

电话面试问到了HashMap里的类要实现什么方法,只知道是按哈希值查找所以查找效率很快,其它的一问三不知,现在来研究研究。
想研究研究,但是却不知道从哪里下手。。。。 汗!!!首先来咬文嚼字吧
什么是哈希值?百度了一下:哈希算法将任意长度的二进制值映射为固定长度的较小二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。。。 还是看不出和java类有什么关系。。。以前学数据结构时哈希表(也叫做散列表)这章还是很重要的,关键是那个哈希映射的哈希函数,也就是哈希算法,根据key 映射到 hash值。这个哈希函数对应到java就是 Object类中的hashCode方法:

根据这个方法的声明可知,该方法返回一个int类型的数值,并且是本地方法,因此在Object类中并没有给出具体的实现。(也就是从key 到hashcode的映射是类自己的方法实现的。。。。。 我还以为和HashMap有关。。。晕死。。。)。关于那个关键字 native :native关键字说明其修饰的方法是一个原生态方法,方法对应的实现不是在当前文件,而是在用其他语言(如C和C++)实现的文件中。Java语言本身不能对操作系统底层进行访问和操作,但是可以通过JNI接口调用其他语言来实现对底层的访问。说道这里又引出了一个新的知识点:JNI
回归正题研究hashCode()方法,现在我的疑问有两个:一是他在java的集合框架中有什么具体作用?而是 key由hashCode()方法得到哈希值,那么这个key又是什么呢?首先是第一个问题(下面这部分参考了这篇博文:http://www.cnblogs.com/szlbm/p/5806226.html):
我们知道对于java的一些集合,比如set集合,里面的元素是不允许重复的。那么当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?也许大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行。但是如果集合中已经存在一万条数据或者更多的数据,如果采用 equals方法去逐一比较,效率必然是一个问题。此时hashCode方法的作用就体现出来了,当集合要添加新的对象时,先调用这个对象的 hashCode方法,得到对应的hashcode值,实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode 值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题,这样一来实际调用 equals方法的次数就大大降低了,说通俗一点:Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的 字段等)映射成一个数值,这个数值称作为散列值。下面这段代码是java.util.HashMap的中put方法的具体实现:
public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; }
put方法是用来向HashMap中添加新的元素,从put方法的具体实现可知,会先调用hashCode方法得到该元素的hashCode 值,然后查看table中是否存在该hashCode值,如果存在则调用equals方法重新确定是否存在该元素,如果存在,则更新value值,否则将 新的元素添加到HashMap中。从这里可以看出,hashCode方法的存在是为了减少equals方法的调用次数,从而提高程序效率。
了解了hashcode在集合框架中的作用后,剩下的疑问,也就是最大的疑问便是:从key 经过hashcode()方法到 hashcode 中这个可以是什么呢?默认是以什么为基准生成哈希值的呢?这个哈希值和对象的地址有没有什么关系呢?
有些朋友误以为(比如我)默认情况下,hashCode返回的就是对象的存储地址,事实上这种看法是不全面的,确实有些JVM在实现时是直接返回对象的存储地址,但是大多时候并不是这样,只能说可能存储地址有一定关联。下面是HotSpot JVM中生成hash散列值的实现:
static inline intptr_t get_next_hash(Thread * Self, oop obj) { intptr_t value = 0 ; if (hashCode == 0) { // This form uses an unguarded global Park-Miller RNG, // so it's possible for two threads to race and generate the same RNG. // On MP system we'll have lots of RW access to a global, so the // mechanism induces lots of coherency traffic. value = os::random() ; } else if (hashCode == 1) { // This variation has the property of being stable (idempotent) // between STW operations. This can be useful in some of the 1-0 // synchronization schemes. intptr_t addrBits = intptr_t(obj) >> 3 ; value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom ; } else if (hashCode == 2) { value = 1 ; // for sensitivity testing } else if (hashCode == 3) { value = ++GVars.hcSequence ; } else if (hashCode == 4) { value = intptr_t(obj) ; } else { // Marsaglia's xor-shift scheme with thread-specific state // This is probably the best overall implementation -- we'll // likely make this the default in future releases. unsigned t = Self->_hashStateX ; t ^= (t << 11) ; Self->_hashStateX = Self->_hashStateY ; Self->_hashStateY = Self->_hashStateZ ; Self->_hashStateZ = Self->_hashStateW ; unsigned v = Self->_hashStateW ; v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)) ; Self->_hashStateW = v ; value = v ; } value &= markOopDesc::hash_mask; if (value == 0) value = 0xBAD ; assert (value != markOopDesc::no_hash, "invariant") ; TEVENT (hashCode: GENERATE) ; return value; }
因此可以直接根据hashcode值判断两个对象是否相等吗?肯定是不可以的,因为不同的对象可能会生成相同的hashcode值。虽然不能根据hashcode值判断两个对象是否相等,但是可以直接根据hashcode 值判断两个对象不等,如果两个对象的hashcode值不等,则必定是两个不同的对象。如果要判断两个对象是否真正相等,必须通过equals方法。
也就是说对于两个对象,如果调用equals方法得到的结果为true,则两个对象的hashcode值必定相等;
如果equals方法得到的结果为false,则两个对象的hashcode值不一定不同;
如果两个对象的hashcode值不等,则equals方法得到的结果必定为false;
如果两个对象的hashcode值相等,则equals方法得到的结果未知
说到这里要注意一点的就是:有些情况下,程序设计者在设计一个类的时候为需要重写equals方法,比如String类,但是千万要注意,在重写equals方法的同时,必须重写hashCode方法。这里就涉及到hashCode()方法是默认以什么来映射。对于基本数据类型,如String,double等,默认以它的 value值作为参数然后进行运算得出hashcode。对于对象,hashCode 默认返回对象在JVM中的存储地址(不是实际的内存物理地址),也就是说如果对象不重写该方法,则返回相应对象的32为JVM内存地址。查了下jdk文档,发现不同的类实现hashCode的方法不同。对于我们自己定义的类,如果我们重写equals方法为:只要里面的字段相等便判定这两个对象相等。 那么在集合存取的时候,因为会首先判断他们的hashcode是否相等,相等的情况下才会用equals方法判断,所以如果我们不重写hashCode方法的话,即使两个对象字段值一致但是由于地址不同hascode便不同,这样集合就不会断定他们是相同的。所以要重写hashCode方法,让equals方法和hashCode方法始终在逻辑上保持一致性。
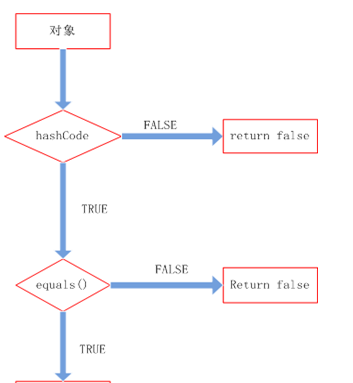
这里顺便贴一下http://www.cnblogs.com/xudong-bupt/p/3960177.html 这篇博客的一些总结:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号