Perl正则表达式超详细教程
前言
想必学习perl的人,对基础正则表达式都已经熟悉,所以学习perl正则会很轻松。这里我不打算解释基础正则的内容,而是直接介绍基础正则中不具备的但perl支持的功能。关于基础正则表达式的内容,可参阅基础正则表达式。
另外,本系列只介绍匹配操作,关于内容替换,因为和学习使用perl正则并无多大关系,所以替换相关的将在下一篇文章单独解释。
这里推荐一个学正则非常好的资料:stackflow上关于各种语言(perl/python/.net/java/ruby等等)的正则的解释、示例,这里收集的都是对问题解释的非常清晰且非常经典的回答。在我学习perl正则的时候,对有些功能实在理解不了(想必你也一定会),就会从这里找答案,而它,也从来没让我失望:https://stackoverflow.com/questions/22937618/reference-what-does-this-regex-mean/22944075#22944075
以下是perl正则的man文档:
- perl正则快速入门:man perlrequick
- perl正则教程:man perlretut
- perl正则完整文档:man perlre
学perl正则必备的一点基本语法
新建一个文件作为perl脚本文件,在其首行写上#!/usr/bin/perl,它表示用perl作为本文件的解释器。写入一些perl程序后,再赋予执行权限就可以执行了,或者直接使用perl命令去调用这个脚本文件,前面的两个过程都可以省略,这和shell脚本的方式是完全一样的,无非是将bash替换为了perl,想必各位都理解。
1.print用来输出信息,相当于shell中的echo命令,但需要手动输入换行符"\n"进行换行。
例如:
#!/usr/bin/perl
print "hello world\n"; # 注意每一句后面都使用分号结尾
保存后,执行它(假设脚本文件名为test.pl):
$ chmod +x test.pl
$ perl test.pl
2.变量赋值
perl中的变量可以不用事先声明,可以直接赋值甚至直接引用。注意变量名前面总是需要加上$符号,无论是赋值的时候还是引用的时候,这和其它语言不太一样。
#!/usr/bin/perl
$name="longshuai";
$age=18;
print "$name $age \n";
3.if语句用来判断,语法格式为:
if(condition){
body
}else{
body
}
例如:
$age = 18;
if($age <= 20){
print "age less than 20\n";
} else {
print "age greate than 20\n";
}
4.默认参数变量
在perl中,对于需要参数的函数或表达式,但却没有给参数,这是将会使用perl的默认参数变量$_。
例如,下面的print本来是需要参数的,但是因为没有给参数,print将输出默认的参数变量$_,也就是输出"abcde"。
$_="abcde";
print ;
perl中使用$_的地方非常多,后文还会出现,不过用到的时候我会解释。
5.读取标准输入
perl中使用一对尖括号格式的<STDIN>来读取来自非文件的标准输入,例如来自管道的数据,来自输入重定向的数据或者来自键盘的输入。需要注意的是,<STDIN>读取的输入会自带换行符,所以print输出的时候不要加上额外的换行符。
例如,在test.pl文件中写入如下内容:
#!/usr/bin/perl
$data=<STDIN>;
print "$data";
然后用管道传递一行数据给perl程序:
echo "abcdefg" | perl test.pl
只是需要注意,将<STDIN>赋值给变量时,将只能读取一行(遇到换行符就结束读取)。例如下面的perl将读取不了"hijklmn"。
echo -e "abcdefg\nhijklmn" | perl test.pl
如果想要读取多行标准输入,就不能将其赋值给变量,而是使用foreach来遍历各行(此处不介绍其它方式):
foreach $line (<STDIN>){
print "$line";
}
以上就是foreach的语法:
- 圆括号中的内容是待遍历对象,通常是一个列表,比如上面用
<STDIN>读取的多行数据就是一个列表,每一行都是列表中的一个元素; - $line称为控制变量,foreach在每次迭代过程中都会选中一个列表中的元素赋值给$line,例如将读取的每一行都赋值给$line。
可以省略$line,这时就采用默认的参数变量$_,所以以下两个表达式是等价的:
foreach (<STDIN>){
print "$_";
}
foreach $_ (<STDIN>){
print "$_";
}
6.读取文件中的数据
正则强大的用处就是处理文本数据,所以必须要说明perl如何读取文件数据来做正则匹配。
我们可以将文件作为perl命令行的参数,perl会使用<>去读取这些文件中的内容。
foreach (<>){
print "$_";
}
执行的时候,只要把文件作为perl命令或脚本文件的参数即可:
perl test.pl /etc/passwd
7.去掉行尾分隔符
由于<>和<STDIN>读取文件、读取标准输入的时候总是自带换行符,很多时候这个自带的换行符都会带来格式问题。所以,有必要在每次读取数据时将行尾的换行符去掉,使用chomp即可。
例如:
foreach $line (<STDIN>) {
chomp $line;
print "$line read\n";
}
以下是执行结果:
[root@xuexi ~]# echo -e "malongshuai gaoxiaofang" | perl 26.plx
malongshuai gaoxiaofang read
如果上面的例子中不加上chomp,那么执行结果将像下面一样:
[root@xuexi perlapp]# echo -e "malongshuai gaoxiaofang" | perl 26.plx
malongshuai gaoxiaofang
read
显然,输出格式和print语句中期待的输出格式不一样。
前面说过,可以省略$line,让其使用默认的参数变量$_,所以可以这样读取来自perl命令行参数文件的数据:
foreach (<>) {
chomp;
print "$_ read\n";
}
8.命令行的操作模式
其实就是一行式。perl命令行加上"-e"选项,就能在perl命令行中直接写perl表达式,例如:
