20212223 《Python程序设计》实验四 Python综合实践实验报告
20212223 《Python程序设计》实验四 Python综合实践实验报告
课程: 《Python程序设计》
班级: 2122
姓名: 刘仁昊龙
学号: 20212223
实验教师: 王志强
实验日期: 2022年5月29日
必修/选修:
公选课
实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
注:在华为ECS服务器(OpenOuler系统)和物理机(Windows/Linux系统)上使用VIM、PDB、IDLE、Pycharm等工具编程实现
目录
一、实验程序... 4
(一)、实验项目内容... 4
(二)、实验项目实现过程... 4
1.在自己本地下载pycharm编译器。... 4
2.创建虚拟云服务器... 5
3.购买弹性云... 6
4.编写代码文件... 6
5.本地试运行代码文件... 7
6.手动上传文件至ecs(winscp)... 7
7.登录putty进行实验... 8
(三)代码分析过程... 8
1.确定网址... 8
2:反爬机制... 8
3:正则式匹配... 8
4:将爬取数据写入表格并保存... 10
源代码如下:... 10
二、 实验过程中遇到的问题和解决过程... 12
问题1:python爬虫时 AttributeError: 'NoneType' object has no attribute 'children'错误提示... 12
解决办法:soup.find()这个函数返回的对象没有children这个属性,发现打错字... 12
问题2:Python html中一级元素.next_sibling. 12
解决办法:放弃,选择手打换行正则表达式... 12
问题3:不知道如何使用正则表达式,写不出来... 12
解决办法:https://www.sojson.com/regex/generate(正则表达式生成网站)... 13
https://i.hate.rex.org. 13
问题4:Traceback (most recent call last):异常... 13
解决办法:.磁盘空间满了。清内存。... 13
问题5:Python报错ValueError: arrays must all be same length. 13
解决办法:df = pd.DataFrame.from_dict(d, orient=‘index’) 13
print(df) 13
最终产生结果:... 13
行数为key值,列数为最长的values的长度,而其他较短的values则用None填充。... 13
(还是不太懂pandas)... 13
问题6:AttributeError: ‘NoneType‘ object has no attribute ‘group (正则表达式) 14
解决办法:将上述代码块中的match改成search()就可以避开这类问题了。search函数是先扫描全部的代码块,再进行提取的。... 14
问题7:Python导出csv中文乱码utf_8_sig没用... 14
解决办法:gbk。。。。... 14
下列是云服务器出现的问题... 14
问题8:Python出现"SyntaxError: Non-ASCII character '\xe6' in file"错误解决方法... 14
解决办法:第一行加上# encoding: utf-8. 14
问题9:无pandas库... 14
解决办法:手动下载 pip install pandas. 14
问题10:云服务器的python2.7不支持pandas库... 15
解决办法:尝试下载python3.6.2在云服务器上... 15
1. 在云服务器中直接下载... 15
2.安装Python-3.6.2. 15
3.安装其它依赖库... 15
4.解压Python-3.6.2.tgz. 15
5.添加配置,用于保存Python3程序... 15
6.编译与安装... 15
7.建立软连接... 16
