【table master mmocr】Windows下模型训练的配置
 Windows下进行训练的调试过程记录
Windows下进行训练的调试过程记录
processed_data就是mmocr_pubtabnet_recognition,注意统一命名
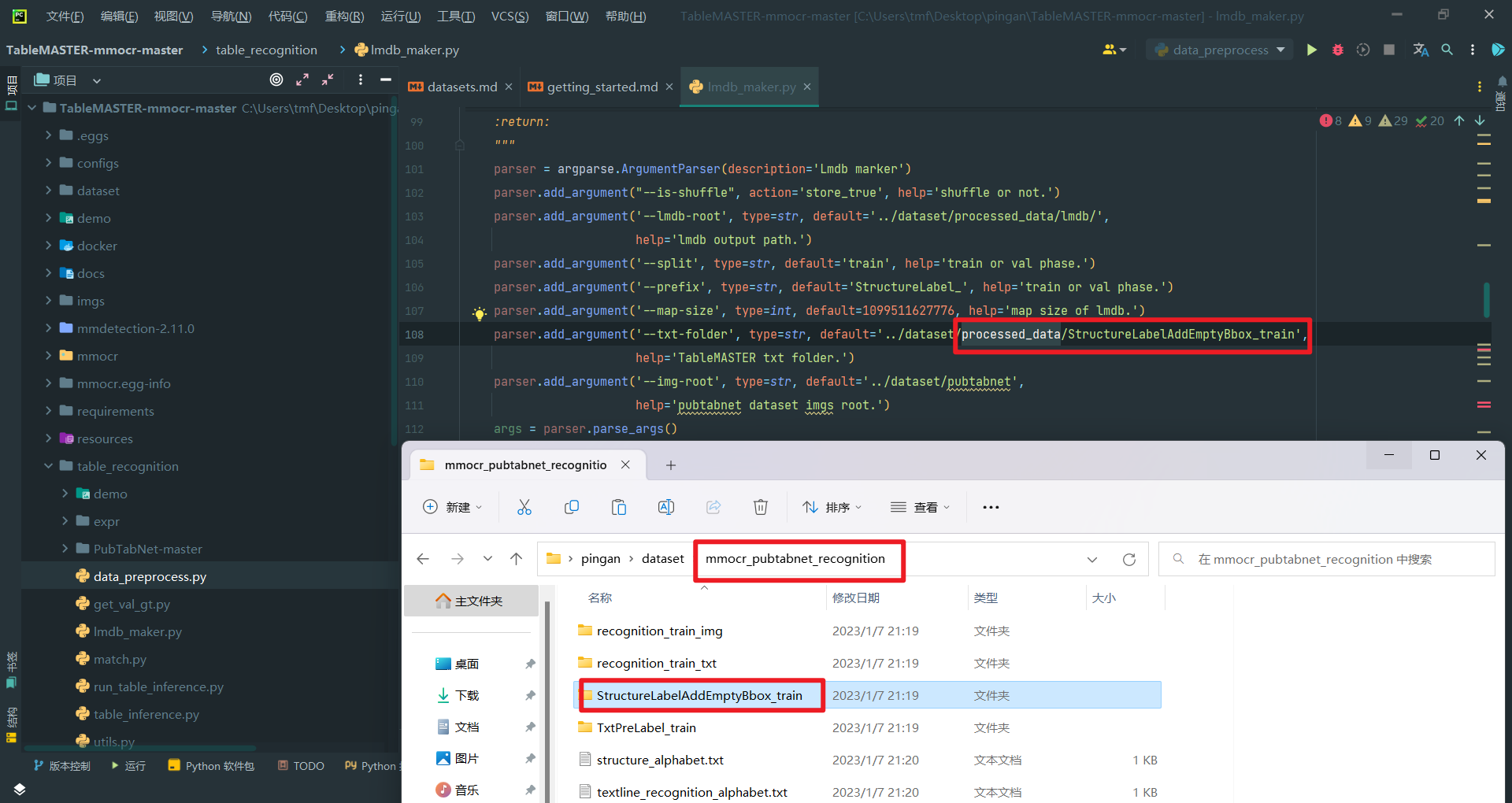
由图可以看出,那个processed_data就是mmocr_pubtabnet_recognition,而且后面后缀_0927之类的都是日期,可能是不同时期训练的,所以对于数据处理目前都是在这同一个目录里,目录结构如下:
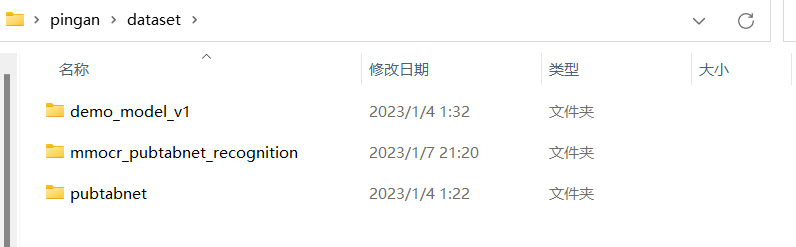
demo_model_v1是预训练模型,用来跑demo预测的
mmocr_pubtabnet_recognition就是目前数据处理的目录,全是这一个
pubtabnet这是下载的原始数据集(其实还有个LICENSE文件,但是只是数据集的LICENSE,不用管)
一、data_preprocess.py的使用
1.数据预处理
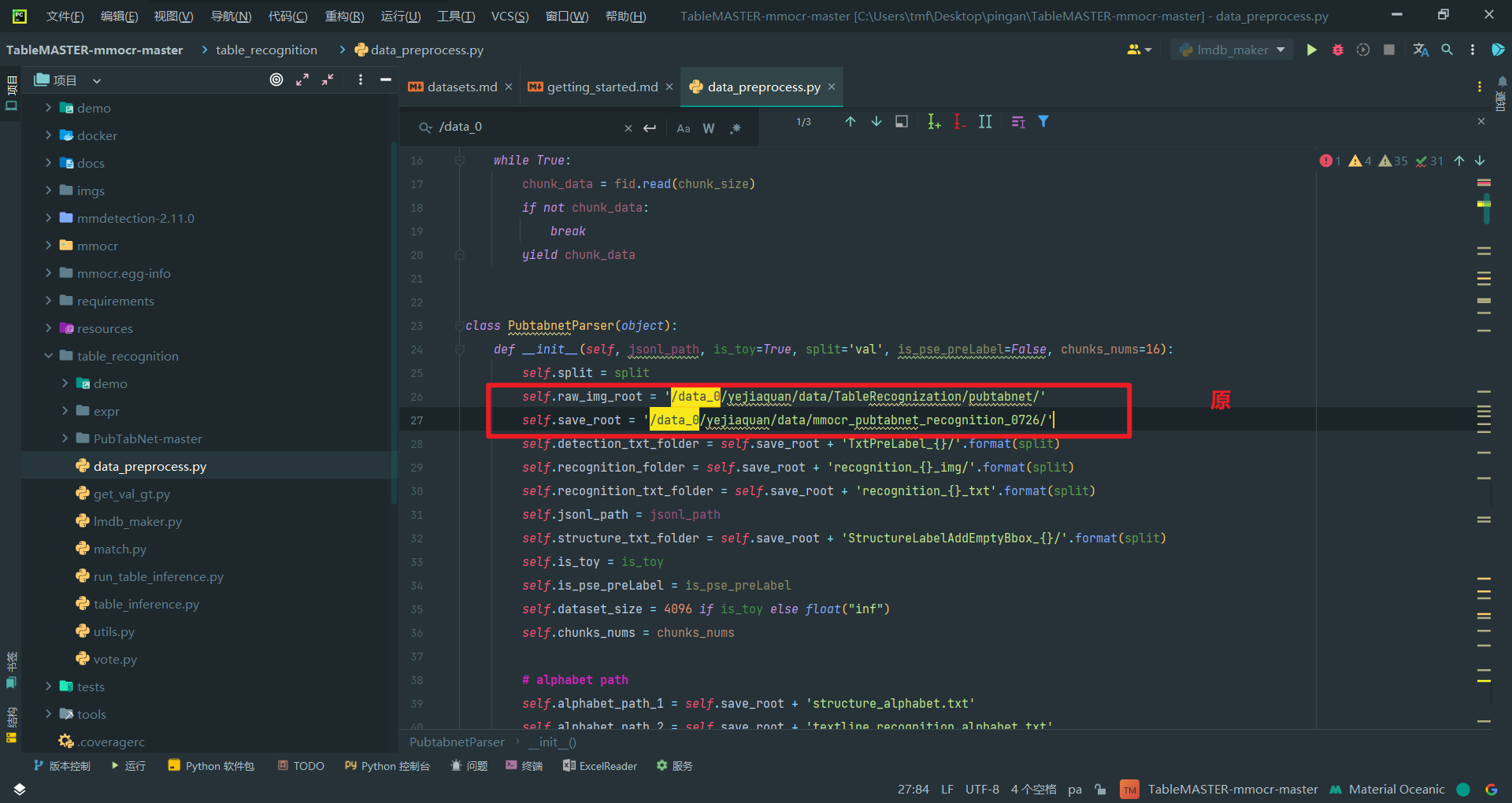
改路径
改后
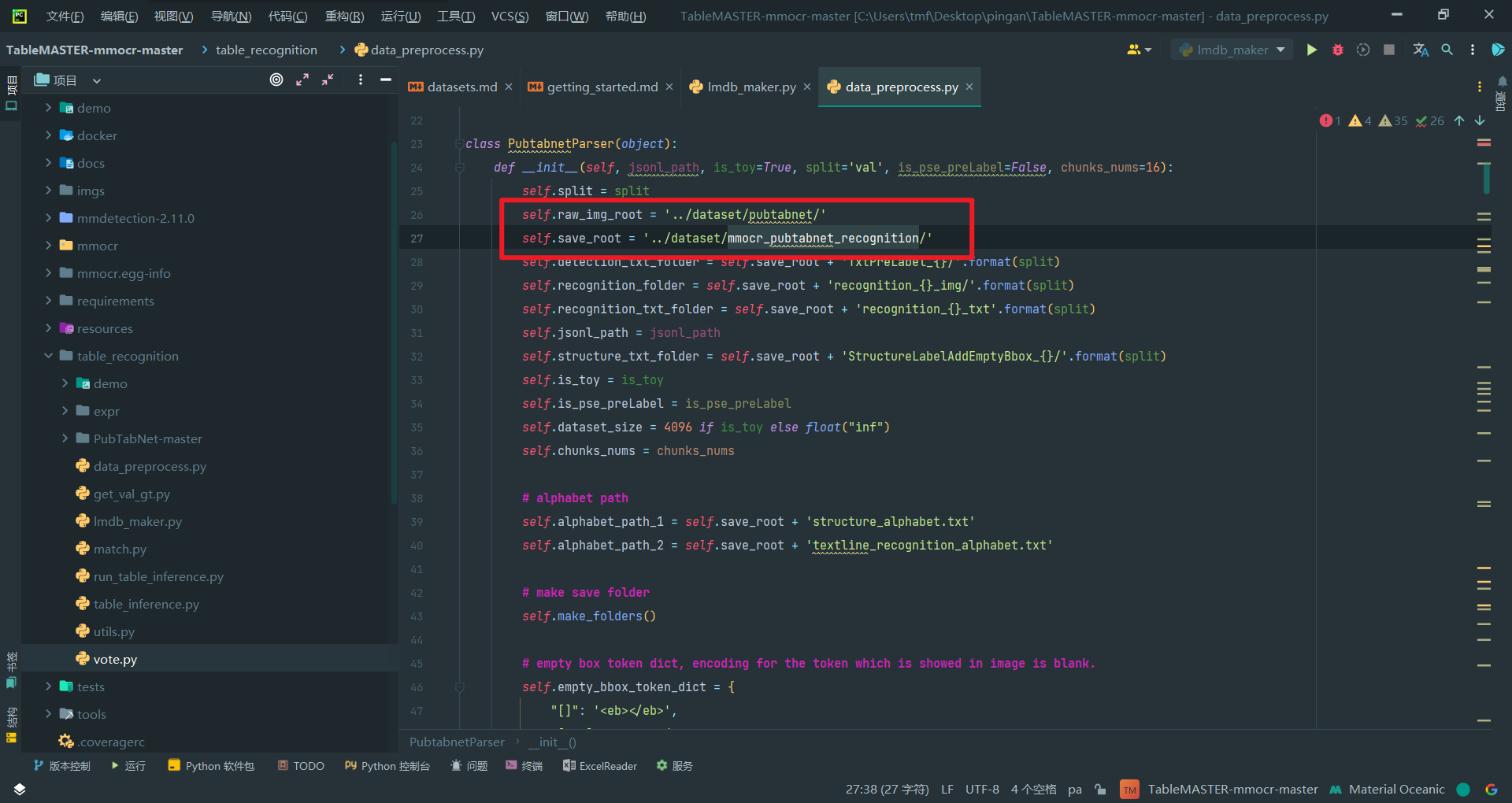
不用手动创建,等会会自己创建的,但在文件中配置时,processed_data位置如下:
dataset
├─demo_model_v1
│ └─outputs
├─processed_data
└─pubtabnet
├─test
├─train
└─val
这里尝试推理mmocr_pubtabnet_recognition这个东西的目录位置和名字这么搞- 它会自己创建目录,在文件的三个位置调好即可
!!!注意!!!
改代码的路径时,末尾一定要有/,不然就会像下面这样.......
