关于模拟退火
随机数的生成
一、随机数
现有的计算机的运算过程都是确定性的,因此,仅凭借算法 来生成真正 不可预测、不可重复 的随机数列是不可能的。
然而在绝大部分情况下,我们都不需要如此强的随机性,而只需要所生成的数列在统计学上具有随机数列的种种特征(比如均匀分布、互相独立等等)。这样的数列即称为 伪随机数 序列。
OI/ICPC 中用到的随机算法,基本都只需要伪随机数。这是因为,这些算法往往是 通过引入随机数来把 概率 引入复杂度分析,从而 降低复杂度。这本质上依然只利用了随机数的 统计 特征。
二、随机数的实现
1. rand()
生成伪随机数的算法,较慢。需要 #include <cstdlib>。
调用 rand() 函数会返回一个 [0, RAND_MAX] 中的随机 非负整数,其中 RAND_MAX 是标准库中的一个宏,在 Linux 系统下 RAND_MAX 等于 \(2^{31} - 1\)。可以用 取模 来限制所生成的数的大小。
使用 rand() 需要一个随机数 种子,可以使用 srand(seed) 函数来将随机种子更改为 seed,当然不初始化也是可以的。
同一程序使用 相同的 seed 两次运行,在同一机器、同一编译器下,随机出的结果将会是 相同 的。
有一个选择是使用 当前系统时间 来作为随机种子:srand(time(0))。
- 在 Windows 系统下
RAND_MAX为 \(2^{15} - 1\) ,当需要生成的数不小于 \(2^{15} - 1\) 时建议使用(rand() << 15 | rand())来生成更大的随机数。
2. mt19937
是一个随机数生成器类,效用同 rand(),随机数的范围同 unsigned int 类型的取值范围。需要 #include<random>。
优点:
随机数 质量高(一个表现为,出现循环的周期更长;其他方面也都至少不逊于 rand()),且 速度比 rand() 快 很多。
使用方法:
std::mt19937 myrand(seed),seed 可不填,不填 seed 则会使用默认随机种子。
mt19937 重载了 operator (),需要生成随机数时调用 myrand() 即可返回一个随机数。
- 若需要将随机数范围扩大到
unsigned long long类型的取值范围,可以使用mt19937_64,使用方法同mt19937。
代码示例:
#include <ctime>
#include <iostream>
#include <random>
using namespace std;
int main() {
mt19937 myrand(time(0));
cout << myrand() << '\n';
return 0;
}
3. random_device(生成真随机数)
random_device 是一个基于 硬件 的均匀分布随机数生成器,在熵池耗尽前 可以高速生成随机数。该类在 C++11 定义,需要 #include <random>。
由于熵池耗尽后性能急剧下降,所以建议用此方法生成 mt19937 等伪随机数的 种子,而不是直接生成。
4. 规定随机数分布的范围与概率
不明觉厉
| 类名 | 分布概率 | 数据类型 |
|---|---|---|
uniform_int_distribution |
等概率分布 | 整数 |
uniform_real_distribution |
等概率分布 | 实数 |
bernoulli_distribution |
伯努利分布 | 布尔 |
binomial_distribution |
二项分布 | 整数 |
negative_binomial_distribution |
负二项分布 | 整数 |
geometric_distribution |
几何分布 | 整数 |
poisson_distribution |
泊松分布 | 整数 |
exponential_distribution |
指数分布 | 实数 |
gamma_distribution |
\(\gamma\) 分布 | 实数 |
weibull_distribution |
威布尔分布 | 实数 |
extreme_value_distribution |
极值分布 | 实数 |
normal_distribution |
标准正态(高斯)分布 | 实数 |
