Spark基本API解读
1. Spark基本API解读
首先我们写一段简单的进行单词统计的代码,考察其中出现的API,然后做出整理:

import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
/*
使用java实现word count
*/
public class WCJava1 {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("wcjava");
JavaSparkContext jsc = new JavaSparkContext(conf);
//加载文件
JavaRDD<String> rdd1 = jsc.textFile("hdfs://mycluster/wc.txt");
//压扁
JavaRDD<String> rdd2 = rdd1.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
//map
JavaPairRDD<String, Integer> rdd3 = rdd2.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairRDD<String, Integer> rdd4 = rdd3.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
List<Tuple2<String, Integer>> list = rdd4.collect();
for (Tuple2<String, Integer> stringIntegerTuple2 : list) {
System.out.println(stringIntegerTuple2);
}
}
}
从语法角度来说,scala版的代码比java要简洁的多,但从性能角度来说,java虽然啰嗦,却优于scala,上述代码中,使用到了一些在做RDD变换中经常会用到的API,事实上,这些API可以参考apache的官方文档,可见网址:http://spark.apache.org/docs/latest/rdd-programming-guide.html
1.1 Spark core模块核心概念介绍
RDD:弹性分布式数据集(resilient distributed dataset)
RDD是Spark编程中的一个核心概念,不同于Hadoop的存储在Datanode中的真实数据集,RDD是一个逻辑上的概念,并没有真实的数据,RDD对象一旦创建出来,就是不可变的了,而“分布式”也就意味着这些数据是被分成不同的范围执行并行计算的,下面我们摘录一段scala版RDD的官方文档注释,进行一下解读:
Internally, each RDD is characterized by five main properties:
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for
an HDFS file)
内部来说,每个RDD都由五个主要特性组成:
1. 分区列表:指的是分区对象中包含的数据的范围
2. 计算每个切片的函数:指的是operator,也就是算子,或者称之为算法
3. 和其他RDD的依赖列表:主要有宽依赖以及窄依赖两种
4. (可选的)KV类型RDD的分区器
5. (可选的)计算每个切片的首选位置列表
Task
任务是Spark中最小的执行单位,RDD的每个分区对应一个task,而每个任务运行在节点上的线程中
依赖(Dependency)
之前说过,依赖分为两种,宽依赖以及窄依赖,
窄依赖:子RDD的每个分区依赖于父RDD的少量分区(不一定是只有一个)
NarrowDependency:本身是一个抽象类,有三个实现子类,OneToOneDependency,PruneDependency以及RangeDependency
宽依赖:子RDD的每个分区依赖于父RDD的所有分区
ShuffleDependency:是Dependency抽象类的实现子类,可以将其称之为shuffle依赖或是宽依赖
1.2 RDD API基本特性总结
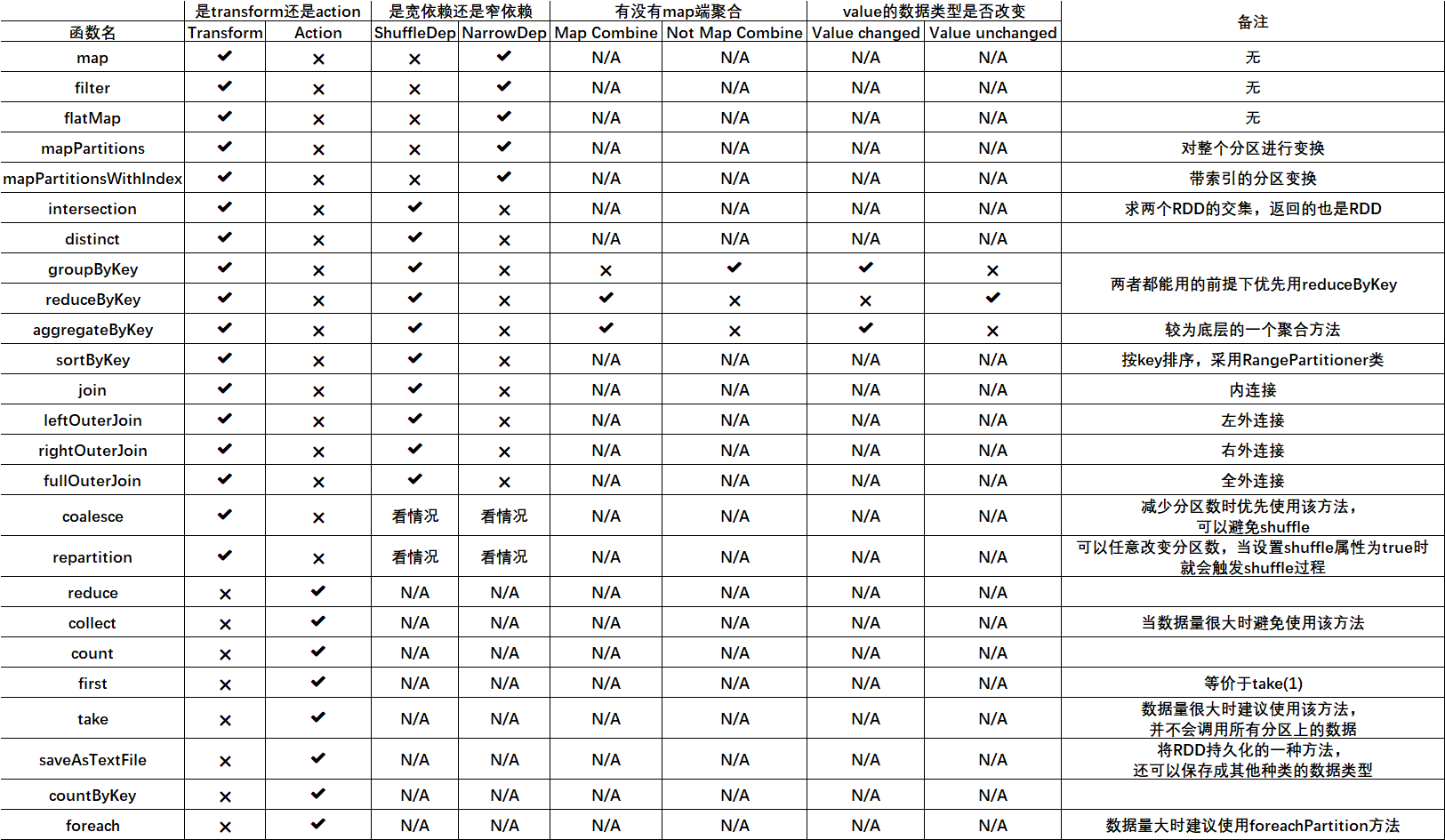
关于groupByKey,reduceByKey等聚合方法的总结:
查看groupByKey的scala源码:
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
// groupByKey shouldn't use map side combine because map side combine does not
// reduce the amount of data shuffled and requires all map side data be inserted
// into a hash table, leading to more objects in the old gen.
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
