rsync算法原理和工作流程分析
本文通过示例详细分析rsync算法原理和rsync的工作流程,是对rsync官方技术报告和官方推荐文章的解释。本文不会介绍如何使用rsync命令(见rsync基本用法),而是详细解释它如何实现高效的增量传输。
以下是rsync系列篇:
1.rsync(一):基本命令和用法
2.rsync(二):inotify+rsync详细说明和sersync
3.rsync算法原理和工作流程分析
4.rsync技术报告(翻译)
5.rsync工作机制(翻译)
6.man rsync翻译(rsync命令中文手册)
在开始分析算法原理之前,简单说明下rsync的增量传输功能。
假设待传输文件为A,如果目标路径下没有文件A,则rsync会直接传输文件A,如果目标路径下已存在文件A,则发送端视情况决定是否要传输文件A。rsync默认使用"quick check"算法,它会比较源文件和目标文件(如果存在)的文件大小和修改时间mtime,如果两端文件的大小或mtime不同,则发送端会传输该文件,否则将忽略该文件。
如果"quick check"算法决定了要传输文件A,它不会传输整个文件A,而是只传源文件A和目标文件A所不同的部分,这才是真正的增量传输。
也就是说,rsync的增量传输体现在两个方面:文件级的增量传输和数据块级别的增量传输。文件级别的增量传输是指源主机上有,但目标主机上没有将直接传输该文件,数据块级别的增量传输是指只传输两文件所不同的那一部分数据。但从本质上来说,文件级别的增量传输是数据块级别增量传输的特殊情况。通读本文后,很容易理解这一点。
1.1 需要解决的问题
假设主机α上有文件A,主机β上有文件B(实际上这两文件是同名文件,此处为了区分所以命名为A和B),现在要让B文件和A文件保持同步。
最简单的方法是将A文件直接拷贝到β主机上。但如果文件A很大,且B和A是相似的(意味着两文件实际内容只有少部分不同),拷贝整个文件A可能会消耗不少时间。如果可以拷贝A和B不同的那一小部分,则传输过程会很快。rsync增量传输算法就充分利用了文件的相似性,解决了远程增量拷贝的问题。
假设文件A的内容为"123xxabc def",文件B的内容为"123abcdefg"。A与B相比,相同的数据部分有123/abc/def,A中多出的内容为xx和一个空格,但文件B比文件A多出了数据g。最终的目标是让B和A的内容完全相同。
如果采用rsync增量传输算法,α主机将只传输文件A中的xx和空格数据给β主机,对于那些相同内容123/abc/def,β主机会直接从B文件中拷贝。根据这两个来源的数据,β主机就能组建成一个文件A的副本,最后将此副本文件重命名并覆盖掉B文件就保证了同步。
虽然看上去过程很简单,但其中有很多细节需要去深究。例如,α主机如何知道A文件中哪些部分和B文件不同,β主机接收了α主机发送的A、B不同部分的数据,如何组建文件A的副本。
1.2 rsync增量传输算法原理
假设执行的rsync命令是将A文件推到β主机上使得B文件和A文件保持同步,即主机α是源主机,是数据的发送端(sender),β是目标主机,是数据的接收端(receiver)。在保证B文件和A文件同步时,大致有以下6个过程:
(1).α主机告诉β主机文件A待传输。
(2).β主机收到信息后,将文件B划分为一系列大小固定的数据块(建议大小在500-1000字节之间),并以chunk号码对数据块进行编号,同时还会记录数据块的起始偏移地址以及数据块长度。显然最后一个数据块的大小可能更小。
对于文件B的内容"123abcdefg"来说,假设划分的数据块大小为3字节,则根据字符数划分成了以下几个数据块:
count=4 n=3 rem=1 这表示划分了4个数据块,数据块大小为3字节,剩余1字节给了最后一个数据块 chunk[0]:offset=0 len=3 该数据块对应的内容为123 chunk[1]:offset=3 len=3 该数据块对应的内容为abc chunk[2]:offset=6 len=3 该数据块对应的内容为def chunk[3]:offset=9 len=1 该数据块对应的内容为g
当然,实际信息中肯定是不会包括文件内容的。
(3).β主机对文件B的每个数据块根据其内容都计算两个校验码:32位的弱滚动校验码(rolling checksum)和128位的MD4强校验码(现在版本的rsync使用的已经是128位的MD5强校验码)。并将文件B计算出的所有rolling checksum和强校验码跟随在对应数据块chunk[N]后形成校验码集合,然后发送给主机α。
也就是说,校验码集合的内容大致如下:其中sum1为rolling checksum,sum2为强校验码。
chunk[0] sum1=3ef2c827 sum2=3efa923f8f2e7 chunk[1] sum1=57ac2aaf sum2=aef2dedba2314 chunk[2] sum1=92d7edb4 sum2=a6sd6a9d67a12 chunk[3] sum1=afe74939 sum2=90a12dfe7485c
需要注意,不同内容的数据块计算出的rolling checksum是有可能相同的,但是概率非常小。
(4).当α主机接收到文件B的校验码集合后,α主机将对此校验码集合中的每个rolling checksum计算16位长度的hash值,并将每216个hash值按照hash顺序放入一个hash table中,hash表中的每一个hash条目都指向校验码集合中它所对应的rolling checksum的chunk号码,然后对校验码集合根据hash值进行排序,这样排序后的校验码集合中的顺序就能和hash表中的顺序对应起来。
所以,hash表和排序后的校验码集合对应关系大致如下:假设hash表中的hash值是根据首个字符按照[0-9a-f]的顺序进行排序的。
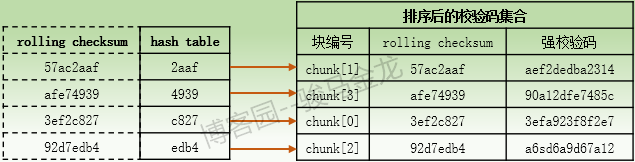
同样需要注意,不同rolling checksum计算出的hash值也是有可能会相同的,概率也比较小,但比rolling checksum出现重复的概率要大一些。
(5).随后主机α将对文件A进行处理。处理的过程是从第1个字节开始取相同大小的数据块,并计算它的校验码和校验码集合中的校验码进行匹配。如果能匹配上校验码集合中的某个数据块条目,则表示该数据块和文件B中数据块相同,它不需要传输,于是主机α直接跳转到该数据块的结尾偏移地址,从此偏移处继续取数据块进行匹配。如果不能匹配校验码集合中的数据块条目,则表示该数据块是非匹配数据块,它需要传输给主机β,于是主机α将跳转到下一个字节,从此字节处继续取数据块进行匹配。注意,匹配成功时跳过的是整个匹配数据块,匹配不成功时跳过的仅是一个字节。可以结合下一小节的示例来理解。
上面说的数据块匹配只是一种描述,具体的匹配行为需要进行细化。rsync算法将数据块匹配过程分为3个层次的搜索匹配过程。
首先,主机α会对取得的数据块根据它的内容计算出它的rolling checksum,再根据此rolling checksum计算出hash值。
然后,将此hash值去和hash表中的hash条目进行匹配,这是第一层次的搜索匹配过程,它比较的是hash值。如果在hash表中能找到匹配项,则表示该数据块存在潜在相同的可能性,于是进入第二层次的搜索匹配。
第二层次的搜索匹配是比较rolling checksum。由于第一层次的hash值匹配到了结果,所以将搜索校验码集合中与此hash值对应的rolling checksum。由于校验码集合是按照hash值排序过的,所以它的顺序和hash表中的顺序一致,也就是说只需从此hash值对应的rolling chcksum开始向下扫描即可。扫描过程中,如果A文件数据块的rolling checksum能匹配某项,则表示该数据块存在潜在相同的可能性,于是停止扫描,并进入第三层次的搜索匹配以作最终的确定。或者如果没有扫描到匹配项,则说明该数据块是非匹配块,也将停止扫描,这说明rolling checksum不同,但根据它计算的hash值却发生了小概率重复事件。
第三层次的搜索匹配是比较强校验码。此时将对A文件的数据块新计算一个强校验码(在第三层次之前,只对A文件的数据块计算了rolling checksum和它的hash值),并将此强校验码与校验码集合中对应强校验码匹配,如果能匹配则说明数据块是完全相同的,不能匹配则说明数据块是不同的,然后开始取下一个数据块进行处理。
之所以要额外计算hash值并放入hash表,是因为比较rolling checksum的性能不及hash值比较,且通过hash搜索的算法性能非常高。由于hash值重复的概率足够小,所以对绝大多数内容不同的数据块都能直接通过第一层次搜索的hash值比较出来,即使发生了小概率hash值重复事件,还能迅速定位并比较更小概率重复的rolling checksum。即使不同内容计算的rolling checksum也可能出现重复,但它的重复概率比hash值重复概率更小,所以通过这两个层次的搜索就能比较出几乎所有不同的数据块。假设不同内容的数据块的rolling checksum还是出现了小概率重复,它将进行第三层次的强校验码比较,它采用的是MD4(现在是MD5),这种算法具有"雪崩效应",只要一点点不同,结果都是天翻地覆的不同,所以在现实使用过程中,完全可以假设它能做最终的比较。
