出 String
User user = new User<>(1); // 不进行限制
System.out.println(user); // 输出 1
user.setType("类型");
System.out.println(user); // 输出 类型
}
2.2 定义和使用泛型方法
修饰符 <代表泛型的变量> 返回值类型 方法名(参数)
// 定义泛型方法
class Person{
public <Fan> void show(Fan fan){
System.out.println(fan);
}
public <Fan> Fan showFan(Fan fan){
return fan;
}
}
// 使用
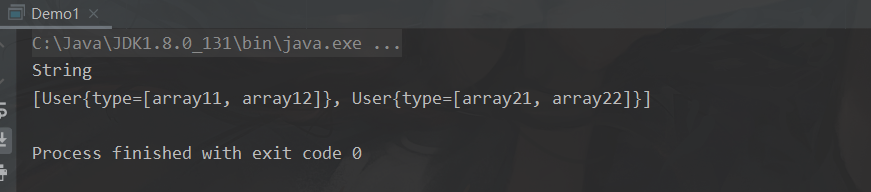
public static void main(String[] args) {
Person person = new Person();
person.show("String"); // 无返回,直接输出
// 传入一个 List 的 User泛型对象,User 的泛型又为 List
ArrayList<User<List<String>>> users = person.showFan(new ArrayList<User<List<String>>>(){
{
this.add(new User<>(new ArrayList<String>(){
{
this.add("array11");
this.add("array12");
}
}));
this.add(new User<>(new ArrayList<String>(){
{
this.add("array21");
this.add("array22");
}
}));
}
});
System.out.println(users); // 输出返回值
}
2.3 定义和使用泛型接口
修饰符 interface 接口名<代表泛型的变量>
interface MyInterface<Fan>{
void add(Fan fan);
Fan get(Fan fan);
}
2.3.1 定义实现类时确定泛型的类型
class MyInterfaceImpl implements MyInterface<String>{
@Override
public void add(String s) {
System.out.println(s + ",fan");
}
@Override
public String get(String s) {
return s;
}
}
2.3.2 始终不确定泛型的类型,直到创建对象时,确定泛型的类型
// 实现类
class MyInterfaceImpl<Fan> implements MyInterface<Fan>{
@Override
public void add(Fan fan) {
System.out.println(fan + ",fan");
}
@Override
public Fan get(Fan fan) {
return fan;
}
}
// 主启动类
public static void main(String[] args){
MyInterface myInterface = new MyInterfaceImpl(); // 不限制泛型
myInterface.add(1);
MyInterface<String> myInterface1 = new MyInterfaceImpl<>(); // 限制泛型为 String
System.out.println(myInterface1.get("String"));
}
2.4 泛型通配符 ?
当使用泛型类或者接口时,传递的数据中,泛型类型不确定,可以通过通配符 <?> 表示。但是一旦使用泛型的通配符后,只能使用 Object 类中的共性方法,集合中元素自身方法无法使用
2.4.1 通配符基础使用
泛型的通配符:不知道使用什么类型来接收的时候,此时可以使用 ?,? 表示未知通配符。此时只能接受数据,不能往该集合中存储数据。
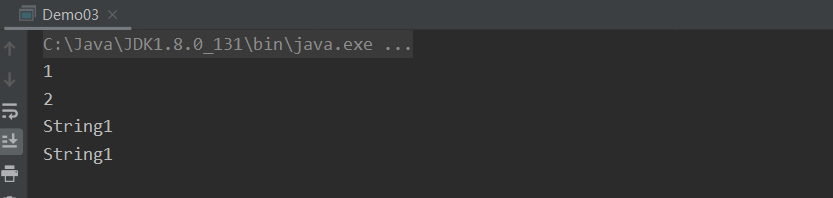
public static void main(String[] args) {
get(new ArrayList<Integer>(){
{
this.add(1);
this.add(2);
}
});
get(new LinkedList<String>(){
{
this.add("String1");
this.add("String1");
}
});
}
public static void get(Collection<?> collection){ // 可以传入任意的 Collection 下的类型
collection.stream().forEach(o -> {
System.out.println(o);
});
}
2.4.2 通配符高级使用----受限泛型
之前设置泛型的时候,实际上是可以任意设置的,只要是类就可以设置。但是在JAVA的泛型中可以指定一个泛型的上限和下限
泛型的上限:
- 格式: 类型名称 <? extends 类 > 对象名称
- 意义: 只能接收该类型及其子类
泛型的下限:
- 格式: 类型名称 <? super 类 > 对象名称
- 意义: 只能接收该类型及其父类型
// 泛型的上限:此时的泛型?,必须是Number类型或者Number类型的子类
// Collection 可以换为 ArrayList 等其他类型
public static void getElement1(Collection<? extends Number> collection){
}
// 泛型的下限:此时的泛型?,必须是Number类型或者Number类型的父类
public static void getElement2(Collection<? super Number> collection){
}
// 现已知 Object 类,String 类,Number 类,Integer 类,其中 Number 是 Integer 的父类
public static void main(String[] args) {
Collection<Integer> integer = new ArrayList<Integer>();
Collection<String> string = new ArrayList<String>();
Collection<Number> number = new ArrayList<Number>();
Collection<Object> object = new ArrayList<Object>();
getElement1(integer);
getElement1(string);//报错
getElement1(number);
getElement1(object);//报错
getElement2(integer);//报错
getElement2(string);//报错
getElement2(number);
getElement2(object);
}
3. 反射
-
框架:半成品软件。可以在框架的基础上进行软件开发,简化编码
-
反射:将类的各个组成部分封装为其他对象,这就是反射机制
好处:- 可以在程序运行过程中,操作这些对象
- 可以解耦,提高程序的可扩展性
3.1 获取Class对象的方式
Class.forName("全类名"):将字节码文件加载进内存,返回Class对象
多用于配置文件,将类名定义在配置文件中。读取文件,加载类类名.class:通过类名的属性 class 获取
多用于参数的传递对象.getClass():getClass()方法是Object类中的方法,Object类是所有类的父类,所有创建的对象都有该方法.
多用于对象的获取字节码的方式- 通过类加载器
xxxClassLoader.loadClass()传入类路径获取
结论:
同一个字节码文件(*.class)在一次程序运行过程中,只会被加载一次,不论通过哪一种方式获取的Class对象都是同一个
3.2 Class对象功能
获取功能:
- 获取成员变量
// 获取所有 public 的成员变量,包括继承的 Field[] getFields() // 获取指定名称的 public 成员变量 Field getField(String name) // 获取所有的成员变量,不考虑修饰符,不包括继承的(这里只能获取到 private 的属性,但并不能访问该 private 字段的值,除非加上 setAccessible(true)) Field[] getDeclaredFields() // 获取指定名称的所有成员变量,不考虑修饰符 Field getDeclaredField(String name) - 获取构造方法
// 获取所有 public 的构造方法 Constructor<?>[] getConstructors() // 获取传入数据类型的对应构造方法,Constructor<UserTest> constructor = userTestClass.getConstructor(String.class, Integer.class); Constructor<T> getConstructor(类<?>... parameterTypes) // 不考虑修饰符获取 Constructor<T> getDeclaredConstructor(类<?>... parameterTypes) // 不考虑修饰符获取 Constructor<?>[] getDeclaredConstructors() - 获取成员方法
// 获取所有 public 的成员方法,包括继承的 Method[] getMethods() // 获取指定名称和传入参数类型的 public 成员方法,Method test = userTestClass.getMethod("test", String.class); Method getMethod(String name, 类<?>... parameterTypes) // 获取所有的成员方法,不包括继承的 Method[] getDeclaredMethods() // 获取指定名称和传入参数类型的所有成员方法 Method getDeclaredMethod(String name, 类<?>... parameterTypes) - 获取全类名
