
数据库范式
范式是关系数据库理论的基础,也是我们在设计数据库结构过程中所要遵循的规则和指导方法。目前有迹可寻的共有8种范式,依次是:1NF,2NF,3NF,BCNF,4NF,5NF,DKNF,6NF。通常所用到的只是前三个范式,即:第一范式(1NF),第二范式(2NF),第三范式(3NF)。
首先看下一些基本概念
一、基础概念
要理解范式,首先必须对知道什么是关系数据库,如果你不知道,我可以简单的不能再简单的说一下:关系数据库就是用二维表来保存数据。表和表之间可以……(省略10W字)。
然后你应该理解以下概念:
- 实体:现实世界中客观存在并可以被区别的事物。比如“一个学生”、“一本书”、“一门课”等等。值得强调的是这里所说的“事物”不仅仅是看得见摸得着的“东西”,它也可以是虚拟的,不如说“老师与学校的关系”。
- 属性:教科书上解释为:“实体所具有的某一特性”,由此可见,属性一开始是个逻辑概念,比如说,“性别”是“人”的一个属性。在关系数据库中,属性又是个物理概念,属性可以看作是“表的一列”。
- 元组:表中的一行就是一个元组。
- 分量:元组的某个属性值。在一个关系数据库中,它是一个操作原子,即关系数据库在做任何操作的时候,属性是“不可分的”。否则就不是关系数据库了。
- 码:表中可以唯一确定一个元组的某个属性(或者属性组),如果这样的码有不止一个,那么大家都叫候选码,我们从候选码中挑一个出来做老大,它就叫主码。
- 全码:如果一个码包含了所有的属性,这个码就是全码。
- 主属性:一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
- 非主属性:与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
- 外码:一个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
◆ 第一范式(1NF):强调的是列的原子性,即列不能够再分成其他几列。
我想这个应该很好理解,就是一个列中不能重现出现属性。比如电话这个列中,分座机和手机,你不能把他们放在同一个列中。
◆ 第二范式(2NF):首先是 1NF,另外包含两部分内容,一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
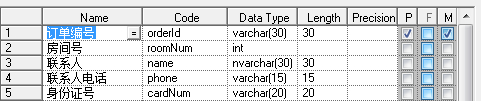
一个人同时订几个房间,就会出来一个订单号多条数据,这样子联系人都是重复的,就会造成数据冗余。我们应该把他拆开来。


◆ 第三范式(3NF):首先是 2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)
这样一个表结构,就存在上述关系。 学号--> 所在院校 --> (院校地址,院校电话)
这样的表结构,我们应该拆开来,如下。
(学号,姓名,年龄,性别,所在院校)--(所在院校,院校地址,院校电话)
第二范式(2NF)和第三范式(3NF)的概念很容易混淆,区分它们的关键点在于,2NF:非主键列是否完全依赖于主键,还是依赖于主键的一部分;3NF:非主键列是直接依赖于主键,还是直接依赖于非主键列。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号