echo "malongshuai" | perl -e '$name=<STDIN>;print $name;'
因为perl最为人所知的就是它应用了各种符号的组合,让人看着怪异无比,而这些符号放在命令行中很可能会被shell先解析,所以强烈建议"-e"后表达式使用单引号包围,而不是双引号。
更建议,如果可以,不要使用perl命令行的方式,调试起来容易混乱。
perl如何使用正则进行匹配
使用=~符号表示要用右边的正则表达式对左边的数据进行匹配。正则表达式的书写方式为m//。关于m//,其中斜线可以替换为其它符号,规则如下:
- 双斜线可以替换为任意其它对应符号,例如对称的括号类,
m(),m{},相同的标点类,m!!,m%%等等 - 只有当m模式采用双斜线的时候,可以省略m字母,即
//等价于m// - 如果正则表达式中出现了和分隔符相同的字符,可以转义表达式中的符号,但更建议换分隔符,例如
/http:\/\//转换成m%http://%
所以要匹配内容,有以下两种方式:
- 方式一:使用
data =~ m/reg/,可以明确指定要对data对应的内容进行正则匹配 - 方式二:直接
/reg/,因为省略了参数,所以使用默认参数变量,它等价于$_ =~ m/reg/,也就是对$_保存的内容进行正则匹配
perl中匹配操作默认返回的是匹配成功与否,成功则返回真,匹配不成功则返回假。但是当使用了全局匹配修饰符g,则返回本次匹配成功的内容。此外,perl提供了特殊变量允许访问匹配到的内容,甚至匹配内容之前的数据、匹配内容之后的数据都提供了相关变量以便访问。见下面的示例。
例如:
1.匹配给定字符串内容
$name = "hello gaoxiaofang";
if ($name =~ m/gao/){
print "matched\n";
}
或者,直接将字符串拿来匹配:
"hello gaoxiaofang" =~ m/gao/;
2.匹配来自管道的每一行内容,匹配成功的行则输出
foreach (<STDIN>){
chomp;
if (/gao/){
print "$_ was matched 'gao'\n";
}
}
上面使用了默认的参数变量$_,它表示foreach迭代的每一行数据;上面还简写的正则匹配方式/gao/,它等价于$_ =~ m/gao/。
以下是执行结果:
[root@xuexi perlapp]# echo -e "malongshuai gaoxiaofang" | perl 26.plx
malongshuai gaoxiaofang was matched 'gao'
3.匹配文件中每行数据
foreach (<>){
chomp;
if(/gao/){
print "$_ was matched 'gao'\n";
}
}
4.如果想要输出匹配到的内容,可以使用特殊变量$&来引用匹配到的内容,还可以使用$`引用匹配前面部分的内容,$'引用匹配后面部分的内容
例如:
aAbBcC =~ /bB/
由于匹配的内容是bB,匹配内容之前的部分是aA,匹配之后的部分是cC,于是可以看作下面对应关系:
(aA)(bB)(cC)
| | |
$` $& $'
以下是使用这三个特殊变量的示例:
$name="aAbBcC";
if($name =~ /bB/){
print "pre match: $` \n";
print "match: $& \n";
print "post match: $' \n";
}
需要注意的是,正则中一般都提供全局匹配的功能,perl中使用修饰符/g开启。当开启了全局匹配功能,这3个变量保存的值需要使用循环语句去遍历,否则将只保存第一次匹配的内容。例如:
$name="aAbBcCbB";
if($name =~ /bB/g){ # 匹配完第一个bB就结束
print "pre match: $` \n";
print "match: $& \n";
print "post match: $' \n";
}
while($name =~ /bB/g){ # 将迭代两次
print "pre match: $` \n";
print "match: $& \n";
print "post match: $' \n";
}
perl支持的正则
从这里开始,正式介绍perl支持的正则。
出于方便,我全部都直接在perl程序内部定义待匹配的内容,如果想要匹配管道传递的输入,或者匹配文件数据,请看上文获取操作方法。
为了完整性,每一节中我都是先把一大堆的内容列出来做个简单介绍,然后再用示例解释每个(或某几个)。但perl正则的内容太多,而且很多功能前后关联,所以如果列出来的内容没有在同一小节内介绍,那么就是在后面需要的地方介绍。当然,也有些没什么用或者用的很少的功能(比如unicode相关的),通篇都不会介绍。
模式匹配修饰符
指定模式匹配的修饰符,可以改变正则表达式的匹配行为。例如,下面的i就是一种修饰符,它让前面的正则REG匹配时忽略大小写。
m/REG/i
perl总共支持以下几种修饰符:msixpodualngc
i:匹配时忽略大小写g:全局匹配,默认情况下,正则表达式"abc"匹配"abcdabc"字符串的时候,将之匹配左边的abc,使用g将匹配两个"abc"c:在开启g的情况下,如果匹配失败,将不重置搜索位置m:多行匹配模式s:让.可以匹配换行符"\n",也就是说该修饰符让.真的可以匹配任意字符x:允许正则表达式使用空白符号,免得让整个表达式难读难懂,但这样会让原本的空白符号失去意义,这是可以使用\s来表示空白o:只编译一次正则表达式n:非捕获模式p:保存匹配的字符串到${^PREMATCH}、${^MATCH}、${^POSTMATCH}中,它们在结果上对应$`、$&和$',但性能上要更好a和u和l:分别表示用ASCII、Unicode和Locale的方式来解释正则表达式,一般不用考虑这几个修饰符d:使用unicode或原生字符集,就像5.12和之前那样,也不用考虑这个修饰符
这些修饰符可以连用,连用时顺序可随意。例如下面两行是等价的行为:全局忽略大小写的匹配行为。
m/REG/ig
m/REG/gi
上面的修饰符,本节介绍igcmsxpo这几个修饰符,n修饰符在后面分组捕获的地方解释,auld修饰符和字符集相关,不打算解释。
i修饰符:忽略大小写
该修饰符使得正则匹配的时候,忽略大小写。
$name="aAbBcC";
if($name =~ m/ab/i){
print "pre match: $` \n"; # 输出a
