Python函数基础
函数声明、调用、返回基础
Python中使用def关键字来声明函数,声明函数的格式为:
def func_name(args):
...body...
[return ...]
有3个需要注意的地方:
- 函数名后面必须加冒号
- 如果函数体和def不在同一行,则必须缩进
- return指定函数返回值,用来结束函数
- 但return语句是可有可无的,如果不给return,则等价于加上了
return None,即函数默认返回None结构
- 但return语句是可有可无的,如果不给return,则等价于加上了
如果函数体body语句只有一行,或者可以简写为一行,则可以写在def的同行。例如:
def myfunc(x,y,z): print(x+y+z)
函数声明好之后,就可以执行函数,执行函数也称为调用函数,方式为func_name(args),例如:
myfunc(1,2,3)
函数中往往会包含一个return或多个return语句,它可以出现在函数中的任意位置处,它用来结束函数的执行,并返回给定的值。例如:
def func(x):
return x+5
表示返回x+5的值,返回值是一种值类型,所以可以赋值给变量、可以输出、可以操作等等。例如:
print(func(3)) # 输出返回值
a=func(4) # 赋值给变量
print(a)
print(func(5)+3) # 数值操作
return语句是可选的,如果函数中不指定return语句,则默认返回None,即类似于return None。
关于函数参数
函数的参数其实也是变量,只不过这些变量是独属于函数的本地变量,函数外部无法访问。在函数调用的时候,会将给定的值传递给函数的参数,这实际上是变量赋值的过程。
def myfunc(x,y,z):
print(x,y,z)
myfunc(1,2,3)
def首先声明好函数,然后到了myfunc(1,2,3)时,表示调用函数(执行函数),调用函数时会将给定的值1,2,3传递给函数的参数x,y,z,其实就是变量赋值x=1,y=2,z=3,然后使用print输出它们。
由于python是动态语言,无需先声明变量,也无需指定变量的类型,所以python的函数参数和返回值非常的灵活。任何类型的变量或数据结构都可以传递给参数,这实际上是变量赋值的过程。例如:
myfunc(1,2,3)
myfunc("abc",2,"def")
myfunc([1,2,3],4,5)
上面几个函数调用语句中,赋值给参数的值可以是数值类型,可以是字符串类型,可以是列表类型,也可以是其它任何数据类型。
python函数的参数相比其它语言要复杂一些,意味着要灵活很多,短短一个小节的篇幅完全没法解释清楚,关于参数细节,详细内容见后面的文章。
函数声明、调用的过程详述
def用来声明一个函数,python的函数包括函数名称、参数、函数体、函数体中涉及到的变量、返回值。
实际上,函数名称其实是一个变量名,def表示将保存在某块内存区域中的函数代码体赋值给函数名变量。例如:
def myfunc(x,y,z):
...CODE...
上面表示将函数体赋值给变量名myfunc。如下图:
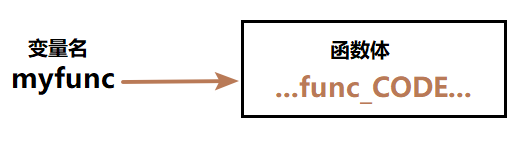
既然是变量,就可以进行输出:
def myfunc(x):
return x+5
print(myfunc)
输出结果:
<function myfunc at 0x032EA6F0>
由于python是解释型语言,所以必须先定义函数,才能调用函数。
如果导入一个模块文件,导入的时候会解释、执行文件中的代码,包括def语句,也就是说,导入文件时会先声明好函数。
函数变量的细节
请一定理解本节内容,也许细节方面可能会有些不准确,但对于深入理解函数来说(不仅限于python语言),是非常有帮助的,特别是理解作用域规则的时候。
python是解释性语言,读一行解释一行,解释一行忘记一行。而函数是一种代码块,代码块是一个解释单元,是一个整体。在代码块范围内不会忘记读取过的行,也不会读一行就立即解释一行,而是读取完所有代码块内的行,然后统筹安排地进行解释。关于这一点,在后面的文章代码块详述中有非常详细的解释,建议一读。
