
问题发现
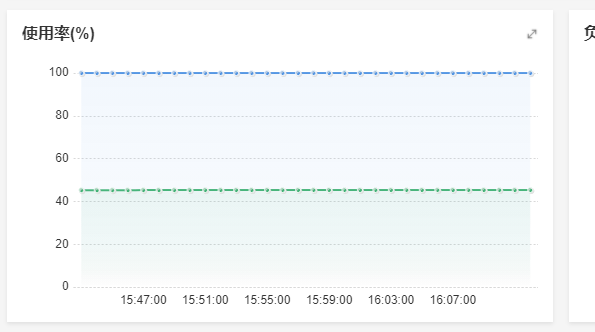
先上图,从容器监控里面看到cpu已经长期保持100%运行。(蓝色线条cpu,绿色的是内存)
排查过程
通过堡垒机连上服务器查jstack
1、由于这台容器里面就一个java服务,而且已经确定是这个服务的问题,因此直接jps查询对应pid(如果无法确定应用范围需要用top命令排序查看最耗费cpu资源的进程pid)

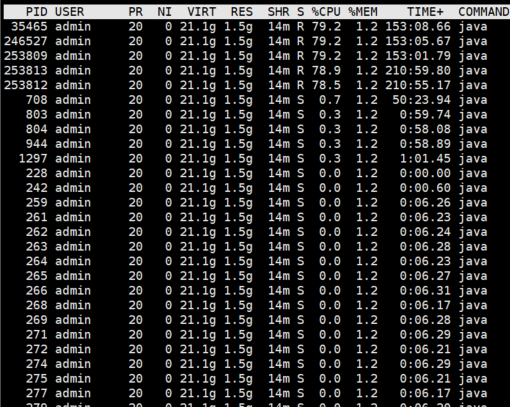
2、使用top -H -p 228命令查看该应用进程下占用cpu资源最高的线程,结果如下图。其中%CPU越高的表示耗费cpu资源越高,TIME列表示cpu持续执行时间(可以看到这几个好非资源大的线程都执行了150分钟,210分钟以上,明显是有问题的)
3、先使用jstack 命令把这个占用最高cpu的进程堆栈信息输出到文件“localadmin.txt”中,方便后续查看。
jstack 228 >> localadmin.txt
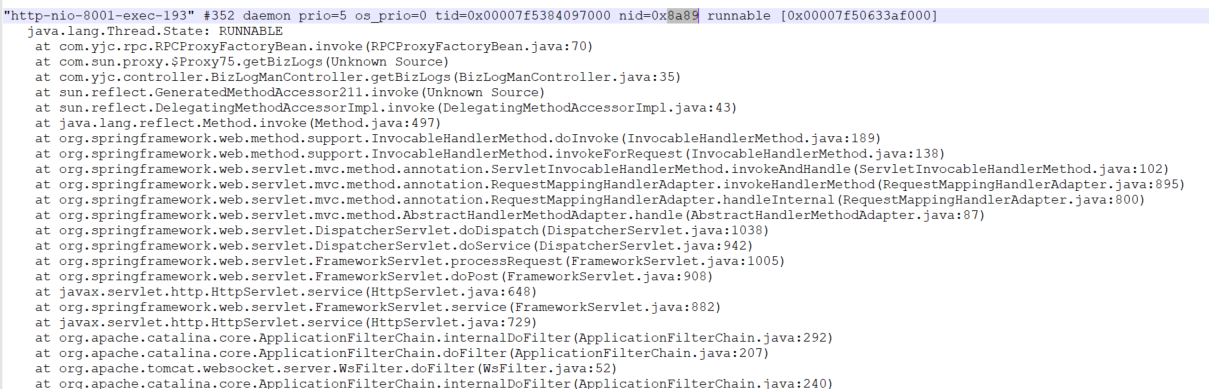
4、通过线程pid查找具体堆栈信息。从第2步可以看到,占用cpu资源最高的几个线程是 35465、246527、253809等……这里需要注意的是jstack文件中是按照16进制标示堆栈信息的,因此这里需要先把35465等信息转换为16进制,即0x8A89,然后在上面导出的localadmin.txt文件中找到对应的堆栈信息。可以看到范围锁定在RPCProxyFactoryBeanRPCProxyFactoryBean的invoke方法,这个方法在我项目中是执行动态代理远程调用客户端方法并接受信息的。
在接受消息处理时采用的方式是如下代码,这个result在正常场景下没有问题,但是在tcp超时,或者业务超时后会一直处于循环中。问题找到,解决方法有两种一种是通过GenericFutureListener接口异步执行操作结束后的回调,一种是我当前的解决方法,接受消息继续用 f.channel().closeFuture().sync(); ,在后续分发器finally中监听ChannelFutureListener.CLOSE
do { // 接收返回信息 result = ClientChannelUtil.getResult(uuid); LOGGER.debug("接受返回消息,uuid:【{}】,result:【{}】",uuid,result); } while (result == null);
修复后重新上线,观察,问题解决。