数据块大小会影响rsync算法的性能。如果数据块大小太小,则数据块的数量就太多,需要计算和匹配的数据块校验码就太多,性能就差,而且出现hash值重复、rolling checksum重复的可能性也增大;如果数据块大小太大,则可能会出现很多数据块都无法匹配的情况,导致这些数据块都被传输,降低了增量传输的优势。所以划分合适的数据块大小是非常重要的,默认情况下,rsync会根据文件大小自动判断数据块大小,但rsync命令的"-B"(或"--block-size")选项支持手动指定大小,如果手动指定,官方建议大小在500-1000字节之间。
(6).当α主机发现是匹配数据块时,将只发送这个匹配块的附加信息给β主机。同时,如果两个匹配数据块之间有非匹配数据,则还会发送这些非匹配数据。当β主机陆陆续续收到这些数据后,会创建一个临时文件,并通过这些数据重组这个临时文件,使其内容和A文件相同。临时文件重组完成后,修改该临时文件的属性信息(如权限、所有者、mtime等),然后重命名该临时文件替换掉B文件,这样B文件就和A文件保持了同步。
1.3 通过示例分析rsync算法
前面说了这么多理论,可能已经看的云里雾里,下面通过A和B文件的示例来详细分析上一小节中的增量传输算法原理,由于上一小节中的过程(1)-(4),已经给出了示例,所以下面将继续分析过程(5)和过程(6)。
先看文件B(内容为"123abcdefg")排序后的校验码集合以及hash表。
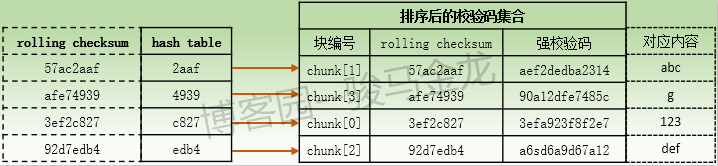
当主机α开始处理文件A时,对于文件A的内容"123xxabc def"来说,从第一个字节开始取大小相同的数据块,所以取得的第一个数据块的内容是"123",由于和文件B的chunk[0]内容完全相同,所以α主机对此数据块计算出的rolling checksum值肯定是"3ef2e827",对应的hash值为"e827"。于是α主机将此hash值去匹配hash表,匹配过程中发现指向chunk[0]的hash值能匹配上,于是进入第二层次的rolling checksum比较,也即从此hash值指向的chunk[0]的条目处开始向下扫描。扫描过程中发现扫描的第一条信息(即chunk[0]对应的条目)的rollign checksum就能匹配上,所以扫描终止,于是进入第三层次的搜索匹配,这时α主机将对"123"这个数据块新计算一个强校验码,与校验码集合中chunk[0]对应的强校验码做比较,最终发现能匹配上,于是确定了文件A中的"123"数据块是匹配数据块,不需要传输给β主机。
虽然匹配数据块不用传输,但匹配的相关信息需要立即传输给β主机,否则β主机不知道如何重组文件A的副本。匹配块需要传输的信息包括:匹配的是B文件中的chunk[0]数据块,在文件A中偏移该数据块的起始偏移地址为第1个字节,长度为3字节。
数据块"123"的匹配信息传输完成后,α主机将取第二个数据块进行处理。本来应该是从第2个字节开始取数据块的,但由于数据块"123"中3个字节完全匹配成功,所以可以直接跳过整个数据块"123",即从第4个字节开始取数据块,所以α主机取得的第2个数据块内容为"xxa"。同样,需要计算它的rolling checksum和hash值,并搜索匹配hash表中的hash条目,发现没有任何一条hash值可以匹配上,于是立即确定该数据块是非匹配数据块。
此时α主机将继续向前取A文件中的第三个数据块进行处理。由于第二个数据块没有匹配上,所以取第三个数据块时只跳过了一个字节的长度,即从第5个字节开始取,取得的数据块内容为"xab"。经过一番计算和匹配,发现这个数据块和第二个数据块一样是无法匹配的数据块。于是继续向前跳过一个字节,即从第6个字节开始取第四个数据块,这次取得的数据块内容为"abc",这个数据块是匹配数据块,所以和第一个数据块的处理方式是一样的,唯一不同的是第一个数据块到第四个数据块,中间两个数据块是非匹配数据块,于是在确定第四个数据块是匹配数据块后,会将中间的非匹配内容(即123xxabc中间的xx)逐字节发送给β主机。
(前文说过,hash值和rolling checksum是有小概率发生重复,出现重复时匹配如何进行?见本小节的尾部)
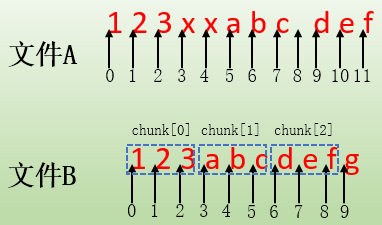
依此方式处理完A中所有数据块,最终有3个匹配数据块chunk[0]、chunk[1]和chunk[2],以及2段非匹配数据"xx"和" "。这样β主机就收到了匹配数据块的匹配信息以及逐字节的非匹配纯数据,这些数据是β主机重组文件A副本的关键信息。它的大致内容如下:
chunk[0] of size 3 at 0 offset=0 data receive 2 at 3 chunk[1] of size 3 at 3 offset=5 data receive 1 at 8 chunk[2] of size 3 at 6 offset=9
为了说明这段信息,首先看文件A和文件B的内容,并标出它们的偏移地址。
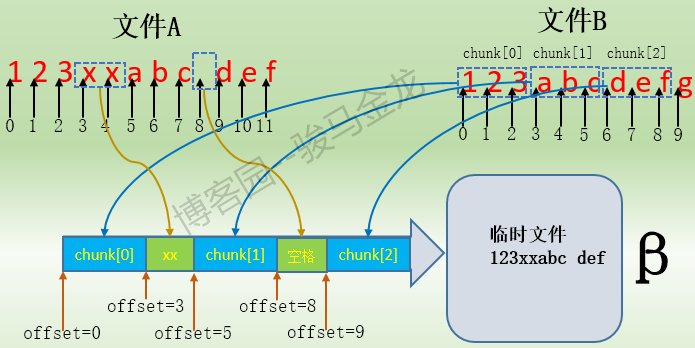
对于"chunk[0] of size 3 at 0 offset=0",这一段表示这是一个匹配数据块,匹配的是文件B中的chunk[0],数据块大小为3字节,关键词at表示这个匹配块在文件B中的起始偏移地址为0,关键词offset表示这个匹配块在文件A中起始偏移地址也为0,它也可以认为是重组临时文件中的偏移。也就是说,在β主机重组文件时,将从文件B的"at 0"偏移处拷贝长度为3字节的chunk[0]对应的数据块,并将这个数据块内容写入到临时文件中的offset=0偏移处,这样临时文件中就有了第一段数据"123"。
对于"data receive 2 at 3",这一段表示这是接收的纯数据信息,不是匹配数据块。2表示接收的数据字节数,"at 3"表示在临时文件的起始偏移3处写入这两个字节的数据。这样临时文件就有了包含了数据"123xx"。
对于"chunk[1] of size 3 at 3 offset=5",这一段表示是匹配数据块,表示从文件B的起始偏移地址at=3处拷贝长度为3字节的chunk[1]对应的数据块,并将此数据块内容写入在临时文件的起始偏移offset=5处,这样临时文件就有了"123xxabc"。
对于"data receive 1 at 8",这一说明接收了纯数据信息,表示将接收到的1个字节的数据写入到临时文件的起始偏移地址8处,所以临时文件中就有了"123xxabc "。
最后一段"chunk[2] of size 3 at 6 offset=9",表示从文件B的起始偏移地址at=6处拷贝长度为3字节的chunk[2]对应的数据块,并将此数据块内容写入到临时文件的起始偏移offset=9处,这样临时文件就包含了"123xxabc def"。到此为止,临时文件就重组结束了,它的内容和α主机上A文件的内容是完全一致的,然后只需将此临时文件的属性修改一番,并重命名替换掉文件B即可,这样就将文件B和文件A进行了同步。
整个过程如下图:
需要注意的是,α主机不是搜索完所有数据块之后才将相关数据发送给β主机的,而是每搜索出一个匹配数据块,就会立即将匹配块的相关信息以及当前匹配块和上一个匹配块中间的非匹配数据发送给β主机,并开始处理下一个数据块,当β主机每收到一段数据后会立即将将其重组到临时文件中。因此,α主机和β主机都尽量做到了不浪费任何资源。
1.3.1 hash值和rolling checksum重复时的匹配过程
在上面的示例分析中,没有涉及hash值重复和rolling checksum重复的情况,但它们有可能会重复,虽然重复后的匹配过程是一样的,但可能不那么容易理解。
还是看B文件排序后的校验码集合。
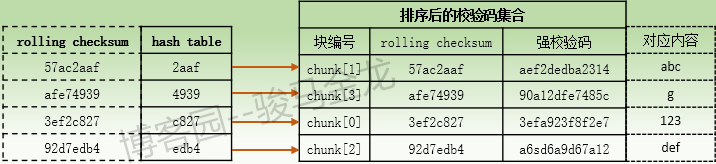
当文件A处理数据块时,假设处理的是第2个数据块,它是非匹配数据块,对此数据块会计算rolling checksum和hash值。假设此数据块的hash值从hash表中匹配成功,例如匹配到了上图中"4939"这个值,于是会将此第二个数据块的rolling checksum与hash值"4939"所指向的chunk[3]的rolling checksum作比较,hash值重复且rolling checksum重复的可能性几乎趋近于0,所以就能确定此数据块是非匹配数据块。
考虑一种极端情况,假如文件B比较大,划分的数据块数量也比较多,那么B文件自身包含的数据块的rolling checksum就有可能会出现重复事件,且hash值也可能会出现重复事件。