String getName()
3.3 Field 成员变量
操作:
- 设置值
void set(Object obj, Object value) - 获取值
get(Object obj) - 忽略访问权限修饰符的安全检查(可以获取 private 的成员变量的值)
setAccessible(true):暴力反射
// 示例类
class UserTest{
private String name;
private Integer age;
public String birthday;
public UserTest() {
}
public UserTest(String name, Integer age) {
this.name = name;
this.age = age;
}
public void test(){
System.out.println("test");
}
@Override
public String toString() {
return "UserTest{" +
"name='" + name + '\'' +
", age=" + age +
", birthday='" + birthday + '\'' +
'}';
}
}
// 使用
public static void main(String[] args) throws Exception {
UserTest userTest = new UserTest(); // 新建一个对象
Class<? extends UserTest> aClass = userTest.getClass(); // 通过对象.getClass() 的方式获取字节码
Field[] fields = aClass.getFields(); // 获取 public 的成员变量
for (Field field : fields) {
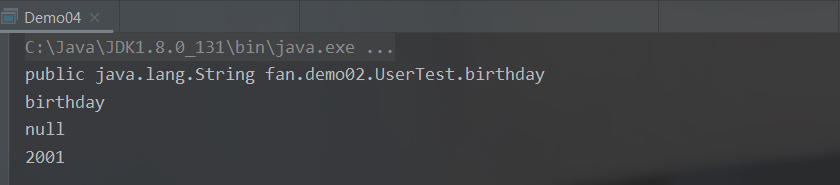
// public java.lang.String fan.demo02.UserTest.birthday
System.out.println(field);
System.out.println(field.getName()); // birthday
System.out.println(field.get(userTest)); // 获取值 null
field.set(userTest,"2001"); // 设置值,传入对象和设置的值
System.out.println(field.get(userTest)); // 2001
}
}
3.4 Constructor 构造方法
创建对象:
T newInstance(Object... initargs)
注:如果使用空参数构造方法创建对象,操作可以简化:Class对象.newInstance方法
// 使用
public static void main(String[] args) throws Exception {
// 无参构造创建对象
Class<UserTest> userTestClass = UserTest.class; // 通过类名.class 的方式获取字节码
UserTest userTest = userTestClass.newInstance(); // 直接通过Class对象.newInstance() 方法创建对象
UserTest userTest = userTestClass.getConstructor().newInstance(); // 获取构造方法再调用 newInstance 方法
// 有参构造创建对象,传入对应的数据类型
Constructor<UserTest> constructor = userTestClass.getConstructor(String.class, Integer.class);
UserTest userTest = constructor.newInstance("张三",1);
}
3.5 Method 方法对象
执行方法:
Object invoke(Object obj, Object... args) :调用 obj 对象的成员方法,参数是args,返回值是 Object 类型
获取方法名称:
String getName:获取方法名
// 使用
public static void main(String[] args) throws Exception {
Class<UserTest> userTestClass = UserTest.class;
Method test = userTestClass.getMethod("test", String.class);
System.out.println(test); // public void fan.demo02.UserTest.test(java.lang.String)
System.out.println(test.getName()); // test
UserTest userTest = userTestClass.newInstance(); // 创建对象
// 调用对象的 test 方法,有传参,传入参数 “李四”,有返回值,输出 “李四”
System.out.println(test.invoke(userTest,"李四"));
// 调用对象的 test1 方法,无传参,无返回值,输出为 null
Method test1 = aClass.getMethod("test1");
System.out.println(test1.invoke(userTest));
}

4. 注解
4.1 概念
注解(Annotation),也叫元数据。一种代码级别的说明。它是 JDK1.5 及以后版本引入的一个特性,与类、接口、枚举是在同一个层次。它可以声明在包、类、字段、方法、局部变量、方法参数等的前面,用来对这些元素进行说明,注释。
- 注解:说明程序的。给计算机看的。@注解名称
- 注释:用文字描述程序的。给程序员看的
4.2 作用分类
- 编写文档:通过代码里标识的注解生成文档【生成文档doc文档】
- 代码分析:通过代码里标识的注解对代码进行分析【使用反射】
- 编译检查:通过代码里标识的注解让编译器能够实现基本的编译 【Override】
4.3 JDK中预定义的一些注解
- @Override :检测被该注解标注的方法是否是继承自父类(接口)的
- @Deprecated:该注解标注的内容,表示已过时
- @SuppressWarnings:压制警告
一般传递参数 all @SuppressWarnings("all")
4.4 自定义注解
-
格式:
// 元注解 public @interface 注解名称{ 属性列表; } -
本质:
注解本质上就是一个接口,该接口默认继承 Annotation 接口public interface MyAnnotation extends java.lang.annotation.Annotation
-
属性:接口中的抽象方法
- 1、属性的返回值类型有下列取值
- 基本数据类型
- String
- 枚举
- 注解
- 以上类型的数组
- 2、定义了属性,在使用时需要给属性赋值
- 如果定义属性时,使用 default 关键字给属性默认初始化值,则使用注解时,可以不进行属性的赋值
- 如果只有一个属性需要赋值,并且属性的名称是 value,则 value 可以省略,直接定义值即可
- 数组赋值时,值使用 { } 包裹。如果数组中只有一个值,则 { } 可以省略
- 1、属性的返回值类型有下列取值
-
元注解:用于描述注解的注解
- @Target:描述注解能够作用的位置
- ElementType取值:
- TYPE:可以作用于类上
- METHOD:可以作用于方法上
- FIELD:可以作用于成员变量上
- ElementType取值:
- @Retention:描述注解被保留的阶段(存活阶段)
- @Retention(RetentionPolicy.RUNTIME):当前被描述的注解,会保留到 class 字节码文件中,并被 JVM 读取到
- @Documented:描述注解是否被抽取到 api 文档中
- @Inherited:所标记的类的子类也会拥有这个注解
- @Target:描述注解能够作用的位置
// 自定义一个注解
@Target({ElementType.FIELD, ElementType.TYPE}) // 作用在变量和方法上
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface MyAnnotation {
String value() default "fan"; // 设置默认值
boolean isNull(); // 不设置默认值,通过标注注解时传入
}
// 配置注解
@MyAnnotation(isNull = true)
@Data
class Person {
private String name;
private int age;
private boolean isDelete;
}
// 使用
public static void main(String[] args) throws Exception{
Person person = new Person();
Class<? extends Person> personClass = person.getClass();
// 通过反射,获取作用在类上的注解
MyAnnotation annotation = personClass.getAnnotation(MyAnnotation.class);
// @fan.annotation.MyAnnotation(value=fan, isNull=true)