#特殊情况:请注意文件路径问题
Windows系统使用\分隔路径,导致拼接路径时出现了很多问题,故为了方便以后统一使用Linux的/分隔,故需做出如下规定:
1.第25行,添加+ '/',即在目录末尾保留分隔符,将使os默认使用它进行分隔,而不是Windows的\
self.split = split + '/'
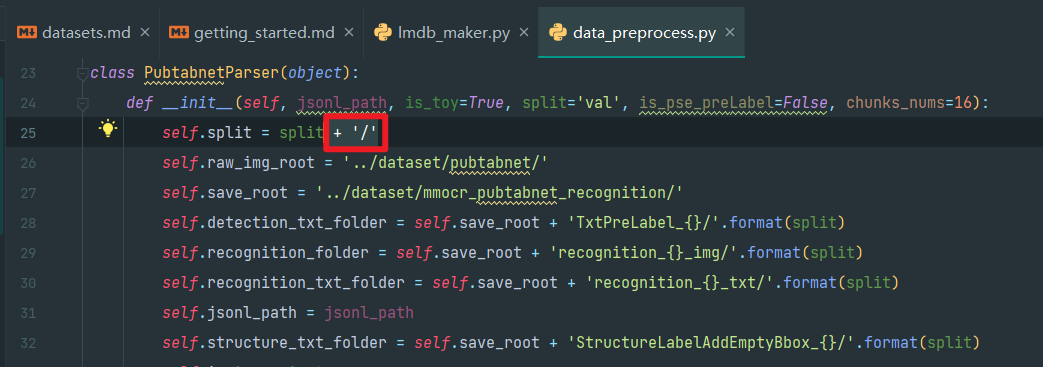
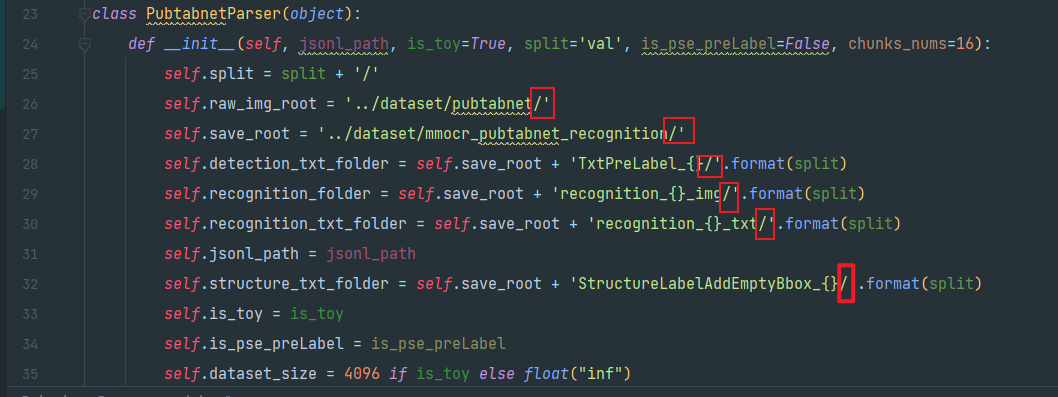
2.第26-32行的路径结尾都要保证有/!
3.第348行添加+ '/',使成为
recognition_folder = os.path.join(self.recognition_folder, str(chunks_idx)+'/')
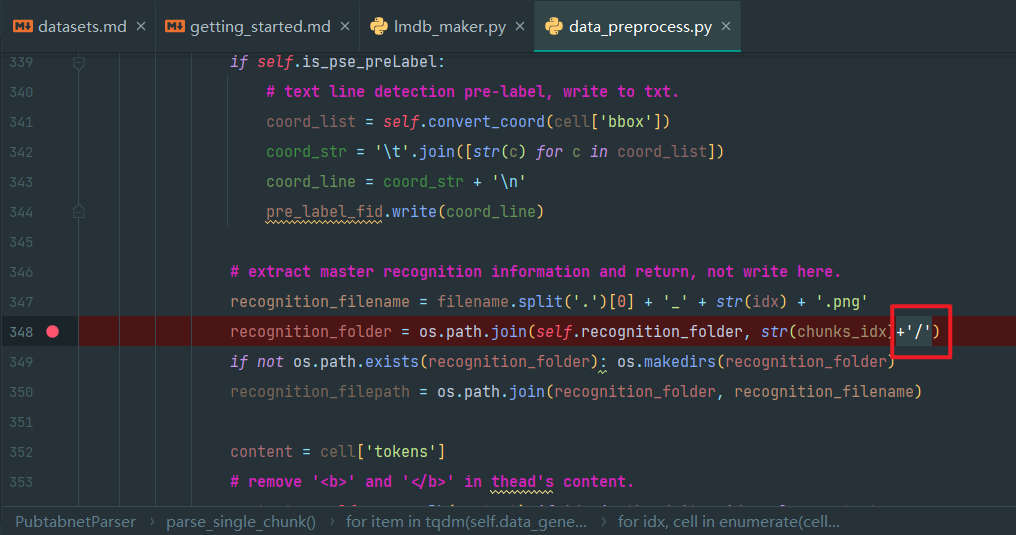
这样才能保证txt里面保存的路径都是/分隔,而且,保存的路径都是相对路径(本来要绝对路径的,但是目前看无所谓)
2.debug先把is_toy设为True
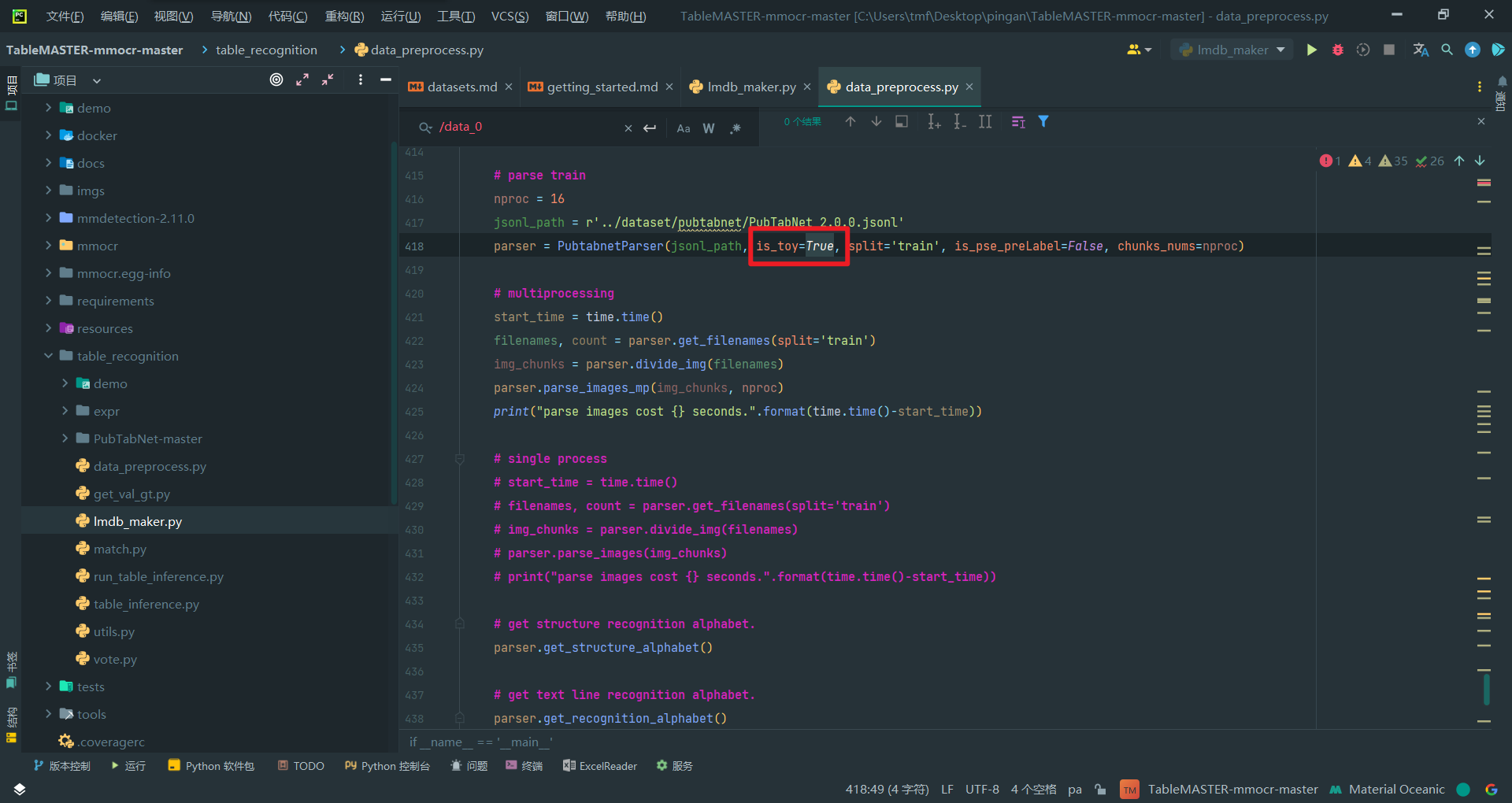
3.运行试试
报错没有json_lines模块,
pip install json_lines
安装再运行
又路径报错,是工作目录问题,调到TableMASTER-mmocr-master,再运行

运行OK
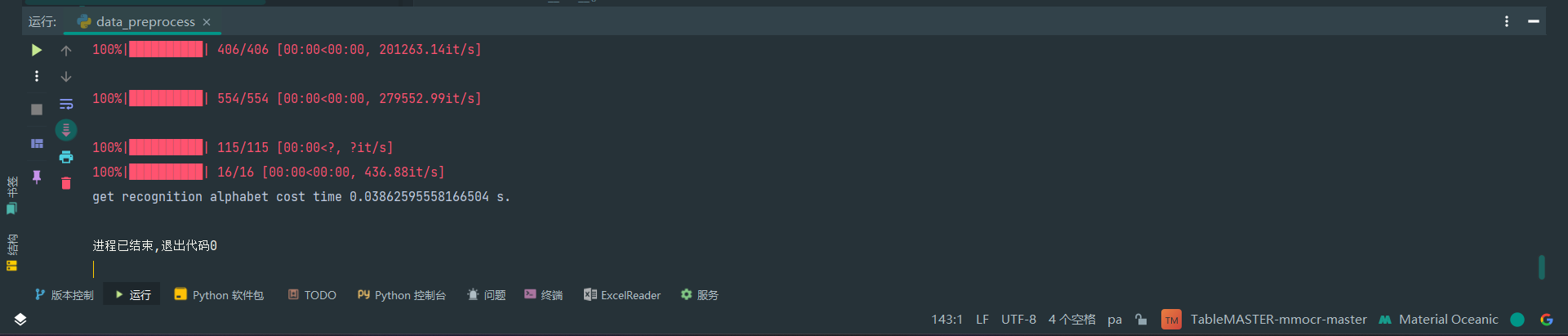
新建了这些内容
4.删掉文件,is_toy改为False再跑
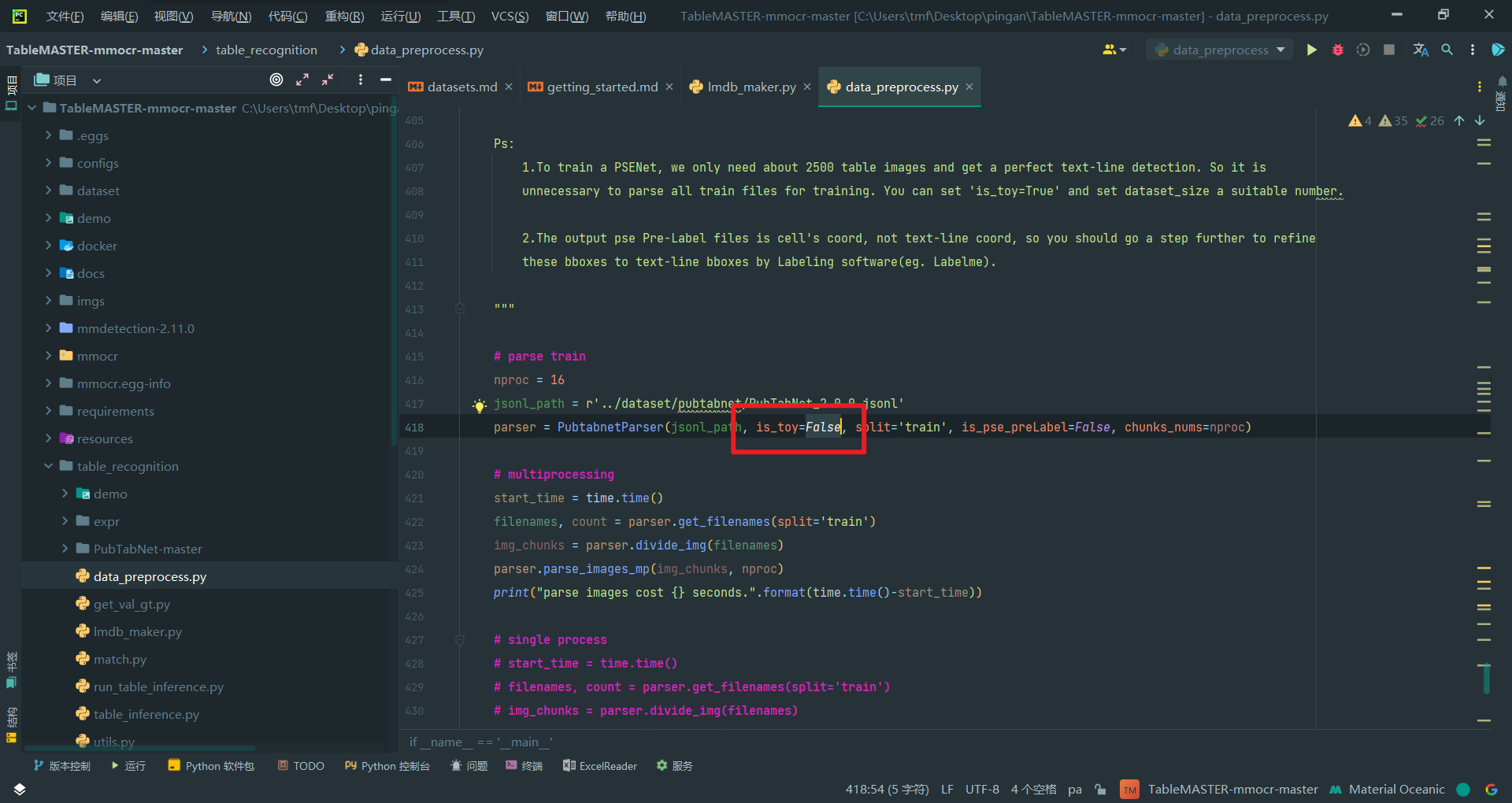
这次数据量就很大了,需要跑挺久,建议没调试完其它程序不要运行。(True就是少量数据便于后面训练调试,避免大数据占用太多时间)
正常运行完毕,就是时间有点久,大概十分钟多。
5.将split改为val再运行得到验证集
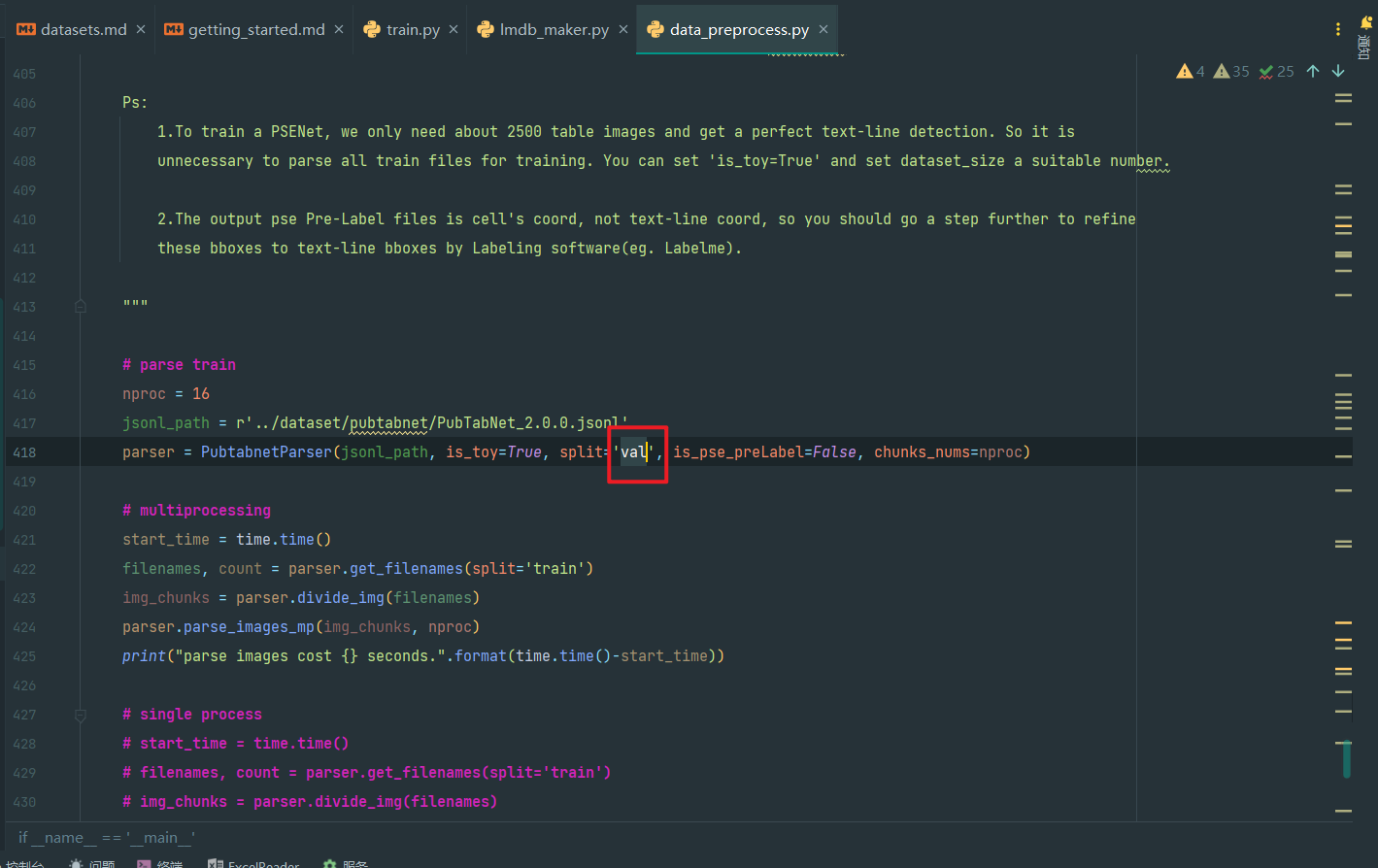
如图,第418行的split改为val,is_toy安装实际情况,debug就True,实际训练就False
parser = PubtabnetParser(jsonl_path, is_toy=True, split='val', is_pse_preLabel=False, chunks_nums=nproc)
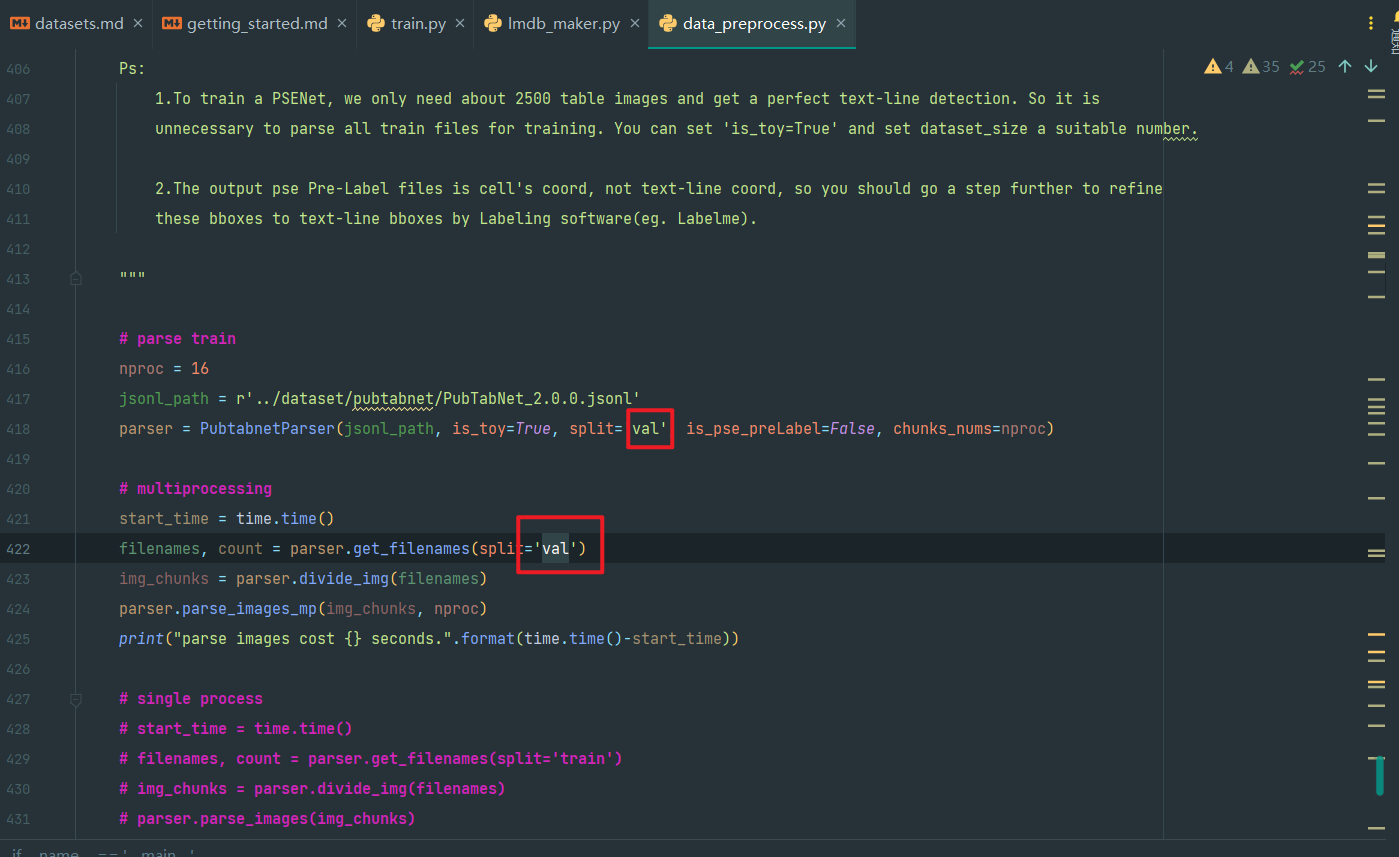
如图,第422行也要改成对应的,即
filenames, count = parser.get_filenames(split='val')
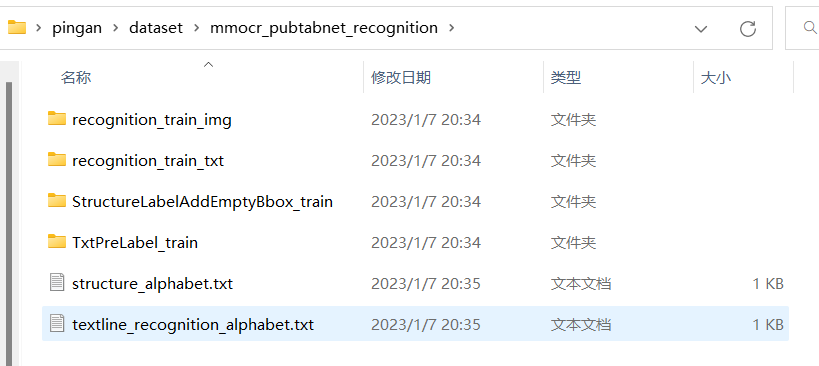
6.最终结果目录结构