例如chunk[0]和chunk[3]的rolling checksum不同,但根据rolling checksum计算的hash值却相同,此时hash表和校验码集合的对应关系大致如下:
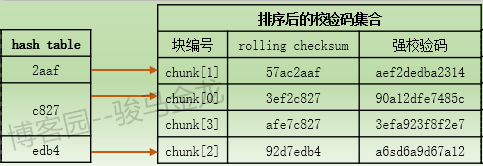
如果文件A中正好有数据块的hash值能匹配到"c827",于是准备比较rolling checksum,此时将从hash值"c827"指向的chunk[0]向下扫描校验码集合。当扫描过程中发现数据块的rolling checksum正好能匹配到某个rolling checksum,如chunk[0]或chunk[3]对应的rolling checksum,则扫描终止,并进入第三层次的搜索匹配。如果向下扫描的过程中发现直到chunk[2]都没有找到能匹配的rolling checksum,则扫描终止,因为chunk[2]的hash值和数据块的hash值已经不同,最终确定该数据块是非匹配数据块,于是α主机继续向前处理下一个数据块。
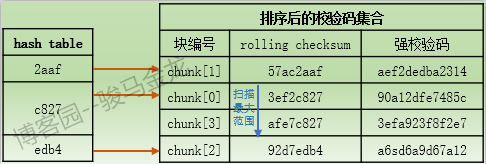
假如文件B中数据块的rolling checksum出现了重复(这只说明一件事,你太幸运),将只能通过强校验码来匹配。
1.4 rsync工作流程分析
上面已经把rsync增量传输的核心分析过了,下面将分析rsync对增量传输算法的实现方式以及rsync传输的整个过程。在这之前,有必要先解释下rsync传输过程中涉及的client/server、sender、receiver、generator等相关概念。
1.4.1 几个进程和术语
rsync有3种工作方式。一是本地传输方式,二是使用远程shell连接方式,三是使用网络套接字连接rsync daemon模式。
使用远程shell如ssh连接方式时,本地敲下rsync命令后,将请求和远程主机建立远程shell连接如ssh连接,连接建立成功后,在远程主机上将fork远程shell进程调用远程rsync程序,并将rsync所需的选项通过远程shell命令如ssh传递给远程rsync。这样两端就都启动了rsync,之后它们将通过管道的方式(即使它们之间是本地和远程的关系)进行通信。
使用网络套接字连接rsync daemon时,当通过网络套接字和远程已运行好的rsync建立连接时,rsync daemon进程会创建一个子进程来响应该连接并负责后续该连接的所有通信。这样两端也都启动了连接所需的rsync,此后通信方式是通过网络套接字来完成的。
本地传输其实是一种特殊的工作方式,首先rsync命令执行时,会有一个rsync进程,然后根据此进程fork另一个rsync进程作为连接的对端,连接建立之后,后续所有的通信将采用管道的方式。
无论使用何种连接方式,发起连接的一端被称为client,也即执行rsync命令的一段,连接的另一端称为server端。注意,server端不代表rsync daemon端。server端在rsync中是一个通用术语,是相对client端而言的,只要不是client端,都属于server端,它可以是本地端,也可以是远程shell的对端,还可以是远程rsync daemon端,这和大多数daemon类服务的server端不同。
rsync的client和server端的概念存活周期很短,当client端和server端都启动好rsync进程并建立好了rsync连接(管道、网络套接字)后,将使用sender端和receiver端来代替client端和server端的概念。sender端为文件发送端,receiver端为文件接收端。
当两端的rsync连接建立后,sender端的rsync进程称为sender进程,该进程负责sender端所有的工作。receiver端的rsync进程称为receiver进程,负责接收sender端发送的数据,以及完成文件重组的工作。receiver端还有一个核心进程——generator进程,该进程负责在receiver端执行"--delete"动作、比较文件大小和mtime以决定文件是否跳过、对每个文件划分数据块、计算校验码以及生成校验码集合,然后将校验码集合发送给sender端。
rsync的整个传输过程由这3个进程完成,它们是高度流水线化的,generator进程的输出结果作为sender端的输入,sender端的输出结果作为recevier端的输入。即:
generator进程-->sender进程-->receiver进程
虽然这3个进程是流水线式的,但不意味着它们存在数据等待的延迟,它们是完全独立、并行工作的。generator计算出一个文件的校验码集合发送给sender,会立即计算下一个文件的校验码集合,而sender进程一收到generator的校验码集合会立即开始处理该文件,处理文件时每遇到一个匹配块都会立即将这部分相关数据发送给receiver进程,然后立即处理下一个数据块,而receiver进程收到sender发送的数据后,会立即开始重组工作。也就是说,只要进程被创建了,这3个进程之间是不会互相等待的。
另外,流水线方式也不意味着进程之间不会通信,只是说rsync传输过程的主要工作流程是流水线式的。例如receiver进程收到文件列表后就将文件列表交给generator进程。
1.4.2 rsync整个工作流程
假设在α主机上执行rsync命令,将一大堆文件推送到β主机上。
1.首先client和server建立rsync通信的连接,远程shell连接方式建立的是管道,连接rsync daemon时建立的是网络套接字。
2.rsync连接建立后,sender端的sender进程根据rsync命令行中给出的源文件收集待同步文件,将这些文件放入文件列表(file list)中并传输给β主机。在创建文件列表的过程中,有几点需要说明:
(1).创建文件列表时,会先按照目录进行排序,然后对排序后的文件列表中的文件进行编号,以后将直接使用文件编号来引用文件。
(2).文件列表中还包含文件的一些属性信息,包括:权限mode,文件大小len,所有者和所属组uid/gid,最近修改时间mtime等,当然,有些信息是需要指定选项后才附带的,例如不指定"-o"和"-g"选项将不包含uid/gid,指定"--checksum"公还将包含文件级的checksum值。
(3).发送文件列表时不是收集完成后一次性发送的,而是按照顺序收集一个目录就发送一个目录,同理receiver接收时也是一个目录一个目录接收的,且接收到的文件列表是已经排过序的。
(4).如果rsync命令中指定了exclude或hide规则,则被这些规则筛选出的文件会在文件列表中标记为hide(exclude规则的本质也是hide)。带有hide标志的文件对receiver是不可见的,所以receiver端会认为sender端没有这些被hide的文件。
3.receiver端从一开始接收到文件列表中的内容后,立即根据receiver进程fork出generator进程。generator进程将根据文件列表扫描本地目录树,如果目标路径下文件已存在,则此文件称为basis file。
generator的工作总体上分为3步:
(1).如果rsync命令中指定了"--delete"选项,则首先在β主机上执行删除动作,删除源路径下没有,但目标路径下有的文件。
(2).然后根据file list中的文件顺序,逐个与本地对应文件的文件大小和mtime做比较。如果发现本地文件的大小或mtime与file list中的相同,则表示该文件不需要传输,将直接跳过该文件。
(3).如果发现本地文件的大小或mtime不同,则表示该文件是需要传输的文件,generator将立即对此文件划分数据块并编号,并对每个数据块计算弱滚动校验码(rolling checksum)和强校验码,并将这些校验码跟随数据块编号组合在一起形成校验码集合,然后将此文件的编号和校验码集合一起发送给sender端。发送完毕后开始处理file list中的下一个文件。
需要注意,α主机上有而β主机上没有的文件,generator会将文件列表中的此文件的校验码设置为空发送给sender。如果指定了"--whole-file"选项,则generator会将file list中的所有文件的校验码都设置为空,这样将使得rsync强制采用全量传输功能,而不再使用增量传输功能。
从下面的步骤4开始,这些步骤在前文分析rsync算法原理时已经给出了非常详细的解释,所以此处仅概括性地描述,如有不解之处,请翻到前文查看相关内容。
4.sender进程收到generator发送的数据,会读取文件编号和校验码集合。然后根据校验码集合中的弱滚动校验码(rolling checksum)计算hash值,并将hash值放入hash表中,且对校验码集合按照hash值进行排序,这样校验码集合和hash表的顺序就能完全相同。
