

Lucene 分页搜索实现
Lucene中有两种分页查询方式
1、一次查询出大量数据,然后根据页码定位是哪个文档,其实就是暴力获取了
2、通过调用searchAfter来实现
我们都知道collect是lucene中对搜索到的文档进行收集和排序过程,searchAfter也是通过一个收集器来控制的,叫PagingTopScoreDocCollector

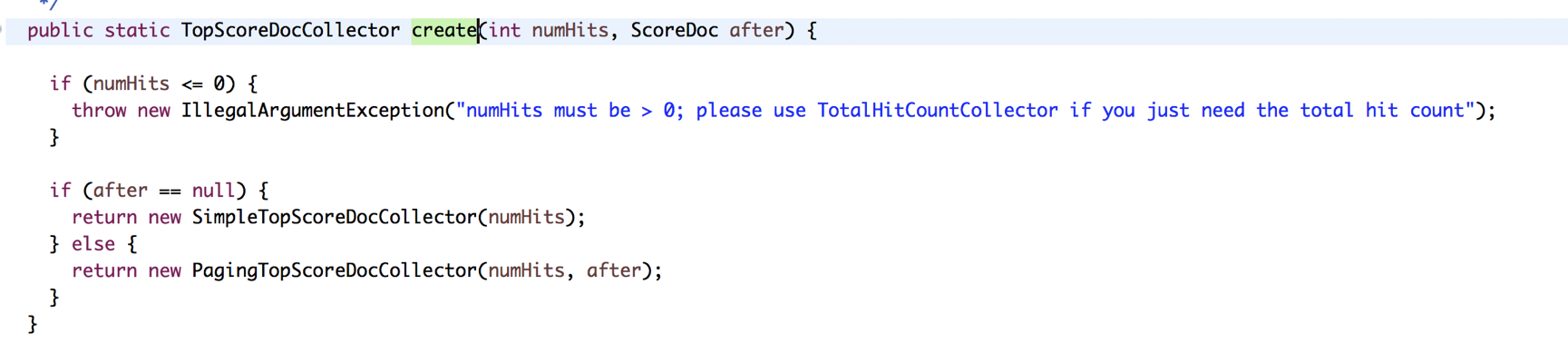
PagingTopScoreDocCollector中最主要的方法是getLeafCollector()判断分页查询的代码为,collect中包含了判断视为当前页的结果还有结果排序,排序方法是pq.updateTop();