print "match: $& \n"; # 输出Ab
print "post match: $' \n"; # 输出BcC
}
g和c修饰符以及\G
g修饰符(global)使得正则匹配的时候,对字符串做全局匹配,也就是说,即使前面匹配成功了,还会继续向后匹配,看是否还能匹配成功。
例如,字符串"abcabc",正则表达式"ab",在默认情况下(不是全局匹配)该正则在匹配到第一个ab后就结束了,如果使用了g修饰符,匹配完第一个ab,还会继续向后匹配,而且正好还能匹配到第二个ab,所以最终有两个ab被匹配成功。
要验证多次匹配,需要使用循环遍历的方式,而不能用if语句:
$name="aAbBcCaBc";
while($name =~ m/ab/gi){
print "pre match: $` \n";
print "match: $& \n";
print "post match: $' \n";
}
执行它,将输出如下内容:
pre match: a
match: Ab
post match: BcCabd
pre match: aAbBcC
match: ab
post match: d
以下内容,如果仅仅只是为了学perl正则,那么可以跳过,因为很难,如果是学perl语言,那么可以继续看下去。
实际上,在开启了g全局匹配后,perl每次在成功匹配的时候都会记下匹配的字符位移,以便在下次匹配该内容时候,可以从指定位移处继续向后匹配。每次匹配成功后的位移值(pos的位移从0开始算,0位移代表的是第一个字符左边的位置),都可以通过pos()函数获取。如果本次匹配导致位移指针重置,pos将返回undef。
$name="123ab456";
$name =~ m/\d\d/g; # 第一次匹配,匹配成功后记下位移
print "matched string: $&, position: ",pos $name,"\n";
$name =~ m/\d\d/g; # 第二次匹配,匹配成功后记下位移
print "matched string: $&, position: ",pos $name,"\n";
执行它,将输出如下内容:
matched string: 12, position: 2
matched string: 45, position: 7
由于匹配失败的时候,正则匹配操作会返回假,所以可以作为if或while等的条件语句。例如,改为while循环多次匹配:
$name="123ab456";
while($name =~ m/\d\d/g){
print "matched string: $&, position: ",pos $name,"\n";
}
默认全局匹配情况下,当本次匹配失败,位移指针将重置到起始位置0处,也就是说,下次匹配将从头开始匹配。例如:
$txt="1234a56";
$txt =~ /\d\d/g; # 匹配成功:12,位移向后移两位
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d/g; # 匹配成功:34,位移向后移两位
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d\d/g; # 匹配失败,位移指针回到0处,pos()返回undef
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d/g; # 匹配成功:1,位移向后移1位
print "matched $&: ",pos $txt,"\n";
执行上述程序,将输出:
matched 12: 2
matched 34: 4
matched 34:
matched 1: 1
如果"g"修饰符下同时使用"c"修饰符,也就是"gc",它表示全局匹配失败的时候不重置位移指针。也就是说,本次匹配失败后,位移指针会卡在原处不动,下次匹配将从这个位置处开始匹配。
$txt="1234a56";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d\d/gc; # 匹配失败,$&和pos()保留上一次匹配成功的内容
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d/g; # 匹配成功:5
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d/g; # 匹配成功:6
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d/gc; # 匹配失败
print "matched $&: ",pos $txt,"\n";
执行上述程序,将输出:
matched 12: 2
matched 34: 4
matched 34: 4
matched 5: 6
matched 6: 7
matched 6: 7
继续上面的问题,如果第三个匹配语句不是\d\d\d,而是"\d",它匹配字母a的时候也失败,不用c修饰符的时候会重置位移吗?显然是不会。因为它会继续向后匹配。所以该\G登场了。
默认全局匹配情况下,匹配时是可以跳过匹配失败的字符继续匹配的:当某个字符匹配失败,它会后移一位继续去匹配,直到匹配成功或匹配结束。
$txt="1234ab56";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d/g; # 字母a匹配失败,后移一位,字母b匹配失败,后移一位,数值5匹配成功
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d/g; # 数值6匹配成功
print "matched $&: ",pos $txt,"\n";
执行上述程序,将输出:
matched 12: 2
matched 34: 4
matched 5: 7
matched 6: 8
可以指定\G,使得本次匹配强制从位移处进行匹配,不允许跳过任何匹配失败的字符。
- 如果本次
\G全局匹配成功,位移指针自然会后移 - 如果本次
\G全局匹配失败,且没有加上c修饰符,那么位移指针将重置 - 如果本次
\G全局匹配失败,且加上了c修饰符,那么位移指针将卡在那不动
例如:
$txt="1234ab56";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\G\d/g; # 强制从位移4开始匹配,无法匹配字母a,但又不允许跳过