5.sender进程对校验码集合排序完成后,根据读取到的文件编号处理本地对应的文件。处理的目的是找出能匹配的数据块(即内容完全相同的数据块)以及非匹配的数据。每当找到匹配的数据块时,都将立即发送一些匹配信息给receiver进程。当发送完文件的所有数据后,sender进程还将对此文件生成一个文件级的whole-file校验码给receiver。
6.receiver进程接收到sender发送的指令和数据后,立即在目标路径下创建一个临时文件,并按照接收到的数据和指令重组该临时文件,目的是使该文件和α主机上的文件完全一致。重组过程中,能匹配的数据块将从basis file中copy并写入到临时文件,非匹配的数据则是接收自sender端。
7.临时文件重组完成后,将对此临时文件生成文件级的校验码,并与sender端发送的whole-file校验码比较,如果能匹配成功则表示此临时文件和源文件是完全相同的,也就表示临时文件重组成功,如果校验码匹配失败,则表示重组过程中可能出错,将完全从头开始处理此源文件。
8.当临时文件重组成功后,receiver进程将修改该临时文件的属性信息,包括权限、所有者、所属组、mtime等。最后将此文件重命名并覆盖掉目标路径下已存在的文件(即basis file)。至此,文件同步完成。
1.5 根据执行过程分析rsync工作流程
为了更直观地感受上文所解释的rsync算法原理和工作流程,下面将给出两个rsync执行过程的示例,并分析工作流程,一个是全量传输的示例,一个是增量传输的示例。
要查看rsync的执行过程,执行在rsync命令行中加上"-vvvv"选项即可。
1.5.1 全量传输执行过程分析
要执行的命令为:
[root@xuexi ~]# rsync -a -vvvv /etc/cron.d /var/log/anaconda /etc/issue longshuai@172.16.10.5:/tmp
目的是将/etc/cron.d目录、/var/log/anaconda目录和/etc/issue文件传输到172.16.10.5主机上的/tmp目录下,由于/tmp目录下不存在这些文件,所以整个过程是全量传输的过程。但其本质仍然是采用增量传输的算法,只不过generator发送的校验码集合全为空而已。
以下是/etc/cron.d目录和/var/log/anaconda目录的层次结构。
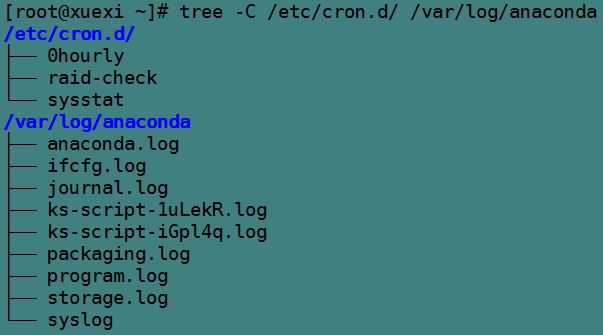
以下是执行过程。
[root@xuexi ~]# rsync -a -vvvv /etc/cron.d /var/log/anaconda /etc/issue longshuai@172.16.10.5:/tmp # 使用ssh(ssh为默认的远程shell)执行远程rsync命令建立连接 cmd=<NULL> machine=172.16.10.5 user=longshuai path=/tmp cmd[0]=ssh cmd[1]=-l cmd[2]=longshuai cmd[3]=172.16.10.5 cmd[4]=rsync cmd[5]=--server cmd[6]=-vvvvlogDtpre.iLsf cmd[7]=. cmd[8]=/tmp opening connection using: ssh -l longshuai 172.16.10.5 rsync --server -vvvvlogDtpre.iLsf . /tmp note: iconv_open("UTF-8", "UTF-8") succeeded. longshuai@172.16.10.5's password: # 双方互相发送协议版本号,并协商使用两者较低版本 (Server) Protocol versions: remote=30, negotiated=30 (Client) Protocol versions: remote=30, negotiated=30 ######### sender端生成文件列表并发送给receiver端 ############# sending incremental file list [sender] make_file(cron.d,*,0) # 第一个要传输的文件目录:cron.d文件,注意,此处cron.d是待传输的文件,而不认为是目录 [sender] make_file(anaconda,*,0) # 第二个要传输的文件目录:anaconda文件 [sender] make_file(issue,*,0) # 第三个要传输的文件目录:issue文件 # 指明从文件列表的第1项开始,并确定这次要传输给receiver的项共有3个 [sender] flist start=1, used=3, low=0, high=2 # 为这3项生成列表信息,包括此文件id,所在目录,权限模式,长度,uid/gid,最后还有一个修饰符 [sender] i=1 /etc issue mode=0100644 len=23 uid=0 gid=0 flags=5 [sender] i=2 /var/log anaconda/ mode=040755 len=4096 uid=0 gid=0 flas=5 [sender] i=3 /etc cron.d/ mode=040755 len=51 uid=0 gid=0 flags=5 send_file_list done file list sent # 唯一需要注意的是文件所在目录,例如/var/log anaconda/,但实际在命令行中指定的是/var/log/anaconda。 # 此处信息中log和anaconda使用空格分开了,这个空格非常关键。空格左边的表示隐含目录(见man rsync的"-R"选项), # 右边的是待传输的整个文件或目录,默认情况下将会在receiver端生成anaconda/目录,但左边隐含目录则不会创建。 # 但可以通过指定特殊选项(如"-R"),让rsync也能在receiver端同时创建隐含目录,以便创建整个目录层次结构。 # 举个例子,如果A主机的/a目录下有b、c等众多子目录,并且b目录中有d文件,现在只想传输/a/b/d并保留/a/b的目录层次结构, # 那么可以通过特殊选项让此处的文件所在目录变为"/ a/",关于具体的实现方法,见"rsync -R选项示例"。 ############ sender端发送文件属性信息 ##################### # 由于前面的文件列表中有两个条目是目录,因此还要为目录中的每个文件生成属性信息并发送给receiver端 send_files starting [sender] make_file(anaconda/anaconda.log,*,2) [sender] make_file(anaconda/syslog,*,2) [sender] make_file(anaconda/program.log,*,2) [sender] make_file(anaconda/packaging.log,*,2) [sender] make_file(anaconda/storage.log,*,2) [sender] make_file(anaconda/ifcfg.log,*,2) [sender] make_file(anaconda/ks-script-1uLekR.log,*,2) [sender] make_file(anaconda/ks-script-iGpl4q.log,*,2) [sender] make_file(anaconda/journal.log,*,2) [sender] flist start=5, used=9, low=0, high=8 [sender] i=5 /var/log anaconda/anaconda.log mode=0100600 len=6668 uid=0 gid=0 flags=0 [sender] i=6 /var/log anaconda/ifcfg.log mode=0100600 len=3826 uid=0 gid=0 flags=0 [sender] i=7 /var/log anaconda/journal.log mode=0100600 len=1102699 uid=0 gid=0 flags=0 [sender] i=8 /var/log anaconda/ks-script-1uLekR.log mode=0100600 len=0 uid=0 gid=0 flags=0 [sender] i=9 /var/log anaconda/ks-script-iGpl4q.log mode=0100600 len=0 uid=0 gid=0 flags=0 [sender] i=10 /var/log anaconda/packaging.log mode=0100600 len=160420 uid=0 gid=0 flags=0 [sender] i=11 /var/log anaconda/program.log mode=0100600 len=27906 uid=0 gid=0 flags=0 [sender] i=12 /var/log anaconda/storage.log mode=0100600 len=78001 uid=0 gid=0 flags=0 [sender] i=13 /var/log anaconda/syslog mode=0100600 len=197961 uid=0 gid=0 flags=0 [sender] make_file(cron.d/0hourly,*,2) [sender] make_file(cron.d/sysstat,*,2) [sender] make_file(cron.d/raid-check,*,2) [sender] flist start=15, used=3, low=0, high=2 [sender] i=15 /etc cron.d/0hourly mode=0100644 len=128 uid=0 gid=0 flags=0 [sender] i=16 /etc cron.d/raid-check mode=0100644 len=108 uid=0 gid=0 flags=0 [sender] i=17 /etc cron.d/sysstat mode=0100600 len=235 uid=0 gid=0 flags=0 # 从上述结果中发现,没有i=4和i=14的文件信息,因为它们是目录anaconda和cron.d的文件信息 # 还发现没有发送/etc/issue文件的信息,因为issue自身是普通文件而非目录,因此在发送目录前就发送了 ############# 文件列表所有内容发送完毕 #################### ############### server端相关活动内容 ################ # 首先在server端启动rsync进程 server_recv(2) starting pid=13309 # 接收client第一次传输的数据,此次传输server端收到3条数据,它们是传输中根目录下的文件或目录 received 3 names [receiver] flist start=1, used=3, low=0, high=2 [receiver] i=1 1 issue mode=0100644 len=23 gid=(0) flags=400 [receiver] i=2 1 anaconda/ mode=040755 len=4096 gid=(0) flags=405 [receiver] i=3 1 cron.d/ mode=040755 len=51 gid=(0) flags=405 recv_file_list done # 第一次接收数据完成 ############ 在receiver端启动generator进程 ######## get_local_name count=3 /tmp # 获取本地路径名 generator starting pid=13309 # 启动generator进程 delta-transmission enabled # 启用增量传输算法 ############ generator进程设置完毕 ################ ############# 首先处理接收到的普通文件 ############## recv_generator(issue,1) # generator收到receiver进程通知的文件id=1的文件issue send_files(1, /etc/issue) count=0 n=0 rem=0 # 此项为目标主机上的文件issue分割的数据块信息,count表示数量,n表示数据块的固定大小, # rem是remain的意思,表示剩余的数据长度,也即最后一个数据块的大小, # 此处因为目标端不存在issue文件,因此全部设置为0 send_files mapped /etc/issue of size 23 # sender端映射/etc/issue,使得sender可以获取到该文件的相关内容 calling match_sums /etc/issue # sender端调用校验码匹配功能 issue sending file_sum # 匹配结束后,再发送文件级的checksum给receiver端 false_alarms=0 hash_hits=0 matches=0 # 输出数据块匹配的相关统计信息 sender finished /etc/issue # 文件/etc/issue发送完毕,因为目标上不存在issue文件,所以整个过程非常简单,直接传输issue中的全部数据即可 ############## 开始处理目录格式的文件列表 ############# # 首先接收到两个id=2和id=3的文件 recv_generator(anaconda,2) recv_generator(cron.d,3) # 然后开始从文件列表的目录中获取其中的文件信息 recv_files(3) starting # 先获取的是dir 0的目录中的文件信息 [receiver] receiving flist for dir 0 [generator] receiving flist for dir 0 received 9 names # 表示从该目录中收到了9条文件信息 [generator] flist start=5, used=9, low=0, high=8 # 文件的id号从5开始,总共有9个条目 [generator] i=5 2 anaconda/anaconda.log mode=0100600 len=6668 gid=(0) flags=400 [generator] i=6 2 anaconda/ifcfg.log mode=0100600 len=3826 gid=(0) flags=400 [generator] i=7 2 anaconda/journal.log mode=0100600 len=1102699 gid=(0) flags=400 [generator] i=8 2 anaconda/ks-script-1uLekR.log mode=0100600 len=0 gid=(0) flags=400 [generator] i=9 2 anaconda/ks-script-iGpl4q.log mode=0100600 len=0 gid=(0) flags=400 [generator] i=10 2 anaconda/packaging.log mode=0100600 len=160420 gid=(0) flags=400 [generator] i=11 2 anaconda/program.log mode=0100600 len=27906 gid=(0) flags=400 [generator] i=12 2 anaconda/storage.log mode=0100600 len=78001 gid=(0) flags=400 [generator] i=13 2 anaconda/syslog mode=0100600 len=197961 gid=(0) flags=400 recv_file_list done # dir 0目录中的文件信息接收完毕 [receiver] receiving flist for dir 1 # 然后获取的是dir 1的目录中的文件信息 [generator] receiving flist for dir 1 received 3 names [generator] flist start=15, used=3, low=0, high=2 [generator] i=15 2 cron.d/0hourly mode=0100644 len=128 gid=(0) flags=400 [generator] i=16 2 cron.d/raid-check mode=0100644 len=108 gid=(0) flags=400 [generator] i=17 2 cron.d/sysstat mode=0100600 len=235 gid=(0) flags=400 recv_file_list done # dir 1目录中的文件信息接收完毕 ################# 开始传输目录dir 0及其内文件 ############# recv_generator(anaconda,4) # generator接收目录anaconda信息,它的id=4,是否还记得上文sender未发送过id=4和 # id=14的目录信息?