问题11:无法使用pip3. 16
解决办法:https://blog.csdn.net/ZCShouCSDN/article/details/85002647. 16
问题12:发现甚至没有pip3文件... 16
解决办法:重装python3.6.2. 16
问题13:zipimport.ZipImportError: can't decompress data; zlib not available. 16
解决办法:yum -y install zlib*. 16
问题14:-bash: /usr/bin/yum: /usr/bin/python3: bad interpreter: No such file or directory. 16
解决办法:yum无法使用了,重装云服务器系统为ubuntu. 17
问题15:/usr/bin/yum: /usr/bin/python: bad interpreter: No such file or directory. 17
解决办法:找到python路径建立软连接... 17
问题16:使用yum报错:There are no enabled repos. Run “yum repolist all“ to see the repos you have. 17
解决办法:直接用apt-get就行了,别用yum。... 17
问题17:sudo apt-get install的作用... 17
解决办法:下载安装... 17
问题18:ubantu下安装zlib. 17
解决办法:zlib的官网打不开,apt-get insatll zlib也找不到软件包,貌似不在软件源里?解决方法是打开ubuntu software center,搜索zlib,找到zlib1g-dev这个包,安装成功。... 18
问题19:下载pandas库无代码... 18
解决办法:... 18
问题20:window无录屏软件... 18
解决办法:qq截图选择录屏... 18
三. 课程小结及实验感想... 18
1.实验感想... 18
(1).csdn永远滴神!!!!!自己自学基本都在csdn上... 18
(2).爬虫框架其实简单的挺好写的,但是其中的正则表达式,存放文件,反爬机制,文件格式不简单... 18
(3).云服务器Linux命令还是不太熟练,只能基本操控。... 18
(4).云服务器安装软件是一大折磨,运行也是。感谢pycharm。。。(没有专业版的悲哀)... 18
2.课程小结... 18
人生苦短,我用python!!... 19
一、实验程序
(一)、实验项目内容
运用python的网页爬虫爬取2000-2020的全球GDP排名,并分别放置在csv表格文件中。
(二)、实验项目实现过程
1.在自己本地下载pycharm编译器。
2.创建虚拟云服务器
3.购买弹性云
4.编写代码文件
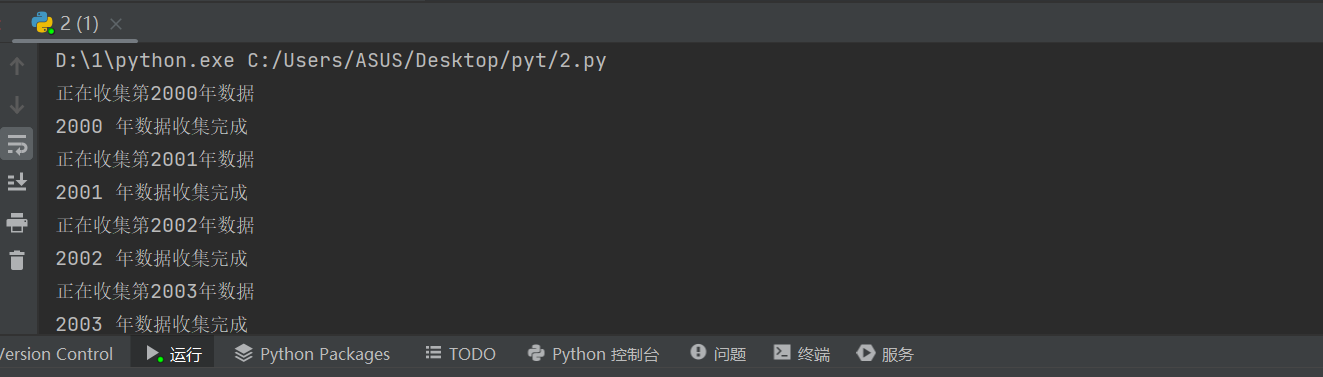
5.本地试运行代码文件
6.手动上传文件至ecs(winscp)
7.登录putty进行实验
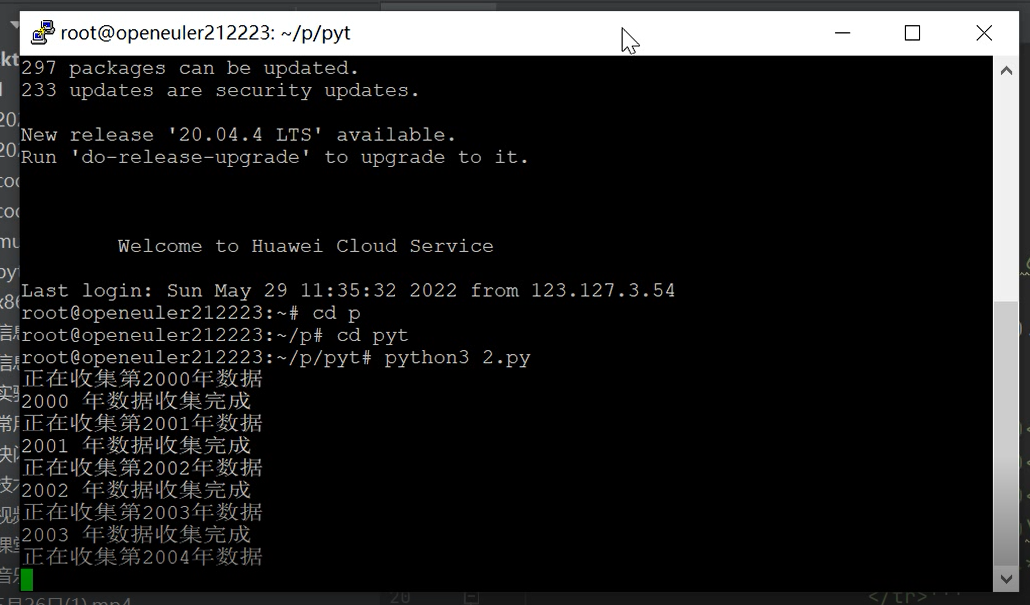
(三)代码分析过程
1.确定网址
数据爬取的是世界各国GDP数据,解析网页信息并解码。
2:反爬机制
有些网站需要定义反爬机制。
有关User-Agent的知识可参考Python爬虫:将User-Agent添加进网页请求头。
3:正则式匹配
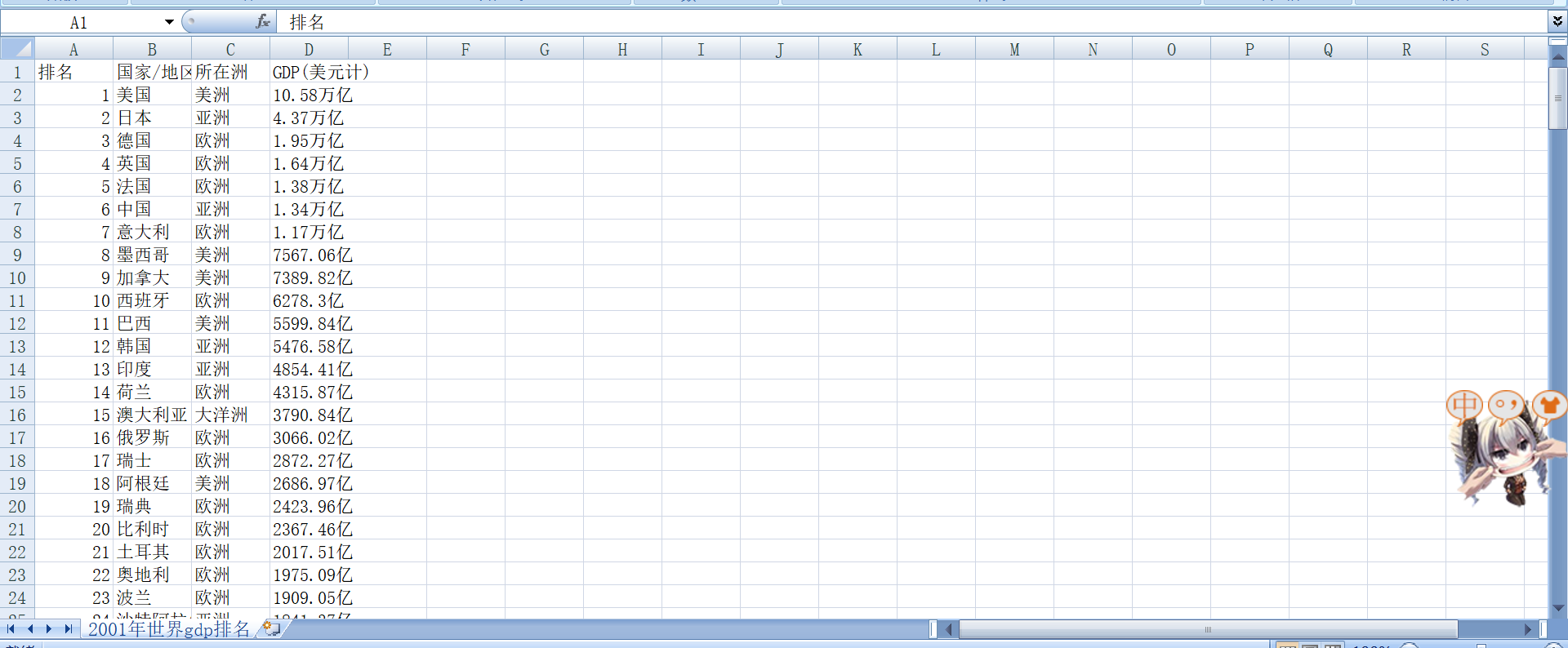
打开源数据网页,查看源代码,确定爬取数据的位置。见下图:
则爬取的位置是:
<tr>
<td>2</td>
<td>中国</td>
<td>亚洲</td>
<td>2019</td>
<td>14.34万亿 (14,342,903,006,431)</td>
<td>16.3362%</td>
确定正则匹配式:
4:将爬取数据写入表格并保存
首先导入pandas库。
import pandas as pd
然后写入表格并保存
源代码如下:
#encoding:utf-8
