Perl文件句柄相关常量变量
文件句柄相关变量
对应的官方手册:http://perldoc.perl.org/perlvar.html#Variables-related-to-filehandles
默认情况下:
$/:输入行的分隔符以换行符为单位,可以使用$/指定$\:print输出行的分隔符为undef,可以使用$\指定,例如指定换行符"\n"$,:print输出列表(也就是每个逗号分隔的部分)的字段分隔符为undef,可以使用$,指定,例如指定空格$":默认在双引号上下文中,数组被输出的时候是使用空格作为分隔符的,可以使用$"指定列表分隔符$.:当前处理到的行号$.。它是一个行号计数器。文件句柄关闭时会重置行号- 由于读取文件的输入符号
<>从不会显式关闭文件句柄,所以从命令行ARGV读取的文件行号会不断增加
- 由于读取文件的输入符号
$ARGV:表示当前处理的命令行参数中的文件,注意区分:@ARGV表示命令行参数$ARGV[N]表示的是@ARGV数组中的某个元素$ARGV是命令行参数中各文件列表,perl当前正在处理的文件
$|:控制写入或输出数据时是否先放进缓冲再刷入文件句柄- 值为0时,表示先缓存,缓冲了一段数据之后再刷入文件句柄通道
- 值为非0时,表示直接刷入文件句柄通道
- 在使用管道、套接字的时候,建议设置为非0值,以便数据能立刻被处理
- 该变量只对写数据或输出有效,对读取操作无效
注意:输出的分隔符只适用于print,不适用say。
例如:
1.指定输出行分隔符$\。这样每次输出的时候,会自动在输出语句的尾部加上这个分隔符。可以指定多个字符作为分隔符。
{
my $\ = "\n";
print "new line1";
print "new line2";
print "new line3";
# 可以指定多个字符:$\ = "YYY"
}
上面将换行输出各行。
2.指定输出字段分隔符$,。这样print语句中每个逗号隔开的地方都会按照指定的分隔符输出。
{
my $,="-";
print "new field1","new field2","new field3","\n";
# 可以指定多个字符:$, = "YYY"
}
上面将输出:new field1-new field2-new field3
3.数组输出字段分隔符$"。当print的输出列表中有数组,且数组使用双引号包围的时候(即双引号上下文中数组替换),默认数组元素是使用空格分隔的,该分隔符指定元素之间的分隔符。
#!/usr/bin/perl
{
$"="x";
@arr=qw{perl python shell};
print "@arr","\n";
}
上面将输出:"perlxpythonxshell"。
4.$.表示当前处理到的行号。文件句柄关闭时会重置行号,但重新打开文件句柄时不会重置。但由于读取文件的输入符号<>从不会显式关闭文件句柄,所以ARGV读取的文件行号会不断增加。
#!/usr/bin/perl
# 打开文件,看行号
open LOG1,"<","test.log";
while(<LOG1>){
print "Line $.: $_";
}
print "---------------------\n";
close LOG1;
# 关闭上面的文件句柄后,再打开一次文件句柄,行号重置
open LOG2,"<","test.log";
while(<LOG2>){
print "Line $.: $_";
}
print "---------------------\n";
close LOG2;
# 从<>读内容,行号一直变大
while(<>){
print "Line $. from $ARGV: $_";
}
5.$/控制的是输入行分隔符。在读取文件的时候,通过该特殊变量可以控制如何分行。
例如,以下是test1.log文件的内容:
a
b
x
c
d
x
e
以下是15.plx的源代码:
$/="x";
while(<>){
print "Line $.: $_","\n";
}
执行的结果:
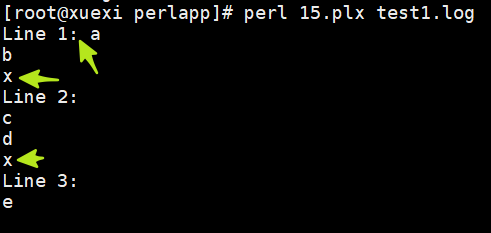
注意换行符"x"也会保留在行中。
伪文件句柄DATA
经常地,想要在源码文件里读取一些文件数据来进行测试,这时可以直接使用一个预定义的伪文件句柄DATA。
... some code ...
从__DATA__或__END__开始的数据都将被DATA文件句柄读取,直到文件结尾
__DATA__
...一些待读取数据...
当perl编译器遇到__DATA__或__END__了,就意味着代码到此结束,下面的数据都将作为当前文件内有效的DATA文件句柄的数据流。
例如:
#!/usr/bin/perl
while(<DATA>){
chomp;
print "read from DATA: $_\n";
}
__DATA__
first line in DATA
second line in DATA
third line in DATA
last line in DATA
Inline::Files
DATA伪文件句柄的一个缺点是从遇到__DATA__或__END__起直到文件的尾部,都属于DATA文件句柄的内容,也就是说在源代码文件中只能定义一个伪文件句柄。
在CPAN上有一个Inline::Files模块,它可以在同一个源代码文件中定义多个伪文件句柄。需要先安装:
cpan install Inline::Files
例如:
use Inline::Files;
use 5.010;
say "@main::FILE1";
say "@main::FILE2";
while(<FILE1>){
say "$_";
}
while(<FILE2>){
say "$_";
}
__FILE1__
first line in FILE1
second line in FILE1
third line in FILE1
__FILE2__
first line in FILE2
second line in FILE2
third line in FILE2
它像ARGV一样,在运行程序初始阶段就打开这些虚拟文件句柄,并将每个虚拟文件句柄保存到@<PACKNAME>::<HANDLE>中。例如,上面的是示例是在main包中定义了FILE1和FILE2两个文件句柄,那么这两个文件句柄将保存到@main::FILE1和@main::FILE2中,并在处理某个文件句柄的时候,将其保存到标量$main::FILE1或$main::FILE2中。
可以同时定义多个名称相同的虚拟文件系统。例如:
__FILE1__
...
__FILE2__
...
__FILE1__
...
这时在@<packname>::FILE1数组中就保存了两个元素,当处理第二个FILE1的时候,将自动重新打开这个文件句柄。
一般来说,这些就够了,更多详细的用法请参见官方手册:Inline::Files。
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号