
python字符串的格式化
字符串格式化,就是字符串中含有变量,根据需求地取出。比如,你给所有员工发邮件过程中,“你好,张三:”,那个张三可以是李四,也可以是王五等。对文本相应位置进行变量替换,叫做文本(字符串)格式化。
三种形式:
- %s和%d
- {}.format()
- f'{}'
- 还有一种方式:标准库模板
1、%号:
%号格式化字符串的方式从Python诞生之初就已经存在
| 格式化符号 | 说明 | 举例 |
| %c | 转换成字符(ASCII 码值,或者长度为一的字符串) |
print('%c' % 65) 输出:A
|
| %s | 优先用str()函数进行字符串转换 |
print('%s' % [1,2,3]) 输出:[1, 2, 3]
|
| %% | 输出% (格式化字符串里面包括百分号,那么必须使用%%) |
print('%d%%' % 2) 输出:2%
|
| %f | 转成浮点数 |
print('%f' % 6) 输出:6.000000(默认六位小数)
print('%.2f' % 6) 输出:6.00
|
| %e | 转成科学计数法 |
print('%e' % 6) 输出:6.000000e+00
print('%.2e' % 6) 输出:6.00e+00
print('%.2e' % 1000) 输出:1.00e+03
|
| %g | 在保证六位有效数字的前提下,使用小数方式,否则使用科学计数法 |
print('%g' % 1111.1111) 输出:1111.11
print('%.7g' % 1111.1111) 输出:1111.111
print('%.2g' % 1111.1111) 输出:1.1e+03
print('%.7g' % 1111.1) 输出:1111.1
|
1> 格式的字符串(即%s)与被格式化的字符串(即传入的值)必须按照位置一一对应
备注:当需格式化的字符串过多时,位置极容易搞混
names = ['张三', '李四', '王五'] age = [18, 15, 13] print('你好,%s' % names[0]) print('hello, %s年纪是%d, %s年纪是%d' % (names[1], age[1], names[2], age[2]))
注意: 这里的格式化字符串由两部分组成,第一部分是%,第二部分是s或者d。这里文本是字符串(str)就使用s,str首字母;相应的是数字就使用d,data首字母。
2>可以通过字典方式格式化,打破了位置带来的限制与困扰
name_age = {'name': '张三', 'age': 18}
print('hello, %(name)s年纪是%(age)s' % name_age)
print('hello, %(name)s年纪是%(age)s' % {'name': '张三', 'age': 18})
2、str.format
format方法是在Python 2.6中引入的,是字符串类型的内置方法,str.format的方式在性能和使用的灵活性上都比%号更胜一筹
1>使用位置参数
# 按照位置一一对应 names = ['张三', '李四', '王五'] age = [18, 15, 13] print('你好,{}'.format(names[0])) print('hello, {}年纪是{}, {}年纪是{}'.format(names[1], age[1], names[2], age[2]))
2>使用索引
# 使用索引取对应位置的值 print('hello, {0}年纪是{2}, {1}年纪是{3}'.format('张三', '李四', 18, 15))
3>使用关键字参数or字典
备注:传入字典的时候需要使用**进行解包操作,%传入字典的时候不需要**
# 可以通过关键字or字典方式的方式格式化,打破了位置带来的限制与困扰 name_age = {'name': '张三', 'age': 18} print('hello, {name}年纪是{age}'.format(name='张三', age=18)) print('hello, {name}年纪是{age}'.format(**name_age)) print('hello, {name}年纪是{age}'.format(**{'name': '张三', 'age': 18}))
4>填充与格式化
# 先取到值,然后在冒号后设定填充格式:[填充字符][对齐方式][宽度]
# :号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充
# *<10:左对齐,总共10个字符,不够的用*号填充 print('{0:*<10}'.format('开始执行啦'))
print('{:*<10}'.format('开始执行啦'))
# *>10:右对齐,总共10个字符,不够的用*号填充
print('{0:?>10}'.format('开始执行啦'))
print('{:?>10}'.format('开始执行啦'))
# *^10:居中显示,总共10个字符,不够的用*号填充
print('{1:%^10}'.format('开始执行啦', '执行中'))
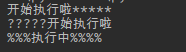
5>精度与进制
b、d、o、x分别是二进制、八进制、十进制、十六进制
print('{salary:.3f}'.format(salary=123213.12351)) #精确到小数点后3位,四舍五入,结果为:1232132.124 print('{0:b}'.format(123)) # 转成二进制,结果为:1111011 print('{0:o}'.format(9)) # 转成八进制,结果为:11 print('{0:x}'.format(15)) # 转成十六进制,结果为:f print('{0:,}'.format(99812939393931)) # 千分位格式化,结果为:99,812,939,393,931
str.format() 格式化数字的多种方法:
^, <, > 分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。