updateTop中就执行两部操作,在查询到结果中找到最小的,然后返回heap[1],i默认从1开始所以head【0】为空,所以返回heap[1],每次都会和heap[1]对比把最小的放在前面
这是一个弄了一个二叉堆,具体分析的可以看http://quweiprotoss.blog.163.com/blog/static/408828832011523114133876/这个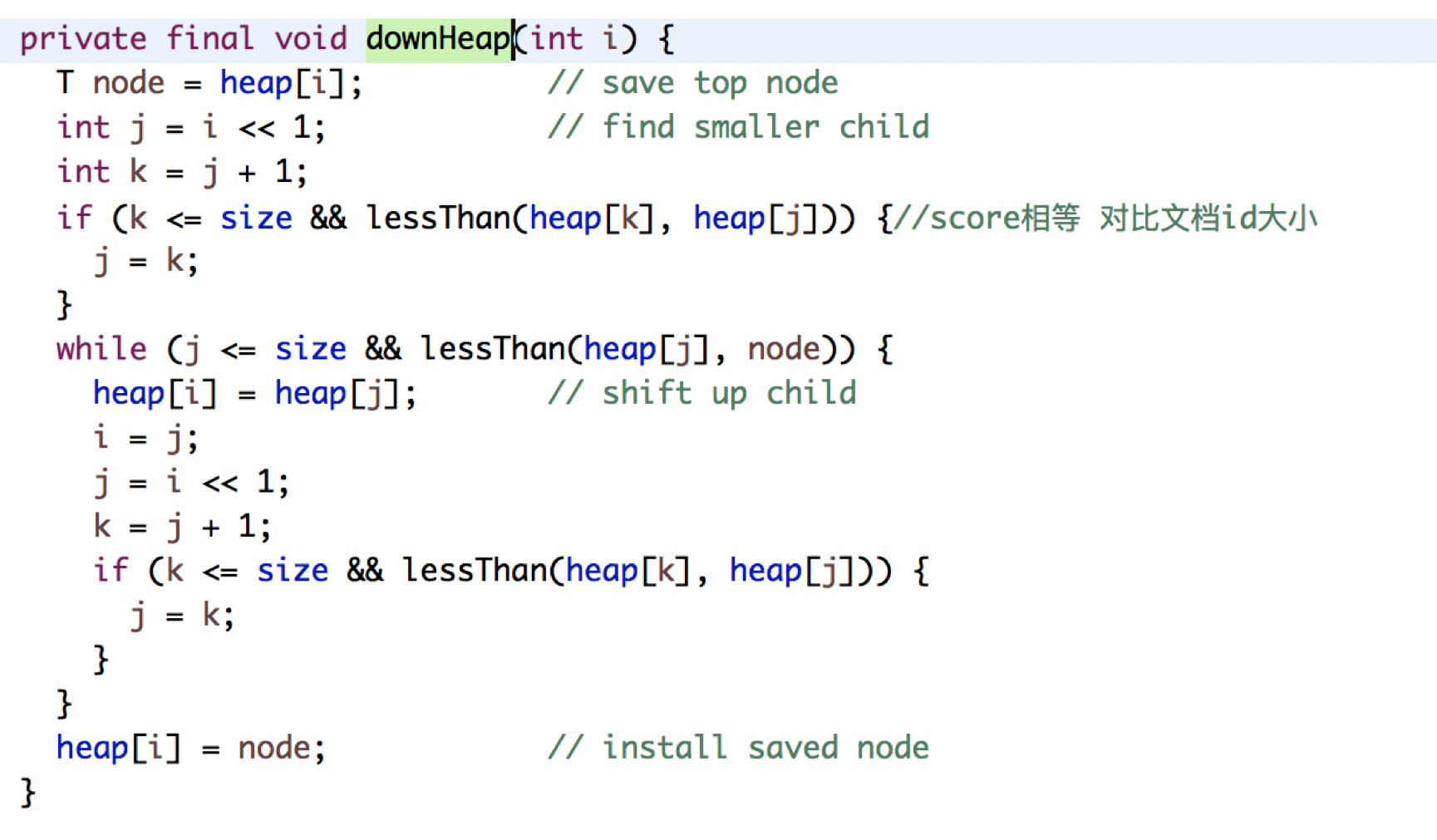
当score分数一样的时候会对比文档大小,最后是按照文档id的大小进行排列的
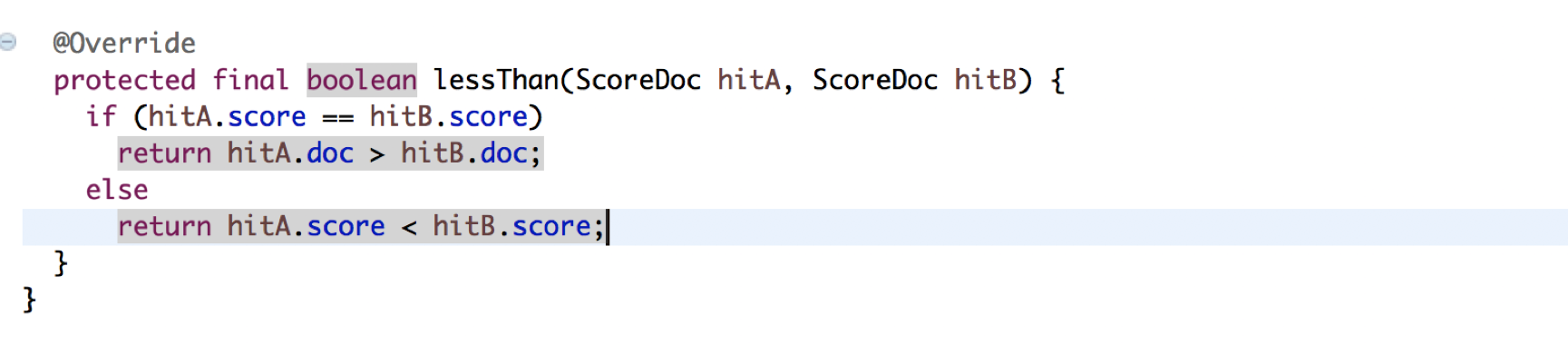
说白了searchAfter也是全部搜索了一遍只不过在collect过程中添加了一个上一页最后doc和当前返回的doc对比,这个过程时间复杂度为o(n),而用普通的查询这个过程会没有从某种程度上来说兴许速度还会由于searchAfter