processed_data
│ ├─StructureLabel_train
│ └─StructureLabel_val
├─recognition_train_img
│ ├─0
│ ├─1
│ ├─10
│ ├─11
│ ├─12
│ ├─13
│ ├─14
│ ├─15
│ ├─2
│ ├─3
│ ├─4
│ ├─5
│ ├─6
│ ├─7
│ ├─8
│ └─9
├─recognition_train_txt
├─recognition_val_img
│ ├─0
│ ├─1
│ ├─10
│ ├─11
│ ├─12
│ ├─13
│ ├─14
│ ├─15
│ ├─2
│ ├─3
│ ├─4
│ ├─5
│ ├─6
│ ├─7
│ ├─8
│ └─9
├─recognition_val_txt
├─StructureLabelAddEmptyBbox_train
├─StructureLabelAddEmptyBbox_val
├─TxtPreLabel_train
└─TxtPreLabel_val
二、lmdb_maker.py的使用
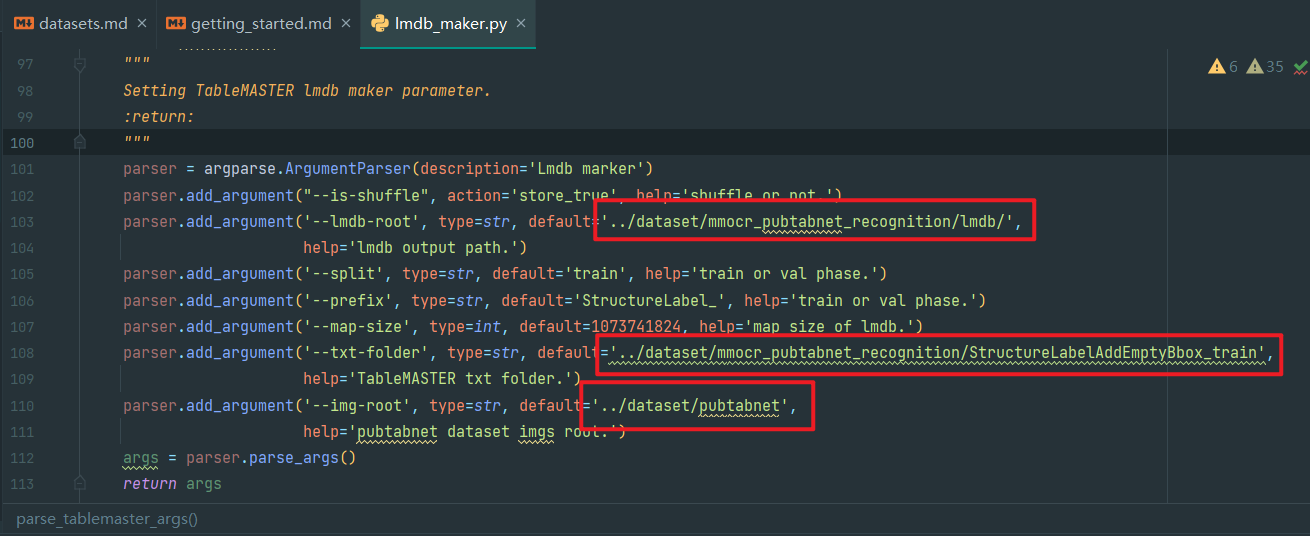
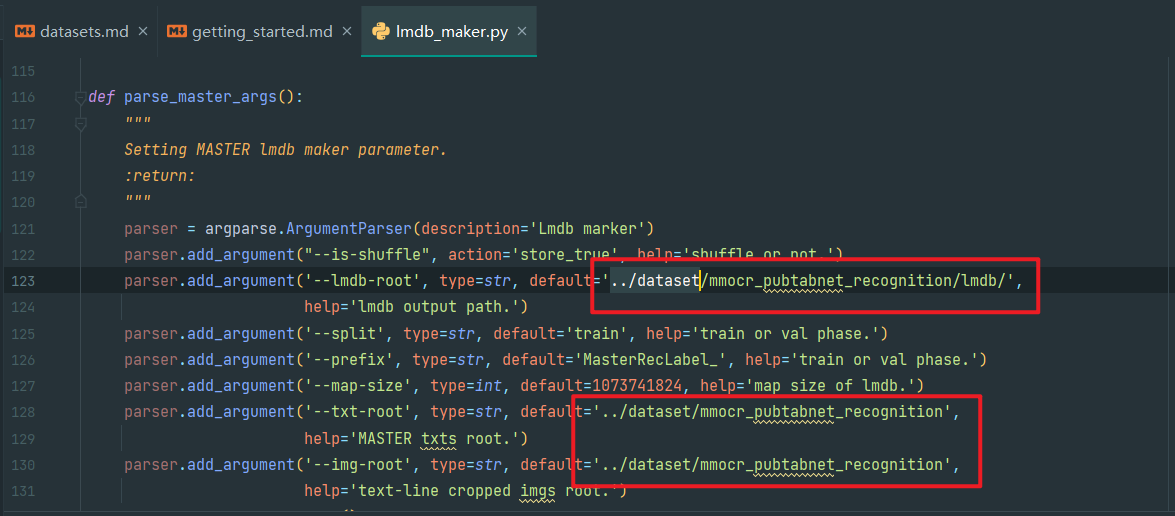
1.修改文件路径
如图,parse_data_args函数和parse_tablemaster_args函数定义的默认值改成自己的processed_data位置(或者是mmocr_pubtabnet_recognition)
2.调整map_size
map_size是lmdb数据库的大小(它是固定分配的),所以源文件是1TB大小,debug改为1GB(1073741824),但实际运行时可能要预留15GB(1024*1024*1024*15=16106127360)。
且注意是有两个地方有map_size,分别在parse_data_args函数和parse_tablemaster_args函数定义,请自行搜索
3.必须手动创建lmdb目录
在mmocr_pubtabnet_recognition或者processed_data目录下手动新建lmdb目录即可,其它不用管
所以目录结构看起来是这样(子目录没有展开)
mmocr_pubtabnet_recognition
├─lmdb
├─recognition_train_img
├─recognition_train_txt
├─StructureLabelAddEmptyBbox_train
└─TxtPreLabel_train
4.train or val phase
parser.add_argument('--split', type=str, default='train', help='train or val phase.')