可以看到,很多带有"ByKey"的方法底层都是通过调用combineByKeyWithClassTag方法来实现的,而在groupByKey方法体中我们发现它将mapSideCombine=false,因此该方法并没有map端的聚合
关于基本聚合方法aggregateByKey方法的解读:
参考该方法的源码:
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)] = self.withScope {
// Serialize the zero value to a byte array so that we can get a new clone of it on each key
val zeroBuffer = SparkEnv.get.serializer.newInstance().serialize(zeroValue)
val zeroArray = new Array[Byte](zeroBuffer.limit)
zeroBuffer.get(zeroArray)
lazy val cachedSerializer = SparkEnv.get.serializer.newInstance()
val createZero = () => cachedSerializer.deserialize[U](ByteBuffer.wrap(zeroArray))
// We will clean the combiner closure later in `combineByKey`
val cleanedSeqOp = self.context.clean(seqOp)
combineByKeyWithClassTag[U]((v: V) => cleanedSeqOp(createZero(), v),
cleanedSeqOp, combOp, partitioner)
}
def combineByKeyWithClassTag[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
if (keyClass.isArray) {
if (mapSideCombine) {
throw new SparkException("Cannot use map-side combining with array keys.")
}
if (partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
}
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}
很明显,该函数使用的是一个柯里化过程,第一个括号内由用户指定一个zeroValue,即零值U,该值可以是任意的数据类型,在seqOp中使用的变换过程是 ( U , V ) => U,在同一个分区中,该零值与value进行某种聚合操作,因此能够将value的数据类型改变成U的数据类型,而combOp则是对分区之间各自计算出来的U值进行聚合操作,然后聚合成最终的U,即 ( U , U ) => U,该函数的优点有这么几个:
1. 使用了map端聚合,因此可以提高计算效率
2. 可以改变value的数据类型,并且可由用户自行指定聚合规则,非常的灵活
那么,下面我们就来进行一次实战演练,写一个Demo运用一下该方法吧!
import org.apache.spark.{SparkConf, SparkContext}
/*
写一个使用aggregateByKey方法做word count的demo
*/
object AggScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("aggscala")
val sc = new SparkContext(conf)
//设置zeroValue
val zeroValue = ""
def seqOp(U:String, V:Int) : String = {
U + V + ","
}
def combOp(U1:String, U2:String) : String = {
U1 + ":" + U2
}
sc.textFile("hdfs://mycluster/wc.txt",2).flatMap(e => e.split(" "))
.map(e => (e, 1))
.aggregateByKey(zeroValue)(seqOp,combOp)
.collect
.foreach(println(_))
}
}
关于countByKey为何是action的疑问
我们来一起看一下countByKey的源代码:
def countByKey(): Map[K, Long] = self.withScope {
self.mapValues(_ => 1L).reduceByKey(_ + _).collect().toMap
}
查看源码,我们可以发现,countByKey是将每一个value计数成1,然后调用的是reduceByKey方法,最后再调用collect方法和map方法,因此触发了action操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号