# 所以本次\G全局匹配失败,由于没有修饰符c,指针重置
print "matched $&: ",pos $txt,"\n";
$txt =~ /\G\d/g; # 指针回到0,强制从0处开始匹配,数值1能匹配成功
print "matched $&: ",pos $txt,"\n";
以下是输出内容:
matched 12: 2
matched 34: 4
matched 34:
matched 1: 1
如果将上面第三个匹配语句加上修饰符c,甚至后面的语句也都加上\G和c修饰符,那么位移指针将卡在那个位置:
$txt="1234ab56";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\d\d/g;
print "matched $&: ",pos $txt,"\n";
$txt =~ /\G\d/gc; # 匹配失败,指针卡在原地
print "matched $&: ",pos $txt,"\n";
$txt =~ /\G\d/gc; # 匹配失败,指针继续卡在原地
print "matched $&: ",pos $txt,"\n";
$txt =~ /\G\d/gc; # 匹配失败,指针继续卡在原地
print "matched $&: ",pos $txt,"\n";
以下是输出结果:
matched 12: 2
matched 34: 4
matched 34: 4
matched 34: 4
matched 34: 4
一般来说,全局匹配都会用循环去多次迭代,和上面一次一次列出匹配表达式不一样。所以,下面使用while循环的例子来对\G和c修饰符稍作解释,其实理解了上面的内容,在循环中使用\G和c修饰符也一样很容易理解。
$txt="1234ab56";
while($txt =~ m/\G\d\d/gc){
print "matched: $&, ",pos $txt,"\n";
}
执行结果:
matched: 12, 2
matched: 34, 4
当第三轮循环匹配到a字母的时候,由于使用了\G,导致匹配失败,结束循环。
上面使用c与否是无关紧要的,但如果这个while循环的后面后还有对$txt的匹配,那么使用c修饰符与否就有关系了。例如下面两段程序,返回结果不一样:
$txt="1234ab56";
while($txt =~ m/\G\d\d/gc){ # 使用c修饰符
print "matched: $&, ",pos $txt,"\n";
}
$txt =~ m/\G\d\d/gc;
print "matched: $&, ",pos $txt,"\n";
和
$txt="1234ab56";
while($txt =~ m/\G\d\d/g){ # 不使用c修饰符
print "matched: $&, ",pos $txt,"\n";
}
$txt =~ m/\G\d\d/gc;
print "matched: $&, ",pos $txt,"\n";
m修饰符:多行匹配模式
正则表达式一般都只用来匹配单行数据,但有时候却需要一次性匹配多行。比如匹配跨行单词、匹配跨行词组,匹配跨行的对称分隔符(如一对括号)。
使用m修饰符可以开启多行匹配模式。
例如:
$txt="ab\ncd";
$txt =~ /a.*\nc/m;
print "===match start===\n$&\n===match end===\n";
执行,将输出:
===match start===
ab
c
===match end===
关于多行匹配,需要注意的是元字符.默认情况下无法匹配换行符。可以使用[\d\D]代替点,也可以开启s修饰符使得.能匹配换行符。
例如,下面两个匹配输出的结果和上面是一致的。
$txt="ab\ncd";
$txt =~ /a.*c/ms;
print "===match start===\n$&\n===match end===\n";
$txt="ab\ncd";
$txt =~ /a[\d\D]*c/m;
print "===match start===\n$&\n===match end===\n";
s修饰符
默认情况下,.元字符是不能匹配换行符\n的,开启了s修饰符功能后,可以让.匹配换行符。正如刚才的那个例子:
$txt="ab\ncd";
$txt =~ /a.*c/m; # 匹配失败
print "===match start===\n$&\n===match end===\n";
$txt="ab\ncd";
$txt =~ /a.*c/ms; # 匹配成功
print "===match start===\n$&\n===match end===\n";
x修饰符
正则表达式最为人所抱怨的就是它的可读性极差,无论你的正则能力有多强,看着一大堆乱七八糟的符号组合在一起,都得一个符号一个符号地从左向右读。
万幸,perl正则支持表达式的分隔,甚至支持注释,只需加上x修饰符即可。这时候正则表达式中出现的所有空白符号都不会当作正则的匹配对象,而是直接被忽略。如果想要匹配空白符号,可以使用\s表示,或者将空格使用\Q...\E包围。
例如,以下4个匹配操作是完全等价的。
$ans="cat sheep tiger";
$ans =~ /(\w) *(\w) *(\w)/; # 正常情况下的匹配表达式
$ans =~ /(\w)\s* (\w)\s* (\w)/x;
$ans = ~ /
(\w)\s* # 可以加上本行注释:匹配第一个单词
(\w)\s* # 可以加上本行注释:匹配第二个单词
(\w) # 可以加上本行注释:匹配第三个单词
/x;
$ans =~ /
(\w)\Q \E # \Q \E强制将中间的空格当作字面符号被匹配
(\w)\Q \E
(\w)
/x;
对于稍微复杂一些的正则表达式,常常都会使用x修饰符来增强其可读性,最重要的是加上注释。这一点真的非常人性化。
p修饰符
前面说过,通过3个特殊变量$`、$&和$'可以保存匹配内容之前的内容,匹配内容以及匹配内容之后的内容。但是,只要使用了这3个变量中的任何一个,后面的所有分组效率都会降低。perl提供了一个p修饰符,能实现完全相同的功能:
${^PREMATCH} <=> $`
${^MATCH} <=> $&
${^POSTMATCH} <=> $'
一个例子即可描述:
$ans="cat sheep tiger";
$ans =~ /sheep/p;
print "${^PREMATCH}\n"; # 输出"cat "