只有先接收该目录,才能继续接收该目录中的文件 send_files(4, /var/log/anaconda) # 因为anaconda是要在receiver端创建的目录,所以sender端先发送该目录文件 anaconda/ # anaconda目录发送成功 set modtime of anaconda to (1494476557) Thu May 11 12:22:37 2017 # 然后再设置目录anaconda的mtime(即modify time) # receiver端的anaconda目录已经建立,现在开始传输anaconda中的文件 # 以下的第一个anaconda目录中的第一个文件处理过程 recv_generator(anaconda/anaconda.log,5) # generator进程接收id=5的anaconda/anaconda.log文件 send_files(5, /var/log/anaconda/anaconda.log) count=0 n=0 rem=0 # 计算该文件数据块相关信息 send_files mapped /var/log/anaconda/anaconda.log of size 6668 # sender端映射anaconda.log文件 calling match_sums /var/log/anaconda/anaconda.log # 调用校验码匹配功能 anaconda/anaconda.log sending file_sum # 数据块匹配结束后,再发送文件级别的checksum给receiver端 false_alarms=0 hash_hits=0 matches=0 # 输出匹配过程中的统计信息 sender finished /var/log/anaconda/anaconda.log # anaconda.log文件传输完成 recv_generator(anaconda/ifcfg.log,6) # 开始处理anaconda中的第二个文件 send_files(6, /var/log/anaconda/ifcfg.log) count=0 n=0 rem=0 send_files mapped /var/log/anaconda/ifcfg.log of size 3826 calling match_sums /var/log/anaconda/ifcfg.log anaconda/ifcfg.log sending file_sum false_alarms=0 hash_hits=0 matches=0 sender finished /var/log/anaconda/ifcfg.log # 第二个文件传输完毕 recv_generator(anaconda/journal.log,7) # 开始处理anaconda中的第三个文件 send_files(7, /var/log/anaconda/journal.log) count=0 n=0 rem=0 send_files mapped /var/log/anaconda/journal.log of size 1102699 calling match_sums /var/log/anaconda/journal.log anaconda/journal.log sending file_sum false_alarms=0 hash_hits=0 matches=0 sender finished /var/log/anaconda/journal.log # 第二个文件传输完毕 #以下类似过程省略 ...... recv_generator(anaconda/syslog,13) # 开始处理anaconda中的最后一个文件 send_files(13, /var/log/anaconda/syslog) count=0 n=0 rem=0 send_files mapped /var/log/anaconda/syslog of size 197961 calling match_sums /var/log/anaconda/syslog anaconda/syslog sending file_sum false_alarms=0 hash_hits=0 matches=0 sender finished /var/log/anaconda/syslog # anaconda目录中所有文件传输完毕 ################# 开始传输目录dir 1及其内文件 ############# recv_generator(cron.d,14) send_files(14, /etc/cron.d) cron.d/ set modtime of cron.d to (1494476430) Thu May 11 12:20:30 2017 recv_generator(cron.d/0hourly,15) send_files(15, /etc/cron.d/0hourly) count=0 n=0 rem=0 send_files mapped /etc/cron.d/0hourly of size 128 calling match_sums /etc/cron.d/0hourly cron.d/0hourly sending file_sum false_alarms=0 hash_hits=0 matches=0 sender finished /etc/cron.d/0hourly ......类似过程省略...... recv_generator(cron.d/sysstat,17) send_files(17, /etc/cron.d/sysstat) count=0 n=0 rem=0 send_files mapped /etc/cron.d/sysstat of size 235 calling match_sums /etc/cron.d/sysstat cron.d/sysstat sending file_sum false_alarms=0 hash_hits=0 matches=0 sender finished /etc/cron.d/sysstat ############## 以下是receiver端文件重组相关过程 ################ generate_files phase=1 # generator进程进入第一阶段 # 重组第一个文件issue recv_files(issue) data recv 23 at 0 # data recv关键字表示从sender端获取的纯文件数据,23表示接收到的这一段纯数据大小为23字节, # at 0表示接收的这段数据放在临时文件的起始偏移0处。 got file_sum # 获取到sender端最后发送的文件级的checksum,并进行检查,检查通过则表示重组正式完成 set modtime of .issue.RpT9T9 to (1449655155) Wed Dec 9 17:59:15 2015 # 临时文件重组完成后,设置临时文件的mtime renaming .issue.RpT9T9 to issue # 最后将临时文件重命名为目标文件 # 至此,第一个文件真正完成同步 # 重组第二个文件列表anaconda及其内文件 recv_files(anaconda) # 重组目录anaconda recv_files(anaconda/anaconda.log) # 重组目录anaconda中的第一个文件 data recv 6668 at 0 got file_sum set modtime of anaconda/.anaconda.log.LAR2t1 to (1494476557) Thu May 11 12:22:37 2017 renaming anaconda/.anaconda.log.LAR2t1 to anaconda/anaconda.log # anaconda目录中的第一个文件同步完成 recv_files(anaconda/ifcfg.log) # 重组目录anaconda中的第二个文件 data recv 3826 at 0 got file_sum set modtime of anaconda/.ifcfg.log.bZDW3S to (1494476557) Thu May 11 12:22:37 2017 renaming anaconda/.ifcfg.log.bZDW3S to anaconda/ifcfg.log # anaconda目录中的第二个文件同步完成 recv_files(anaconda/journal.log) # 重组目录anaconda中的第三个文件 data recv 32768 at 0 # 由于每次传输的数据量最大为32kB,因此对于较大的journal.log分成了多次进行传输 data recv 32768 at 32768 data recv 32768 at 65536 .............. got file_sum set modtime of anaconda/.journal.log.ylpZDK to (1494476557) Thu May 11 12:22:37 2017 renaming anaconda/.journal.log.ylpZDK to anaconda/journal.log # anaconda目录中的第三个文件同步完成 .........