这个是可选train和val的,默认是train,这里参考训练的博文,修改后再生成了一个val的lmdb,请把所有的train换为val(包括后面test的路径)
5.取消注释
if __name__ == '__main__':
下面默认只有MASTER lmdb test能运行,但是table_master的训练被注释,所以这要根据需求,看注释,训练目前是把TableMASTER lmdb create和TableMASTER lmdb test取消注释其它master lmdb的都注释掉
6.注释pdb
在每个test的最后都有一行
import pdb;pdb.set_trace()
这个是Python debug的,详见
https://blog.csdn.net/zqqbb7601/article/details/124728867
https://www.jianshu.com/p/fb5f791fcb18(详细)
因为我们不会debug,这个又需要命令来,所以先注释掉不管吧。
如果不注释,要继续运行程序用c命令,退出可以用q命令
7.特别提醒
lmdb test处的文件路径使用绝对路径,否则lmdb会open报错
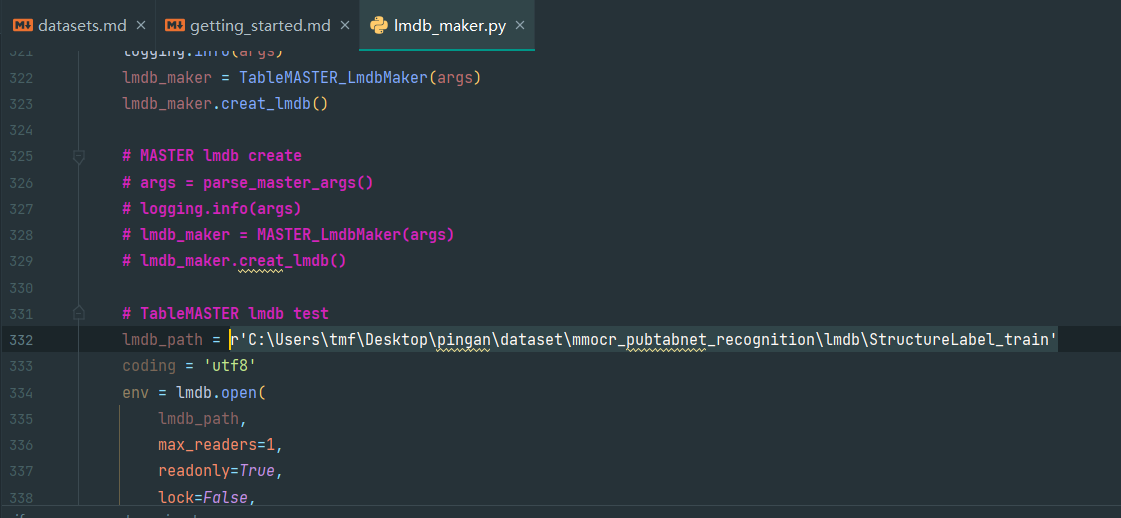
8.修改train为val进行val的lmdb制作
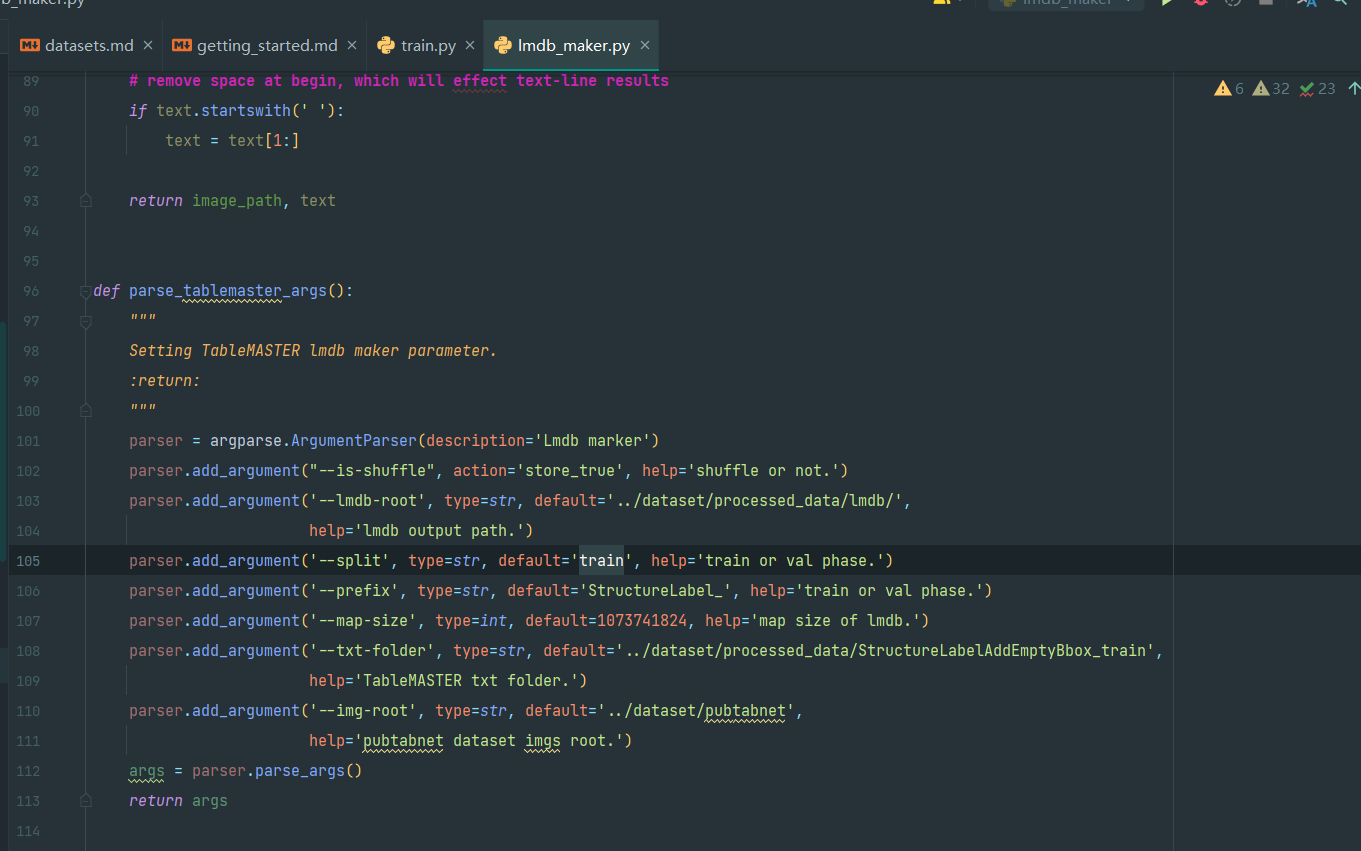
如图,第105行的default的train改成val,即
parser.add_argument('--split', type=str, default='val', help='train or val phase.')
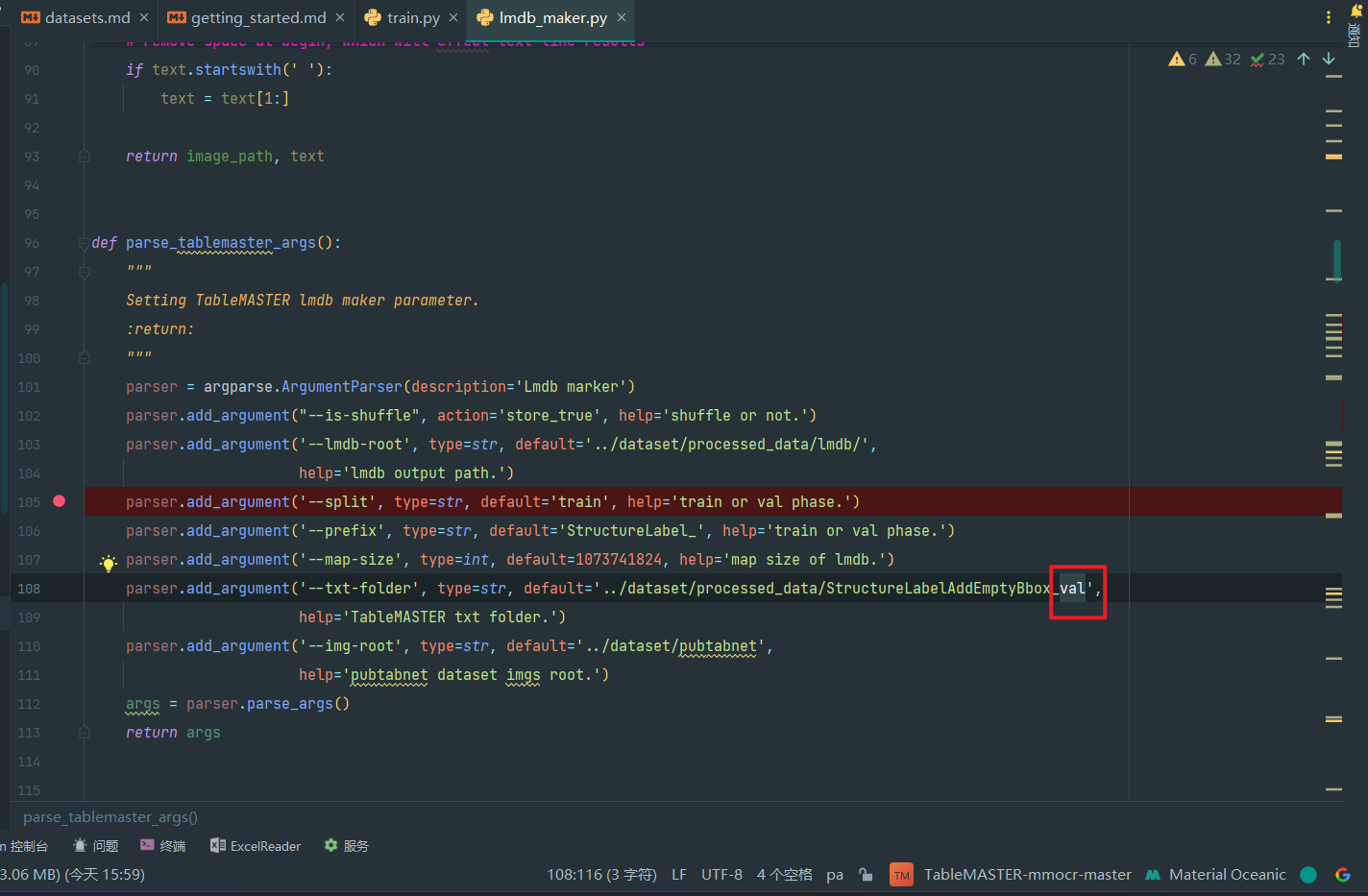
如图,第108行的文件夹也要改成对应的val的(这要求前面预处理要二次修改得到val),即
parser.add_argument('--txt-folder', type=str, default='../dataset/processed_data/StructureLabelAddEmptyBbox_val',
help='TableMASTER txt folder.')
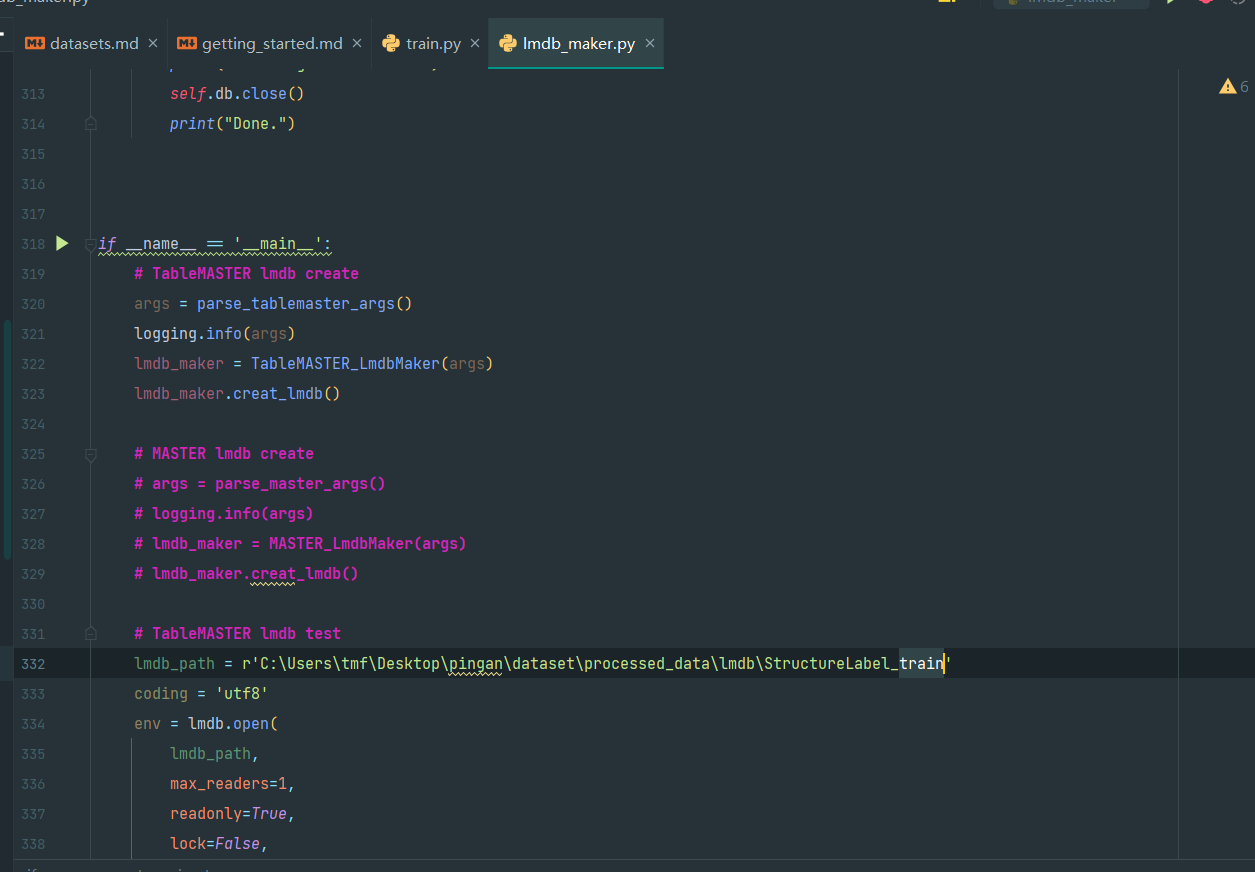
如图,第332行的TableMASTER lmdb test的路径改成val进行认证,即
lmdb_path = r'C:\Users\tmf\Desktop\pingan\dataset\processed_data\lmdb\StructureLabel_val'
再次运行即可
9.最终结果目录
lmdb
├─StructureLabel_train
│ data.mdb
│ lock.mdb
│
└─StructureLabel_val
data.mdb
lock.mdb
3.1table_recognition_dist_train.sh解析
一个GPU的sh和debug差不多,只是WORK_DIR没有_debug而已,这里只解析table_recognition_dist_train.sh,其它的到具体文件的解析看
该文件就如下一条命令,是用这个命令来启动另一个实际的sh文件的
CUDA_VISIBLE_DEVICES=0,1,2 PORT=29500 ./tools/dist_train.sh ./configs/textrecog/master/table_master_lmdb_ResnetExtract_Ranger_0930.py ./work_dir/1114_TableMASTER_structure_debug/ 3
Usage:
bash table_recognition_dist_train.sh CONFIG WORK_DIR GPUS
解析:
-
前面的是GPU编号(从0开始)和端口的环境变量设置,Windows不确定是否需要,再看
-
table_recognition_dist_train.sh:实际调用的sh文件 -
CONFIG:需要的配置文件 -
WORK_DIR:工作路径 -
GPUS:GPU数量,和GPU编号对应
因为我们是一个GPU,所以GPU应该像下面这样,端口、配置文件等另说
CUDA_VISIBLE_DEVICES=0 PORT=29500 ./tools/dist_train.sh ./configs/textrecog/master/table_master_lmdb_ResnetExtract_Ranger_0930.py ./work_dir/1114_TableMASTER_structure_debug/ 1
3.2tools下dist_train.sh解析
源代码如下:
#!/usr/bin/env bash
if [ $# -lt 3 ]
then
echo "Usage: bash $0 CONFIG WORK_DIR GPUS"
exit
fi
CONFIG=$1
WORK_DIR=$2
GPUS=$3
PORT=${PORT:-29500}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
if [ ${GPUS} == 1 ]; then
python3 $(dirname "$0")/train.py $CONFIG --work-dir=${WORK_DIR} ${@:4}
else
python3 -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
$(dirname "$0")/train.py $CONFIG --work-dir=${WORK_DIR} --launcher pytorch ${@:4}
