
进入 https://www.pearvideo.com/
随便打开一个视频,这里我打开了 https://www.pearvideo.com/video_1757324
右键该网页 检查
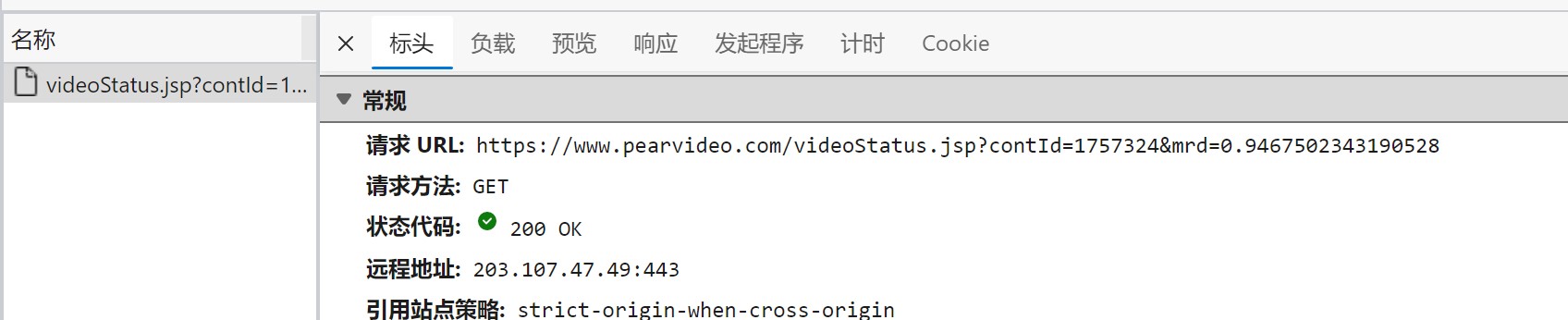
拿到 https://www.pearvideo.com/videoStatus.jsp?contId=1757324&mrd=0.9467502343190528
紧接着 点击预览返回如下JSON信息
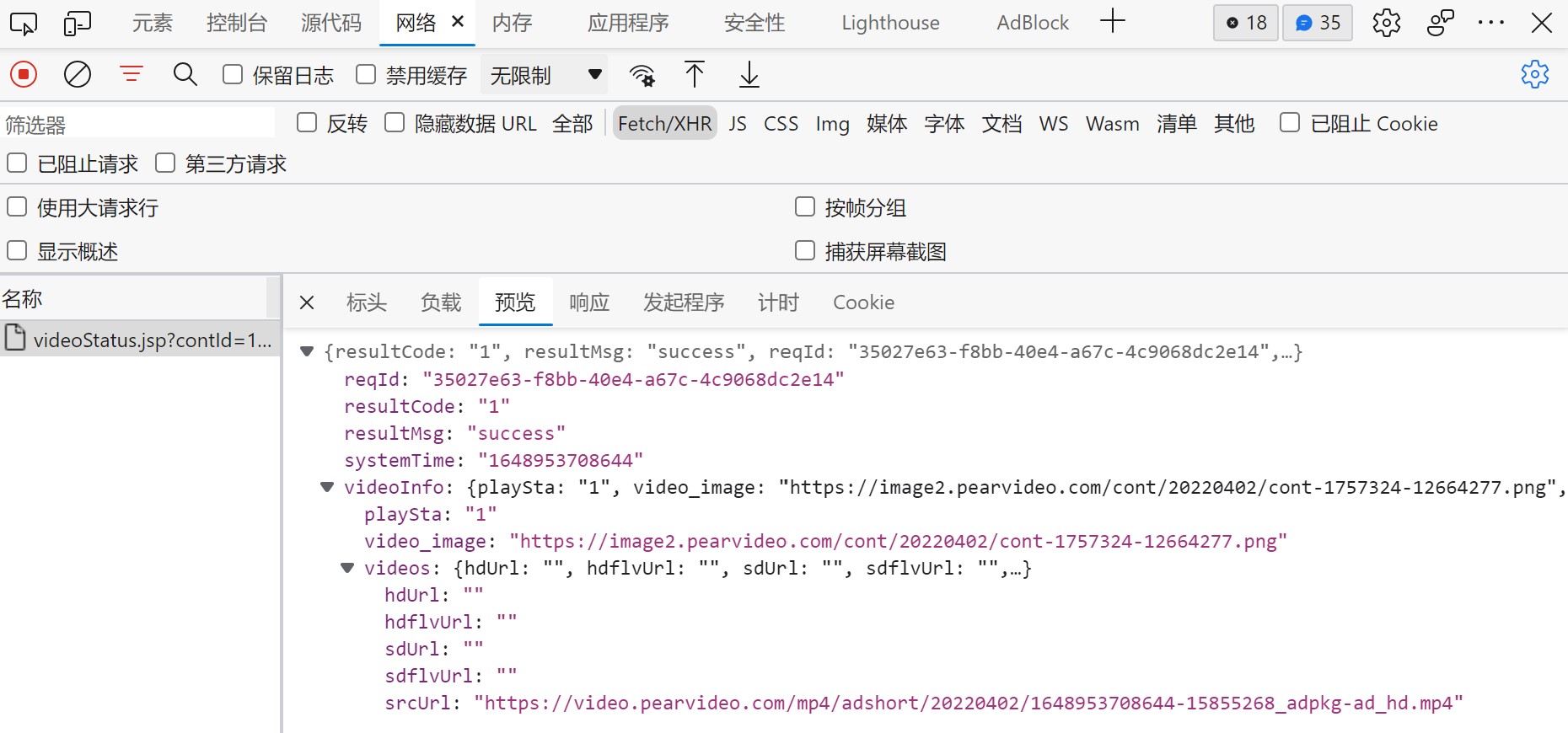
srcURL 直接打开是返回404的的。
我们 切换的元素,找到视频的URL
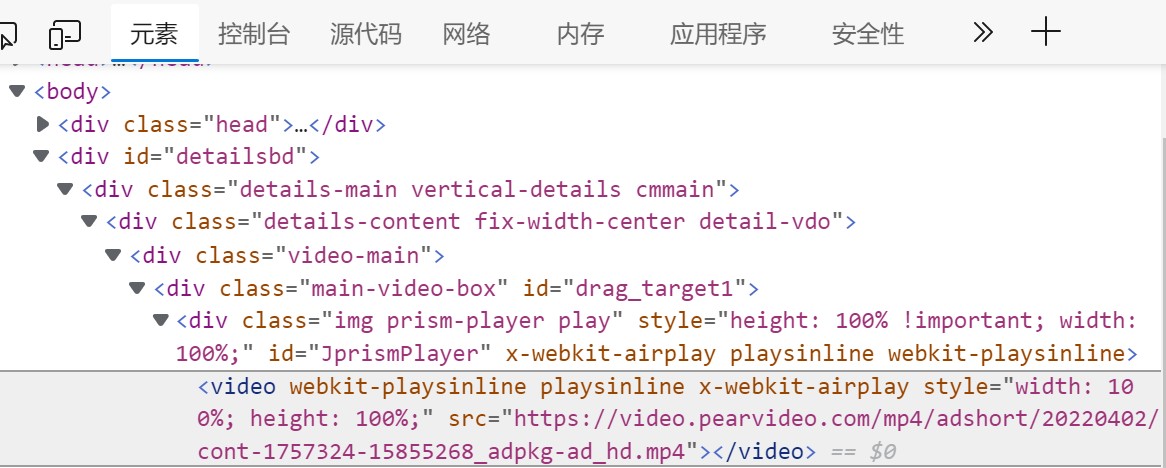
可以发现视频的URL是:https://video.pearvideo.com/mp4/adshort/20220402/cont-1757324-15855268_adpkg-ad_hd.mp4 ,这个是可以访问的
接下来我们来捋一下思路
请求https://www.pearvideo.com/videoStatus.jsp?contId=1757324&mrd=0.9467502343190528 返回了一些JSON数据
其中就包括srcURL :https://video.pearvideo.com/mp4/adshort/20220402/1648953708644-15855268_adpkg-ad_hd.mp4
而我们从元素里找到视频的url是: https://video.pearvideo.com/mp4/adshort/20220402/cont-1757324-15855268_adpkg-ad_hd.mp4
唯一不同的是 1648953708644 和 cont-1757324,前者我们称为json里的url,后者为称为元素里的url (即真实的url)
https://www.pearvideo.com/video_1757324 我们把这个url的后面数字分割下来,跟json里的url作一下拼接就可以了。
爬取思路
1, 拿到contID
2, 拿到videoStatus 返回的json. -> srcURL
3. srcURL里面的内容进行替换
4. 下载视频
import requests
from fake_useragent import UserAgent
ua = UserAgent()
# 填写基本信息
url = 'https://www.pearvideo.com/video_1757324' #目标URL
headers = {'User-Agent': ua.random,
'Referer': url} # Referer 防盗链 这里加不加你可以试一下。
contID = url.split("_")[1] # 获取 1757324
# videoStatusUrl 该URL能够返回JSON数据,根据JSON数据
videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contID}&mrd=0.9467502343190528"
resp = requests.get(videoStatusUrl, headers=headers)
dic = resp.json() # 这里必须是json哦。text是字符串,是无法使用键值对的。
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime'] # 因为返回的srcUrl 就有systemTime的值。systemTime 是用来被替换的,总不能打一串数字吧?
srcUrl = srcUrl.replace(systemTime, f"cont-{contID}") # contID 包含在目标URL
with open(f"{contID}.mp4", mode="wb") as f:
f.write(requests.get(srcUrl).content)
排版可能会不太舒服,凑合看一下吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号