print "${^MATCH}\n"; # 输出"sheep"
print "${^POSTMATCH}\n"; # 输出" tiger"
o修饰符
在较老的perl版本中,如果使用同一个正则表达式做多次匹配,正则引擎将只多次编译正则表达式。很多时候正则表达式并不会改变,比如循环匹配文件中的行,这样的多次编译导致性能下降很明显,于是可以使用o修饰符让正则引擎对同一个正则表达式不重复编译。
在perl5.6中,默认情况下对同一正则表达式只编译一次,但同样可以指定o修饰符,使得即使正则表达式变化了也不要重新编译。
一般情况下,可以无视这个修饰符。
范围模式匹配修饰符(?imsx-imsx:pattern)
前文介绍的修饰符adluoimsxpngc都是放在m//{FLAG}的flag处的,放在这个位置会对整个正则表达式产生影响,所以它的作用范围有点广。
例如m/pattern1 pattern2/i的i修饰符会影响pattern1和pattern2。
perl允许我们定义只在一定范围内生效的修饰符,方式是(?imsx:pattern)或(?-imsx:pattern)或(?imsx-imsx:pattern),其中加上-表示去除这个修饰符的影响。这里只列出了imsx,因为这几个最常用,其他的修饰符也一样有效。
例如,对于待匹配字符串"Hello world gaoxiaofang",使用以下几种模式去匹配的话:
/(?i:hello) world/
表示匹配hello时,可忽略大小写,但匹配world时仍然区分大小写。所以匹配成功
/(?ims:hello.)world/
表示可以跨行匹配helloworld,也可以匹配单行的hellosworld,且hello部分忽略大小写。所以匹配成功
/(?i:hello (?-i:world) gaoxiaoFANG)/
表示在第二个括号之前,可用忽略大小写进行匹配,但因为第二个括号里指明了去除i的影响,所以对world的匹配会区分大小写,但是对gaoxiaofang部分的匹配又不区分大小写。所以匹配成功
/(?i:hello (?-i:world) gaoxiao)FANG/
和前面的类似,但是将"FANG"放到了括号外,意味着这部分要区分大小写。所以匹配失败
perl支持的反斜线序列
1.锚定类的反斜线序列
所谓锚定,是指它匹配的是位置,而非字符,比如锚定行首的意思是匹配第一个字母前的空字符。也就是很多人说的"零宽断言(zero-width assertions)"。
\b:匹配单词边界处的空字符\B:匹配非单词边界处的空字符\<:匹配单词开头处的空字符\>:匹配单词结尾处的空字\A:匹配绝对行首,换句话说,就是输入内容的开头\z:匹配绝对行尾,换句话说,就是输入内容的绝对尾部\Z:匹配绝对行尾或绝对行尾换行符前的位置,换句话说,就是输入内容的尾部\G:强制从位移指针处进行匹配,详细内容见g和c修饰符以及\G
主要解释下\A \z \Z,其它的属于基础正则的内容,不多做解释了。
\A \z \Z和^ $的区别主要体现在多行模式下。在多行模式下:
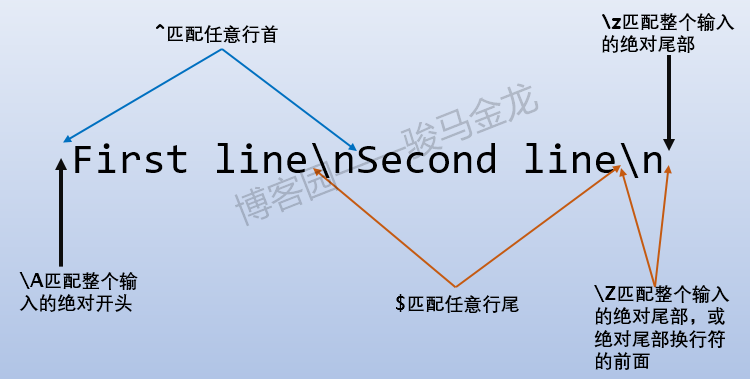
$txt = "abcd\nABCD\n";
$txt1 = "abcd\nABCD";
$txt =~ /^ABC*/; # 无法匹配
$txt =~ /^ABC*/m; # 匹配
$txt =~ /\Aabc/; # 匹配
$txt =~ /\Aabc/m; # 匹配
$txt =~ /\AABC/m; # 无法匹配
$txt =~ /cd\n$/m; # 不匹配
$txt =~ /cd$\n/m; # 不匹配
$txt =~ /cd$/m; # 匹配
$txt =~ /CD\Z\n/m # 匹配
$txt =~ /CD\Z\n\Z/m; # 匹配
$txt =~ /CD\n\z/m; # 匹配
$txt1 =~ /CD\Z/m; # 匹配
$txt1 =~ /CD\z/m; # 匹配
从上面的$匹配示例可知,$代表的行尾,其实它在有换行符的时候匹配"\n",而不是"\n"的前、后,在没有换行符的时候,匹配行尾。
2.字符匹配反斜线序列
当然,除了以下这几种,还有\v \V \h \H \R \p \c \X,这些基本不会用上,所以都不会在本文解释。
\w:匹配单词构成部分,等价于[_[:alnum:]]\W:匹配非单词构成部分,等价于[^_[:alnum:]]\s:匹配空白字符,等价于[[:space:]]\S:匹配非空白字符,等价于[^[:space:]]\d:匹配数字,等价于[0-9]\D:匹配非数字,等价于[^0-9]\N:不匹配换行符,等价于[^\n]。但\N{NAME}有特殊意义,表示匹配已命名(名为NAME)的unicode字符序列,本文不介绍该特殊用法
由于元字符.默认无法匹配换行符,所以需要匹配换行符的时候,可以使用特殊组合[\d\D]或者(\n|\N)来替换.,换句话说,如果想匹配任意长度的任意字符,可以换成[\d\D]*或者(\n|\N)*,当然,前提是必须支持这3个反斜线序列。
之所以不用[\n\N]替代元字符.,是因为\N有特殊意义,不能随意接符号和字母。
3.分组引用的反斜线序列
\1:反向引用,其中1可以替换为任意一个正整数,即使超出9,例如\111表示匹配第111个分组\g1或\g{1}:也是反向引用,只不过这种写法可以避免歧义,例如\g{1}11表示匹配第一个分组内容后两个数字1\g{-1}:还可以使用负数,表示距离\g左边的分组号,也就是相对距离。例如(abc)([a-z])\g{-1}中的\g引用的是[a-z],如果-1换成-2,则引用的abc\g{name}:引用已命名的分组(命名捕获),其中name为分组的名称\k<name>:同上,引用已命名的分组(命名捕获),其中name为分组的名称\K:不要将\K左边的内容放进$&。换句话说,\K左边的内容即使匹配成功了,也会重置匹配的位置
\1表示引用第一个分组,\11表示引用第11个分组,在基础正则中,是不支持引用超出9个分组的,但显然perl会将\11的第二个1解析为引用,以便能引用更多分组。
同理\g1和\g11,只是使用\g引用的方式可以加上大括号使引用变得更安全,更易读,且\g可以使用负数来表示从右向左相对引用。这样在\g{-2}的左边添加新的分组括号时,无须修改引用表达式。
此处暂时还没介绍到命名分组,所以\g{name}和\k<name>留在后面再介绍。