中间类似过程省略........... recv_files(anaconda/syslog) data recv 32768 at 0 data recv 32768 at 32768 data recv 32768 at 65536 ................ got file_sum set modtime of anaconda/.syslog.zwQynW to (1494476557) Thu May 11 12:22:37 2017 renaming anaconda/.syslog.zwQynW to anaconda/syslog # 至此,anaconda及其内所有文件都同步完毕 # 重组第三个文件列表cron.d及其内文件 recv_files(cron.d) recv_files(cron.d/0hourly) ......中间类似过程省略.......... recv_files(cron.d/sysstat) data recv 235 at 0 got file_sum set modtime of cron.d/.sysstat.m4hzgx to (1425620722) Fri Mar 6 13:45:22 2015 renaming cron.d/.sysstat.m4hzgx to cron.d/sysstat # 至此,cron.d及其内所有文件都同步完毕 send_files phase=1 touch_up_dirs: cron.d (1) # sender进程修改上层目录cron.d的各种时间戳 set modtime of cron.d to (1494476430) Thu May 11 12:20:30 2017 # 设置cron.d目录的mtime recv_files phase=1 generate_files phase=2 send_files phase=2 send files finished # sender进程消逝,并输出匹配的统计信息以及传输的总的纯数据量 total: matches=0 hash_hits=0 false_alarms=0 data=1577975 recv_files phase=2 generate_files phase=3 recv_files finished generate_files finished client_run waiting on 13088 sent 1579034 bytes received 267 bytes 242969.38 bytes/sec # 总共发送了1579034字节的数据,此项统计包括了纯文件数据以 # 及各种非文件数据,接收到了来自receiver端的267字节的数据 total size is 1577975 speedup is 1.00 # sender端所有文件总大小为1577975字节,因为receiver端完全没有basis file, # 所以总大小等于传输的纯数据量 [sender] _exit_cleanup(code=0, file=main.c, line=1052): entered [sender] _exit_cleanup(code=0, file=main.c, line=1052): about to call exit(0)
1.5.2 增量传输执行过程分析
要执行的命令为:
[root@xuexi ~]# rsync -vvvv /tmp/init 172.16.10.5:/tmp
目的是将/etc/init文件传输到172.16.10.5主机上的/tmp目录下,由于/tmp目录下已经存在该文件,所以整个过程是增量传输的过程。
以下是执行过程。
[root@xuexi ~]# rsync -vvvv /tmp/init 172.16.10.5:/tmp # 使用ssh(ssh为默认的远程shell)执行远程rsync命令建立连接 cmd=<NULL> machine=172.16.10.5 user=<NULL> path=/tmp cmd[0]=ssh cmd[1]=172.16.10.5 cmd[2]=rsync cmd[3]=--server cmd[4]=-vvvve.Lsf cmd[5]=. cmd[6]=/tmp opening connection using: ssh 172.16.10.5 rsync --server -vvvve.Lsf . /tmp note: iconv_open("UTF-8", "UTF-8") succeeded. root@172.16.10.5's password: # 双方互相发送协议版本号,并协商使用两者较低版本 (Server) Protocol versions: remote=30, negotiated=30 (Client) Protocol versions: remote=30, negotiated=30 [sender] make_file(init,*,0) [sender] flist start=0, used=1, low=0, high=0 [sender] i=0 /tmp init mode=0100644 len=8640 flags=0 send_file_list done file list sent send_files starting server_recv(2) starting pid=13689 # 在远程启动receiver进程 received 1 names [receiver] flist start=0, used=1, low=0, high=0 [receiver] i=0 1 init mode=0100644 len=8640 flags=0 recv_file_list done get_local_name count=1 /tmp generator starting pid=13689 # 在远程启动generator进程 delta-transmission enabled recv_generator(init,0) recv_files(1) starting gen mapped init of size 5140 # generator进程映射basis file文件(即本地的init文件),只有映射后各进程才能获取该文件相关数据块 generating and sending sums for 0 # 生成init文件的弱滚动校验码和强校验码集合,并发送给sender端 send_files(0, /tmp/init) # 以下generator生成的校验码集合信息 count=8 rem=240 blength=700 s2length=2 flength=5140 count=8 n=700 rem=240 # count=8表示该文件总共计算了8个数据块的校验码,n=700表示固定数据块的大小为700字节, # rem=240(remain)表示最终剩240字节,即最后一个数据块的长度 chunk[0] offset=0 len=700 sum1=3ef2e827 chunk[0] len=700 offset=0 sum1=3ef2e827 chunk[1] offset=700 len=700 sum1=57aceaaf chunk[1] len=700 offset=700 sum1=57aceaaf chunk[2] offset=1400 len=700 sum1=92d7edb4 chunk[2] len=700 offset=1400 sum1=92d7edb4 chunk[3] offset=2100 len=700 sum1=afe7e939 chunk[3] len=700 offset=2100 sum1=afe7e939 chunk[4] offset=2800 len=700 sum1=fcd0e7d5 chunk[4] len=700 offset=2800 sum1=fcd0e7d5 chunk[5] offset=3500 len=700 sum1=0eaee949 chunk[5] len=700 offset=3500 sum1=0eaee949 chunk[6] offset=4200 len=700 sum1=ff18e40f chunk[6] len=700 offset=4200 sum1=ff18e40f chunk[7] offset=4900 len=240 sum1=858d519d chunk[7] len=240 