过拟合处理方法
面试的时候被问到过拟合怎么处理,没有好好准备结果这个简单的问题没答上来,我头脑第一个想的是决策树--过拟合--剪枝。笑死,这个回答相当于100分的问题我就会3分,不被白眼才怪,没有系统的认知体系。因此今天要争取整理出一个60+分的答案哈哈
1.什么是过拟合
还没找到很标准的话来定义他,但是用图比较容易看
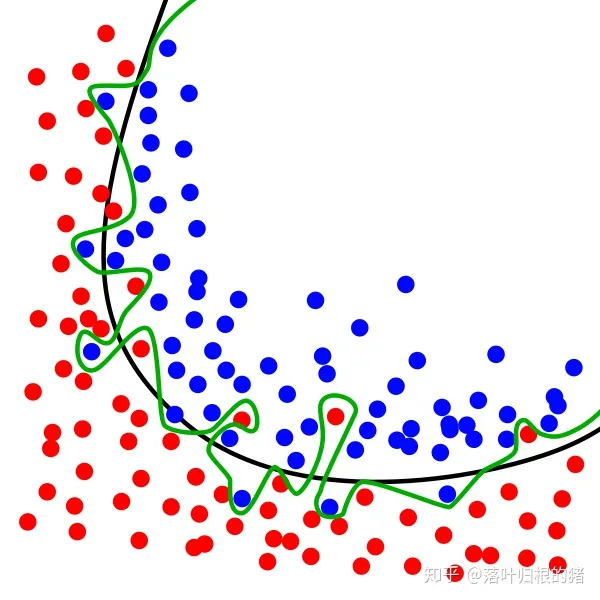
绿线就是过拟合的学习曲线,而黑线是比较理想的曲线。
过拟合过度追求每个样本的y值,对当前数据进行“过度解读”,对模型的泛化有很大的影响。
2.如何解决过拟合
2.1增加训练的数据量,选择合适的准确率和召回率
过拟合的根本原因是对当前样本的“过度解读”,所以最简单的方法就是再训练样本上下下功夫,扩大训练数据集,选择合适的抽样方法。
2.2运用正则化
对特征进行一定的变换,改变样本空间分布。
例如误差的公式套上平方,将样本误差小的不同分类样本间距离拉伸
2.3简化模型
这里就是前面提到的决策树过拟合时候的剪枝了。
另外从图1看,回归分析的高次的多项式曲线也会过度拟合样本,这个时候要降低回归拟合公式的次数
特别的,神经网络有随机切除神经元的方法来降低过拟合现象。
2.4多个欠拟合模型组合
这个思想在cart决策树中有所体现,统筹多个欠拟合的小树的结果来作为最终的预测结果。
常见的有bagging和boosting方法。
碎碎念
当前就简单写这一点,没有好的素材展开。着4个标题扯一扯也够回答这个问题了对吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号