\K表示强制中断前面已完成的匹配。例如"abc22ABC" =~ /abc\K2.*/;,虽然abc三个字母也被匹配,如果没有\K,这3个字母将放进$&中,但是\K使得匹配完abc后立即切断前面的匹配,也就是从c字母后面开始重新匹配,所以这里匹配的结果是22ABC。
再例如,"abc123abcfoo"=~ /(abc)123\K\g1foo/;,它匹配到123后被切断,但是分组引用还可以继续引用,所以匹配的结果是"abcfoo"。
贪婪匹配、非贪婪匹配、占有优先匹配
在基础正则中,那些能匹配多次的量词都会匹配最长内容。这种尽量多匹配的行为称为"贪婪匹配"(greedy match)。
例如字符串"aa1122ccbb",用正则表达式a.*c去匹配这个字符串,其中的.*将直接从第二个字母a开始匹配到最结尾的b,因为从第二个字母a开始到最后一个字母b都符合.*的匹配模式。再然后,去匹配字母c,但因为已经把所有字母匹配完了,只能回退一个字母一个字母地释放,每释放一个就匹配一次字母c,发现回退释放到倒数第三个字母就能满足匹配要求,于是这里的.*最终匹配的内容是"a1122cc"。
上面涉及到回溯的概念,也就是将那些已经被量词匹配的内容回退释放。
上面描述的是贪婪匹配行为,还有非贪婪匹配、占有优先匹配,以下简单描述下他们的意义:
- 非贪婪匹配:(lazy match,reluctant)尽可能少地匹配,也叫做懒惰匹配
- 占有优先匹配:(possessive)占有优先和固化分组是相同的,只要占有了就不再交换,不允许进行回溯。相关内容见后文"固化分组"
有必要搞清楚这几种匹配模式在匹配机制上的区别:
- 贪婪匹配:对于那些量词,将一次性从左到右匹配到最大长度,然后再往回回溯释放
- 非贪婪匹配:对于那些量词,将从左向右逐字符匹配最短长度,然后直接结束这次的量词匹配行为
- 占有优先匹配:按照贪婪模式匹配,匹配后内容就锁住,不进行回溯(后文固化分组有具体示例)
除了上面描述的*量词会进行贪婪匹配,其他所有能进行多次匹配的量词可以选择贪婪匹配模式、非贪婪匹配模式和占有优先匹配模式,只需选择对应的量词元字符即可。如下:
(量词后加上?) (量词后加上+)
贪婪匹配量词 非贪婪匹配量词 占有优先匹配量词
-----------------------------------------------------------------
* *? *+
? ?? ?+
+ +? ++
{M,} {M,}? {M,}+
{M,N} {M,N}? {M,N}+
{N} {N}? {N}+
几点需要说明:
- 非贪婪匹配时的
{M,}?和{M,N}?,它们是等价的,因为最多只匹配M次 - 在perl中不支持
{,N}的模式,所以也没有对应的非贪婪和占有优先匹配模式 - 关于
{N}这个量词,由于是精确匹配N次,所以贪婪与否对最终结果无关紧要,但是却影响匹配时的行为:贪婪匹配最长,需要回溯,非贪婪匹配最短,不回溯,占有优先匹配最长不回溯。
看以下示例即可理解贪婪和非贪婪匹配的行为:
$str="abc123abc1234";
# greedy match
if( $str =~ /(a\w*3)/){
print "$&\n"; # abc123abc123
}
# lazy match
if( $str =~ /(a\w*?3)/){
print "$&\n"; # abc123
}
以下是占有优先匹配模式的示例:
$str="abc123abc1234";
if( $str =~ /a\w*+/){ # 成功
print "possessive1: $&\n";
}
if( $str =~ /a\w*+3/){ # 失败
print "possesive2: $&\n";
}
所以,在使用占有优先匹配模式时,它后面不应该跟其他表达式,例如a*+x永远匹配不了东西。绝大多数时候都是不会回溯的。但是少数情况下,它并非强制锁住回溯,这个和正则引擎匹配原理有关,本文不多做解释。
另外,固化分组和占有优先并不完全等价,它们只是匹配行为相同:匹配后不回溯。具体可对比后文对应内容。
perl的分组捕获和分组引用
分组的基本应用
在基础正则中,使用括号可以对匹配的内容进行分组,这种行为称为分组捕获。捕获后可以通过\1这种反向引用方式去引用(访问)保存在分组中的匹配结果。
例如:
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\1\2/;
在perl中,还可以使用\gN的方式来反向引用分组,这个在上一节"反斜线序列"中已经解释过了。例如,以下是和上面等价的几种写法:
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\g1\g2/;
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\g{1}\g{2}/;
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\g{-2}\g{-1}/;
perl还会把分组的内容放进perl自带的特殊变量$1,$2,...,$N中,它们和\1,\2,...\N在匹配成功时的结果上没有区别,但是\N这种类型的反向引用只在正则匹配中有效,正则匹配结束后就消亡了,而$N因为是perl的变量,即使正则已经退出匹配,也依然可以引用。所以,我们可以使用$N的方式来输出分组匹配的结果:
"abc11ddabc11" =~ /([a-z]*)([0-9]*)dd\1\2/;
print "first group \\1: $1\n";
print "second group \\2: $2\n";
有两点需要注意:
- 这些分组可能捕获到的是空值(比如那些允许匹配0次的量词),但是整个匹配是成功的。这时候引用分组时,得到的结果也将是空值
- 当分组匹配失败的时候,
\1会在识别括号的时候重置,而$1仍保存上一次分组成功的值
第一点,示例可知:
"abcde" =~ /([0-9]*)de/;
print "null group: $1\n";
第二点,从机制上去分析。\1是每个正则匹配都相互独立的,而$1则保存分组捕获成功的值,即使这次值是上次捕获的。
正则匹配的操作如果在列表上下文,则保存各个分组捕获的内容。所以,出于方便,可以通过下面的方式直接将分组捕获的结果赋值给指定变量:
$date = "2018-11-22";
($year,$mon,$day) = ($date =~ /(\d{4})-(\d{2})-(\d{2})/);
这里稍微解释下正则匹配关于分组捕获的匹配过程:
例如,匹配表达式"12abc22abc" =~ /\d(abc)\d\d\1/;,当正则引擎去匹配数据时:
1.首先匹配第一个数字1,发现符合\d,于是继续用(abc)去匹配字符串,因为发现了是分组括号,于是会将第二个字符2放进分组,发现不匹配字母a,于是匹配失败,丢弃这个分组中的内容。
2.正则引擎继续向后匹配数值2,发现符合\d,于是用(abc)去匹配字符串,接着会将第三个字符a放进分组,发现能匹配,继续匹配字符串中的b、c发现都能匹配,于是分组捕获完成,将其赋值给$1,之后就能用\1和$1去引用这个分组的内容。
3.后面继续去匹配\d\d\1,直到匹配结束。
当然,具体匹配的过程不会真的这么简单,它会有一些优化匹配方式,以上只是用逻辑去描述匹配的过程。
perl中更强大的分组捕获
在perl中,支持的分组捕获更强大、更完整,它除了支持普通分组(也就是直接用括号的分组),还支持:
- 命名捕获
(?<NAME>...):捕获后放进一个已分配好名称(即NAME)的分组中,以后可以使用这个名称来引用这个分组,如\g{NAME}引用 - 匿名捕获
(?:...):仅分组,不捕获,所以后面无法再引用这个捕获 - 固化分组
(?>...):一匹配成功就永不交回内容(用回溯的想法理解很容易)
匿名捕获
匿名捕获是指仅分组,不捕获。因为不捕获,所以无法使用反向引用,也不会将分组结果赋值给$1这种特殊变量。
虽然有了分组捕获功能,就可以实现任何需求,但有时候可以让这种行为变得更人性化,减少维护力度。
例如字符串"xiaofang or longshuai",使用模式/(\w+) or (\w+)/去捕获,用$1和$2分别引用or左右两个单词:
$str = "xiaofang or longshuai";
if ($str =~ /(\w+) or (\w+)/){
print "name1: $1, name2: $2\n";
}
但如果需求是中间的关系or也可以换成and,为了同时满足and和or两种需求,使用模式/(\w+) (and|or) (\w+)/去匹配,但是这时引用的序号就得由$2变为$3:
$str = "xiaofang or longshuai";
if ($str =~ /(\w+) (or|and) (\w+)/){
print "name1: $1, name2: $3\n";
}
如果使用匿名捕获,对and和or这样无关紧要,却有可能改变匹配行为的内容,可以将其放进一个无关的分组中。这样不会对原有的其余正则表达式产生任何影响:
$str = "xiaofang or longshuai";
if ($str =~ /(\w+) (?:or|and) (\w+)/){
print "name1: $1, name2: $2\n";
}
注意上面仍然使用$2引用第三个括号。
同样,如果要在正则内部使用反向引用,也一样使用\2来引用第三个括号。
另外,在前文还介绍过一个n修饰符,它也表示非捕获仅分组行为。但它只对普通分组有效,对命名分组无效。且因为它是修饰符,它会使所有的普通分组都变成非捕获模式。
$str = "xiaofang or longshuai";
if ($str =~ /(\w+) (or|and) (\w+)/n){
print "name1: $1, name2: $2\n";
}
由于上面开启了n修饰符,使得3个普通分组括号都变成非捕获仅分组行为,所以\1和$1都无法使用。除非正则中使用了命名分组。
命名捕获
命名捕获是指将捕获到的内容放进分组,这个分组是有名称的分组,所以后面可以使用分组名去引用已捕获进这个分组的内容。除此之外,和普通分组并无区别。
当要进行命名捕获时,使用(?<NAME>)的方式替代以前的分组括号()即可。例如,要匹配abc并将其分组,以前普通分组的方式是(abc),如果将其放进命名为name1的分组中:(?<name1>abc)。
当使用命名捕获的时候,要在正则内部引用这个命名捕获,除了可以使用序号类的绝对引用(如\1或\g1或\g{1}),还可以使用以下任意一种按名称引用方式:
\g{NAME}\k{NAME}\k<NAME>\k'NAME'
如果要在正则外部引用这个命名捕获,除了可以使用序号类的绝对应用(如$1),还可以使用$+{NAME}的方式。
实际上,后一种引用方式的本质是perl将命名捕获的内容放进了一个名为%+的特殊hash类型中,所以可以使用$+{NAME}的方式引用,如果你不知道这一点,那就无视与此相关的内容即可,不过都很简单,一看就懂。
例如:
$str = "ma xiaofang or ma longshuai";
if ($str =~ /
(?<firstname>\w+)\s # firstname -> ma
(?<name1>\w+)\s # name1 -> xiaofang
(?:or|and)\s # group only, no capture
\g1\s # \g1 -> ma
(?<name2>\w+) # name2 -> longshuai
/x){
print "$1\n";
print "$2\n";
print "$3\n";
# 或者指定名称来引用
print "$+{firstname}\n$+{name1}\n$+{name2}\n";
}
其中上述代码中的\g1还可以替换为\1、\g{firstname}、\k{firstname}或\k<firstname>。
通过使用命名捕获,可以无视序号,直接使用名称即可准确引用。
固化分组
首先固化分组不是一种分组,所以无法去引用它。它和"占有优先"匹配模式(贪婪匹配、惰性匹配、占有优先匹配三种匹配模式,见后文)是等价的除了这两种称呼,在不同的书、不同的语言里还有一种称呼:原子匹配。
它的表示形式类似于分组(?>),所以有些地方将其称呼为"固化分组"。再次说明,固化分组不是分组,无法进行引用。如果非要将其看作是分组,可以将其理解为被限定的匿名分组:不捕获,只分组。
- 按照"占有优先"的字面意义来理解比较容易:只要匹配成功了,就绝不回溯。
- 如果按照固化分组的概念来理解,就是将匹配成功的内容放进分组后,将其固定,不允许进行回溯。但是需要注意,这里的不回溯是放进分组中的内容不会回溯给分组外面,而分组内部的内容是可以回溯的。
如果不知道什么是回溯,看完下面的例子就明白。
例如"hello world"可以被hel.* world成功匹配,但不能被hel(?>.*) world匹配。因为正常情况下,.*匹配到所有内容,然后往回释放已匹配的内容直到释放完空格为止,这种往回释放字符的行为在正则术语中称为"回溯"。而固化分组后,.*已匹配后面所有内容,这些内容一经匹配绝不交回,即无法回溯。