System.out.println(annotation);
person.setName(annotation.value()); // 注入从注解里获取到的值
person.setDelete(annotation.isNull());
System.out.println(person); // Person(name=fan, age=0, isDelete=true)
}

5. 函数式接口
5.1 概念
函数式接口在Java中是指:有且仅有一个抽象方法的接口
函数式接口,即适用于函数式编程场景的接口。而Java中的函数式编程体现就是Lambda,所以函数式接口就是可以适用于Lambda使用的接口。只有确保接口中有且仅有一个抽象方法,Java中的Lambda才能顺利地进行推导
备注:“语法糖”是指使用更加方便,但是原理不变的代码语法。例如在遍历集合时使用的 for-each 语法,其实底层的实现原理仍然是迭代器,这便是“语法糖”。从应用层面来讲,Java 中的 Lambda 可以被当做是匿名内部类的“语法糖”,但是二者在原理上是不同的
5.2 格式
只要确保接口中有且仅有一个抽象方法即可
修饰符 interface 接口名称 {
public abstract 返回值类型 方法名称(可选参数信息);
// 其他非抽象方法内容
}
5.3 @FunctionalInterface 注解
与 @Override 注解的作用类似,Java 8 中专门为函数式接口引入了一个新的注解: @FunctionalInterface 。该注解可用于一个接口的定义上:
@FunctionalInterface
public interface MyFunctionalInterface {
void myMethod();
}
一旦使用该注解来定义接口,编译器将会强制检查该接口是否确实有且仅有一个抽象方法,否则将会报错。需要注意的是,即使不使用该注解,只要满足函数式接口的定义,这仍然是一个函数式接口,使用起来都一样
5.4 自定义函数式接口
// 定义一个函数式接口
@FunctionalInterface
public interface MyFunction {
String myMethod(String name); // public abstract 可以省略
default void hidden() { };
}
// 使用
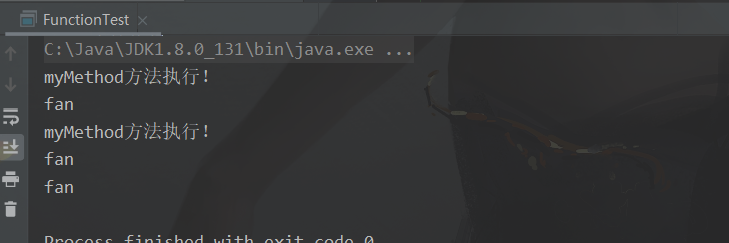
public static void main(String[] args) {
// 最基础写法
test(new MyFunction() {
@Override
public String myMethod(String name) {
System.out.println("myMethod方法执行!");
return name;
}
});
// 使用 Lambda 表达式
test(name -> {
System.out.println("myMethod方法执行!");
return name;
});
// 假如没有其他语句直接返回值,可以省略大括号和 return
test(name -> name);
}
public static void test(MyFunction myFunction){
String name = myFunction.myMethod("fan");
System.out.println(name);
}
5.5 Lambda 的延迟执行
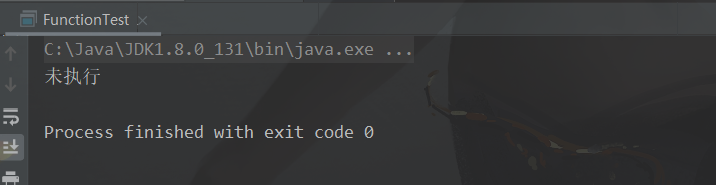
当 flag 为 false 的时候,Lambda将不会执行。从而达到节省性能的效果
public static void main(String[] args) {
test(false, name -> {
System.out.println("myMethod方法执行!");
return name;
});
}
public static void test(Boolean flag, MyFunction myFunction){
if (flag == true){
String s = myFunction.myMethod("fan");
System.out.println(s);
}else {
System.out.println("未执行");
}
}
扩展:实际上使用内部类也可以达到同样的效果,只是将代码操作延迟到了另外一个对象当中通过调用方法来完成。而是否调用其所在方法是在条件判断之后才执行的
5.6 Lambda 作为参数和返回值
如果抛开实现原理不说,Java 中的 Lambda 表达式可以被当作是匿名内部类的替代品。如果方法的参数是一个函数式接口类型,那么就可以使用 Lambda 表达式进行替代。使用 Lambda 表达式作为方法参数,其实就是使用函数式接口作为方法参数
5.6.1 作为参数
例如 java.lang.Runnable 接口就是一个函数式接口,假设有一个 startThread 方法使用该接口作为参数,那么就可以使用 Lambda 进行传参。这种情况其实和 Thread 类的构造方法参数为 Runnable 没有本质区别
public class Demo04Runnable {
public static void main(String[] args) {
startThread(() ‐> System.out.println("线程任务执行!"));
}
private static void startThread(Runnable runnable) {
new Thread(runnable).start();
}
}
5.6.2 作为返回值
类似地,如果一个方法的返回值类型是一个函数式接口,那么就可以直接返回一个 Lambda 表达式。当需要通过一个方法来获取一个 java.util.Comparator 接口类型的对象作为排序器时,就可以调该方法获取
public class Demo06Comparator {
public static void main(String[] args) {
String[] array = { "abc", "ab", "abcd" };
System.out.println(Arrays.toString(array));
Arrays.sort(array, newComparator());
System.out.println(Arrays.toString(array));
}
private static Comparator<String> newComparator() {
return (a, b) ‐> b.length() ‐ a.length();
}
}
5.7 常用函数式接口
JDK 提供了大量常用的函数式接口以丰富Lambda的典型使用场景,它们主要在 java.util.function 包中被提供
5.7.1 Supplier
java.util.function.Supplier
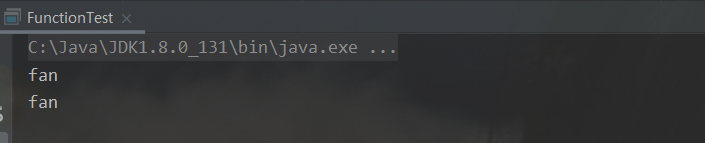
public static void main(String[] args) {
System.out.println(test(new Supplier<String>() {
@Override
public String get() { // 参数类型为使用 Supplier 时指定的数据类型
return "fan";
}
}));
System.out.println(test(() -> "fan"));
}
public static String test(Supplier<String> supplier){
return supplier.get();
}
5.7.2 Consumer
java.util.function.Consumer<T> 接口则正好与Supplier接口相反,它不是生产一个数据,而是消费一个数据,其数据类型由泛型决定
-
抽象方法:accept
Consumer 接口中包含抽象方法 void accept(T t) ,意为消费一个指定泛型的数据public static void main(String[] args) { test("fan", new Consumer<String>() { @Override public void accept(String name) { System.out.println(name); } }); test("fan", name -> System.out.println(name)); } public static void test(String name, Consumer<String> consumer){ consumer.accept(name); }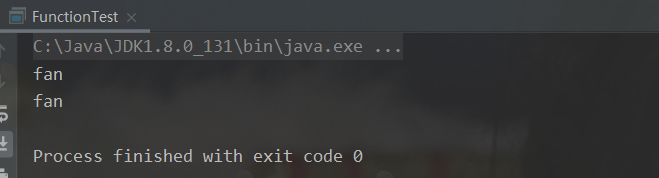
-
默认方法:andThen
如果一个方法的参数和返回值全都是 Consumer 类型,那么就可以实现效果:消费数据的时候,首先做一个操作,然后再做一个操作,实现组合。而这个方法就是 Consumer 接口中的 default 方法 andThenpublic static void main(String[] args) { test("fan", one -> System.out.println(one.toLowerCase()), two -> System.out.println(two.toUpperCase())); } public static void test(String name, Consumer<String> one, Consumer<String> two){ Consumer<String> stringConsumer = one.andThen(two); stringConsumer.accept(name); one.andThen(two).accept(name); }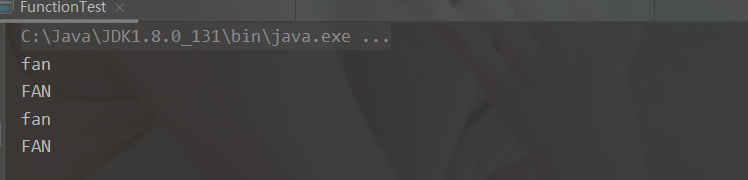
5.7.3 Predicate