fi
注释解析如下:
涉及到较多shell语法:
https://blog.csdn.net/sxzlc/article/details/7544465
https://blog.csdn.net/hanjinjuan/article/details/119086556
https://blog.csdn.net/daocaokafei/article/details/120050007($@)
#!/usr/bin/env bash # bash环境
# $0 $1 $2 $3 这个就是命令行输入的命令了,和Python的sys.argv[]一样。$0就是这个文件本身
if [ $# -lt 3 ] # 如果后面的参数小于3,即命令usage不对,退出
then
echo "Usage: bash $0 CONFIG WORK_DIR GPUS" # 输出usage并退出
exit
fi
# 给后面的参数命了个名而已
CONFIG=$1
WORK_DIR=$2
GPUS=$3
PORT=${PORT:-29500} # 如果变量名有赋值或为空,使用value的值 ${variable:-value}
# 下面是调用Python运行程序,同时要设置Python的工作路径PYTHONPATH,使用的是shell命令来设置
# 详细语法见 https://www.cnblogs.com/zhaoyangang/p/5641706.html
# 简单来说,$(dirname $0) 代表当前这个文件所在的目录(相对或绝对路径)
# $() / ..就是去到它的父目录,在这个模型的运行环境下就是把Python工作目录设置为 TableMASTER-mmocr-master
# 然后在这个工作目录下运行 ./tools/train.py
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
if [ ${GPUS} == 1 ]; then
python3 $(dirname "$0")/train.py $CONFIG --work-dir=${WORK_DIR} ${@:4}
else
python3 -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
$(dirname "$0")/train.py $CONFIG --work-dir=${WORK_DIR} --launcher pytorch ${@:4}
fi
同时这个脚本会检测GPU数量(指自己输入的数量),如果是多个,就会运行
python3 -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
./tools/train.py $CONFIG --work-dir=${WORK_DIR} --launcher pytorch ${@:4}
恩,就会复杂一些,但是对于只有一个GPU,那就简单很多了,而且也不需要PORT
python3 ./tools/train.py $CONFIG --work-dir=${WORK_DIR} ${@:4}
而对于结尾的${@:4},$@表示全部命令行参数,这个写法根据实验是截取第四个及后面的所有附加参数
(本来只有三个参数的,所以后面的可以忽略)
总结
1.环境变量设置
CUDA_VISIBLE_DEVICES=0 这个环境变量,可能最好还是在系统环境变量添加一个,或者就在Python文件里添加
os.environ['CUDA_VISIBLE_DEVICES']='1'
参考https://blog.csdn.net/zqx951102/article/details/127946871
但是不确定这个environment的范围,我用Python文件运行另一个Python文件后这个环境还有吗,没有的话就得在每一个需要这个环境的代码前面添加,那还不如自己手动在环境永久添加。
2.单GPU不需要PORT环境变量
这里我们单GPU可以不用管了,多GPU就得设置一下了
3.sh改写为py
设置好环境变量后,连同发起调用的table_recognition_dist_train.sh一起写成一个py文件放到./table_recognition/expr/table_recognition_dist_train.py
# pwd: TableMASTER-mmocr-master
# file: ./table_recognition/expr/table_recognition_dist_train.py
""" 提示:
1.请设置环境变量
CUDA_VISIBLE_DEVICES=0 如果要修改,多个就是字符串值 0, 1, 2, 3
2.多GPU还需要设置PORT变量
PORT=29500(默认)
3.自行调整参数
CONFIG: 配置文件
WORK_DIR :工作目录,但不是当前文件的这个工作目录,这是./tools/train.py的运行参数,用来存储日志和model
GPUS:GPU数量,根据环境变量CUDA_VISIBLE_DEVICES来,有多少个就多少个
"""
import os
import sys # 额外参数用命令行参数传入
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:32" # CUDA out of memory的解决(实测可以不用,我的是单纯GPU内存不够啊)
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
pwd = '../../' # 这个文件的工作路径,要 TableMASTER-mmocr-master ,默认情况下不用改