但是,如果正则表达式是hel(?>.* world),即将原来分组外面的内容放进了分组内部,这时在分组内部是会回溯的,也就是说能匹配"hello world"。
$str="ma longshuai gao xiaofang";
if($str =~ /ma (?>long.*)/){ # 成功
print "matched\n";
}
if($str =~ /ma (?>long.*)gao/){ # 失败
print "matched\n";
}
if($str =~ /ma (?>long.*gao)/){ # 成功
print "matched\n";
}
if($str =~ /ma (?>long.*g)ao/){ # 成功
print "matched\n";
}
固化分组看上去挺简单的,此处也仅介绍了它最简单的形式。但实际上固化分组很复杂,它涉及了非常复杂的正则引擎匹配原理和回溯机制。如果有兴趣,可以阅读《精通正则表达式》一书的第四章。
环视锚定(断言)
"环视"锚定,即lookaround anchor,也称为"零宽断言",它表示匹配的是位置,不是字符。
(?=...):表示从左向右的顺序环视。例如(?=\d)表示当前字符的右边是一个数字时就满足条件(?!...):表示顺序环视的取反。如(?!\d)表示当前字符的右边不是一个数字时就满足条件(?<=...):表示从右向左的逆序环视。例如(?<=\d)表示当前字符的左边是一个数字时就满足条件(?<!)...:表示逆序环视的取反。如(?<!\d)表示当前字符的左边不是一个数字时就满足条件
关于"环视"锚定,最需要注意的一点是匹配的结果不占用任何字符,它仅仅只是锚定位置。
例如"your name is longshuai MA"和"your name is longfei MA"。使用(?=longshuai)将能锚定第一个句子中单词"longshuai"前面的空字符,但它的匹配结果是"longshuai"前的空白字符,所以(?=longshuai)long才能代表"long"这几个字符串,所以仅对于此处的两个句子,long(?=shuai)和(?=longshuai)long是等价的。
一般为了方便理解,在顺序环视的时候会将匹配内容放在锚定括号的左边(如long(?=longshuai)),在逆序环视的时候会将匹配的内容放在锚定括号的右边(如(?<=long)shuai)。
另外,无论是哪种锚定,都是从左向右匹配再做回溯的(假设允许回溯),即使是逆序环视。
例如:
$str="abc123abcc12c34";
# 顺序环视
$str =~ /a.*c(?=\d)/; # abc123abcc12c
print "$&\n";
# 顺序否定环视
$str =~ /a.*c(?!\d)/; # abc123abc
print "$&\n";
# 逆序环视,这里能逆序匹配成功,靠的是锚定括号后面的c
$str =~ /a.*(?<=\d)c/; # abc123abcc12c
print "$&\n";
# 逆序否定环视
$str =~ /a.*(?<!\d)c/; # abc123abcc
print "$&\n";
逆序环视的表达式必须只能表示固定长度的字符串。例如(?<=word)或(?<=word|word)可以,但(?<=word?)不可以,因为?匹配0或1长度,长度不定,它无法对左边是word还是wordx做正确判断。
$str="hello worlds Gaoxiaofang";
$str =~ /he.*(?<=worlds?) Gao/; # 报错
$str =~ /he.*(?<=worlds|world) Gao/; # 报错
在PCRE中,这种变长的逆序环视锚定可重写为(?<=word|words),但perl中不允许,因为perl严格要求长度必须固定。
\Q...\E
perl中的\Q...\E用来强制包围一段字符,使得里面的正则符号都当做普通字符,不会有特殊意义,它是一种非常强的引用。但注意,它无法强制变量的替换。
例如:
$sub="world";
$str="hello worlds gaoxiaofang";
$str =~ /\Q$sub\E/; # $sub会替换,所以匹配成功world
$str =~ /\Q$sub.\E/; # 元字符"."被当做普通的字符,所以无法匹配
qr//创建正则对象
因为可以在正则模式中使用变量替换,所以我们可以将正则中的一部分表达式事先保存在变量中。例如:
$str="hello worlds gaoxiaofang";
$pattern="w.*d";
$str =~ /$pattern/;
print "$&\n";
但是,这样缺陷很大,在保存正则表达式的变量中存放的特殊字符要防止有特殊意义。例如,当使用m//的方式做匹配分隔符时,不能在变量中保存/,除非转义。
perl提供了qr/pattern/的功能,它把pattern部分构建成一个正则表达式对象,然后就可以在正则表达式中直接引用这个对象,更方便的是可以将这个对象保存到变量中,通过引用变量的方式来引用这个已保存好的正则对象。
$str="hello worlds gaoxiaofang";
# 直接作为正则表达式
$str =~ qr/w.*d/;
print "$&\n";
# 保存为变量,再作为正则表达式
$pattern=qr/w.*d/;
$str =~ $pattern; # (1)
$str =~ /$pattern/; # (2)
print "$&\n";
# 保存为变量,作为正则表达式的一部分
$pattern=qr/w.*d/;
$str =~ /hel.* $pattern/;
print "$&\n";
还允许为这个正则对象设置修饰符,比如忽略大小写的匹配修饰符为i,这样在真正匹配的时候,就只有这一部分正则对象会忽略大小写,其余部分仍然区分大小写。
$str="HELLO wORLDs gaoxiaofang";
$pattern=qr/w.*d/i; # 忽略大小写
$str =~ /HEL.* $pattern/; # 匹配成功,$pattern部分忽略大小写
$str =~ /hel.* $pattern/; # 匹配失败
$str =~ /hel.* $pattern/i; # 匹配成功,所有都忽略大小写
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号