当python读取到def所在行的时候,知道这是一个函数声明语句,它有一个属于自己的代码块范围,于是会读完整个代码块,然后解释这个代码块。在这个解释过程中,会记录好变量以及该变量的所属作用域(是全局范围内的变量还是函数的本地变量),但一定注意,def声明函数的过程中不会进行变量的赋值(参数默认值除外,见下文),只有在函数调用的时候才会进行变量赋值。换句话说,在def声明函数的过程中,在函数被调用之前,函数所记录的变量一直都是变量的地址,或者通俗一点理解为记录变量的名称,而不会进行变量的赋值替换。
实际上,变量的明确的值会当作常量被记录起来。如a=10的10被作为常量,而变量a赋值给变量b时b=a,a显然不会作为常量。
如下函数:
x=3
def myfunc(a,b):
c=10
print(x,a,b,c)
myfunc(5,6)
输出结果为:"3 5 6 10"。
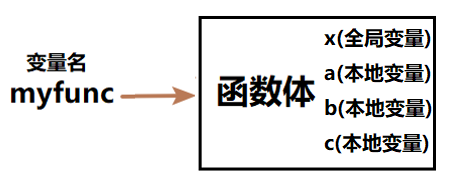
上面的函数涉及到了4个变量:a、b、c、x。其中:
- 全局变量x
- 本地变量a、b、c,其中本地变量a和b是函数的参数
在def的过程中,会完完整整地记录好这些变量以及所属作用域,但只会记录,不会进行变量的赋值。如下图:
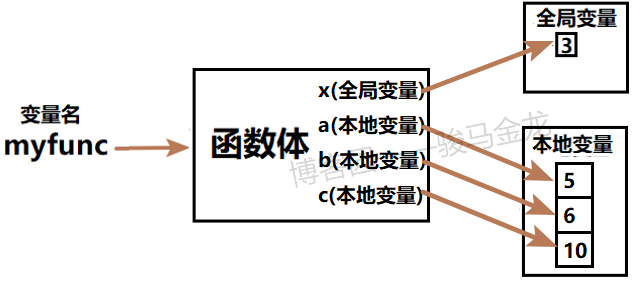
然后函数被调用,这时候才会开始根据记录的作用域搜索变量是否存在,是否已经赋值(非本地变量),并对需要赋值的变量赋值:
- 查找全局变量变量x,它在全局作用域内已经赋值过了,所以只需找到这个全局变量即可
- 查找本地变量a、b、c,它们是属于函数myfunc的本地变量,而a和b是参数变量,所以最先对它们进行赋值
a=5,b=6,然后赋值普通的本地变量c=10
如图:
最后执行print(x,a,b,c)输出这些变量的值。
还需注意,python是读一行解释一行的,在函数调用过程中,因为c=10在print()的前面,所以是先赋值c=10,再执行print,如果print在c=10前面,则先执行print,再赋值,这显然是错误的,因为print()中使用了变量c,但目前还没有对其赋值。这和其它语言可能有些不同(特别是编译型语言),它们可能会无视变量赋值以及变量使用的位置前后关系。
如果上面的示例中,函数myfunc调用之前,将变量x赋值为另一个值:
x=3
def myfunc(a,b):
c=10
print(x,a,b,c)
x=33
myfunc(5,6)
这时将输出:"33 5 6 10"。因为x是全局变量,只有在函数调用的时候才会去找到变量x对应的值,而这时全局变量的值已经是33。
匿名函数lambda
匿名函数是指没有名称的函数,任何编程语言中,匿名函数都扮演着重要角色,它的功能非常灵活,但是匿名函数中的逻辑一般很简单,否则直接使用命名函数更好,匿名函数常用于回调函数、闭包等等。
在python中使用lambda关键字声明匿名函数,python中的lambda是一个表达式而不是一个语句,这意味着某些语句环境下可能无法使用def声明函数,但却可以使用lambda声明匿名函数。当然,匿名函数能实现的功能,命名函数也以一样都能实现,只不过有时候可能会比较复杂,可读性会更差。
lambda声明匿名函数的方式很简单,lambda关键字后面跟上参数列表,然后一个冒号,冒号后跟一个表达式。
lambda argl, arg2,... argN :expression statement
lambda表达式返回一个匿名函数,这个匿名函数可以赋值给一个变量。
例如:
# 声明匿名函数,并赋值给变量f
f = lambda x,y,z: x+y+z
print(f)
输出结果:
<function <lambda> at 0x027EA6F0>
既然匿名函数赋值给了变量,这个函数就像是命名变量一样,可以通过这个变量去调用这个匿名函数。当然,它毕竟还是匿名函数,正如上面输出的结果中function <lambda>所示。而且,匿名函数并非一定要赋值给变量。
# 调用匿名函数
print(f(2,3,4)) # 输出9
匿名函数的返回值是冒号后面的表达式计算得到的结果。对于上面的示例,它等价于return x+y+z。
因为lambda是一个表达式,所以可以写在任何表达式可以出现的位置处,而某些语句上下文环境中,并不能直接使用def来声明。例如,将函数保存到一个列表中:
L=[ lambda x: x * 2,
lambda x: x * 3,
lambda x: x * 4 ]
print(L[0](2))
print(L[1](2))
print(L[2](2))
上面的lambda出现在列表的内部,且这里面的匿名函数并赋值给某个变量。像def语句就无法出现在这样的环境中,如果真要使用def来声明函数,并保存到列表中,只能在L的外部使用def定义,然后将函数名来保存。
def f1(x): return x * 2
def f2(x): return x * 3
def f3(x): return x * 4
L=[f1,f2,f3]
print(L[0](2))
print(L[1](2))
print(L[2](2))
看上去没什么问题,但函数定义的位置和列表L定义的位置可能会相差甚远,可读性可能会非常差。
同理的,还可以将匿名函数保存在字典的value位置上:
key='four'
print(
{
'two':(lambda x: x * 2),
'three':(lambda x: x * 3),
'four':(lambda x: x * 4)
}[key](2)
)
函数嵌套
函数内部可以嵌套函数。一般来说,在函数嵌套时,内层函数会作为外层函数的返回值(当然,并非必须)。既然内层函数要作为返回值,这个嵌套的内层函数更可能会是lambda匿名函数。
例如:
def f(x):
y=10
def g(z):
return x+y+z
return g
上面的函数f()中嵌套了一个g(),并返回这个g()。其实上面示例中的g()是一个闭包函数。
既然f()返回的是函数,这个函数可以赋值给其它变量,也可以直接调用:
# 将嵌套的函数赋值给变量myfunc
# 这时myfunc()和g()是等价的
myfunc = f(3)
print( myfunc(5) )
# 直接调用g()
print( f(3)(5) )
当然,嵌套lambda匿名函数也可以,且更常见:
def f(x):
y=10
return lambda z: x+y+z
嵌套在循环内部的函数
看下面嵌套在循环内部的函数,在每个迭代过程中都声明一个匿名函数,这个匿名函数返回循环控制变量i,同时将声明的匿名函数保存到列表L中。
def f():
L=[]
for i in range(5):
L.append( lambda : i )
return L
但如果调用该函数f(),并调用保存在列表中的每个匿名函数,会发现它们的值完全相同,且都是循环迭代的最后一个元素值i=4。
List = f()
print(List[0]())
print(List[1]())
print(List[2]())
print(List[3]())
print(List[4]())
执行结果:
4
4
4
4
4
为什么会如此?为什么循环迭代过程中的i没有影响到匿名函数的返回值?这是一个非常值得思考的问题,如果不理解结果,请仔细回顾前文函数变量的细节。如果还是不理解,请阅读Python作用域详述。
嵌套函数的作用域
此处给几个示例,这些示例的结果对于只学过python的人来说,可能会很容易理解,但对于学过其它语言的人来说,很容易混淆出错。
此处并不会对这些示例的结果进行解释,因为只要理解了前文函数变量的细节,这几个示例的结果很容易理解。
同样,更详细的内容参见Python作用域详述。
如下示例:
x=3
def f():
x=4
g()
print("f:",x)
def g():
print("g:",x)
f()
输出:
g: 3
f: 4
如果在调用函数前,修改全局变量x的值:
x=3
def f():
x=4
g()
print("f:",x)
def g():
print("g:",x)
x=6
f()
输出:
g: 6
f: 4
如果把g()的声明放在f()的内部呢?
x=3
def f():
x=4
def g():
print("g:",x)
print("f:",x)
x=5
return g
f()()
输出:
f: 4
g: 5
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号