
第一次爬虫与测试
一、程序测试
测试球赛程序中的所有函数,并输出测试结果
1、测试printInfo()(程序的介绍性信息)
代码如下:
def printInfo(): print("这个程序模拟两个选手A和B的羽毛球竞技比赛") print("程序需要两个选手的能力值0-1") print("规则:三局两胜--21分制") printInfo()
二.HTML页面的简单操作
import requests from bs4 import BeautifulSoup soup = BeautifulSoup("<!DOCTYPE html><html><head><meta charset=‘utf-8‘>\ <title菜鸟教程(rounoob.com)</title></head><body>\ <h1>我的第一标题</h1>\ <p id='first'>我的第一个段落。</p></body>\ <table border=‘1‘><tr><td>row 1,cell 1\ </td><td>row 1,cell 2</td></tr><tr><td>row 2,cell 1\ </td><td>row 2,cell 2</td></tr</table></html>") print(soup.head,"06") #获取并打印head标签的内容和学号后两位 print(soup.body) #获取并打印body的内容 print(soup.find_all(id="first")) #获取并打印id为first的文本 print(soup.h1.string,soup.p.string) #获取并打印html页面中的中文字符
结果:
三.测试getInput()(输入参数)
代码如下:
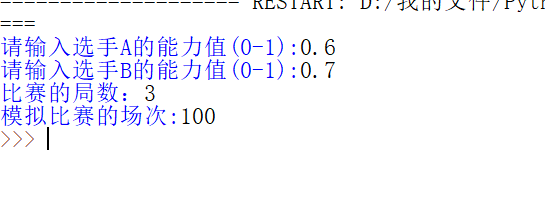
def getInput(): a = eval(input("请输入选手A的能力值(0-1):")) b = eval(input("请输入选手B的能力值(0-1):")) m=eval(input("比赛的局数:")) n = eval(input("模拟比赛的场次:")) return a,b,m,n getInput()
结果是:
二、爬取中国大学排名
from bs4 import BeautifulSoup import requests import pandas as pd allUniv = [] def getHTMLText(url): try: r = requests.get(url, timeout=10) r.raise_for_status() r.encoding = 'utf-8' return r.text except: return "" def filUnivList(soup): data = soup.find_all('tr') for tr in data: ltd = tr.find_all('td') if len(ltd) == 0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) write_csv(allUniv) def write_csv(list): name = ['排名', '学校名称', '省份', '总分', '生源质量(新生高考成绩得分)', '培养结果(毕业生就业率)', '社会声誉(社会捐赠收入·千元)', '科研规模(论文数量·篇)',\ '科研质量(论文质量·FWCI)', '顶尖成果(高被引论文·篇)', '顶尖人才(高被引学者·人)', '科技服务(企业科研经费·千元)', '成果转化(技术转让收入·千元)', '学生国际化(留学生比例)'] name2 = ['a', 'b', 'c'] test = pd.DataFrame(columns=name, data=list) test.to_csv('e:/testcsv.csv', encoding='gbk') def main(): url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html' html = getHTMLText(url) soup = BeautifulSoup(html, "html.parser") filUnivList(soup) print("完成") main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号