os.chdir(pwd) # 其实这么设置的话就不用在pycharm设置运行目录了
print('cwd:', os.getcwd())
# os.system('chdir') # 查看cmd工作路径,是一致的
# 待修改参数
CONFIG = './configs/textrecog/master/table_master_lmdb_ResnetExtract_Ranger_0930.py'
WORK_DIR = './work_dir/1114_TableMASTER_structure_debug/'
GPUS = 1
PORT = 29500 # 多GPU才需要,默认值是29500
if GPUS == 1:
os.system(f'python ./tools/train.py {CONFIG} --work-dir={WORK_DIR} {" ".join(sys.argv[1:])}')
else:
os.system(f'python -m torch.distributed.launch --nproc_per_node={GPUS} --master_port={PORT} '
f'./tools/train.py {CONFIG} --work-dir={WORK_DIR} --launcher pytorch {" ".join(sys.argv[1:])}')
3.3只用table_recognition_dist_train.py即可
4.train.py文件设置解读
1.--load_from参数
第28-31行,这个参数应该可以保证断点续练
parser.add_argument(
'--load-from', help='The checkpoint file to load from.')
parser.add_argument(
'--resume-from', help='The checkpoint file to resume from.')
2.mc-config参数
第76-80行,这个参数可能可以设置内存缓存加快图片加载速度
parser.add_argument(
'--mc-config',
type=str,
default='',
help='Memory cache config for image loading speed-up during training.')
3.自动创建work_dir
第151行,程序会自动创建work_dir,所以不需要自己创建,整个程序不需要改动什么东西
# create work_dir
mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
4.除了自定义命令行参数(基本不动),所有配置主要在config文件
如果实在需要,可以在源代码加个
os.environ['CUDA_VISIBLE_DEVICES']='0'
设置一下GPU
5.work_dir自己定个路径就好,不用创建
6.config文件配置
1._base_和alphabet_file的相对路径有点奇怪
_base_ = [
'../../_base_/default_runtime.py'
]
alphabet_file = './tools/data/alphabet/structure_alphabet.txt'
_base_是以当前文件的目录作cwd,但是alphabet_file是以TableMASTER-mmocr-master作为cwd的,另外大致翻看了一下代码这个_base_好像不使用
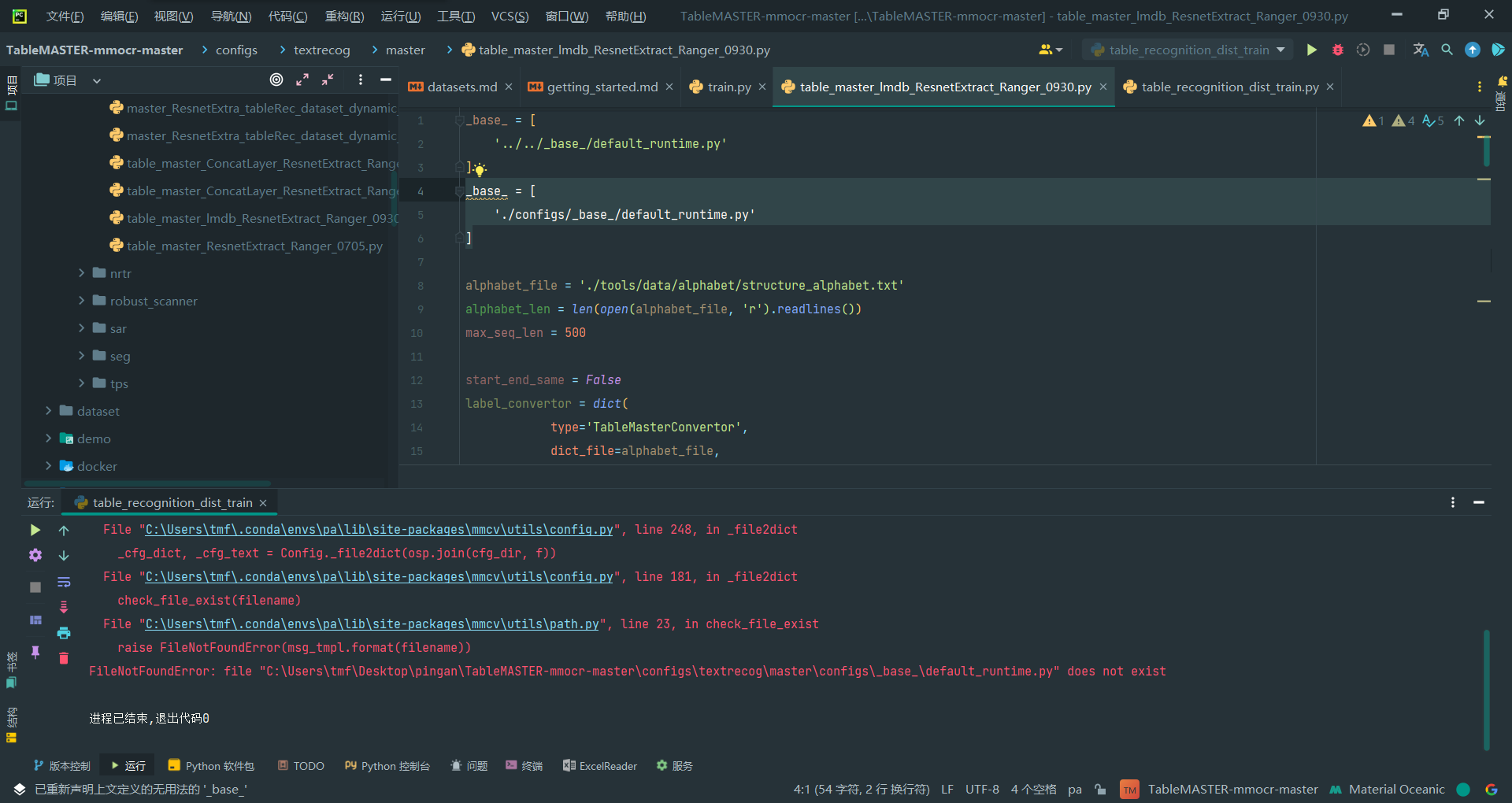
如图,如果修改_base_路径,会发生如下报错,所以它就是这样的,不用修改
2.修改训练集等路径
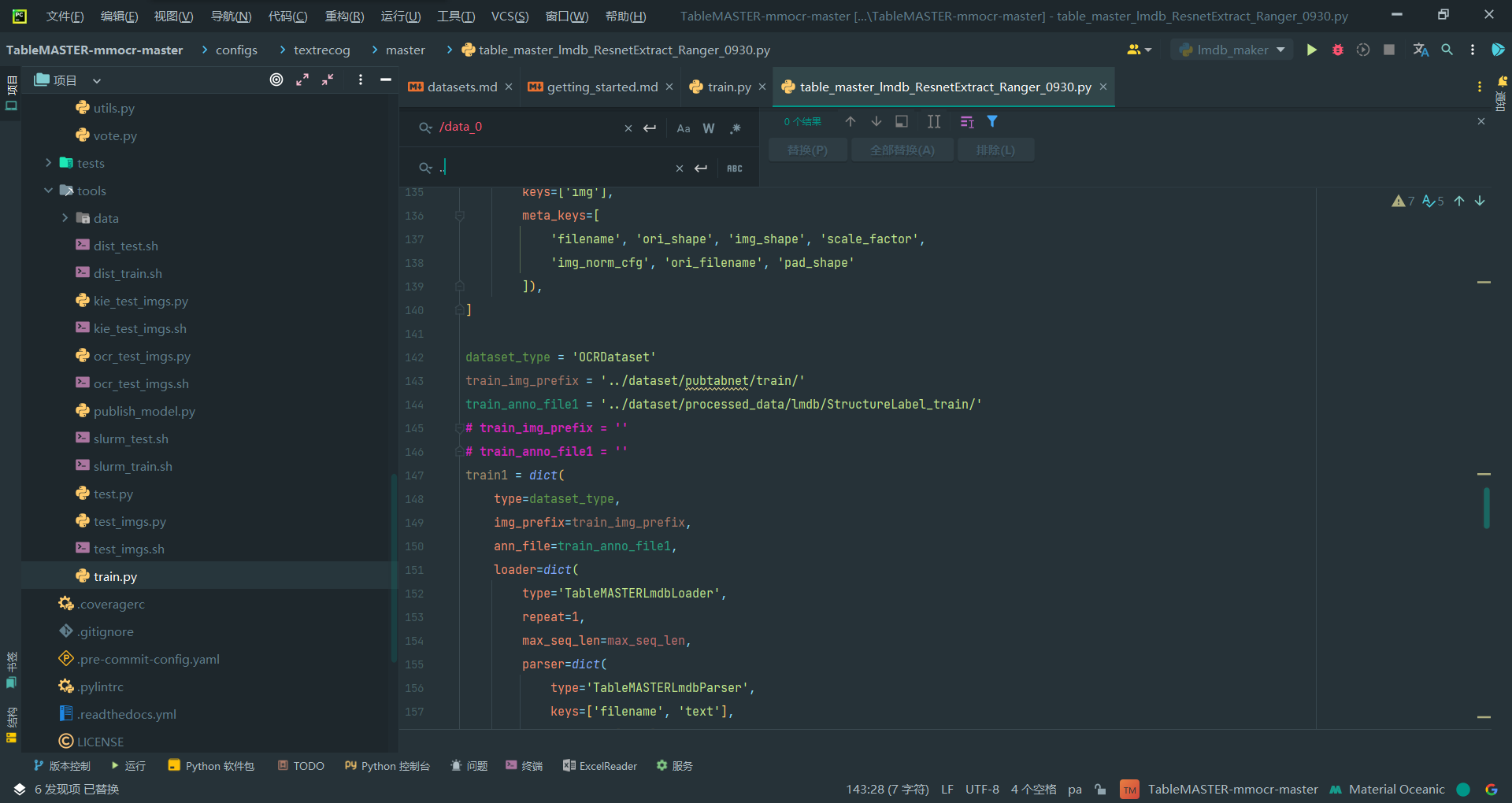
主要是pubtabnet的train和val的位置以及相对应的lmdb的位置
所以lmdb里面需要同时有train和val,因此前面的lmdb_maker.py要修改运行两次
3.设置batch_size和num_workers
在第205-206行,
batch_size就是samples_per_gpu,目前我的GPU只能设置成1才能跑。
num_workers就是workers_per_gpu,这个设置涉及到一个报错,必须改成0让它在主线程才行
samples_per_gpu=1,
workers_per_gpu=0,
4.epoch可调
第223行
total_epochs = 17
每个epoch训练时都会保存一个模型pth
7.调用脚本开始训练
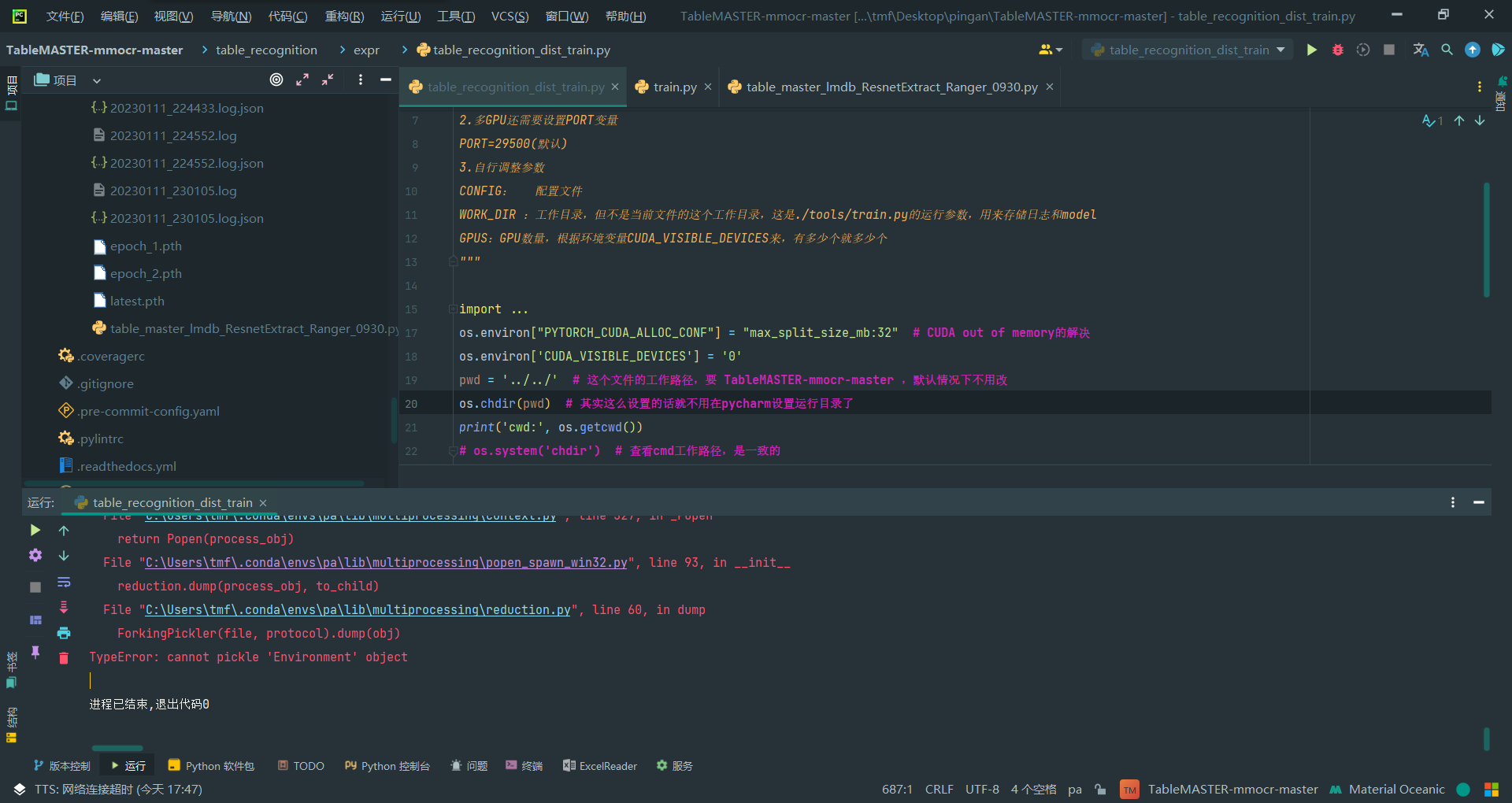
1.直接调用sh改成的脚本进行训练
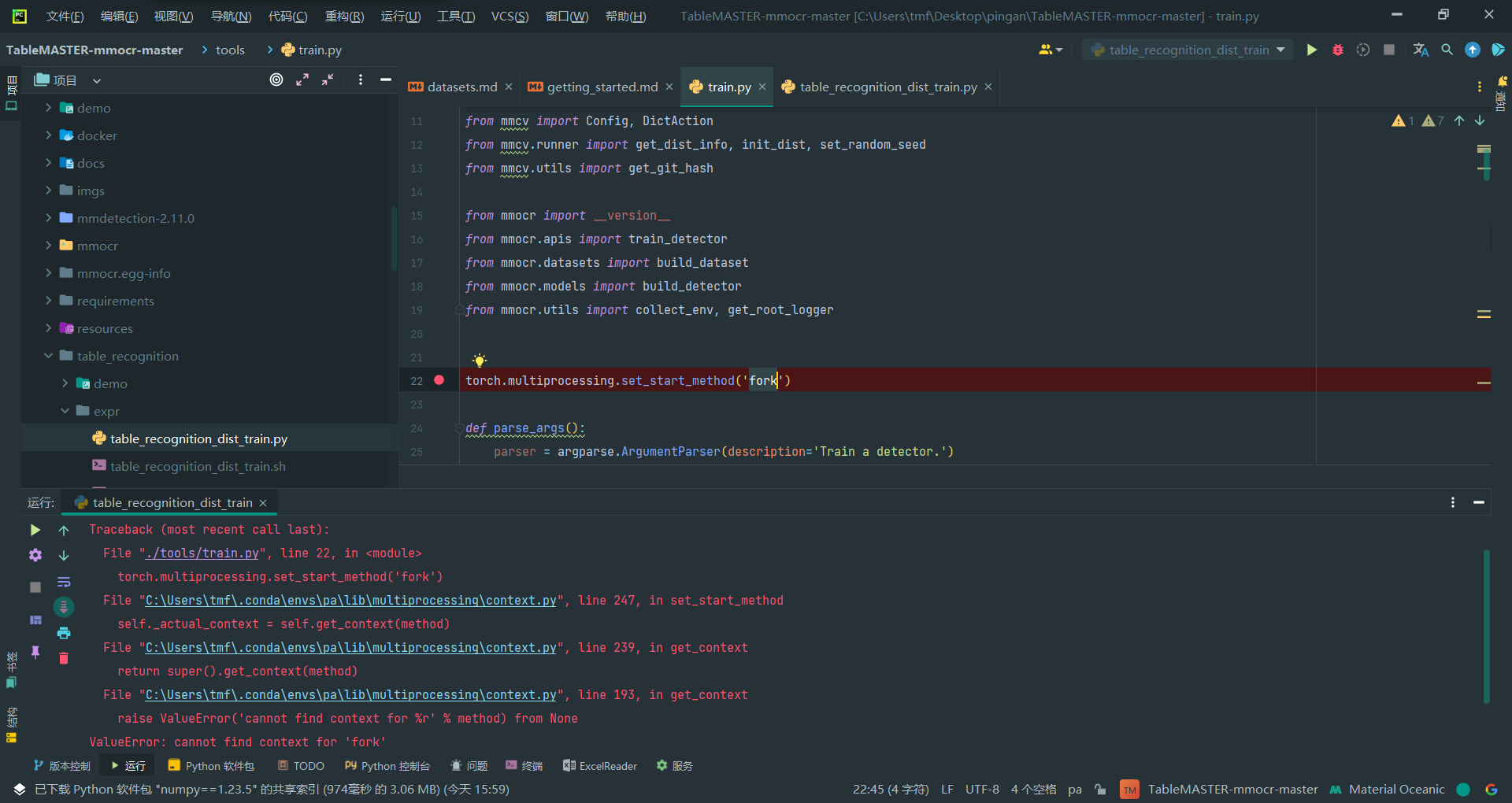
出现如上报错,网上搜索的结果(非本项目)都是将fork改为spawn
https://github.com/beancount/beangrow/issues/11
https://blog.csdn.net/m0_37876745/article/details/119750687
https://blog.csdn.net/weixin_43235307/article/details/122108358
2.fork改为spawn后运行
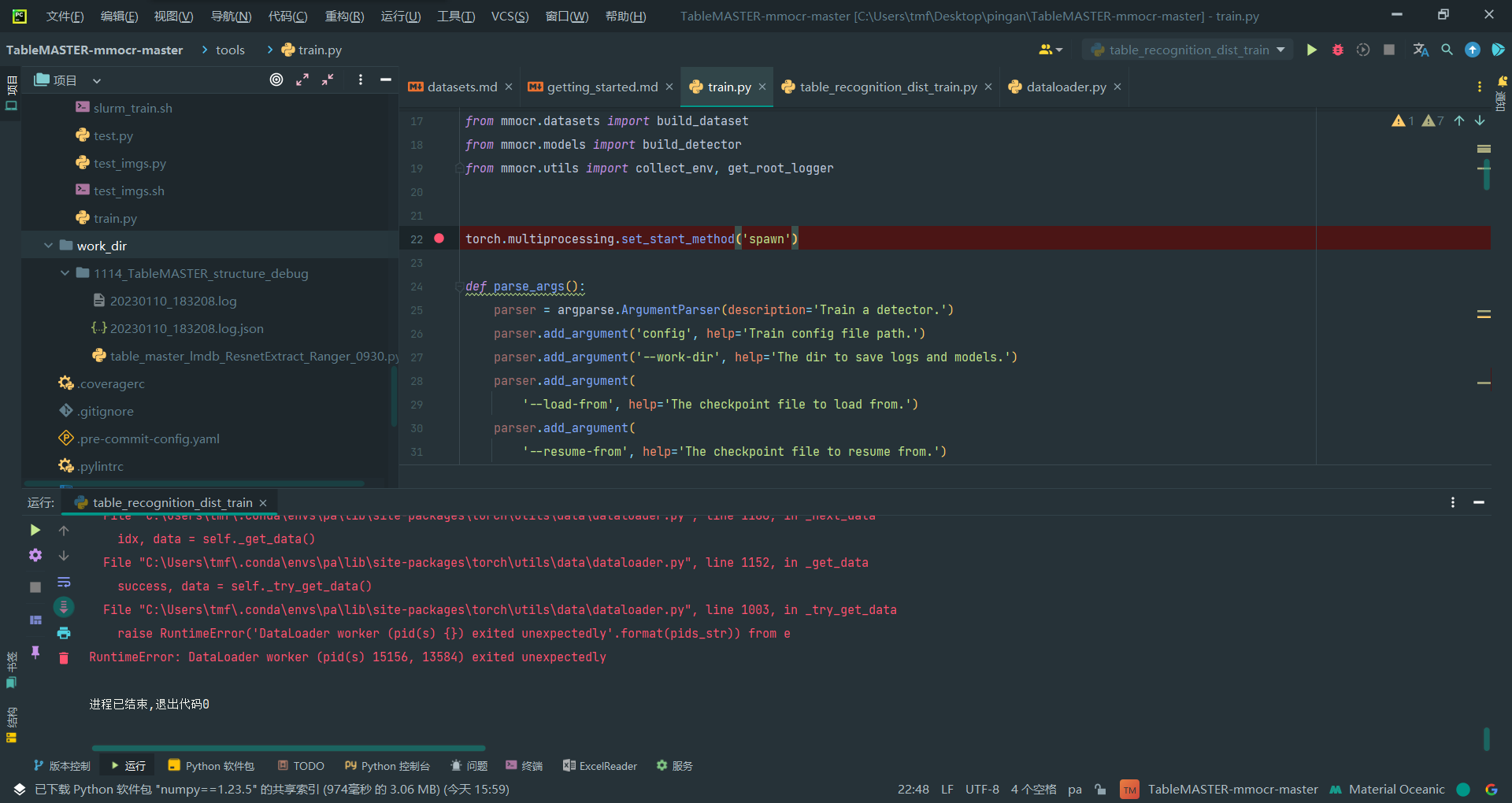
可以运行,但开始报其他错误了
3.再次修改set_start_method
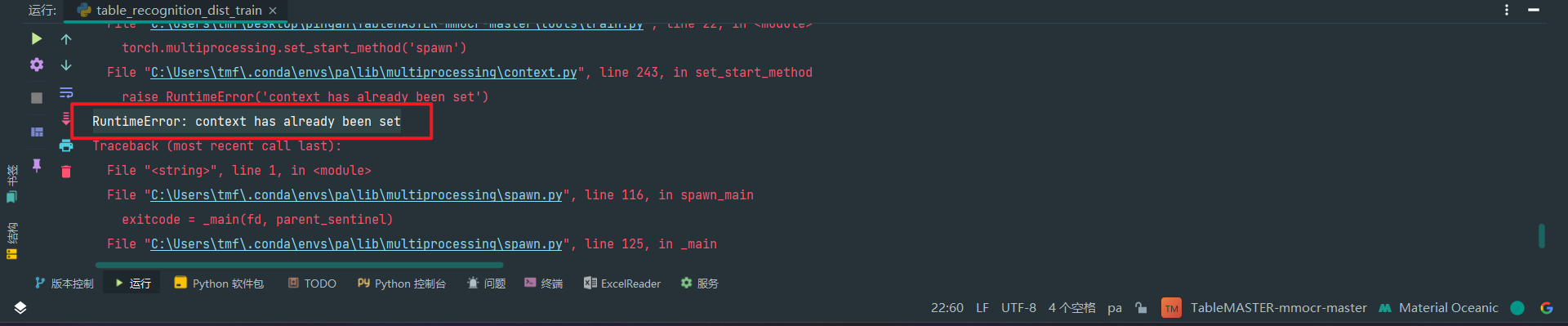
如图,搜索这个报错信息
RuntimeError: context has already been set