有时候我们需要对某种类型的数据进行判断,从而得到一个 boolean 值结果。这时可以使用 java.util.function.Predicate<T> 接口
-
抽象方法:test
Predicate 接口中包含一个抽象方法: boolean test(T t) 。用于条件判断的场景public static void main(String[] args) { test("false", new Predicate<String>() { @Override public boolean test(String s) { return s.length() > 4; // 返回一个判断 } }); // 判断字符串长度是否小于 4 test("false", s -> s.length() < 4); } public static void test(String str, Predicate<String> predicate){ boolean test = predicate.test(str); System.out.println(test); }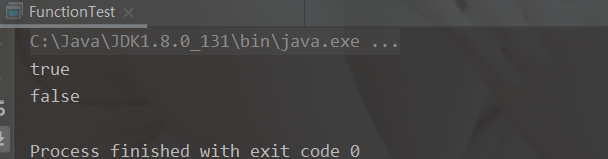
-
默认方法:and
既然是条件判断,就会存在与、或、非三种常见的逻辑关系。其中将两个 Predicate 条件使用“与”逻辑连接起来实现“并且”的效果时,可以使用 default 方法 andpublic static void main(String[] args) { // 判断字符串是否存在 H 并且存在 W test("fanHW", one -> one.contains("H"), two -> two.contains("W")); } public static void test(String str, Predicate<String> one, Predicate<String> two){ boolean test = one.and(two).test(str); System.out.println(test); }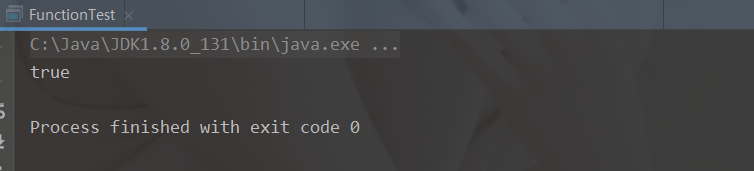
-
默认方法:or
与 and 的“与”类似,默认方法 or 实现逻辑关系中的“或”public static void main(String[] args) { // 判断字符串是否存在 H 或存在 W test("fanH", one -> one.contains("H"), two -> two.contains("W")); } public static void test(String str, Predicate<String> one, Predicate<String> two){ boolean test = one.or(two).test(str); System.out.println(test); }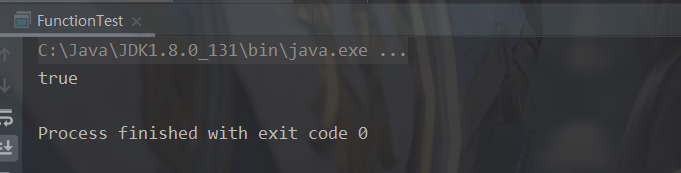
-
默认方法:negate
它是执行了test方法之后,对结果 boolean 值进行 “!” 取反。一定要在 test 方法调用之前调用 negate 方法,正如 and 和 or 方法一样public static void main(String[] args) { test("fanH", one -> one.contains("H"), two -> two.contains("W")); } public static void test(String str, Predicate<String> one, Predicate<String> two){ boolean test = one.or(two).negate().test(str); // 对结果取反 System.out.println(test); }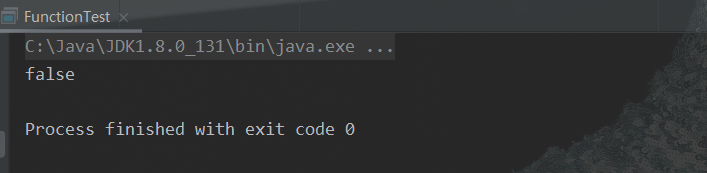
5.7.4 Function
java.util.function.Function<T,R> 接口用来根据一个类型的数据得到另一个类型的数据,前者称为前置条件,后者称为后置条件
-
抽象方法:apply
Function 接口中最主要的抽象方法为:R apply(T t) ,根据类型 T 的参数获取类型R的结果// 将 String 类型转换为 Integer 类型 public static void main(String[] args) { test("1234", new Function<String, Integer>() { @Override public Integer apply(String s) { System.out.println("apply方法执行!"); return Integer.parseInt(s); // 返回转换后的类型 } }); test("1234", s -> Integer.parseInt(s)); } public static void test(String str, Function<String, Integer> function){ Integer apply = function.apply(str); System.out.println(apply); }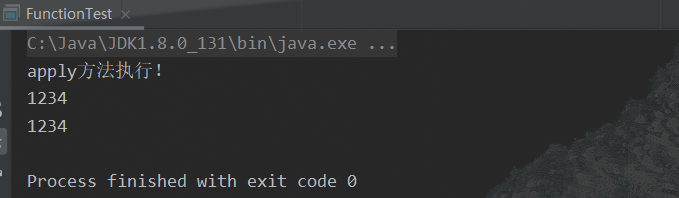
-
默认方法:andThen
Function 接口中有一个默认的 andThen 方法,用来进行组合操作,用于“先做什么,再做什么”的场景public static void main(String[] args) { // 先进行类型转换,然后再将转换后的类型的值乘以 10 test("1234", one -> Integer.parseInt(one), two -> two *= 10); } public static void test(String str, Function<String, Integer> one, Function<Integer, Integer> two){ Integer apply = one.andThen(two).apply(str); System.out.println(apply); }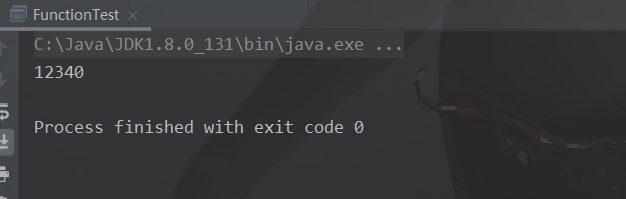
6. 网络编程
网络编程,就是在一定的协议下,实现两台计算机的通信的程序
6.1 网络通信协议
- 网络通信协议:通信协议是对计算机必须遵守的规则,只有遵守这些规则,计算机之间才能进行通信。这就好比在道路中行驶的汽车一定要遵守交通规则一样,协议中对数据的传输格式、传输速率、传输步骤等做了统一规定,通信双方必须同时遵守,最终完成数据交换。
- TCP/IP协议:传输控制协议/因特网互联协议( Transmission Control Protocol/Internet Protocol),是Internet最基本、最广泛的协议。它定义了计算机如何连入因特网,以及数据如何在它们之间传输的标准。它的内部包含一系列的用于处理数据通信的协议,并采用分层模型,每一层都呼叫它的下一层所提供的协议来完成自己的需求。
- 模型各分层作用及对应协议
6.2 协议分类
通信的协议还是比较复杂的, java.net 包中包含的类和接口,它们提供低层次的通信细节。我们可以直接使用这些类和接口,来专注于网络程序开发,而不用考虑通信的细节。java.net 包中提供了两种常见的网络协议的支持
6.2.1 TCP
传输控制协议 (Transmission Control Protocol)。TCP协议是面向连接的通信协议,即传输数据之前,在发送端和接收端建立逻辑连接,然后再传输数据,它提供了两台计算机之间可靠无差错的数据传输
三次握手:TCP协议中,在发送数据的准备阶段,客户端与服务器之间的三次交互,以保证连接的可靠
- 第一次握手,客户端向服务器端发出连接请求,等待服务器确认
- 第二次握手,服务器端向客户端回送一个响应,通知客户端收到了连接请求
- 第三次握手,客户端再次向服务器端发送确认信息,确认连接
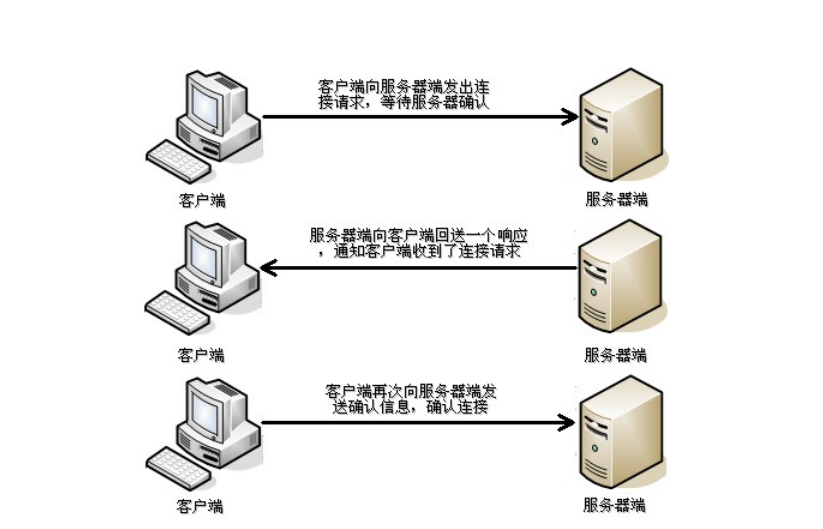
完成三次握手,连接建立后,客户端和服务器就可以开始进行数据传输了。由于这种面向连接的特性,TCP协议可以保证传输数据的安全,所以应用十分广泛,例如下载文件、浏览网页等
6.2.2 UDP
用户数据报协议(User Datagram Protocol)。UDP协议是一个面向无连接的协议。传输数据时,不需要建立连接,不管对方端服务是否启动,直接将数据、数据源和目的地都封装在数据包中,直接发送。每个数据包的大小限制在 64k 以内。它是不可靠协议,因为无连接,所以传输速度快,但是容易丢失数据。日常应用中,例如视频会议、QQ聊天等
6.3 网络编程三要素
6.3.1 协议
计算机网络通信必须遵守的规则
6.3.2 IP地址
指互联网协议地址(Internet Protocol Address),俗称 IP。IP 地址用来给一个网络中的计算机设备做唯一的编号。假如我们把“个人电脑”比作“一台电话”的话,那么“IP地址”就相当于“电话号码”
IP地址分类
- IPv4:是一个 32 位的二进制数,通常被分为 4 个字节,表示成 a.b.c.d 的形式,例如 192.168.65.100 。其中 a、b、c、d 都是0~255之间的十进制整数,那么最多可以表示42亿个
- IPv6:由于互联网的蓬勃发展,IP地址的需求量愈来愈大,但是网络地址资源有限,使得 IP 的分配越发紧张。有资料显示,全球 IPv4 地址在2011年2月分配完毕。为了扩大地址空间,拟通过 IPv6 重新定义地址空间,采用 128 位地址长度,每 16 个字节一组,分成 8 组十六进制数,表示成ABCD:EF01:2345:6789:ABCD:EF01:2345:6789 ,号称可以为全世界的每一粒沙子编上一个网址,这样就解决了网络地址资源数量不够的问题
常用命令
- 查看本机IP地址
ipconfig - 检查网络是否连通
ping IP地址
6.3.3 端口号
网络的通信,本质上是两个进程(应用程序)的通信。每台计算机都有很多的进程,那么在网络通信时,如何区分这些进程呢?
