java基础
java基础:
1.list去重:hashset.addall
2.hashset底层用hashmap实现,保证不会重复
3.hashmap的底层实现和concurrenthashmap的底层实现?
a、hashmap:
容量、加载因子、扩容阈值
b、concurrenthashmap
http://www.importnew.com/28263.html
https://crossoverjie.top/2018/07/23/java-senior/ConcurrentHashMap/
http://www.jasongj.com/java/concurrenthashmap/
4.
java并发:
wait和sleep的区别:
1.所属的类不一样wait:Object sleep:Thread
2.调用sleep方法的线程不会释放对象锁,而调用wait() 方法会释放对象锁
synchronized 的实现原理以及锁优化? (悲观锁)
1. 普通同步方法,锁是当前实例对象
2. 静态同步方法,锁是当前类的class对象
3. 同步方法块,锁是括号里面的对象
同步代码块底层是通过monitorenter和monitorExit指令实现,同步方法修饰符上的ACC_SYNCHRONIZED实现。
synchronized 在静态方法和普通方法,代码块。
锁优化:
1.自旋锁:
2.自适应自旋锁
3.锁消除 :不可能存在数据竞争,逃逸分析(不会当做参数传到其它方法等)。StringBuffer的append()方法
4.锁粗化:加锁出现在循环体之内。
5.偏向锁
6.轻量级锁
7.重量级锁:对性能有较大影响,挂起和恢复线程从用户态到内核态。
cas:乐观锁
自旋CAS(也就是不成功就一直循环执行直到成功)如果长时间不成功,会给CPU带来非常大的执行开销。
对象,内存偏移量,预期值和新值。
volatile 的实现原理? (没有原子性)(java内存模型)
happen-before原则:
- 同一个线程中的,前面的操作 happen-before 后续的操作。(即单线程内按代码顺序执行。但是,在不影响在单线程环境执行结果的前提下,编译器和处理器可以进行重排序,这是合法的。换句话说,这一是规则无法保证编译重排和指令重排)。
- 监视器上的解锁操作 happen-before 其后续的加锁操作。(Synchronized 规则)
- 对volatile变量的写操作 happen-before 后续的读操作。(volatile 规则)
- 线程的start() 方法 happen-before 该线程所有的后续操作。(线程启动规则)
- 线程所有的操作 happen-before 其他线程在该线程上调用 join 返回成功后的操作。
- 如果 a happen-before b,b happen-before c,则a happen-before c(传递性)。
在单线程环境下我们可以认为整个步骤都是原子性操作,但是在多线程环境下则不同,Java只保证了基本数据类型的变量和赋值操作才是原子性的(注:在32位的JDK环境下,对64位数据的读取不是原子性操作*,如long、double)。要想在多线程环境下保证原子性,则可以通过锁、synchronized来确保。
1.可见性(内存模型)
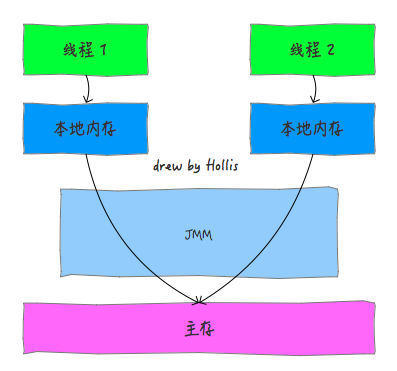
2.指令重排序
观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令。lock前缀指令其实就相当于一个内存屏障。内存屏障是一组处理指令,用来实现对内存操作的顺序限制。volatile的底层就是通过内存屏障来实现的。
3.transient
java 的transient关键字为我们提供了便利,你只需要实现Serilizable接口,将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会序列化到指定的目的地中。
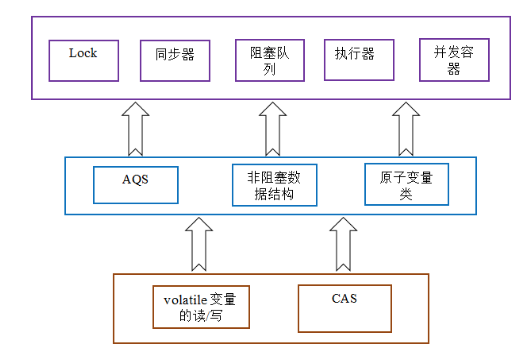
AQS:
ReentrantLock:排他锁
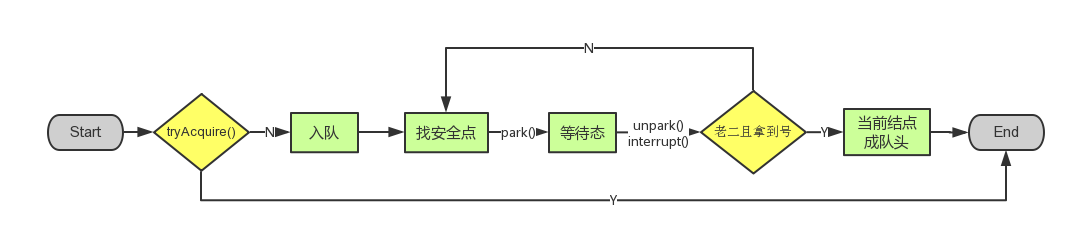
public final void acquire(int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) selfInterrupt(); }
tryAcquire():
- tryAcquire()尝试直接去获取资源,如果成功则直接返回;获取state,判断是否为0,cas修改state,当前线程的独占线程。不为0,看是否是现在的线程,是就state+1.