查看如下链接:
https://cloud.tencent.com/developer/article/2069651
https://blog.csdn.net/weixin_43579015/article/details/127688132
https://blog.csdn.net/qq_16792139/article/details/114963080
有两种改法,分别尝试
torch.multiprocessing.set_start_method('spawn', force=True)
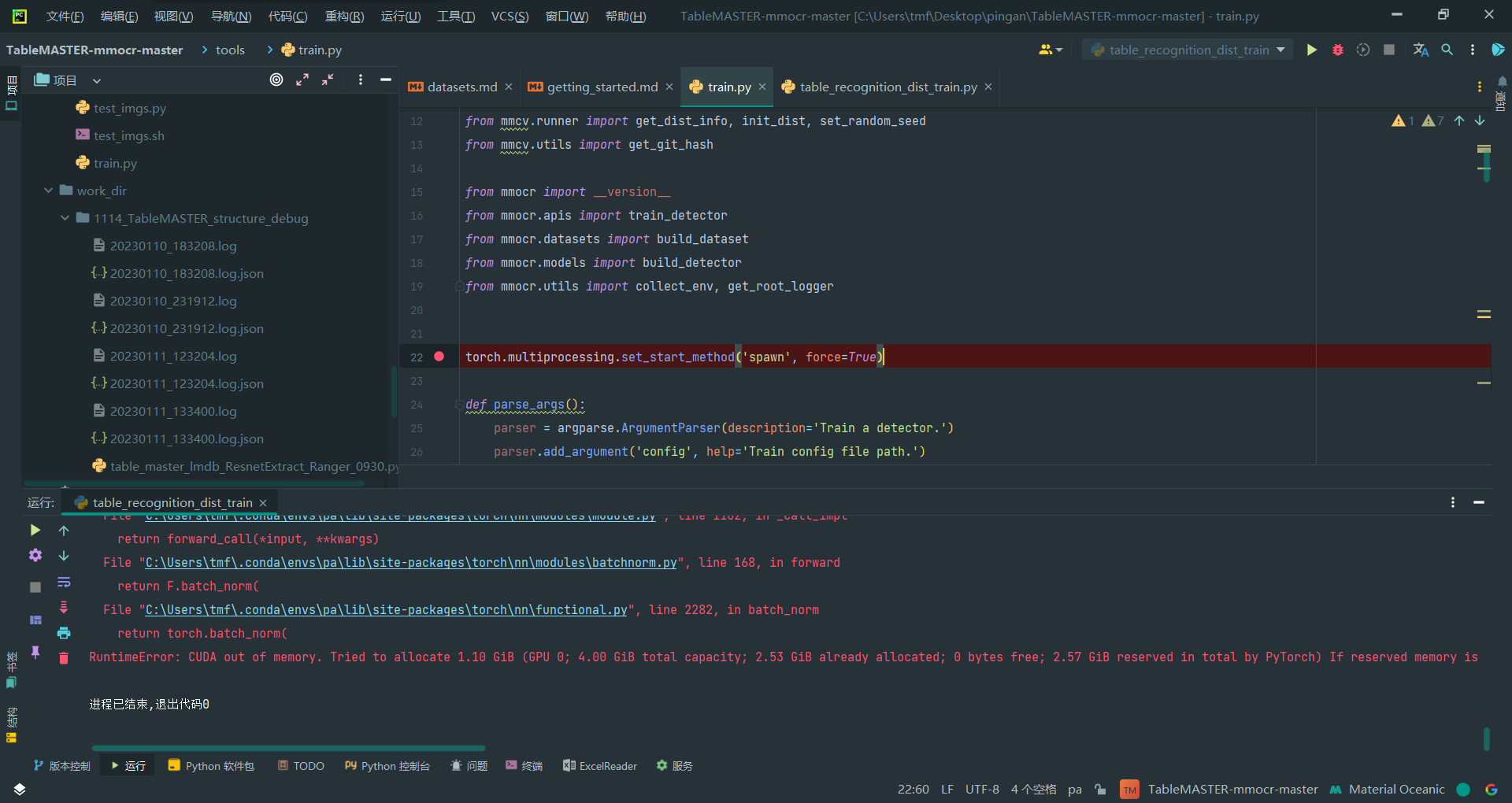
修改后可以运行,但是遇到内存不足的问题
RuntimeError: CUDA out of memory. Tried to allocate 1.10 GiB (GPU 0; 4.00 GiB total capacity; 2.53 GiB already allocated; 0 bytes free; 2.57 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
先再试一下另一个方法
torch.multiprocessing.set_start_method('forkserver', force=True)
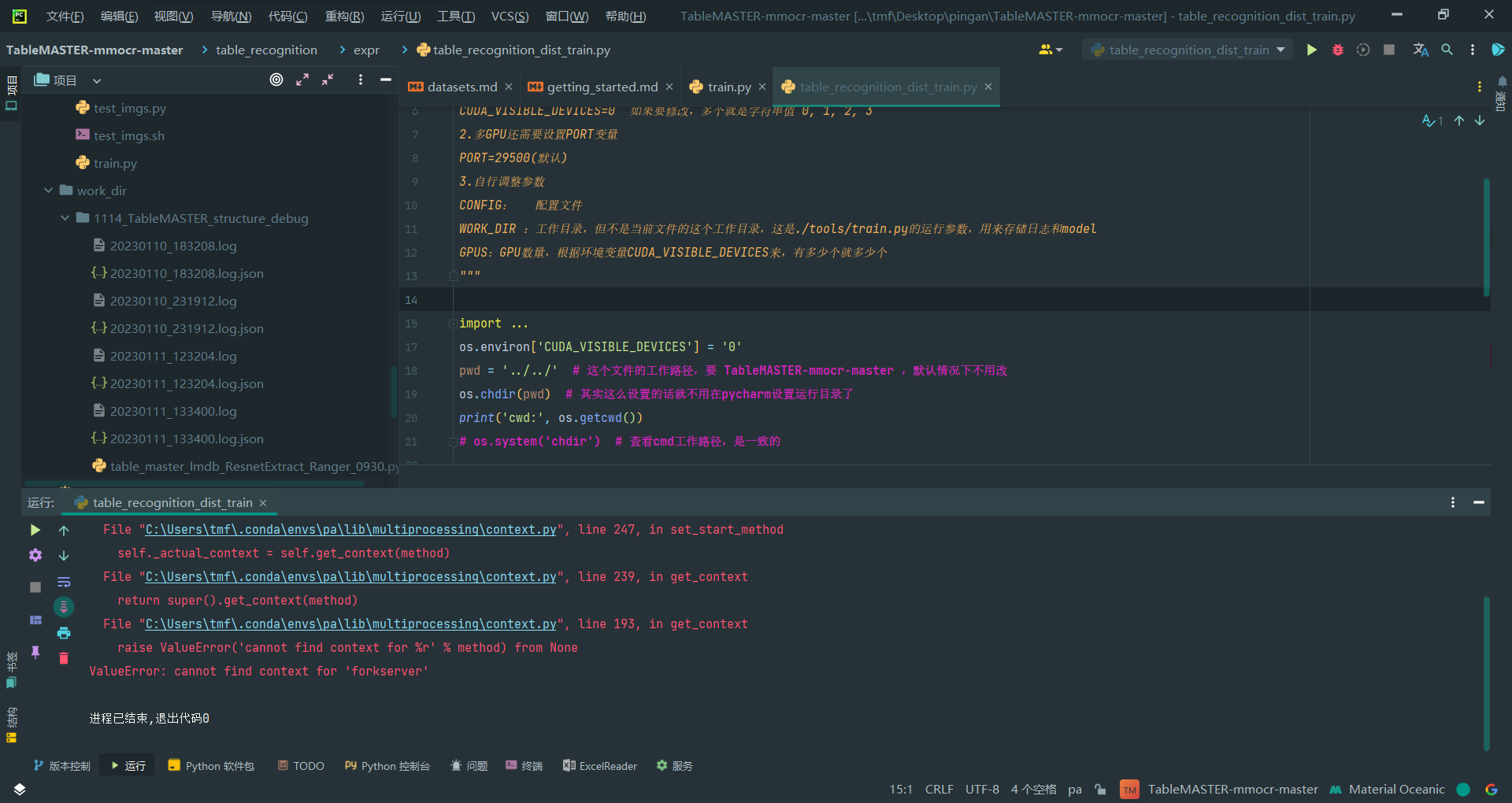
报错ValueError: cannot find context for 'forkserver',看来这个行不通,毕竟和原本的fork类似
4.解决内存问题
依据https://blog.csdn.net/m0_50502579/article/details/126059178中的方法一,减小batch size
搜索后发现在train.py的第187行build_dataset,通过这个函数进入到mmdetection-2.11.0/mmdet/datasets/builder.py,在这里面搜索发现batch size在这个项目里应该是samples_per_gpu (int)
Args:
dataset (Dataset): A PyTorch dataset.
samples_per_gpu (int): Number of training samples on each GPU, i.e.,
batch size of each GPU.
workers_per_gpu (int): How many subprocesses to use for data loading
for each GPU.
num_gpus (int): Number of GPUs. Only used in non-distributed training.
dist (bool): Distributed training/test or not. Default: True.
shuffle (bool): Whether to shuffle the data at every epoch.
Default: True.
kwargs: any keyword argument to be used to initialize DataLoader
于是到config文件里面搜索找到了第205行这个唯一的变量,将其从20修改为8试试。
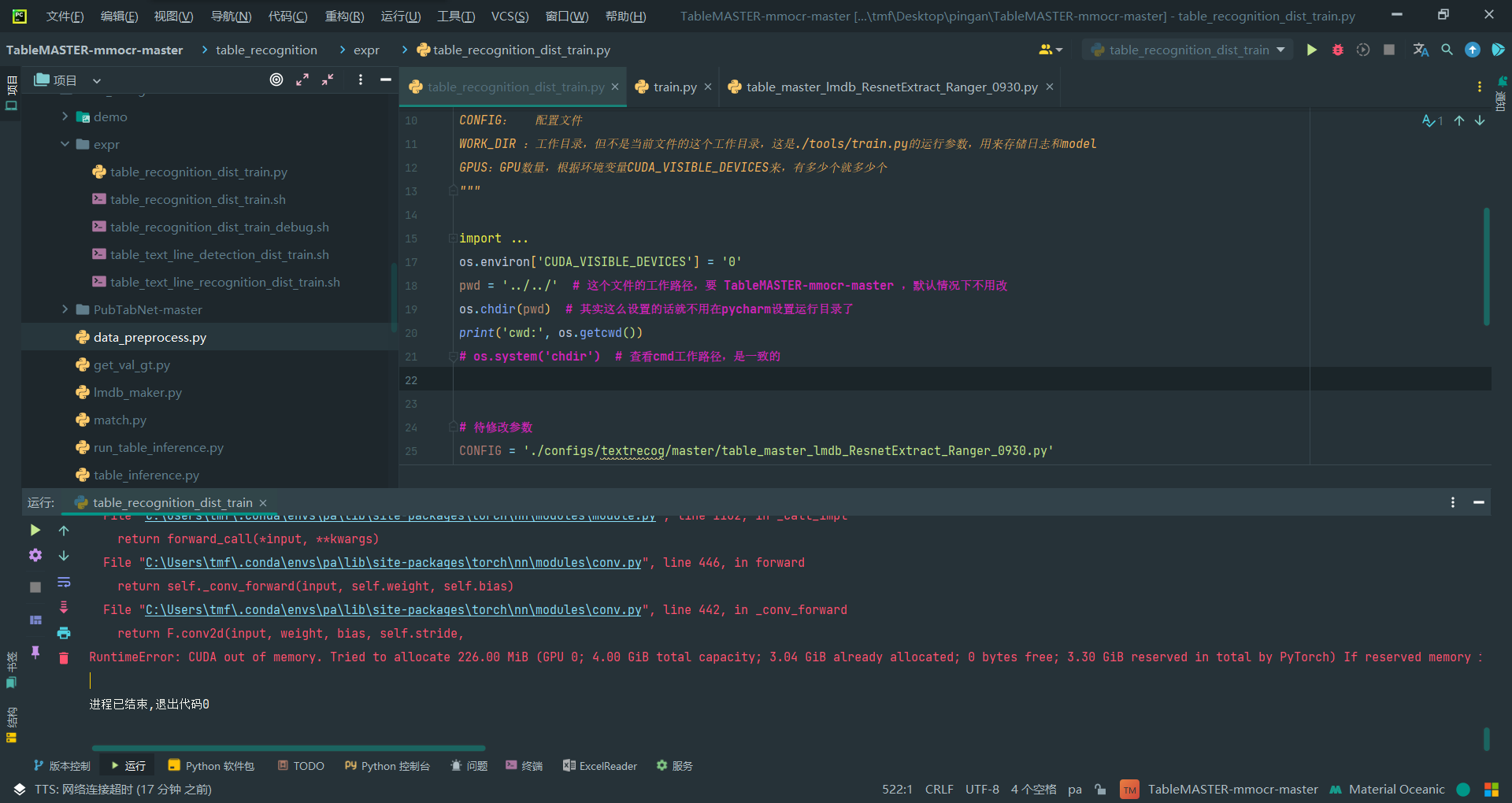
不行,好像原理与想想的不太对,先改为4再试试。
发现还是不行,只能另想办法
虽然pytorch提供了指定gpu的几种方式,但是使用不当的话会遇到out of memory的问题,主要是因为pytorch会在第0块gpu上初始化,并且会占用一定空间的显存.这种情况下,经常会出现指定的gpu明明是空闲的,但是因为第0块gpu被占满而无法运行,一直报out of memory错误.
在网上搜索时看到这么一段话,我感觉可能和我的情况符合了
比较batch 4、8、20时报错给出的内存信息
# 4:
Tried to allocate 220.00 MiB (GPU 0; 4.00 GiB total capacity; 3.38 GiB already allocated; 0 bytes free; 3.46 GiB reserved in total by PyTorch)
# 8:
Tried to allocate 226.00 MiB (GPU 0; 4.00 GiB total capacity; 3.04 GiB already allocated; 0 bytes free; 3.30 GiB reserved in total by PyTorch)
# 20:
Tried to allocate 1.10 GiB (GPU 0; 4.00 GiB total capacity; 2.53 GiB already allocated; 0 bytes free; 2.57 GiB reserved in total by PyTorch)
有点奇怪,pytorch保留的在减少,但就是分不了足够的给allocate
下面用第五种方法即环境变量来试一试
https://zhuanlan.zhihu.com/p/581606031
先加到启动文件table_recognition_dist_train.py的代码里试试os模块添加的环境
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:128" # CUDA out of memory的解决
还是不行。。。
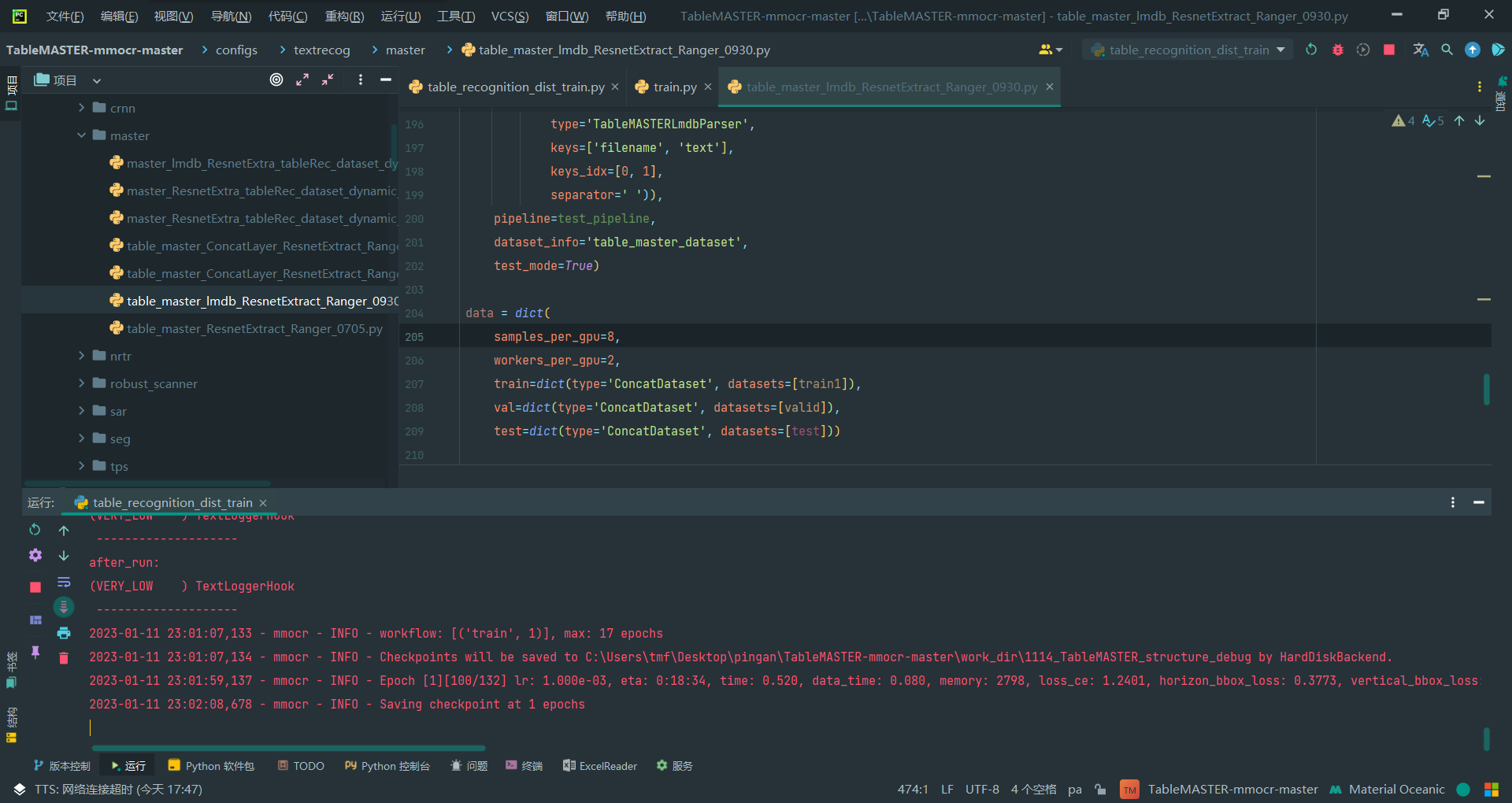
卧槽跑起来了!两个方法的结合!