如果说IP地址可以唯一标识网络中的设备,那么端口号就可以唯一标识设备中的进程(应用程序)了
- 端口号:用两个字节表示的整数,它的取值范围是 0-65535。其中,0~1023 之间的端口号用于一些知名的网络服务和应用,普通的应用程序需要使用 1024 以上的端口号。如果端口号被另外一个服务或应用所占用,会导致当前程序启动失败
利用 协议 + IP地址 + 端口号 三元组合,就可以标识网络中的进程了,那么进程间的通信就可以利用这个标识与其它进程进行交互
Window 和 Linux 查看端口常用命令
6.4 TCP 通信程序
TCP 通信能实现两台计算机之间的数据交互,通信的两端,要严格区分为客户端(Client)与服务端(Server)。两端通信时步骤:
- 服务端程序,需要事先启动,等待客户端的连接
- 客户端主动连接服务器端,连接成功才能通信。服务端不可以主动连接客户端
在Java中,提供了两个类用于实现 TCP 通信程序:
- 客户端: java.net.Socket 类表示
创建 Socket 对象,向服务端发出连接请求,服务端响应请求,两者建立连接开始通信 - 服务端: java.net.ServerSocket 类表示
创建 ServerSocket 对象,相当于开启一个服务,并等待客户端的连接
6.4.1 Socket 类
Socket 类:该类实现客户端套接字,套接字指的是两台设备之间通讯的端点
构造方法:public Socket(String host, int port)
Socket client = new Socket("127.0.0.1", 6666);
创建套接字对象并将其连接到指定主机上的指定端口号。如果指定的 host 是 null ,则相当于指定地址为回送地址
注:回送地址(127.x.x.x) 是本机回送地址(Loopback Address),主要用于网络软件测试以及本地机进程间通信,无论什么程序,一旦使用回送地址发送数据,立即返回,不进行任何网络传输
成员方法
- public InputStream getInputStream() : 返回此套接字的输入流。
- 如果此 Scoket 具有相关联的通道,则生成的 InputStream 的所有操作也关联该通道
- 关闭生成的 InputStream 也将关闭相关的 Socket
- public OutputStream getOutputStream() : 返回此套接字的输出流。
- 如果此 Scoket 具有相关联的通道,则生成的 OutputStream 的所有操作也关联该通道
- 关闭生成的 OutputStream 也将关闭相关的 Socket
- public void close() :关闭此套接字。
- 一旦一个 Socket 被关闭,它不可再使用。
- 关闭此 Socket 也将关闭相关的 InputStream 和 OutputStream
- public void shutdownOutput() : 禁用此套接字的输出流
- 任何先前写出的数据将被发送,随后终止输出流
6.4.2 ServerSocket 类
ServerSocket 类:这个类实现了服务器套接字,该对象等待通过网络的请求
构造方法:public ServerSocket(int port)
ServerSocket server = new ServerSocket(6666);
使用该构造方法在创建 ServerSocket 对象时,就可以将其绑定到一个指定的端口号上,参数 port 就是端口号
成员方法
- public Socket accept()
侦听并接受连接,返回一个新的 Socket 对象,用于和客户端实现通信。该方法会一直阻塞直到建立连接
6.4.3 通信流程
- 【服务端】启动,创建 ServerSocket 对象,等待连接
- 【客户端】启动,创建 Socket 对象,请求连接
- 【服务端】接收连接,调用 accept 方法,并返回一个 Socket 对象
- 【客户端】Socket 对象,获取 OutputStream,向服务端写出数据
- 【服务端】Scoket 对象,获取 InputStream,读取客户端发送的数据
到此,客户端向服务端发送数据成功。
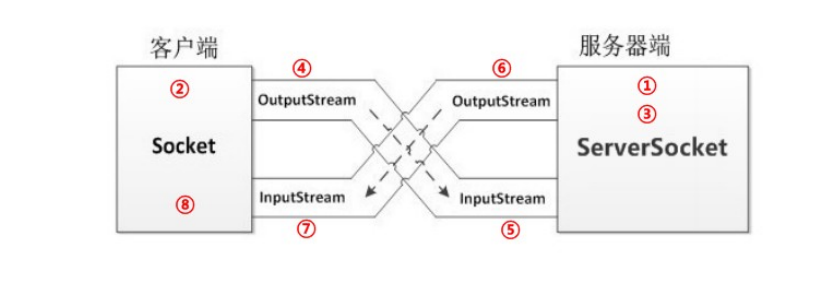
自此,服务端向客户端回写数据。
- 【服务端】Socket 对象,获取 OutputStream,向客户端回写数据
- 【客户端】Scoket 对象,获取 InputStream,解析回写数据
- 【客户端】释放资源,断开连接
6.4.4 使用
6.4.4.1 服务端和客户端案例
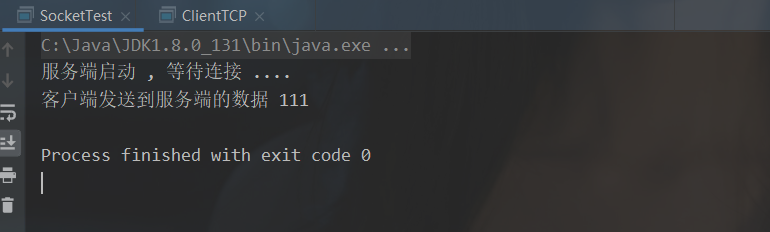
// 服务端
public static void main(String[] args) throws IOException {
System.out.println("服务端启动 , 等待连接 .... ");
// 1.创建 ServerSocket对象,绑定端口,开始等待连接
ServerSocket serverSocket = new ServerSocket(6666);
// 2.接收连接 accept 方法, 返回 socket 对象
Socket server = serverSocket.accept();
// 3.通过socket 获取输入流
InputStream inputStream = server.getInputStream();
// 4.一次性读取数据
// 4.1 创建字节数组
byte[] bytes = new byte[1024];
// 4.2 据读取到字节数组中.
int len = inputStream.read(bytes);
// 4.3 解析数组,打印字符串信息
String str = new String(bytes, 0, len);
System.out.println(str);
// =========== 回写数据 ======================
// 5. 通过 socket 获取输出流
OutputStream outputStream = server.getOutputStream();
// 6. 回写数据
outputStream.write("服务端回复给客户端,数据 111 已收到".getBytes());
// 7.关闭资源.
inputStream.close();
outputStream.close();
server.close();
}
// 客户端
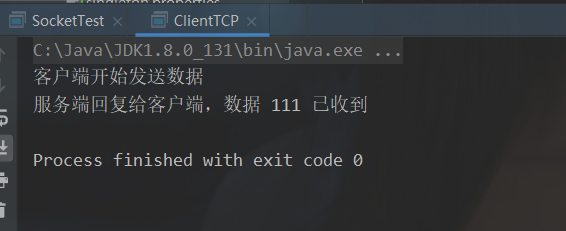
public static void main(String[] args) throws Exception {
System.out.println("客户端开始发送数据");
// 1.创建 Socket ( ip , port ) , 确定连接到哪里
Socket client = new Socket("localhost", 6666);
// 2.获取流对象 . 输出流
OutputStream outputStream = client.getOutputStream();
// 3.写出数据.