lognormal_distribution |
对数正态分布 | 实数 |
chi_squared_distribution |
\(\chi^2\) 分布 | 实数 |
cauchy_distribution |
柯西分布 | 实数 |
fisher_f_distribution |
费舍尔 F 分布 | 实数 |
student_t_distribution |
学生 t 分布 | 实数 |
discrete_distribution |
离散分布 | 整数 |
piecewise_constant_distribution |
分布在常子区间上 | 实数 |
piecewise_linear_distribution |
分布在定义的子区间上 | 实数 |
5. 代码
生成 \([l, r]\) 范围内的 \(n\) 个随机整 / 实数:
#include <cstdio>
#include <random>
using namespace std;
typedef double db;
random_device R; //定义生成种子的类
mt19937 gen(R()); //定义生成随机数的类
inline int dgrand(int l, int r) {
uniform_int_distribution<> dis(l,r); //生成随机整数的范围
return dis(gen);
}
inline db dbrand(db l, db r) {
uniform_real_distribution<> dis(l,r); //生成随机实数的范围
return dis(gen);
}
int main() {
int n;
db l, r;
scanf("%d%lf%lf", &n, &l, &r);
for (int i = 1; i <= n; i++) {
printf("%d%c", dgrand(l, r), "\n "[(bool)(i % 10)]); //l和r自动向下取整了
}
putchar('\n');
for (int i = 1; i <= n; i++) {
printf("%.6lf%c", dbrand(l, r), "\n "[(bool)(i % 10)]);
}
return 0;
}
参考资料
模拟退火 (Simulated Annealing, SA)
一、介绍
模拟退火是一种玄学的经典的随机化全局搜索算法。
模拟退火适用的问题通常是一些求最优解的问题,换言之就是求一个 连续函数的最值。
一般这种问题只需要求一个最优解,而到达这个最优解的路径并不重要;朴素的搜索需要遍历所有的解的可能,这些解构成的解空间又太大,没办法在时间限制内全部遍历搜索。
如果在函数的值域上朴素随机,找到这个最值点的概率是很小的。
由于函数具有连续的性质,我们可以简单的直接向更大或者更小的方向不断移动,但显然这样我们可能找到一个 极值而非最值 点。
科学家们发现,物理学上物体退火降温的微观过程也是粒子不断随机跳动的过程,但是物体冷却后粒子却总是能处于最低的能量状态,所以我们可以模拟退火这个物理过程来求函数的最值。
二、思路
我们引入一个初始温度 \(T_0\)、温度变化率 \(\Delta T\) 和终止温度 \(T_k\),其中 \(T_0\) 是一个较大的正数,\(\Delta T\) 是一个略小于 \(1\) 的正数,\(T_k\) 是一个略大于 \(0\) 的正数。
开始时温度 \(T = T_0\),每次将 \(T \leftarrow T \times \Delta T\),直到 \(T \leq T_k\) 结束算法,来模拟一个降温的过程。
假设我们当前选择解的位置是 \(x\),温度 \(T\) 代表了我们每次选的新解位置在 \(x\) 周围的跨度大小。具体来说,我们每次需要在一定范围内随机一个参数 \(\Delta x\),然后比较 \(f(x + \Delta x)\) 和 \(f(x)\) 的大小。
令 $ f(x + \Delta x) - f(x) = \Delta E$。
如果 \(f(x + \Delta x)\) 比 \(f(x)\) 更优,即 \(\Delta E < 0\),那么我们 直接接受更优的解。
如果 \(\Delta E > 0\),我们 有一定概率接受新的解,这个概率是 \(\text{e}^{-\Delta E / T}\)。新的解越差,\(\Delta E\) 越大,这个概率越小;温度 \(T\) 越低,这个概率越小。
