ZooKeeper系列(6):ZooKeeper的伸缩性和Observer角色
ZooKeeper系列文章:https://www.cnblogs.com/f-ck-need-u/p/7576137.html#zk
1.ZooKeeper中的角色
在比较老的ZooKeeper版本中,只有两种角色:leader和follower。后来引入了一种新角色Observer,Observer角色除了不能投票(以及和投票相关的能力)外,其它和follower功能一样。
所以,在ZooKeeper中:
- 投票角色:leader、follower。
- 无票角色:observer。
2.ZooKeeper如何处理请求?
ZooKeeper集群中的每个server都能为客户端提供读、写服务。
对于客户端的读请求,server会直接从它本地的内存数据库中取出数据返回给客户端,这个过程不涉及其它任何操作,也不会联系leader。
对于客户端的写请求,因为写操作会修改znode的数据、状态,所以必须要在ZooKeeper集群中进行协调。处理过程如下:
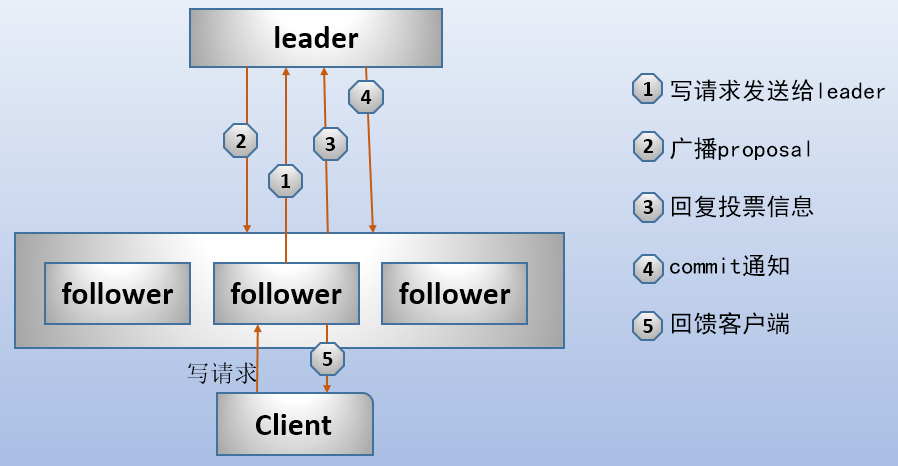
- 收到写请求的那个server,首先将写请求发送给leader。
- leader收到来自follower(或observer)的写请求后,首先计算这次写操作之后的状态,然后将这个写请求转换成带有各种状态的事务(如版本号、zxid等等)。
- leader将这个事务以提议的方式广播出去(即发送proposal)。
- 所有follower收到proposal后,对这个提议进行投票,投票完成后返回ack给leader。follower的投票只有两种方式:(1)确认这次提议表示同意;(2)丢弃这次提议表示不同意。
- leader收集投票结果,只要投票数量达到了大多数的要求(例如,5个节点的集群,3个或3个以上的节点才算大多数),这次提议就通过。
- 提议通过后,leader向所有server发送一个提交通知。
- 所有节点将这次事务写入事务日志,并进行提交。
- 提交后,收到写请求的那个server向客户端返回成功信息。
下面是ZooKeeper集群处理写请求过程的一个简图:
当ZooKeeper集群中follower的数量很多时,投票过程会成为一个性能瓶颈,为了解决投票造成的压力,于是出现了observer角色。
observer角色不参与投票,它只是投票结果的"听众",除此之外,它和follower完全一样,例如能接受读、写请求。就这一个特点,让整个ZooKeeper集群性能大大改善。
和follower一样,当observer收到客户端的读请求时,会直接从内存数据库中取出数据返回给客户端。
对于写请求,当写请求发送到某server上后,无论这个节点是follower还是observer,都会将它发送给leader。然后leader组织投票过程,所有server都收到这个proposal(包括observer,因为proposal是广播出去的),但是leader和follower以及observer通过配置文件,都知道自己是不是observer以及谁是observer。自己是observer的server不参与投票。当leader收集完投票后,将那些observer的server去掉,在剩下的server中计算大多数,如果投票结果达到了大多数,这次写事务就成功,于是leader通知所有的节点(包括observer),让它们将事务写入事务日志,并提交。
3.Observer的优点
observer角色除了减轻了投票的压力,还带来了几个额外的优点。
1.提高了伸缩性。
伸缩性指的是通过添加服务器来负载请求,从而提高整个集群处理请求的能力。也就是"一头牛拉不动了,找更多牛来拉"。
在出现Observer之前,ZooKeeper集群的伸缩性由follower来实现。虽然对于读写操作来说,follower是"无状态"的,这使得添加新的follower到集群(或者从集群中减少follower)很方便,能提高ZooKeeper集群负载能力。但是,对于投票来说,follower是有状态的,增、减follower的数量,都直接影响投票结果,特别是follower的数量越多,投票过程的性能就越差。
而observer无论是读写请求还是投票,都是无状态的,增、减observer的数量不会影响投票结果。这样就可以让一部分server作为follower参与投票,另一部分作为observer单纯地提供读写服务。这使得ZooKeeper的伸缩性大大提高。
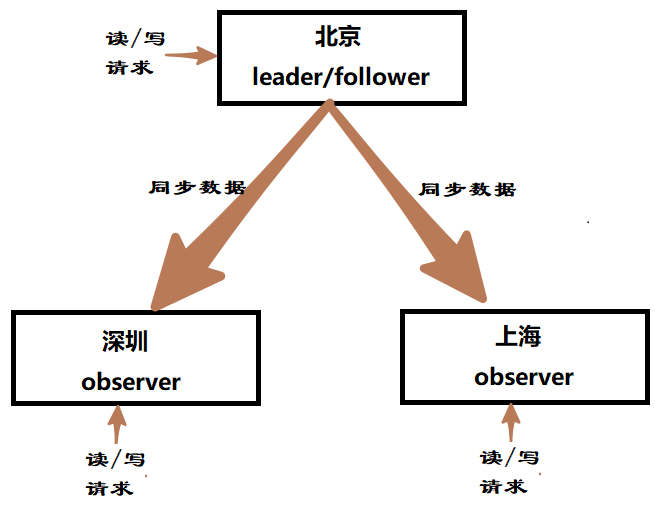
2.部署跨地区的ZooKeeper数据中心更方便。
observer能直接从本地内存数据库中取出数据来响应读请求,所以提高了读的吞吐量。对于写请求,虽然它要发送给leader并接受leader的通知,但相比于投票过程中传递的信息,它的数据量很小,所以即使在广域网也能有很好的性能。
实际上,很多跨机房、跨地区的数据中心就是通过observer来实现的。
4.如何配置Observer?
要配置observer,只需稍微修改一下配置文件即可。
首先,在想要成为observer的配置文件中,加上下面一行:
peerType=observer
这表示这个server以observer角色运行,即不参与投票。
再在所有 server的配置文件中,修改server.X配置项,在那些observer的节点上加上:observer后缀。
例如,server.1对应的server要作为observer:
server.1=IP:2181:3181:observer
这样配置后,ZooKeeper集群中的所有服务器节点都知道哪些节点扮演的是observer角色。
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号