outputStream.write("客户端发送到服务端的数据 111".getBytes());
// ========== 获取回写数据 ================
// 4. 通过 Scoket 获取输入流对象
InputStream inputStream = client.getInputStream();
// 5. 读取数据数据
byte[] bytes = new byte[1024];
int len = inputStream.read(bytes);
String str = new String(bytes, 0, len);
System.out.println(str);
// 6. 关闭资源
outputStream.close();
inputStream.close();
client.close();
}
6.4.4.2 B/S 案例
访问文件位置,web/index.html
// 服务端
public static void main(String[] args) throws IOException {
System.out.println("服务端启动 , 等待连接 .... ");
// 1. 创建ServerSocket 对象,监听端口
ServerSocket server = new ServerSocket(8888);
// 2. 接收连接 accept 方法, 返回 socket 对象
Socket socket = server.accept();
// 3. 转换流读取浏览器的请求消息
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String requst = bufferedReader.readLine(); // 读取一行,GET /web/index.html HTTP/1.1
// 3.1 取出请求资源的路径
String[] strArr = requst.split(" "); //
// 3.2 去掉 web 前面的 /
String path = strArr[1].substring(1); // web/index.html
// 4. 读取客户端请求的资源文件
// 通过从字节码获取文件位置
// InputStream fis = SocketTest.class.getClassLoader().getResourceAsStream(path);
// 通过从项目根路径获取文件位置
FileInputStream fileInputStream = new FileInputStream("src/main/resources/" + path);
byte[] bytes= new byte[1024];
int len = 0 ;
// 5. 字节输出流,将文件写回客户端
OutputStream out = socket.getOutputStream();
// 5.1 写入HTTP协议响应头,固定写法
out.write("HTTP/1.1 200 OK\r\n".getBytes());
out.write("Content‐Type:text/html\r\n".getBytes());
// 5.2 必须要写入空行,否则浏览器不解析
out.write("\r\n".getBytes());
while((len = fileInputStream.read(bytes)) != -1){
out.write(bytes, 0, len);
}
fileInputStream.close();
out.close();
bufferedReader.close();
socket.close();
server.close();
}
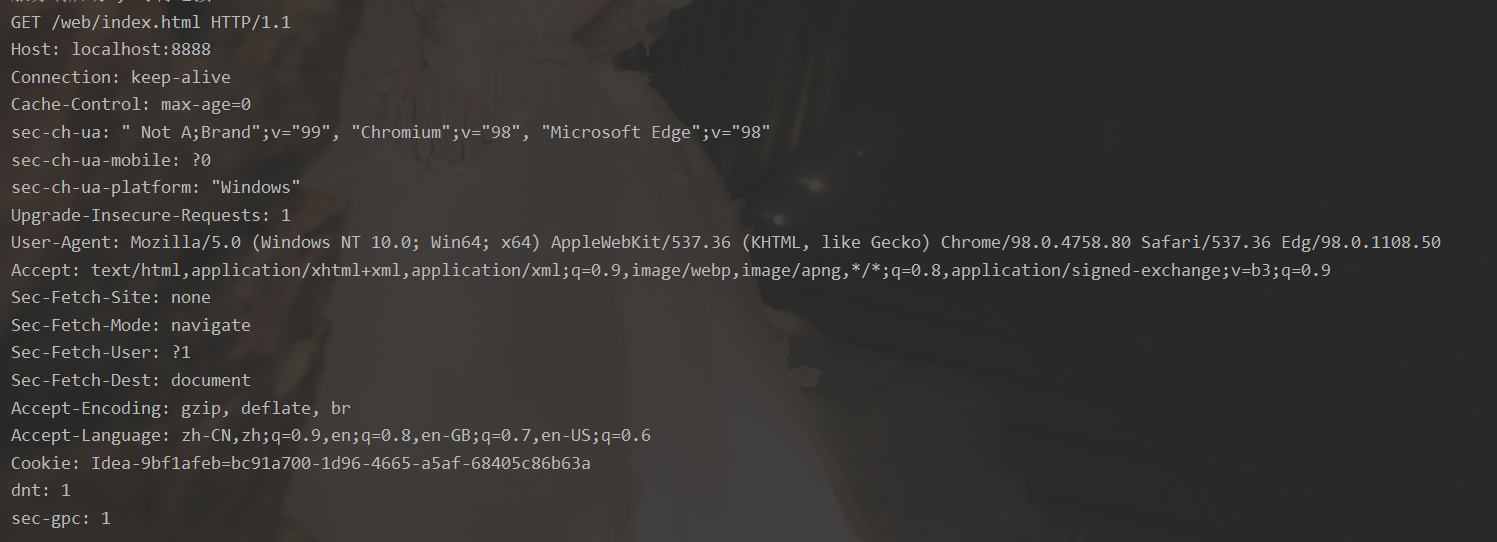
浏览器地址输入 localhost:8888/web/index.html 进行访问,浏览器请求消息:
7. Stream 流
- 可以以一种声明的方式处理数据,Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象
- 这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等
- 元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果

- “Stream流” 其实是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何元素(或其地址值)
- 这里的 filter 、sorted、map 等都是在对函数模型进行操作,集合元素并没有真正被处理。只有当终结方法 collect 执行的时候,整个模型才会按照指定策略执行操作。而这得益于 Lambda 的延迟执行特性
7.1 概念
Stream(流)是一个来自数据源的元素队列并支持聚合操作
- 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算
- 数据源流的来源。 可以是集合,数组,I/O channel, 产生器 generator 等
- 聚合操作类似SQL语句一样的操作, 比如 filter, map, reduce, find, match, sorted 等
特征:
- Pipelining: 中间操作都会返回流对象本身。这样多个操作可以串联成一个管道,如同流式风格(fluent style)。这样做可以对操作进行优化, 比如延迟执行(laziness)和短路(short-circuiting)
- 内部迭代: 以前对集合遍历都是通过 Iterator 或者 For-Each 的方式,显式的在集合外部进行迭代, 这叫做外部迭代。Stream提供了内部迭代的方式,通过访问者模式(Visitor)实现
7.2 获取流
java.util.stream.Stream
- stream() :为集合创建串行流,所有的 Collection 集合都可以通过 stream 默认方法获取流
- parallelStream() :为集合创建并行流
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
使用并行流并不是一定会提高效率,因为 JVM 对数据进行切片和切换线程也需要时间。所以数据量越小,串行操作越快;数据量越大,并行操作效果越好。 - Stream 接口的静态方法 of 可以获取数组对应的流,或者使用 Arrays.stream()
7.3 常用方法
- Intermediate(中间操作)
- 一个流可以后面跟随 0 个或多个 intermediate 操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历
- map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
- Terminal(终端操作)
- 一个流只能有一个 terminal 操作,当这个操作执行后,返回的不是一个流,无法再被操作。所以这必定是流的最后一个操作。多个 intermediate 操作只会在 Terminal 操作的时候融合起来,一次循环完成,Terminal 操作的执行,才会真正开始流的遍历,并且会生成一个结果。
- forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
- short-circuiting(短路操作)
- 对于一个 intermediate 操作,如果它接受的是一个无限大的 Stream,但返回一个有限的新Stream
- 对于一个 terminal 操作,如果它接受的是一个无限大的 Stream,但能在有限的时间计算出结果
- anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
7.3.1 forEach
void forEach(Consumer<? super T> action);
该方法接收一个 Consumer 接口函数,会将每一个流元素交给该函数进行处理
// 使用
public static void main(String[] args) {
// 以下都用这个 ArrayList 进行操作
ArrayList<User> users = new ArrayList<>();
users.add(User.builder().name("张三").age(19).build());
users.add(User.builder().name("李四").age(20).build());
users.add(User.builder().name("王五").age(21).build());
users.add(User.builder().name("赵六").age(22).build());
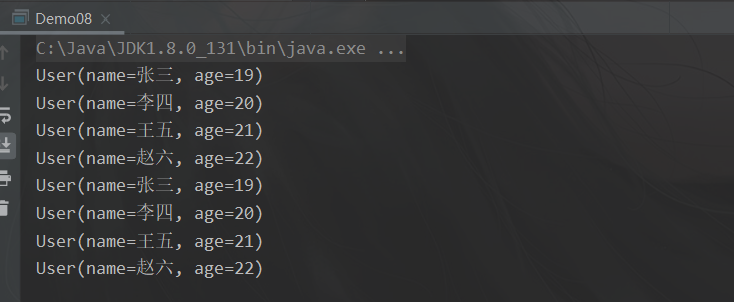
users.stream().forEach(new Consumer<User>() {
@Override
public void accept(User user) {
System.out.println(user);
}
});
users.stream().forEach(user -> System.out.println(user));
}
7.3.2 filter
可以通过 filter 方法将一个流转换成另一个子集流
Stream<T> filter(Predicate<? super T> predicate);
该接口接收一个 Predicate 函数式接口参数(可以是一个 Lambda 或方法引用)作为筛选条件
// 使用
public static void main(String[] args) {
// 返回名字里含有 “三” 的 user
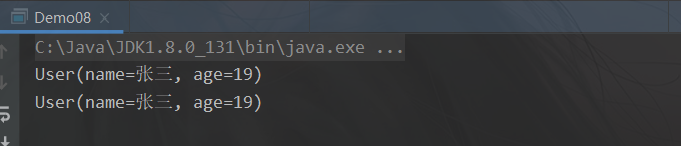
users.stream().filter(new Predicate<User>() {
@Override
public boolean test(User user) {
return user.getName().contains("三");
}
}).forEach(user -> System.out.println(user));
users.stream().filter(user -> user.getName().contains("三")).forEach(user -> System.out.println(user));
}
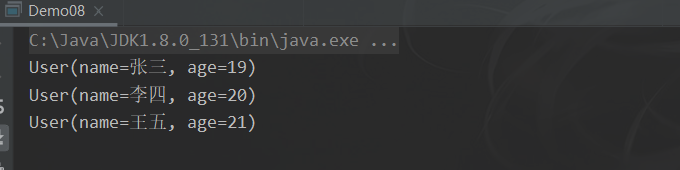
7.3.3 map
将流中的元素映射到另一个流中
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
该接口需要一个 Function 函数式接口参数,可以将当前流中的 T 类型数据转换为另一种 R 类型的流
public static void main(String[] args) {
// 将 user 转换为获取 user中的 name
users.stream().map(new Function<User, String>() {
@Override
public String apply(User user) {
return user.getName();
}
}).forEach(s -> System.out.println(s));
users.stream().map(user -> user.getName()).forEach(s -> System.out.println(s));
}
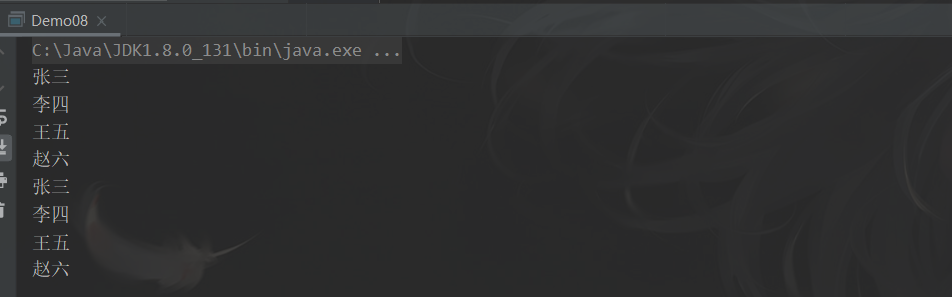
7.3.4 limit
limit 方法可以对流进行截取,只取用前 n 个
Stream<T> limit(long maxSize);
参数是一个 long 型,如果集合当前长度大于参数则进行截取,否则不进行操作
// 使用
public static void main(String[] args) {
users.stream().limit(3).forEach(user -> System.out.println(user));
}
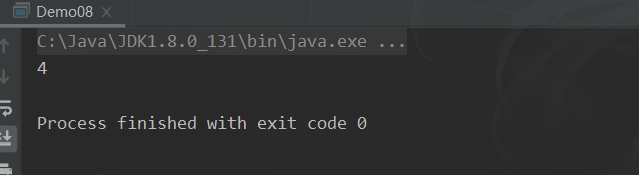
7.3.5 count
long count();
统计个数,该方法返回一个 long 值代表元素个数
// 使用
public static void main(String[] args) {
long count = users.stream().count();
System.out.println(count);
}
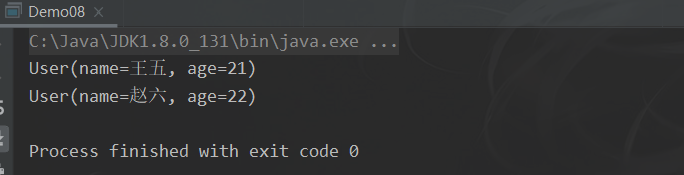