- addWaiter()将该线程加入等待队列的尾部,并标记为独占模式;Node结点是对每一个访问同步代码的线程的封装,其包含了需要同步的线程本身以及线程的状态
a.先尝试快速放到队尾 b.不成功则放入队列,CAS"自旋",直到成功加入队尾
3.acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
- 结点进入队尾后,检查状态,找到安全休息点;
- 调用park()进入waiting状态,等待unpark()或interrupt()唤醒自己;
- 被唤醒后,看自己是不是有资格能拿到号。如果拿到,head指向当前结点,并返回从入队到拿到号的整个过程中是否被中断过;如果没拿到,继续流程1。
CountDownLatch:共享锁
ArrayBlockingQueue,AtomicInteger,ReentrantReadWriteLock,ReentrantLock和Condition,future和callback,fork/join,线程池。
Spring:
1、BeanFactory 和 FactoryBean的区别?
BeanFactory是容器,FactoryBean特殊的bean。
2.bean的加载过程
1.bean的解析:加载资源-封装资源-获取输入流-获取对xml文件的验证模式(DTD or XSD)-加载xml,得到对应的document-根据返回的document注册bean的信息。
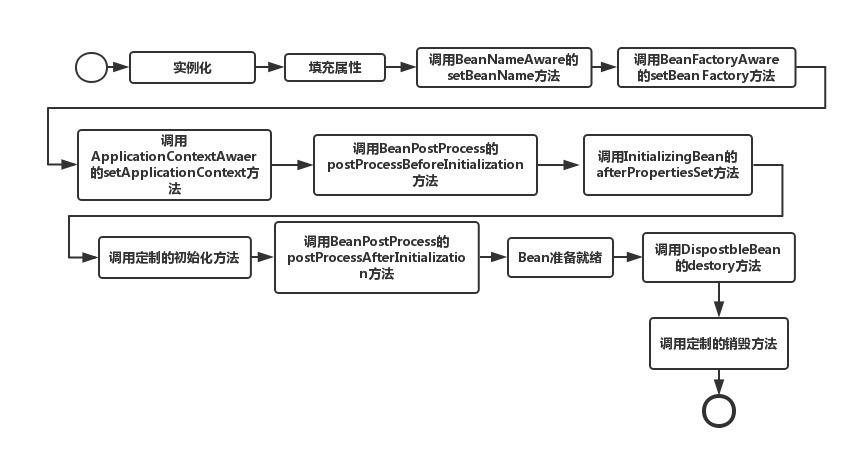
3.Spring 循环注入的原理?
提前暴露ObjectFactory,循环依赖的时候回实例化好。
算法:
两个栈实现一个队列
分布式id:
https://tech.meituan.com/2017/04/21/mt-leaf.html
消息系统:
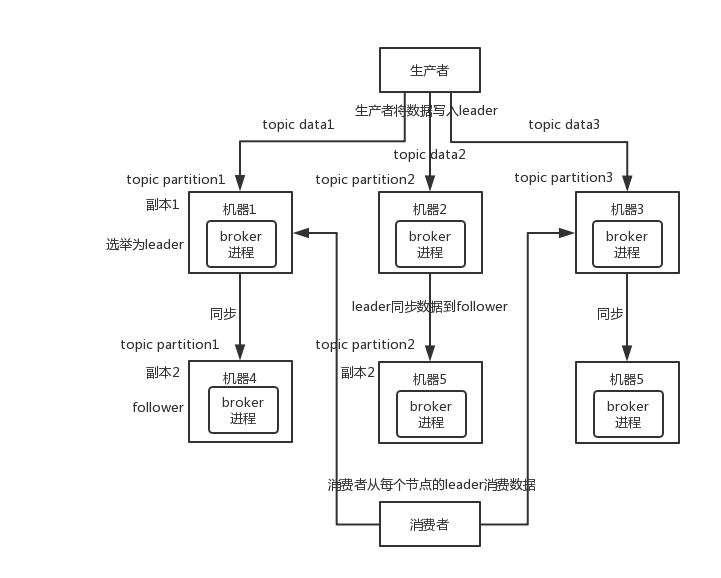
高可用:
kafka:由多个 broker 组成,每个 broker 是一个节点;你创建一个 topic,这个 topic 可以划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 就放一部分数据。HA(High Availability, 高可用性) 的机制:Kafka 0.8 以后,提供了 HA 机制,就是 replica(复制品) 副本机制。每个 partition 的数据都会同步到其它机器上,形成自己的多个 replica 副本。所有 replica 会选举一个 leader 出来,那么生产和消费都跟这个 leader 打交道,然后其他 replica 就是 follower。写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。只能读写 leader?很简单,要是你可以随意读写每个 follower,那么就要 care 数据一致性的问题,系统复杂度太高,很容易出问题。Kafka 会均匀地将一个 partition 的所有 replica 分布在不同的机器上,这样才可以提高容错性。
如何保证消息消费的幂等性:
业务幂等,数据库唯一索引
如何处理消息丢失的问题:
消费端:关闭自动提交 offset,但是此时确实还是可能会有重复消费,自己保证幂等性
mq:
-
- 给 topic 设置
replication.factor参数:这个值必须大于 1,要求每个 partition 必须有至少 2 个副本。 - 在 Kafka 服务端设置
min.insync.replicas参数:这个值必须大于 1,这个是要求一个 leader 至少感知到有至少一个 follower 还跟自己保持联系,没掉队,这样才能确保 leader 挂了还有一个 follower 吧。 - 在 producer 端设置
acks=all:这个是要求每条数据,必须是写入所有 replica 之后,才能认为是写成功了。 - 在 producer 端设置
retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了。
- 给 topic 设置
生产者:ack=all。
设计mq:
高可用,可伸缩,消息确保(持久化)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号