config文件:
samples_per_gpu=1,
启动文件:(实测发现不要这个也行,就单纯是GPU内存不够)
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:32" # CUDA out of memory的解决
又有报错
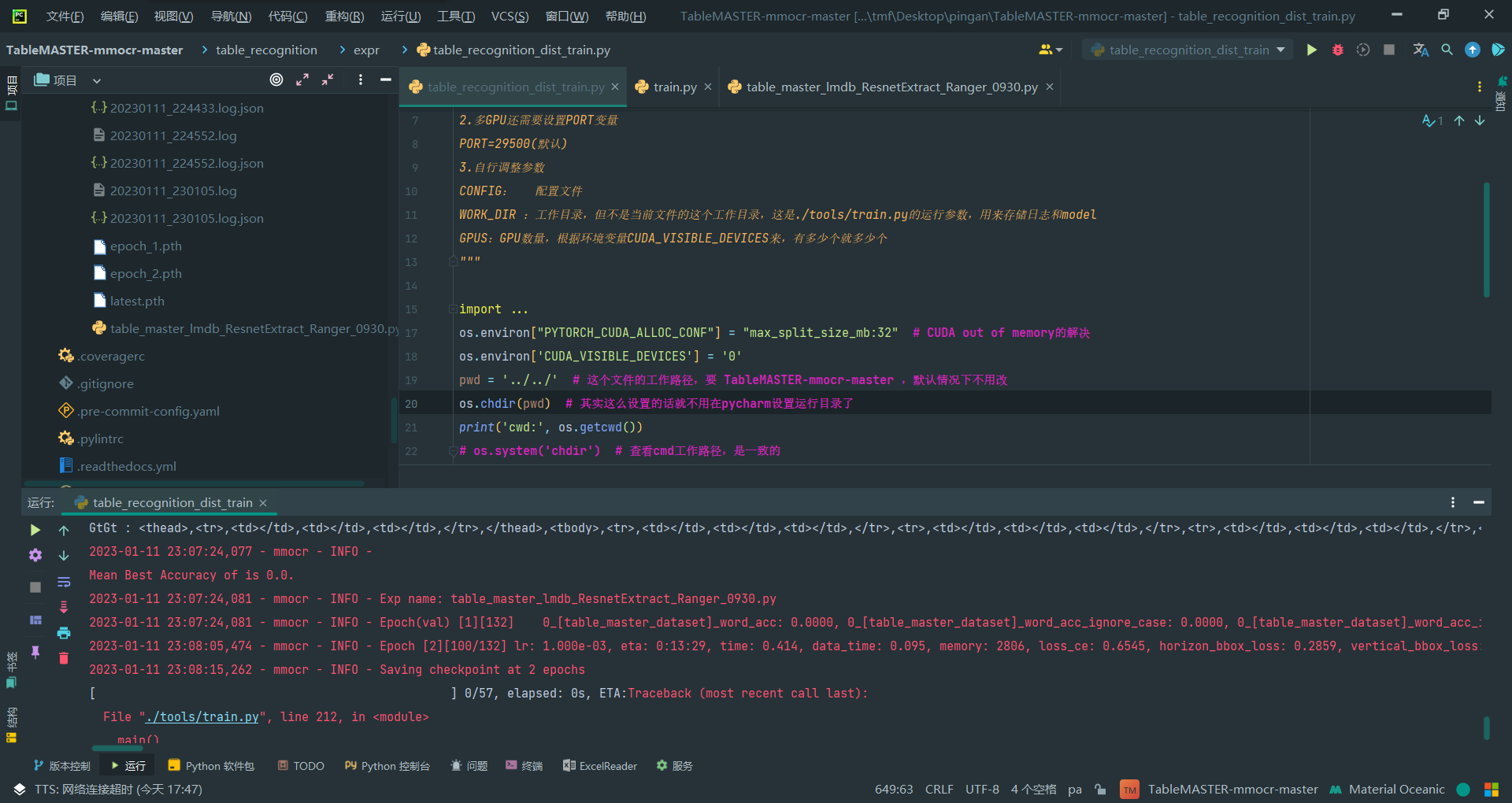
num_workers=0
直接搜索报错,得到下面几个同样的解决方法:
https://blog.csdn.net/weixin_43272781/article/details/112757371
https://blog.csdn.net/u013841196/article/details/106240482
https://github.com/pytorch/examples/issues/526#issuecomment-605450664
这应该是config文件第206行(也就是samples_per_gpu下面那行)
workers_per_gpu=2,
修改为
workers_per_gpu=0,
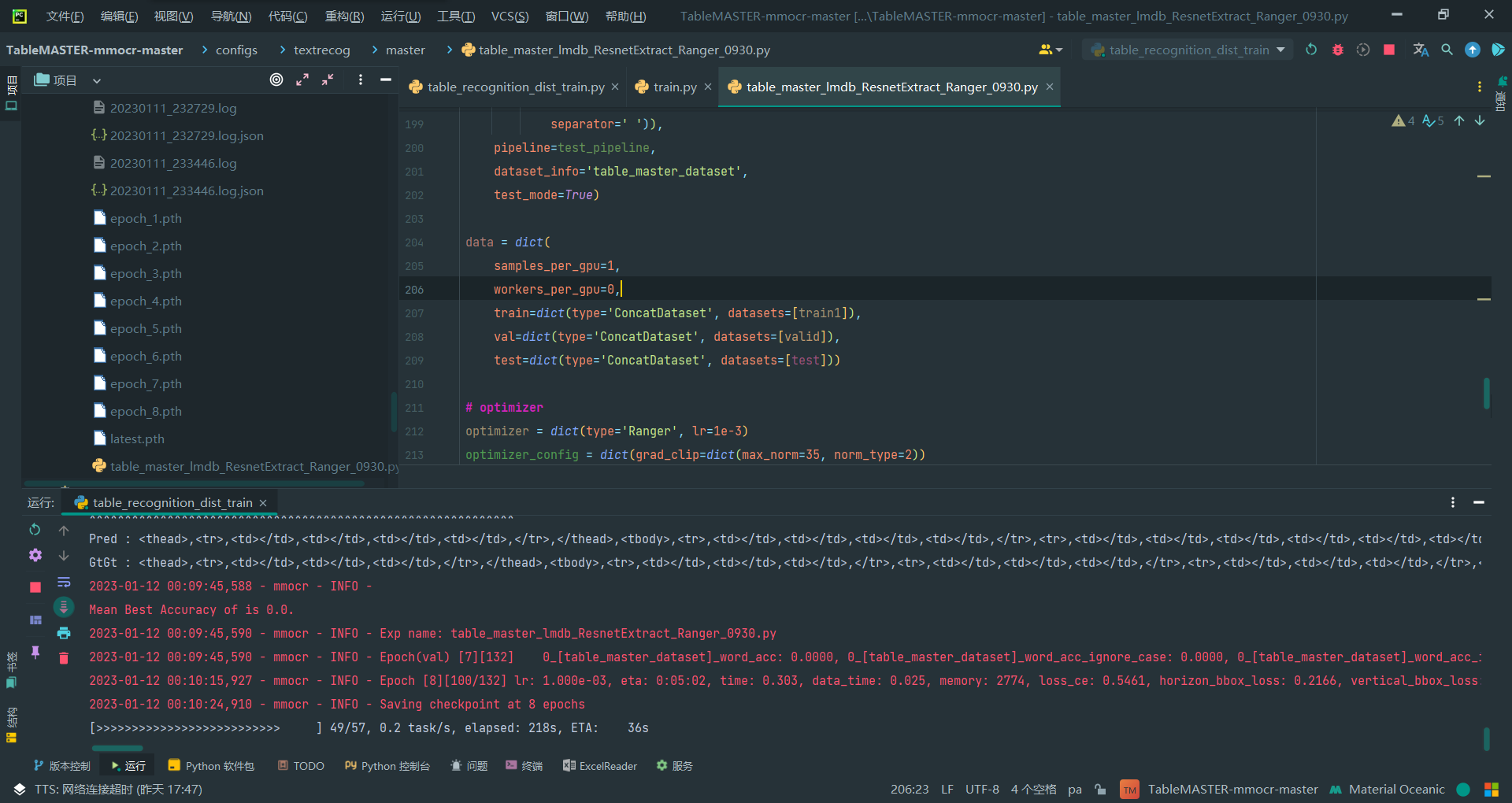
看样子似乎解决了,不确定是否跑得更慢了,但是epoch加了很多啊,之前是12之后就停了,至少现在一直在跑
速度不速度的已经不重要了
顺利跑完
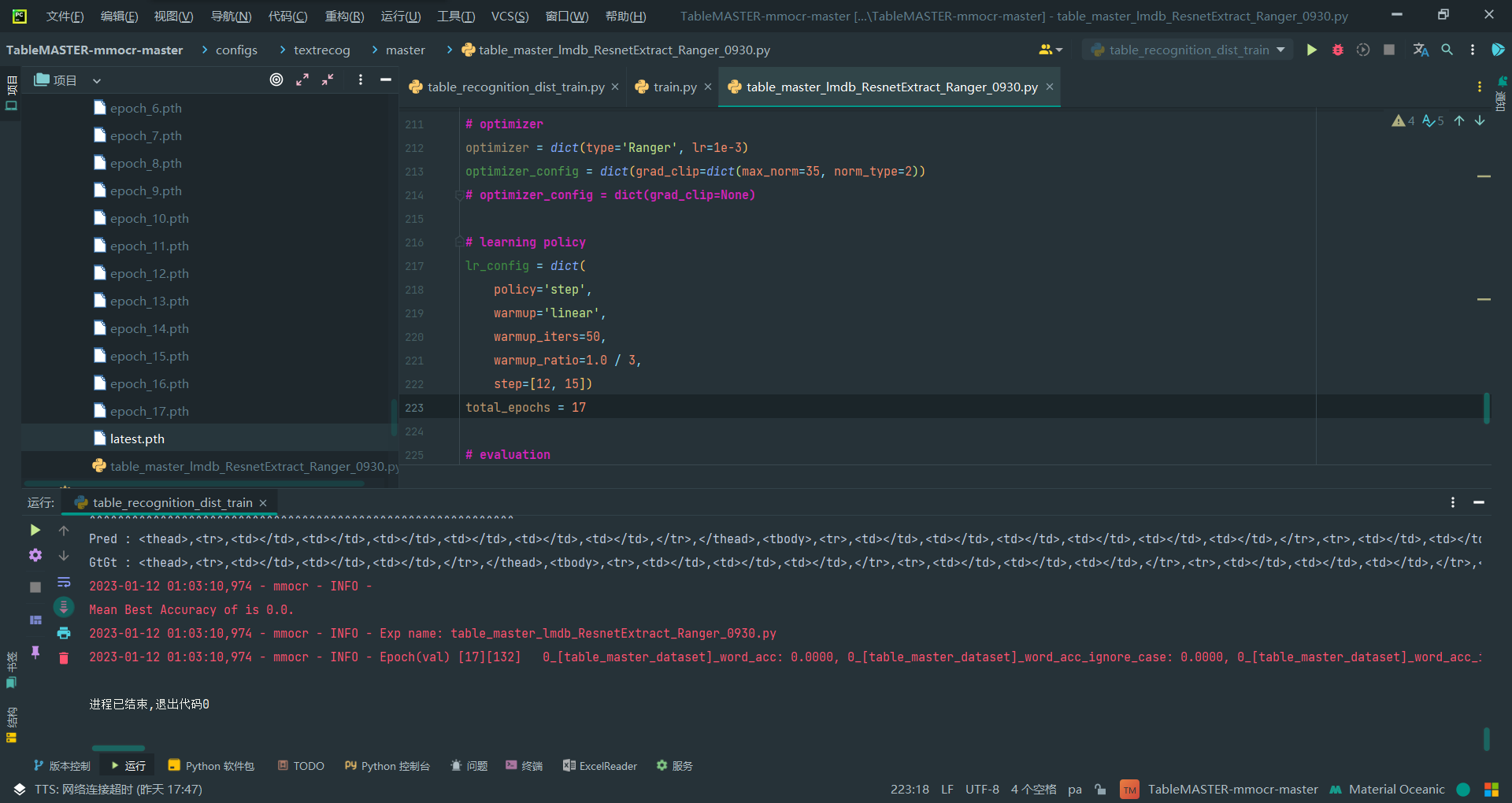
17个epoch顺利跑完
温馨提示
这个训练只是训练了表格识别模型,但是整个项目需要三个模型,这只是其一,具体识别表格见demo的运行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号