7.3.6 skip
跳过前几个元素,使用 skip 方法获取一个截取之后的新流
Stream<T> skip(long n);
如果流的当前长度大于 n,则跳过前 n 个;否则将会得到一个长度为 0 的空流
// 使用
public static void main(String[] args) {
users.stream().skip(2).forEach(user -> System.out.println(user));
}
7.3.7 collect 和 Collectors
collect 可以收集流中的数据到【集合】或者【数组】中
<R, A> R collect(Collector<? super T, A, R> collector);
<R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner);
Collectors 类实现了很多归约操作,例如将流转换成集合和聚合元素
// 使用
public static void main(String[] args) {
// 转换为 List
List<User> collect = users.stream().collect(Collectors.toList());
System.out.println(collect);
// 转换为 Map,Key 为 name,Value 为 age
Map<String, Integer> collect1 = users.stream().collect(Collectors.toMap(user -> user.getName(), user -> user.getAge()));
System.out.println(collect1);
// 合并字符串,添加分隔符
String collect2 = users.stream().map(user -> user.getName()).collect(Collectors.joining(", "));
System.out.println(collect2);
}

Collectors 的操作:
- counting:统计聚合结果的元素数量
- averagingDouble、averagingInt、averagingLong:计算聚合元素的平均值,返回值都是 Double 类型
- summingDouble、summingInt、summingLong:和上面的平均值方法类似,在需要类型转换时,需要强制转换。summingDouble 返回的是 Double 类型、summingInt 返回的是 Integer 类型,summingLong 返回的是 Long 类型
- maxBy、minBy:求聚合元素中指定比较器中的最大/最小元素
- summarizingDouble、summarizingInt、summarizingLong:统计结果,summarizingDouble 返回 DoubleSummaryStatistics 类型,summarizingInt 返回 IntSummaryStatistics 类型,summarizingLong 返回 LongSummaryStatistics 类型
- toList、toSet、toCollection:将聚合之后的元素,重新封装到队列中,然后返回,toList 方法返回的是 List 子类,toSet 返回的是 Set 子类,toCollection 返回的是 Collection 子类。Collection 的子类包括 List、Set 等众多子类,所以 toCollection 更加灵活
- toMap、toConcurrentMap:将聚合元素,重新组装为 Map 结构,toMap 返回的是 Map,toConcurrentMap 返回 ConcurrentMap,也就是说,toConcurrentMap 返回的是线程安全的 Map 结构
- groupingBy、groupingByConcurrent:roupingBy 与 toMap 都是将聚合元素进行分组,区别是,toMap 结果是 1:1 的 k-v 结构,groupingBy 的结果是 1:n 的 k-v 结构
- partitioningBy:partitioningBy 与 groupingBy 的区别在于,partitioningBy 借助 Predicate 断言,可以将集合元素分为 true 和 false 两部分
- joining:对 String 类型的元素进行聚合,拼接成一个字符串返回
- collectingAndThen:先对集合进行一次聚合操作,然后通过 Function 定义的函数,对聚合后的结果再次处理
- mapping:先通过 Function 函数处理数据,然后通过 Collector 方法聚合元素
- reducing:提供了三个重载方法,maxBy 和 minBy 这两个函数就是通过 reducing 实现的:
- public static
Collector<T, ?, Optional > reducing(BinaryOperator op):直接通过 BinaryOperator 操作,返回值是 Optional - public static
Collector<T, ?, T> reducing(T identity, BinaryOperator op):预定默认值,然后通过 BinaryOperator 操作 - public static <T, U> Collector<T, ?, U> reducing(U identity, Function<? super T, ? extends U> mapper, BinaryOperator op):预定默认值,通过 Function 操作元素,然后通过 BinaryOperator 操作
- public static
7.3.8 concat
如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)
注:这是一个静态方法,与 java.lang.String 当中的 concat 方法是不同的
// 使用
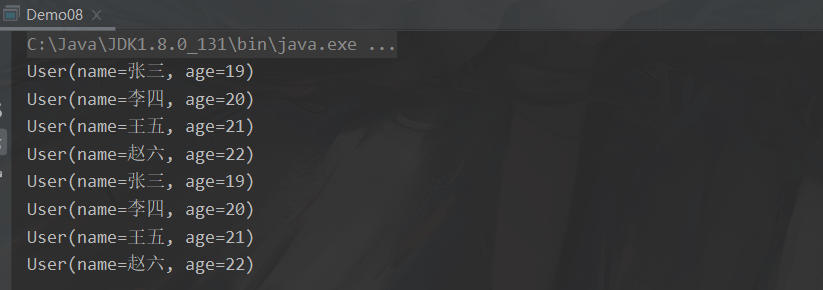
public static void main(String[] args) {
Stream<String> stringStream = users.stream().map(user -> user.getName());
Stream<Integer> integerStream = users.stream().map(user -> user.getAge());
// 将包含 name 和 age 的两个流合成一个
Stream.concat(stringStream, integerStream).forEach(serializable -> System.out.println(serializable));
}
8. 方法引用
双冒号 :: 为引用运算符,而它所在的表达式被称为方法引用。如果 Lambda 要表达的函数方案已经存在于某个方法的实现中,那么则可以通过双冒号来引用该方法作为 Lambda 的替代者。如:
- Lambda 表达式写法: s -> System.out.println(s)
拿到参数之后经 Lambda 之手,继而传递给 System.out.println 方法去处理。 - 方法引用写法: System.out::println
直接让 System.out 中的 println 方法来取代 Lambda。两种写法的执行效果完全一样,而第二种方法引用的写法复用了已有方案,更加简洁。
使用 Lambda,根据“可推导就是可省略”的原则,无需指定参数类型,也无需指定重载形式——它们都将被自动推导。而如果使用方法引用,也是同样可以根据上下文进行推导。函数式接口是 Lambda 的基础,而方法引用是 Lambda 的孪生兄弟。
// 使用
public static void main(String[] args) {
// Lambda 写法
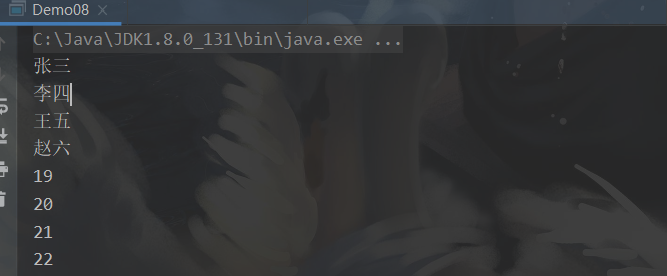
users.stream().map(user -> user).forEach(user -> System.out.println(user));
// 方法引用
users.stream().map(User::toString).forEach(System.out::println);
users.stream().map(User::getName).forEach(System.out::println);
}
9. 序列化与反序列化
9.1 概念
- Java 提供了一种对象序列化的机制,该机制中,一个对象可以被表示为一个字节序列,该字节序列包括该对象的数据、有关对象的类型的信息和存储在对象中数据的类型
- 将序列化对象写入文件之后,可以从文件中读取出来,并且对它进行反序列化,也就是说,对象的类型信息、对象的数据,还有对象中的数据类型可以用来在内存中新建对象
- 整个过程都是 Java 虚拟机(JVM)独立的,也就是说,在一个平台上序列化的对象可以在另一个完全不同的平台上反序列化该对象
- 类 ObjectInputStream 和 ObjectOutputStream 是高层次的数据流,它们包含反序列化和序列化对象的方法
9.2 序列化
一个类的对象要想序列化成功,必须满足两个条件:
- 该类必须实现 java.io.Serializable 接口
- 该类的所有属性必须是可序列化的。如果有一个属性不是可序列化的,则该属性必须用 transient 注明是短暂的
ObjectOutputStream 类用来序列化一个对象,如下的 SerializeDemo 例子实例化了一个 Employee 对象,并将该对象序列化到一个文件中。该程序执行后,就创建了一个名为 employee.ser 文件
public class Employee implements java.io.Serializable{
public String name;
public String address;
public transient int SSN; // 短暂的
public int number;
public void mailCheck(){
System.out.println("Mailing a check to " + name + " " + address);
}
}
public class SerializeDemo{
public static void main(String [] args){
Employee e = new Employee();
e.name = "Reyan Ali";
e.address = "Phokka Kuan, Ambehta Peer";
e.SSN = 11122333;
e.number = 101;
try{
FileOutputStream fileOut = new FileOutputStream("/employee.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut);
out.writeObject(e);
out.close();
fileOut.close();
System.out.printf("Serialized data is saved in /employee.ser");
}catch(IOException i){
i.printStackTrace();
}
}
}
9.3 反序列化
下面的 DeserializeDemo 程序实例了反序列化,/employee.ser 存储了 Employee 对象
public class DeserializeDemo{
public static void main(String [] args){
Employee e = null;
try{
FileInputStream fileIn = new FileInputStream("/employee.ser");
ObjectInputStream in = new ObjectInputStream(fileIn);
e = (Employee) in.readObject();
in.close();
fileIn.close();
}catch(IOException i){
i.printStackTrace();
return;
}catch(ClassNotFoundException c){
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
System.out.println("Deserialized Employee..."); // Deserialized Employee...