import urllib.request
# urllib.request 模块提供了最基本的构造 HTTP 请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还带有处理 authenticaton (授权验证), redirections (重定向), cookies (浏览器Cookies)以及其它内容。
import re
#正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本
import pandas as pd
# Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了高级数据结构和数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一
#!!!!!!!!!!!!!!!!!!!pandas要python3才可下载,我们云服务器上的自带的python2.7无法安装
import time
# time库是Python中处理时间的标准库,提供获取系统时间并格式化输出的功能,提供系统级精确计时功能,用于程序性能分析。
def getdata(url):
req = urllib.request.Request(url)
#取网页源代码
req.add_header('User-Agent',
' Mozilla/5.0 (Windows NT 6.3; Win64;
x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36')
#模拟主机发送请求(反爬机制)
data =
urllib.request.urlopen(req).read().decode('utf-8')
#取数据,控制格式为utf-8
str1 = str(data)
#转码(str)
pat = '''<tr>
<td>(.*?)</td>
<td>(.*?)</td>
<td>(.*?)</td>
<td>(.*?)\(.*?</td>
<td>.*?</td>
</tr>'''
#正则表达式提取结果,爬虫精髓
result = re.compile(pat).findall(str1)
#以pat为筛,在str1中提取结果
return result
#函数返回结果
#主函数
if __name__ == '__main__':
for i in range(2000, 2021):
#循环遍历要爬取的网页
print('正在收集第%d年数据' % i)
rank = []
country = []
zhou = []
total = []
#建立数组存储收集到的数据
#https://www.kylc.com/stats/global/yearly_overview/g_area_surface.html
#https://www.kuaiyilicai.com/stats/global/yearly/g_gdp/
url = 'https://www.kuaiyilicai.com/stats/global/yearly/g_gdp/' + str(i) + '.html'
#要爬取的网页(str(i)控制具体是哪个)
data = getdata(url)
#取数据
for j in range(0, len(data)):
rank.append(data[j][0])
country.append(data[j][1])
zhou.append(data[j][2])
total.append(data[j][3])
#遍历数组,并存放数据
dataframe = pd.DataFrame({'排名': rank, '国家/地区': country, '所在洲': zhou, 'GDP(美元计)': total})
#制表
dataframe.to_csv(str(i) + "年世界gdp排名.csv", index=False, sep=',', encoding="gbk", mode="w")
表中存放爬取到的数据