每次重复这个过程,直到温度趋于零(或者一个设定好的下限)。
形象的演示:
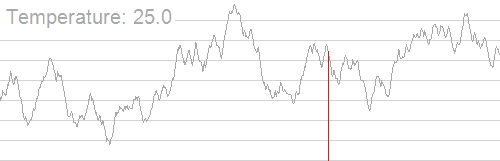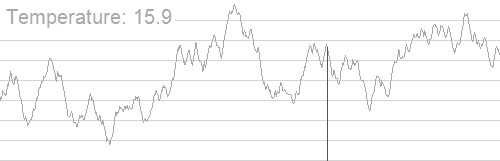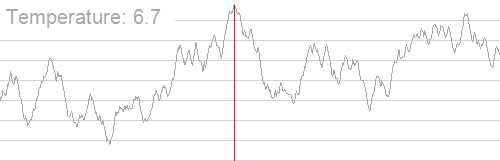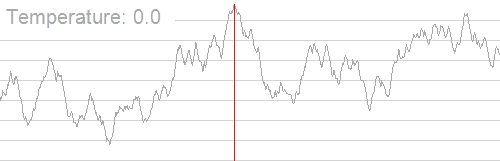
时间复杂度 O(玄学)。
三、调参
模拟退火时有三个参数,分别是初始温度 \(T_0\)、降温系数 \(\Delta T\)、终止温度 \(T_k\)。
一般将 \(T_0\) 设置在 \(1000\) ~ \(5000\) 左右,\(\Delta T\) 设置在 \(0.95\) ~ \(0.999\) 之间, \(T_k\) 设置在 \(10^{-8}\) ~ \(10^{-15}\) 之间。
如果答案不是最优,有以下几种方法来优化:
-
调大 \(\Delta T\)、调整 \(T_0\) 和 \(T_k\)、多跑几遍模拟退火,从而增大得到最优解的概率;
-
尝试更换随机数种子,或者
srand(rand()); -
洗把脸再交一(亿)遍
四、Tricks
-
一般情况下我们不会选取最终的解作为答案,而是在退火过程中不断记录一个全局最优的答案;
-
一般情况下我们可以重复多次模拟退火的过程,来避免落入一个极值区间跨不出来的随机情况;
-
在不会 TLE 的情况下尽量多地跑模拟退火:
我们知道,有一个clock()函数,返回程序运行时间,那么这样即可:
while ((double)clock()/CLOCKS_PER_SEC<MAX_TIME) SA();
其中MAX_TIME是一个自定义的略小于题目时间限制的数;
-
有时函数的峰很多,模拟退火难以跑出最优解,可以把整个值域分成几段,每段跑一遍模拟退火,然后再取全局最优解;
-
有时为了使得到的解更有质量,会在模拟退火结束后,以当前温度在得到的解附近多次随机,以尝试得到更优的解。
五、例题(一)求函数最值
1. UVa10228 A Star not a Tree?
题意:给定二维平面上的 \(n\) 个点,求一个点使得该点到所有点距离之和最小(费马点)。
思路:赤果果的模拟退火模板题,具体请看代码注释。注意每组数据之间输出空行!
参考代码:
https://www.luogu.com.cn/paste/wdkwgtq9
2. [JSOI2004] 平衡点 / 吊打XXX
题意:给定平面上 \(n\) 个点的坐标和权值,求一个点使得该点到所有点的 距离与权值乘积 之和最小(相当于带权费马点)。
思路:与第 (1) 题类似,只是引入了权值。
参考代码:
https://www.luogu.com.cn/paste/t353wll8
3. [JSOI2016]炸弹攻击1
题意:在平面上有一些点和无重合面积的圆,求平面上的一个圆,使该圆覆盖最多的点,且与平面上的任意一个圆无重合面积。无重合面积是指不能有重合部分但可以相切。
思路:对所求的圆的圆心坐标进行退火,暴力计算每一个坐标所能覆盖的最多的点数。
参考代码:
https://www.luogu.com.cn/paste/6gypilfv
六、例题(二)求序列
一般用于数据范围较小,但爆搜会超时的情况。虽然不经典但好用
1. [TJOI2010]分金币
题意:多组数据。给定 \(n\) 个数 \(a_1, a_2,\dots,a_n\),将这些数分成大小为 \(\left\lfloor \dfrac{n}{2} \right\rfloor\) 和 \(\left\lfloor \dfrac{n + 1}{2} \right\rfloor\) 的两组,使这两组数之和的差的绝对值最小。
数据范围: \(1 \leq T \leq 20,1 \leq n \leq 30,1 \leq v_i \leq 2^{30}\)
思路:分别从两组数,即 a[1 .. n/2] 和 a[n/2+1 .. n] 中各随机抽取一个数并交换,比较交换前和交换后的两组数之和的差的绝对值。
参考代码:
https://www.luogu.com.cn/paste/cjqzk2tl
2. [HAOI2006]均分数据