System.out.println("Name: " + e.name); // Name: Reyan Ali
System.out.println("Address: " + e.address); // Address: Phokka Kuan, Ambehta Peer
System.out.println("SSN: " + e.SSN); // SSN: 0
System.out.println("Number: " + e.number); // Number: 101
}
}
/* 当对象被序列化时,属性 SSN 的值为 111222333,但是因为该属性是短暂的,
该值没有被发送到输出流。所以反序列化后 Employee 对象的 SSN 属性为 0。
*/
10. Optional
一个可以更加轻松的避免 NPE(空指针异常,NullPointException)的工具,Optional 是一个包装类,且不可变,不可序列化
10.1 创建实例 of、ofNullable
为了控制生成实例的方式,也是为了收紧空值 Optional 的定义,Optional 将构造函数定义为 private。想要创建 Optional 实例,可以借助 of 和 ofNullable 两个方法实现。of 方法传入的参数不能是 null 的,否则会抛出 NullPointerException。所以,对于可能是 null 的结果,一定使用 ofNullable
UserDemo userDemo = UserDemo.builder().id(1).name("张三").build();
Optional<UserDemo> userDemoOptional = Optional.of(userDemo);
Optional<Object> nullOptional = Optional.ofNullable(null);
Optional 类中还有一个静态方法:empty,这个方法直接返回了内部定义的一个常量 Optional<?> EMPTY = new Optional<>(),这个常量的 value 是 null。ofNullable 方法也是借助了 empty 实现 null 的包装:
public static <T> Optional<T> ofNullable(T value) {
return value == null ? empty() : of(value);
}
所以说,对于 null 的 Optional 包装类,指向的都是相同的实例对象,Optional.empty() == Optional.ofNullable(null) 返回的是 true。换句话说,空 Optional 是单例的,都是引用 Optional.EMPTY
10.2 获取数据 get
Optional 值为空时,使用 get 方法将抛出 NoSuchElementException 异常。如果不想抛出异常,或者能够 100% 确定不是空 Optional,或者使用 isPresent 方法判断
public T get() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
使用 get 方法前,必须使用 isPresent 检查。但是使用 isPresent 前,可以先看是否可以使用 orElse、orElseGet 等方法代替实现。
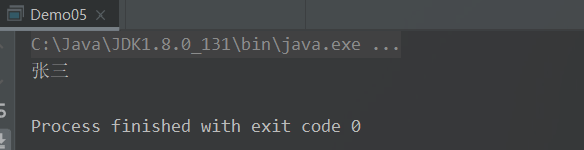
System.out.println(userDemoOptional.get().getName());
10.3 值为空判断 isPresent、ifPresent
isPresent 用来判断值是否为空,类似于obj != null,ifPresent 可以传入一个 Consumer 操作,当值不为空的时候,会执行 Consumer 函数。
// if (userDemoOptional!= null) {
if (userDemoOptional.isPresent()) {
System.out.println(1111);
}
上面的方法等价于:
userDemoOptional.ifPresent(userDemo1 -> System.out.println(1111));
10.4 值处理 map、flatMap
map 和 flatMap 是对 Optional 的值进行操作的方法,区别在于,map 会将结果包装到 Optional 中返回, flatMap 不会。但是两个方法返回值都是 Optional 类型,这也就要求,flatMap 的方法函数返回值需要是 Optional 类型
public<U> Optional<U> map(Function<? super T, ? extends U> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent())
return empty();
else {
return Optional.ofNullable(mapper.apply(value));
}
}
如果 Optional 的值为空,map 直接返回 Optional.EMPTY,否则会执行函数结果,并使用Optional.ofNullable 包装并返回
Optional<String> stringOptional = userDemoOptional.map(userDemo1 -> userDemo1.getName()); // abc
Optional<String> stringOptional1 = stringOptional.map(name -> name.toUpperCase()); // ABC
String aDefault = stringOptional1.orElse("default"); // 假如为空,则执行 else,有一个默认值
System.out.println(aDefault); // 有值为 abc,则 aDefault 为 ABC、值为空,则 aDefault 为 default
String aDefault = userDemoOptional.map(UserDemo::getName).map(String::toUpperCase).orElse("default");
10.5 值为空的处理 orElse、orElseGet、orElseThrow
当值为空时,orElse和orElseGet返回默认值,orElseThrow抛出指定的异常
orElse 和 orElseGet 的区别是 orElse 方法传入的参数是明确的默认值,orElseGet 方法传入的参数是获取默认值的函数。如果默认值的构造过程比较复杂,需要经过一系列的运算逻辑,那一定要使用 orElseGet,因为 orElseGet 是在值为空的时候,才会执行函数,并返回默认值,如果值不为空,则不会执行函数,相比于 orElse 而言,减少了一次构造默认值的过程。
String aDefault = userDemoOptional.map(UserDemo::getName)
.map(String::toUpperCase)
.orElse(null);
// .orElseGet(() -> null);
// .orElseThrow(() -> new IllegalArgumentException("clazz属性不合法"));
10.6 条件过滤 filter
filter 方法提供的是值验证,如果值验证为 true,返回当前值;否则,返回空 Optional
// 遍历 userDemos,找到姓名属性为空的,打印 id
for (UserDemos userDemo : userDemos) {
Optional.of(userDemo )
.filter(x -> x.getName() == null)
.ifPresent(x -> System.out.println(x.getId()));
}
10.7 equals、hashCode、toString
public boolean equals(Object obj) {
// 同一对象判断
if (this == obj) {
return true;
}
// 类型判断
if (!(obj instanceof Optional)) {
return false;
}
Optional<?> other = (Optional<?>) obj;
// 最终还是值的判断
return Objects.equals(value, other.value);
}
public int hashCode() {
// 直接返回值的hashCode
return Objects.hashCode(value);
}
public String toString() {
return value != null
? String.format("Optional[%s]", value) // 用到了值的toString结果
: "Optional.empty";
}
- equals 方法,Optional.of(s1).equals(Optional.of(s2)) 完全等价于 s1.equals(s2)
- hashCode 方法,直接返回的是值的 hashCode,如果是空Optional,返回的是0
- toString 方法,为了能够识别是 Optional,将打印数据包装了一下。如果是空 Optional,返回的是字符串“Optional.empty”;如果是非空,返回是 “Optional[值的toString]”

