Python用python-docx抓取公众号文章写入word
一、安装包
pip3 install python-docx
二、了解python-docx
from docx import Document
from docx.shared import Inches
document = Document()
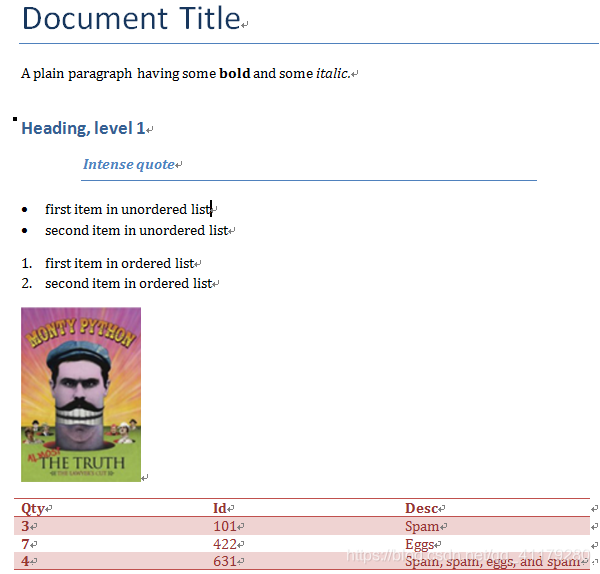
#添加标题,并设置级别,范围:0 至 9,默认为1
document.add_heading('Document Title', 0)
#添加段落,文本可以包含制表符(\t)、换行符(\n)或回车符(\r)等
p = document.add_paragraph('A plain paragraph having some ')
#在段落后面追加文本,并可设置样式
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True
document.add_heading('Heading, level 1', level=1)
document.add_paragraph('Intense quote', style='Intense Quote')
#添加项目列表(前面一个小圆点)
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
document.add_paragraph('second item in unordered list', style='List Bullet')
#添加项目列表(前面数字)
document.add_paragraph('first item in ordered list', style='List Number')
document.add_paragraph('second item in ordered list', style='List Number')
#添加图片
document.add_picture('monty-truth.png', width=Inches(1.25))
records = (
(3, '101', 'Spam'),
(7, '422', 'Eggs'),
(4, '631', 'Spam, spam, eggs, and spam')
)
#添加表格:一行三列
# 表格样式参数可选:
# Normal Table
# Table Grid
# Light Shading、 Light Shading Accent 1 至 Light Shading Accent 6
# Light List、Light List Accent 1 至 Light List Accent 6
# Light Grid、Light Grid Accent 1 至 Light Grid Accent 6
# 太多了其它省略...
table = document.add_table(rows=1, cols=3, style='Light Shading Accent 2')
#获取第一行的单元格列表
hdr_cells = table.rows[0].cells
#下面三行设置上面第一行的三个单元格的文本值
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for qty, id, desc in records:
#表格添加行,并返回行所在的单元格列表
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
document.add_page_break()
#保存.docx文档
document.save('demo.docx')
三、公众号写入word
# -*- coding:utf-8 -*-
"""
Author:SPIDERMAN
Time: 2021/2/8
Software: PyCharm
"""
import time
from scrapy import Selector
import re
from docx import Document
from docx.shared import Inches
import requests
from docx.oxml.ns import qn
from docx.shared import Pt,RGBColor
header = {
"Host": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/79.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
def get_biz_html(url):
"""
获取公众号的页面
:param url:
:return:
"""
res = requests.get(url=url,timeout=8,headers=header).text
contents = Selector(text=res).css('#js_content')
re_title = re.compile('property="og:title".*?content="(.*?)"',re.S)
re_time = re.compile(',n="(.*?)",',re.S)
re_img = re.compile('property="og:image".*?content="(.*?)".*?/>')
re_des = re.compile('name="description".*?content="(.*?)".*?/>')
try:
#构建存储字典
item = {}
#公众号标题
title = re.findall(re_title,res)[0].strip()
#公众号作者
source = Selector(text=res).css('#js_name::text').extract_first().strip()
#公众号链接
url = url
#公众号发布时间
news_time = re.findall(re_time,res)[0]
if news_time:
news_time=time.strftime(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(int(news_time))))
#公众号封面
newsImage = re.findall(re_img,res)[0].strip()
try:
newsDes = re.findall(re_des,res)[0].strip()
except:
newsDes = ''
content = contents.extract_first()
get_html_item(title,content,source,news_time)
except Exception as e:
print('[Exception]:'+str(e))
pass
def get_html_item(title,contents,source,news_time):
"""
将文章正文分段
:param title:
:param contents:
:param source:
:param news_time:
:return:
"""
print('[INFO]:'+title)
print('[INFO]:'+contents)
content_list =[]
content_set = set()
contents = Selector(text=contents).css('#js_content *')
item = {}
for content in contents:
# print(content.extract())
if 'img' in content.extract():
sub_txt = sub_html(content.extract())
if sub_txt:
sub_txt = sub_txt.strip()
if sub_txt not in content_set:
content_set.add(sub_txt)
text = sub_txt.strip()
content_list.append({'text':text})
img = content.css('img::attr(data-src)').extract_first()
if img and img not in content_set:
content_list.append({'img': img.strip()})
content_set.add(img)
else:
sub_txt = sub_html(content.extract())
if sub_txt:
sub_txt = sub_txt.strip()
if sub_txt not in content_set:
content_set.add(sub_txt)
text = sub_txt.strip()
content_list.append({'text': text})
print('[INFO]:html_to_word')
html_to_word(title,content_list,source,news_time)
def sub_html(text):
"""
替换标签
:param text:
:return:
"""
text = re.sub(re.compile('<.*?>'),'',text)
return text
def html_to_word(title,contents,source,news_time):
"""
写入wrod
:param title:
:param contents:
:param source:
:param news_time:
:return:
"""
document = Document()
document.styles['Normal'].font.name = u'宋体'
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
document.styles['Normal'].font.size = Pt(10.5)
document.styles['Normal'].font.color.rgb = RGBColor(0, 0, 0)
#添加标题,并设置级别,范围:0 至 9,默认为1
document.add_heading(title, 0)
#添加段落,文本可以包含制表符(\t)、换行符(\n)或回车符(\r)等
document.add_paragraph('{source} {news_time} '.format(source=source,news_time=news_time)).italic = True
for content in contents:
try:
img =content['img']
requset_img(img)
document.add_picture('1.jpg', width=Inches(5))
except:
text = content['text']
document.add_paragraph(text)
document.add_page_break()
#保存.docx文档
document.save('{}.docx'.format(title))
print('[INFO]:{}.docx is ok'.format(title))
# document.save('{}.docx'.format(title))
# print('{}.docx is ok'.format(title))
def img_parse(response):
with open('1.jpg', 'wb') as img:
img.write(response)
def requset_img(url):
response = requests.get(url=url)
img_parse(response.content)
if __name__ == '__main__':
get_biz_html('https://mp.weixin.qq.com/s/SR7-VuRNH4h8W2MrluSjiA')
同学们可以自己运行一下
console.log("公众号:虫术")
console.log("wx:spiderskill")
欢迎大家前来交流

 浙公网安备 33010602011771号
浙公网安备 33010602011771号