
Python基础—编码(Day2)
一、字符编码
1.ASCII码:包含英文、数字、特殊字符,8位=1字节byte =1个字符,如: 0010 1010
ASCII码表里的字符总共有256个,前128个为常用的字符如运算符,后128个称为扩展ASCII码。
2. Unicode(万国码):将所有国家的语言全部包含在这个密码本中。
初期:16位,两个字节,表示一个字符。
A : 00010000 00010010
中: 00010010 00010010
升级:32位,四个字节,表示一个字符。(32位造成资源浪费)
A : 00010000 00010010 00010000 00010010
中: 00010010 00010010 00010010 00010010
Python2x,unicode默认是两个字节表示一个字符,可以编译安装时调整。
Python3x, unicode统一是四个字节表示一个字符。
3. utf-8:最少用8位表示字符
英文:8位表示1个字符,如:00010000
欧洲:16位表示两个字节表示一个字符,如:00010000 01000100
亚洲:24位三个字节表示一个字符,如:00010000 01000100 00010000
4.GBK:国标,只包含英文、中文
英文:8位,1个字节表示一个字符,如:000 0001
中文:16位,两个字节表示一个字符,如:0000 0001 0000 0001
二、单位换算
- 8 bit = 1 byte
- 1024 byte = 1 kb
- 1024 kb = 1 MB
- 1024 MB = 1 GB
- 1024 GB = 1 TB
三、编码之间的转换
1.编码之间的二进制是互不相识的。
2.用于存储和传输的010101不能是unicode的010101。(utf-8和gbk是在unicode基础上写出来的)
3.数据类型bytes:与str的用法相同。
python3x中的str在内存中的编码方式是unicode,不能直接存储和发送,bytes的编码方式是非unicode(utf- 8、gbk.....等)。

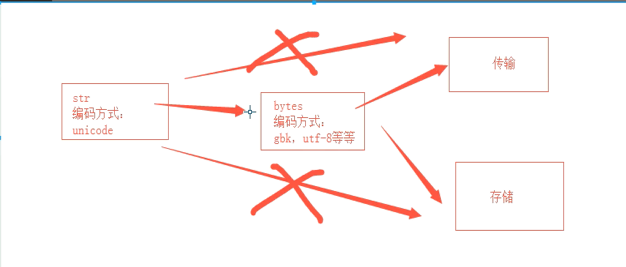
4.str与bytes类型的表现形式和内部编码
对于英文:
str 表现形式:s='laonanhai'
内部编码:unicode
bytes 表现形式:s=b'laonanhai'
内部编码:非unicode(utf-8,gbk等)
对于中文:
str 表现形式:s='中国'
内部编码:unicode
bytes 表现形式:s1=b'\xe4\xb8\xad\xe5\x9b\xbd'
内部编码:非unicode(utf-8,gbk等)
5.str与bytes之间的转换
str---->bytes s.encode('gbk') 编码
bytes---->str s.decode('gbk') 解码
s='alex' s1=s.encode('utf-8') #编码 s2=s1.decode('utf-8') #解码 print(s2)
执行结果:alex
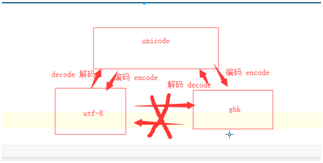
6.编码的转换
utf-8不能直接转换成gbk,要通过unicode转换
四、小数据池
int和str有小数据池,目的是为了节省空间。
1. int: -5—256在同一内存地址
2.str:如果含有特殊字符不存在小数据池。
str*int int>20不存在小数据池(单个str)
五、 is和==
==是数值的比较
is是内存地址的比较

 浙公网安备 33010602011771号
浙公网安备 33010602011771号