print(i, '年数据收集完成')
time.sleep(0.1)#以一定间隔爬取,防止被ban
二、 实验过程中遇到的问题和解决过程
问题1:python爬虫时 AttributeError: 'NoneType' object has no attribute 'children'错误提示
解决办法:soup.find()这个函数返回的对象没有children这个属性,发现打错字
问题2:Python html中一级元素.next_sibling
解决办法:放弃,选择手打换行正则表达式
问题3:不知道如何使用正则表达式,写不出来
解决办法:https://www.sojson.com/regex/generate(正则表达式生成网站)
https://i.hate.rex.org
问题4:Traceback (most recent call last):异常
解决办法:.磁盘空间满了。清内存。
问题5:Python报错ValueError: arrays must all be same length
解决办法:df = pd.DataFrame.from_dict(d, orient=‘index’)
print(df)
最终产生结果:
行数为key值,列数为最长的values的长度,而其他较短的values则用None填充。
(还是不太懂pandas)
问题6:AttributeError: ‘NoneType‘ object has no attribute ‘group (正则表达式)
解决办法:将上述代码块中的match改成search()就可以避开这类问题了。search函数是先扫描全部的代码块,再进行提取的。
问题7:Python导出csv中文乱码utf_8_sig没用
解决办法:gbk。。。。
下列是云服务器出现的问题
问题8:Python出现"SyntaxError: Non-ASCII character '\xe6' in file"错误解决方法
解决办法:第一行加上# encoding: utf-8
问题9:无pandas库
解决办法:手动下载 pip install pandas
问题10:云服务器的python2.7不支持pandas库
解决办法:尝试下载python3.6.2在云服务器上
下载Python-3.6.2
登入华为鲲鹏云服务器
1. 在云服务器中直接下载
wget https://www.python.org/ftp/python/3.6.2/Python-3.6.2.tgz
2.安装Python-3.6.2
检查系统环境中是否有gcc
gcc --version
如果没有gcc,则先安装gcc
yum -y install gcc
3.安装其它依赖库
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel libffi-devel
依赖库一定不要少,否则会导致Python安装错误。
4.解压Python-3.6.2.tgz
tar -zxvf Python-3.6.2.tgz
解压完毕后,进入目录
cd Python-3.6.2/
5.添加配置,用于保存Python3程序
./configure --prefix=/usr/python3
6.编译与安装
make && make install
安装后只要没有提示错误,就代表安装成功了
7.建立软连接
ln -s /usr/python3/bin/python3.6 /usr/bin/python3
ln -s /usr/python3/bin/pip3.6 /usr/bin/pip3
问题11:无法使用pip3
解决办法:https://blog.csdn.net/ZCShouCSDN/article/details/85002647
问题12:发现甚至没有pip3文件
解决办法:重装python3.6.2
问题13:zipimport.ZipImportError: can't decompress data; zlib not available
解决办法:yum -y install zlib*