+ 表示在正数前显示 +,负数前显示 -; (空格)表示在正数前加空格
b、d、o、x 分别是二进制、十进制、八进制、十六进制
使用大括号来转义大括号:
print("{} 对应的位置是 {{0}}".format("hello")) 结果为:hello 对应的位置是 {0}
| 数字 | 格式 | 输出 | 描述 |
|
3.1455926 -3.1455926 |
{:.2f} |
3.15 -3.15 |
保留小数点后两位,四舍五入 |
| 3.1455926 | {:+.2f} | +3.15 | 带符号保留小数点后两位 |
| -1 | {:+.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零(填充左边,宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x(填充右边,宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x(填充右边,宽度为4) |
| 1000000 | {:.} | 1,000,000 | 以逗号分隔的数字格式 |
|
0.25 |
{:.2%} {:.0%} {:.3%} |
25.00% 25% 25.000% |
百分比格式 |
| 1000000000 |
{:.2e} {:.0e} |
1.00e+09 1e+09 |
指数记法 |
| 13 |
{:>10d} {:<10d} {:^10d} |
13 13 13 |
右对齐(默认,宽度为10) 左对齐(宽度为10) 中间对齐(宽度为10) |
| 11 |
'{:b}'.format(11) '{:d}'.format(11) '{:o}'.format(11) '{:x}'.format(11) '{:#x}'.format(11) '{:#X}'.format(11) |
1011 11 13 b 0xb 0XB |
进制 |
3、f-Strings
str.format() 比 %格式化高级了一些,但是它还是有自己的缺陷。当需要传入的字符串过多时,仍然会显得非常冗长。与在Python 3.6中引入 了f-strings,不仅比str.format更简洁,性能上也更胜一筹
f-string是以f或F开头的字符串, 核心在于字符串中符号{}的使用
1> {}中可以是变量名
name = '张三' age = 18 print(f'hello, {name}年纪是{age}') print(F'hello, {name}年纪是{age}')
2>{}中可以是表达式
# 可以在{}中放置任意合法的Python表达式,会在运行时计算 # 比如:数学表达式 print(f'{3*3/2}') # 比如:函数的调用 def foo(n): print('foo say hello') return n print(f'{foo(10)}') # 会调用foo(10),然后打印其返回值 # 比如:调用对象的方法 name = 'AMy' print(f'{name.lower()}')
3>在类中的使用
4>多行f-Strings
# 当格式化字符串过长时,如下列表info name = 'Egon' age = 18 gender = 'male' hobbie1='play' hobbie2='music' hobbie3='read' info = f'名字:{name},年龄:{age},性别:{gender},第一个爱好:{hobbie1},第二个爱好:{hobbie2},第三个爱好:{hobbie3}' print(info) # 我们可以回车分隔到多行,注意每行前都有一个f info_new = [ f'名字:{name}', f'年龄:{age}', f'性别:{gender}', f'第一个爱好:{hobbie1}', f'第二个爱好:{hobbie2}', f'第三个爱好:{hobbie3}', ] print(info_new)

5>引号的嵌套
# 当字符串嵌套发送冲突时,与正常的字符串处理方式是一样的
# 1、外层为单引号,内层嵌套也为单引号,并且想要输入的内容也为单引号,那么外层需要改用双引号
print("my name is 'egon'")
# 2、外层为单引号,内层嵌套也为单引号,并且想要输入的内容也为单引号,需要用到转义
print('my name is \'egon\'')
注意:
1、反斜杠可以用来进行字符转义,但不能用在{}的表达式中
f'{1\2}' # 语法错误
2、注释#号也不能出现在{}的表达式中
f'{x#}' # 语法错误
6>括号的处理
基于3.5我们得知,不能在{}内出现反斜杠\,所以,当我们的输出的结果中需要包含{}时,下面的做法就是错误的
print(f'\{天王盖地虎\}')
类似于输出%号的做法
print('%s%%' % 30) 输出结果:30%
若想输出{},那么需要在原有的基础上再套一层,如下:
print(f'{{天王盖地虎}}') 输出结果:{天王盖地虎} print(f'{{{{天王盖地虎}}}}') 输出结果:{{天王盖地虎}}
4、标准库模板
从Python 2.4起,Python标准库string引入了Template也可以用来格式化字符串,所以说,与前三种方式的一个显著区别就是:Template并属于python语言的核心语法特征,使用方式如下
from string import Template name = 'Amy' age = 18 t = Template('hello $name, $age') print(t.substitute(name=name, age=age))
另外一个不同的地方是这个模板字符串不支持类似str.format那样的进制转换,需要我们自己处理
from string import Template name = 'Amy' t = Template('hello $name, there is $error error') res = t.substitute(name=name, error=hex(12345)) print(res)