题意:给定 \(n\) 个数 \(a_1,a_2,\dots,a_n\),将其分成 \(m\) 组,使得这 \(m\) 组数的均方差
最大。其中 \(x_i\) 为第 \(i\) 组数的和。
数据范围:\(m \leq n \leq 20\),且 \(2 \leq m \leq 6\)。
思路:爆搜枚举每一种情况会超时,数学方法又不会,只好搞玄学的优雅的暴力——模拟退火。
首先考虑对于给定顺序的序列,如何使均方差最小?显然(意思是不会证)把当前数放到和最小的一组数中可以使答案最小。因此可以用模拟退火将序列顺序随机打乱(随机交换两个数即可,或者可以用 random_shuffle),求出最优答案。
参考代码:
https://www.luogu.com.cn/paste/ygvn01ph
3. Coloring
题意:
给定 \(n\) 行 \(m\) 列的方格,用 \(m\) 种颜色将每个方格染上一种颜色。染色方案满足:
- 第 \(i\) 种颜色占 \(p_i\) 个方格,数据满足 \(\sum p_i = n \times m\);
- 将每个格子上下左右与其颜色相同的格子视为位于同一个联通块内,定义不同联通块之间的方格边的条数为 \(q\),则该种方案是使 \(q\) 尽量小的一种方案。
由于可能存在不止一种方案,只需要输出任意一种方案即可。
约定:
本题采用 SPJ。对于每个测试点,将会设置阈值 \(w\),并保证存在构造使得 \(q \leq w\)。
对于程序输出的答案,我们将会以以下方式计算得分:
| \(q\) | \(\text{score}\) | \(q\) | \(\text{score}\) |
|---|---|---|---|
| \(q \leq w\) | \(10\) | \(1.75w < q \leq 2w\) | \(5\) |
| \(w < q \leq 1.1w\) | \(9\) | \(2w < q \leq 2.3w\) | \(4\) |
| \(1.1w < q \leq 1.25w\) | \(8\) | \(2.3w < q \leq 2.6w\) | \(3\) |
| \(1.25w < q \leq 1.5w\) | \(7\) | \(2.6w < q \leq 3w\) | \(2\) |
| \(1.5w < q \leq 1.75w\) | \(6\) | \(3w < q \leq 3.5w\) | \(1\) |
若 \(q > 3.5w\),将以 Wrong Answer 处理。
数据范围:
对于 \(10\%\) 的数据,有 \(1\leq n,m\leq 3,c\leq 3\)。
对于 \(30\%\) 的数据,有 \(1\leq n,m\leq 8,c\leq 6\)。
对于 \(50\%\) 的数据,有 \(1\leq n,m\leq 15,c\leq 25\)。
对于 \(100\%\) 的数据,有 \(1\leq n,m\leq 20,c\leq 50,p_i\leq 20\)。
思路:
首先将所有方格按要求按顺序(也可以不按顺序)填色,计算初始的 \(q\)。然后在退火过程中随机打乱颜色顺序,计算此时的 \(q\)。不断退火得到尽量优的 \(q\)。
参考代码:
https://www.luogu.com.cn/paste/df2utwz6
4. [SCOI2008]城堡
题意:
图中有 \(n\) 个城市(编号 \(0\) ~ \(n - 1\)),\(n\) 条双向道路,第 \(i\) 条道路连接了城市 \(i\) 和城市 \(r_i\),道路长为 \(d_i\)。\(n\) 个城市中有 \(m\) 个城市中有城堡。定义一个城市的 \(\text{dis}\) 为距它最近的城堡到它的距离。你可以在 剩下没有城堡的 \(n-m\) 个城市中的不超过 \(k\) 个城市 建城堡,使得 \(\max\{\text{dis}\}\) 最小。
数据范围:\(2\leq n\leq 50,1\leq d_i\leq 10^6,0\leq m\leq n−k\)。
思路:
显然多建城堡一定比少建城堡更优,所以只需考虑建 \(k\) 座城堡的情况。在没有城堡的 \(n - m\) 个城市中随机选 \(k\) 个建城堡,每次随机改变要建城堡的城市,进行模拟退火。
参考代码:
https://www.luogu.com.cn/paste/dffsztny