问题14:-bash: /usr/bin/yum: /usr/bin/python3: bad interpreter: No such file or directory
解决办法:yum无法使用了,重装云服务器系统为ubuntu
问题15:/usr/bin/yum: /usr/bin/python: bad interpreter: No such file or directory
解决办法:找到python路径建立软连接
whereis python
只要找到python命令的路径,然后建立个软链接即可。
sudo ln -s /usr/bin/python2.4 /usr/bin/python
问题16:使用yum报错:There are no enabled repos. Run “yum repolist all“ to see the repos you have.
解决办法:直接用apt-get就行了,别用yum。
问题17:sudo apt-get install的作用
解决办法:下载安装
问题18:ubantu下安装zlib
解决办法:zlib的官网打不开,apt-get insatll zlib也找不到软件包,貌似不在软件源里?解决方法是打开ubuntu software center,搜索zlib,找到zlib1g-dev这个包,安装成功。
问题19:下载pandas库无代码
解决办法:
问题20:window无录屏软件
解决办法:qq截图选择录屏
三. 课程小结及实验感想
1.实验感想
(1).csdn永远滴神!!!!!自己自学基本都在csdn上
(2).爬虫框架其实简单的挺好写的,但是其中的正则表达式,存放文件,反爬机制,文件格式不简单
(3).云服务器Linux命令还是不太熟练,只能基本操控。
(4).云服务器安装软件是一大折磨,运行也是。感谢pycharm。。。(没有专业版的悲哀)
2.课程小结
对于一个初次学习如何编写程序的小白来说同时学习六门语言其实是一个十分艰难的事情(python,c,c++,java,MATLAB,Lingo)。但我依旧觉得我可以迎难而上.jpg…
刚开始上课的时候,其实我还是某些方面上有一点轻视,因为我之前有一部分的C加加语言基础,觉得python语言和C加加有部分是相通的,可以让我学习变得简单一些。但是在实际的学习过程中,我却发现了我之前的基础,而反而成了阻碍我写代码的障碍,同一个实现有不同的格式,甚至有不同的叫法,在初期让我十分痛苦。不过感谢老师为我带来的在课堂上的悉心指导,在课堂上能一步一步的跟着老师的思维走,让我在写简单程序上不会出什么大的问题。
但是这种略带轻视的态度完全在正则表达式的一刻及后面消失了。正则表达式是第一个,我看得懂,但是写不来的东西。自己手打正则表达式的时候是真的是一种痛苦与折磨。而且当时我对字符串的理解还不深,不知道我们要学到爬虫,所以在当时也找不到应用的方向,让我自己感觉学习这个不太有意义。
然后紧接着的socket,编写客户端与服务端,实现两边的协同操作及加密,实现的语言难度上的一个大的跨越。我从考之前的知识吃老本变成了在csdn上虚心学习,从而才能勉强跟上进度。的确,提升难度是一种激励自学的好方法,但是也给当时的我带来了些许反差的落差感。
然后到了基本是最后的模块,爬虫,编写爬虫的简易程度基本完全取决于你要爬什么网页,在初期,我只能爬央视网的一些简单的h3标签资料,经过了这次大作业的实验的学习和思考,我勉强能实现运用正则表达式爬取网页,并将其存放在Csv表格文件中,并且能实现从爬取单个网页到爬取多个网页,还学会了伪装客户端进行访问,从而避免网页自带的反爬机制。
这次大作业给了我很深的体验,让我自己对python的学习变得更加深入。而且还用了有了一些实际上的以后能使用的技能:爬虫,给了我日常生活带来的很多的帮助。这门课让我有了继续学习python的想法。
人生苦短,我用python!!
#encoding:utf-8
import urllib.request