使用模板字符串Template的最佳的时机就是当你的程序需要处理由用户提供的输入内容时。模板字符串是最保险的选择,因为可以降低复杂性。
其他一些复杂的字符串格式化技巧的可能会给你的程序带来安全漏洞
五、字符串内建函数
S表示任意一个字符串
| 函数 | 说明 |
| S.lower() | 小写 |
| S.upper() | 大写 |
| S.swapcase() | 大小写互换 |
| S.capitalize() |
首字母大写,其余小写 print('A2wWDs as'.capitalize()) 输出:A2wwds as
|
| S.title() |
每个单词的首字母大写,其他小写 print('A2wWDs as'.title()) 输出:A2wwds As
|
| S.strip() |
去掉头和尾的空格 |
| S.lstrip() |
去掉左边的空格 |
| S.rstrip() | 去掉右边的空格 |
| S.ljust(width,[fillchar]) |
输出width个字符,S左对齐,不足部分用fillchar填充 print('A2wWDs'.ljust(10, '*')) 输出:A2wWDs****
|
| S.rjust(width,[fillchar]) |
输出width个字符,S右对齐,不足部分用fillchar填充 print('A2wWDs'.rjust(10, '*')) 输出:****A2wWDs
|
| S.center(width,[fillchar]) |
输出width个字符,S中间对齐,不足部分用fillchar填充 print('A2wWDs'.center(10, '*')) 输出:**A2wWDs**
|
| S.find(substr,[start,[end]]) |
返回S中出现substr的第一个字母的标号,如果S中没有substr则返回-1。start和end作用就相当于在S[start:end]中搜索 print('A2waWDs'.find('waa')) 输出:-1
print('A2waaWDs'.find('waa')) 输出:2
|
| S.rfind(substr,[start,[end]]) |
返回S中最后出现的substr的第一个字母的标号,如果S中没有substr则返回-1,也就是说从右边算起的第一次出现的substr的首字母标号 print('Awaa2waaWDs'.rfind('waa')) 输出:5
print('Awaa2waaWDs'.rfind('wa', 3, 5)) 输出:-1
|
|
S.count(substr,[start,[end]]) |
# 计算substr在S中出现的次数 print('Awaa2waaWDs'.count('wa')) 输出:2
print('Awaa2waaWDs'.count('wa', 3, 6)) 输出:0
|
|
S.replace(oldstr,newstr,[count]) |
#把S中的oldstr替换成newstr,count为替换次数 print('Awaa2waaWDs'.replace('wa', 'p')) 输出:Apa2paWDs
print('Awaa2waaWDs'.replace('wa', 'p', 1)) 输出:Apa2waaWDs
|
|
.join() |
#用特定字符连接单个字符 print('-'.join(['a', 'b', 'c'])) 输出:a-b-c
|
|
split() |
#用字符串中的特定符分割字符串 print('Awa2waaWDs'.split('a')) 输出:['Aw', '2w', '', 'WDs']
print('a-b-c'.split('-')) 输出:['a', 'b', 'c']
print('a b-c'.split()) 输出:['a', 'b-c'] 默认按空格分隔
|
六、总结
1、如果格式化的字符串是由用户输入的,那么基于安全性考虑,推荐使用Template
2、如果使用的python3.6+版本的解释器,推荐使用f-Strings
3、如果要兼容python2.x版本的python解释器,推荐使用str.format
4、如果不是测试的代码,不推荐使用%
七、实际运用
1、python连接mysql数据库,执行sql语句时
备注:要拼接成数据库sql需要的语句,该加括号加括号,该加引号加引号
Ids = [1000226065, 1005589672] now_time = '2022-04-01 16:27:18' details_sql = "SELECT * FROM * WHERE user_id IN (%s) and modify_time= '%s'" % (",".join([str(x) for x in Ids]), now_time) details_sql = f'SELECT * FROM * WHERE user_id IN ({",".join([str(x) for x in Ids])}) and modify_time = "{now_time}"'
details_sql = f'SELECT * FROM * WHERE user_id IN {tuple(Ids)} and moddate = "{now_time}"'
details_sql = "SELECT * FROM * WHERE user_id IN ({}) and modify_time = '{}'".format(",".join([str(x) for x in Ids]), now_time)
details_sql = "SELECT * FROM * WHERE user_id IN {} and modify_time = '{}'".format(tuple(Ids), now_time)
————————————————————————————————
参考博客:https://www.cnblogs.com/yunlong-study/p/14444257.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号