offset=4900 sum1=858d519d # sender收到校验码集合后,准备开始数据块匹配过程 send_files mapped /tmp/init of size 8640 # sender进程映射本地的/tmp/init文件,只有映射后各进程才能获取该文件相关数据块 calling match_sums /tmp/init # 开始调用校验码匹配功能,对/tmp/init文件进行搜索匹配 init built hash table # sender端根据接收到的校验码集合中的滚动校验码生成16位长度的hash值,并将hash值放入hash表 hash search b=700 len=8640 # 第一层hash搜索,搜索的数据块大小为700字节,总搜索长度为8640,即整个/tmp/init的大小 sum=3ef2e827 k=700 hash search s->blength=700 len=8640 count=8 potential match at 0 i=0 sum=3ef2e827 # 在chunk[0]上发现潜在的匹配块,其中i表示的是sender端匹配块的编号 match at 0 last_match=0 j=0 len=700 n=0 # 最终确定起始偏移0上的数据块能完全匹配上,j表示的是校验码集合中的chunk编号。 # 此过程中可能还进行了rolling checksum以及强校验码的匹配 potential match at 700 i=1 sum=57aceaaf match at 700 last_match=700 j=1 len=700 n=0 # last_match的值是上一次匹配块的终止偏移 potential match at 1400 i=2 sum=92d7edb4 match at 1400 last_match=1400 j=2 len=700 n=0 potential match at 2100 i=3 sum=afe7e939 match at 2100 last_match=2100 j=3 len=700 n=0 potential match at 7509 i=6 sum=ff18e40f # 在chunk[6]上发现潜在的匹配块, match at 7509 last_match=2800 j=6 len=700 n=4709 # 此次匹配块的起始偏移地址是7509,而上一次匹配块的结尾偏移是2800, # 中间4709字节的数据都是未匹配上的,这些数据需要以纯数据的方式发送给receiver端 done hash search # 匹配结束 sending file_sum # sender端匹配结束后,再生成文件级别的checksum,并发送给receiver端 false_alarms=0 hash_hits=5 matches=5 # 输出此次匹配过程中的统计信息,总共有5个匹配块,全都是hash匹配出来的, # 没有进行第二层次的rolling checksum检查 sender finished /tmp/init # sender端完成搜索和匹配过程 send_files phase=1 # sender进程进入第一阶段 # sender进程暂时告一段落 # 进入receiver端进行操作 generate_files phase=1 # generator进程进入第一阶段 recv_files(init) # receiver进程读取本地init文件 recv mapped init of size 5140 # receiver进程映射init文件,即basis file ##################### 以下是文件重组过程 ##################### chunk[0] of size 700 at 0 offset=0 # receiver进程从basis file中拷贝chunk[0]对应的数据块到临时文件中 chunk[1] of size 700 at 700 offset=700 # receiver进程从basis file中拷贝chunk[1]对应的数据块到临时文件中 chunk[2] of size 700 at 1400 offset=1400 chunk[3] of size 700 at 2100 offset=2100 data recv 4709 at 2800 # receiver进程从2800偏移处开始接收sender发送的纯数据到临时文件中,共4709字节 chunk[6] of size 700 at 4200 offset=7509 # receiver进程从basis file起始偏移4200处拷贝chunk[6]对应的数据块到临时文件中 data recv 431 at 8209 # receiver进程从8209偏移处开始接收sender发送的纯数据到临时文件中,共431字节 got file_sum # 获取文件级的checksum,并与sender进程发送的文件级checksum作比较 renaming .init.gd5hvw to init # 重命名重组成功的临时文件为目标文件init ###################### 文件重组完成 ########################### recv_files phase=1 generate_files phase=2 send_files phase=2 send files finished # sender进程结束,并在sender端输出报告:搜索过程中发现5个匹配块,且都是由16位的hash值匹配出来的, # 第二层弱检验码检查次数为0,也就是说没有hash值冲突的小概率事件发生。总共传输的纯数据为5140字节 total: matches=5 hash_hits=5 false_alarms=0 data=5140 recv_files phase=2 generate_files phase=3 recv_files finished # receiver进程结束 generate_files finished # generator进程结束 client_run waiting on 13584 sent 5232 bytes received 79 bytes 2124.40 bytes/sec # sender端总共发送5232字节,其中包括纯数据5140字节和非文件数据,接收到79字节 total size is 8640 speedup is 1.63 [sender] _exit_cleanup(code=0, file=main.c, line=1052): entered [sender] _exit_cleanup(code=0, file=main.c, line=1052): about to call exit(0)
1.6 从工作原理分析rsync的适用场景
(1).rsync两端耗费计算机的什么资源比较严重?
从前文中已经知道,rsync的sender端因为要多次计算、多次比较各种校验码而对cpu的消耗很高,receiver端因为要从basis file中复制数据而对io的消耗很高。但这只是rsync增量传输时的情况,如果是全量传输(如第一次同步,或显式使用了全量传输选项"--whole-file"),那么sender端不用计算、比较校验码,receiver端不用copy basis file,这和scp消耗的资源是一样的。
(2).rsync不适合对数据库文件进行实时同步。
像数据库文件这样的大文件,且是频繁访问的文件,如果使用rsync实时同步,sender端要计算、比较的数据块校验码非常多,cpu会长期居高不下,从而影响数据库提供服务的性能。另一方面,receiver端每次都要从巨大的basis file(一般提供服务的数据库文件至少都几十G)中复制大部分相同的数据块重组新文件,这几乎相当于直接cp了一个文件,它一定无法扛住巨大的io压力,再好的机器也扛不住。
所以,对频繁改变的单个大文件只适合用rsync偶尔同步一次,也就是备份的功能,它不适合实时同步。像数据库文件,要实时同步应该使用数据库自带的replication功能。
(3).可以使用rsync对大量小文件进行实时同步。
由于rsync是增量同步,所以对于receiver端已经存在的和sender端相同的文件,sender端是不会发送的,这样就使得sender端和receiver端都只需要处理少量的文件,由于文件小,所以无论是sender端的cpu还是receiver端的io都不是问题。
但是,rsync的实时同步功能是借助工具来实现的,如inotify+rsync,sersync,所以这些工具要设置合理,否则实时同步一样效率低下,不过这不是rsync导致的效率低,而是这些工具配置的问题。
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