# urllib.request 模块提供了最基本的构造 HTTP 请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还带有处理 authenticaton (授权验证), redirections (重定向), cookies (浏览器Cookies)以及其它内容。
import re
#正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本
import pandas as pd
# Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了高级数据结构和数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一
#!!!!!!!!!!!!!!!!!!!pandas要python3才可下载,我们云服务器上的自带的python2.7无法安装
import time
#time库是Python中处理时间的标准库,提供获取系统时间并格式化输出的功能,提供系统级精确计时功能,用于程序性能分析。
def getdata(url):
req = urllib.request.Request(url)
#取网页源代码
req.add_header('User-Agent',
' Mozilla/5.0 (Windows NT 6.3; Win64;
x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36')
#模拟主机发送请求(反爬机制)
data =
urllib.request.urlopen(req).read().decode('utf-8')
#取数据,控制格式为utf-8
str1 = str(data)
#转码(str)
pat = '''<tr>
<td>(.*?)</td>
<td>(.*?)</td>
<td>(.*?)</td>
<td>(.*?)\(.*?</td>
<td>.*?</td>
</tr>'''
#正则表达式提取结果,爬虫精髓
result = re.compile(pat).findall(str1)
#以pat为筛,在str1中提取结果
return result
#函数返回结果
#主函数
if __name__ == '__main__':
for i in range(2000, 2021):
#循环遍历要爬取的网页
print('正在收集第%d年数据' % i)
rank = []
country = []
zhou = []
total = []
#建立数组存储收集到的数据
#https://www.kylc.com/stats/global/yearly_overview/g_area_surface.html
#https://www.kuaiyilicai.com/stats/global/yearly/g_gdp/
url = 'https://www.kuaiyilicai.com/stats/global/yearly/g_gdp/' + str(i) + '.html'
#要爬取的网页(str(i)控制具体是哪个)
data = getdata(url)
#取数据
for j in range(0, len(data)):
rank.append(data[j][0])
country.append(data[j][1])
zhou.append(data[j][2])
total.append(data[j][3])
#遍历数组,并存放数据
dataframe = pd.DataFrame({'排名': rank, '国家/地区': country, '所在洲': zhou, 'GDP(美元计)': total})
#制表
dataframe.to_csv(str(i) + "年世界gdp排名.csv", index=False, sep=',', encoding="gbk", mode="w")
表中存放爬取到的数据
print(i, '年数据收集完成')
time.sleep(0.1)#以一定间隔爬取,防止被ban

 浙公网安备 33010602011771号
浙公网安备 33010602011771号