

[python]有中文字符程序异常的解决方案
一. 含有中文字符无法运行
在python3中用的是Unicode编码,Unicode号称万国码,可以向所有的编码进行兼容。不会出现这种问题。
Python2中使用的是ASCII编码,会出现这种问题。解决步骤如下。
- 对代码的编码进行注解
在头部加入
coding=utf-8 或者 #-- coding:utf-8 --
二、无法打印中文字符
- 对文件进行编码解码
python2
Python编码之间Unicode作为中间的过度。所以编码能够进行通用:
-- coding:utf-8 --
s = "中文"
print(s.decode("utf-8").encode("gbk"))
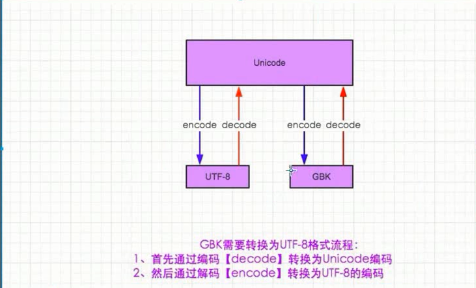
编码解码整个过程,就好像是Unicode是一个翻译官一样:例如jbk和gbk之间的一个过程:
jbk无法直接转换到gbk,所以需要有一个过程, jbk decode生成Unicode utf-8然后在进行encode生成gbk
python3
encode 在编码的同时,会把数据转换成byte类型
import sys
print(sys.getfilesystemencoding())
s = "中文" #py3 默认就是utf8 unicode向下兼容utf-8
s_to_gpk = s.encode("gbk")
print(s_to_gpk.decode("gbk")) #py3是不需要转换的,但是要转的话还要转回去
补充:
'''
-----二进制:(0 and 1)
-------->>ASCII :只能存放英文河拉丁字符。一个字符占一个字节,8位
--------------->>gb2312:只能6700多个中文,1980年
--------------------->>gpk1.0:存了2万多个字符,1995
--------------------------->>gb18030:2000,27000中文(在中国软件发布的时候必须用gb18030)
---------->>unicode: utf-32:一个字符占四个字节
---------->>unicode: utf-16>一个字符占两个字节或两个以上,65535(实在找不到的时候在utf-32里面找)
---------->>unicode: utf-8:一个英文用ASCII码来存,一个中文占3个字节,utf=8表示是根据表示什么来决定大小的。
---------->>GBK GB2312 表示中文得时候用得是两个字节。
'''

