Perl多线程(1):解释器线程的特性
线程简介
线程(thread)是轻量级进程,和进程一样,都能独立、并行运行,也由父线程创建,并由父线程所拥有,线程也有线程ID作为线程的唯一标识符,也需要等待线程执行完毕后收集它们的退出状态(比如使用join收尸),就像waitpid对待子进程一样。
线程运行在进程内部,每个进程都至少有一个线程,即main线程,它在进程创建之后就存在。线程非常轻量级,一个进程中可以有很多个线程,它们全都在进程内部并行地被调度、运行,就像多进程一样。每个线程都共享了进程的很多数据,除了线程自己所需要的数据,它们都直接使用父进程的,比如同一个线程解释器、同一段代码、同一段要处理的数据等,但每个线程都有自己的调用栈(call stack)空间,用来存放某些临时数据、某些状态、某些返回信息等。
于是,现在开始从多进程编程转入到多线程编程。
Perl自己的线程
有些系统不原生支持线程模型(如某些Unix系统),在Perl 5.8中,Perl提供了属于自己的线程模型:解释器线程(interpreter thread, ithreads)。当然,Perl也依旧支持老线程。
Thread模块提供老式线程threads模块提供Perl解释器线程
可以通过以下代码来检测操作系统是否支持老式线程、解释器线程。
#!/usr/bin/perl
BEGIN{
use Config;
if ($Config{usethreads}) {print "support old thread\n";}
if ($Config{useithreads}) {print "support interpreter threads\n";}
}
或者简单的使用perldoc来检查这两个模块是否存在,一般来说安装Perl的时候就会自动安装它们:
$ perldoc Thread
$ perldoc threads
threads模块提供的是面向对象的解释器线程,可以直接使用new方法来创建一个线程,使用其它方法来维护线程。默认情况下,Perl解释器线程不会在线程之间共享数据和状态信息(也就是说数据是线程本地的),如果想要共享,可以使用threads::shared。而老式线程模块Thread的线程默认是自动在线程间共享数据的,且于解释器线程相互隔离,在编写复杂程序时这可能会很复杂。
实际上,在Perl的解释器线程被创建的时候,会将父线程中所有的变量都拷贝到自己的空间中使之成为私有变量,这样各线程之间就互相隔离了,并且自动实现了线程安全。如果想要在同进程的不同线程之间共享数据,需要专门使用threads::shared模块将变量共享出去,这样每个线程都能访问到这个变量。
解释器线程这样的行为对编写多线程来说非常的友好,但是这会影响Perl的线程性能,特别是父线程中数据量较大的时候,创建线程的成本以及内存占用上是非常昂贵的。所以,在使用Perl解释器线程的时候,应当尽量在数据量还小的时候创建子线程。
创建线程
Perl线程在很多方面都像fork出来的进程一样,但是在创建线程上,它更像是一个子程序。
创建线程的方式有两种:create/new、async,create和new是等价的别名,这3种(实际上是两种)创建线程的方式除了语法上不同,在线程执行上是完全一致的。
创建线程的标准方法是使用create或new方法(它们是等价的别名),并且给它一个子程序或子程序引用或匿名子程序,这表示创建一个新线程去运行这个子程序。
例如:
use threads;
my $thr = threads->create(\&sub1);
sub sub1 {
print("In Child Thread\n");
}
这里main线程创建了子线程运行sub1子程序,创建完成后,main线程继续向下运行。
如果子程序要传递参数,直接在create/new的参数位上传递即可。
use threads;
sub threadsub {
my $self = threads->self;
}
my $thr1 = threads->create(\&threadsub, 'arg1', 'arg2');
# 或者使用new
my $thr2 = threads->new(\&threadsub, @args);
如果使用async创建线程,那么给async一个语句块,就像匿名子程序一样。
use threads;
my $thr = async {
... some code ...
}
这表示新建一个子线程来运行代码块中的代码。
至于选择create/new还是选择async来创建新线程,随意。但是如果创建多个线程的话,使用create/new比较方便。而且,create/new也一样能创建新线程执行匿名子程序。
my $thr1 = new threads \&threadsub, $arg1;
my $thr2 = new threads \&threadsub, $arg2;
my $thr3 = new threads \&threadsub, $arg3;
# create执行匿名子程序
my $thr = threads->create( sub {...} );
线程标识
由于我们可能会创建很多个线程,我们需要区分它们。
第一种方式是通过给不同线程的子程序传递不同参数的方式来区分不同的线程。
例如:
my $thr1 = threads->create(\&mysub,"first");
my $thr1 = threads->create(\&mysub,"second");
my $thr1 = threads->create(\&mysub,"third");
sub mysub {
my $thr_num = shift @_;
print "I am thread $thr_num\n";
...
}
第二种方式是获取threads模块中的线程对象,线程对象中包含了线程的id属性。通过类方法threads->self()可以获取当前线程对象,有了线程对象,可以通过tid()对象方法获取这个线程对象的ID,当然还可以直接使用类方法threads->tid()来获取当前线程对象的ID。
my $myself = threads->self;
my $mytid = $myself->tid();
# 或
my $mytid = threads->tid();
对于已知道tid的线程,可以使用类方法threads->object($tid)去获取这个tid的线程对象。注意,object()只能获取正激活的线程对象,对于joined和detached线程(join和detach见下文),都返回undef,不仅如此,对于无法收集的线程对象,object()都返回undef,例如收集$tid不存在的线程。
线程对象的ID是从0开始计算的,然后每新建一个子线程,ID就加1.0号线程就是每个进程创建时的main线程,main线程再创建一个新子线程,这个新子线程的ID就是1。
可以比较两个线程是否是同一个线程,使用equal()方法(或者重载的==和!=符号)即可,它们都基于线程ID进行比较:
print "Equal\n" if $self->equal($thr);
print "Equal\n" if $self == $thr;
线程状态和join、detach
Perl中的线程实际上是一个子程序代码块,它可能会有子程序的返回值,所以父线程需要接收子线程的返回值。不仅如此,就像父进程需要使用wait/waitpid等待子进程并为退出的子进程收尸一样,父线程也需要等待子线程退出并为子线程收尸(做最后的清理工作)。为线程收尸是很重要的,如果只创建了几个运行时间短的子线程,那么操作系统可能会自动为子线程收尸,但创建了一大堆的子线程,操作系统可能不会给我们什么帮助,我们要自己去收尸。
join()方法的功能就像waitpid一样,当父线程中将子线程join()后,表示将子线程从父线程管理的一个线程表中加入到父线程监控的另一个列表中(实际上并非如此,只是修改了进程的状态而已,稍后解释),这个列表中的所有线程是该父线程都需要等待的。所以,将join()方法的"加入"含义看作是加入到了父线程的某个监控列表中即可。
join()做三件事:
- 等待子线程退出,等待过程中父线程一直阻塞
- 子线程退出后,为子线程收尸(OS clean up)
- 如果子线程有返回值,则收集返回值
- 而返回值是有上下文的,根据标量(scalar)、列表(list)、空(void)上下文,应该在合理的上下文中使用返回值
- 线程上下文相关,稍后解释
例如:
use threads;
my ($thr) = threads->create(\&sub1);
# join,父进程等待、收尸、收集返回值
my @returnData = $thr->join();
print 'thread returned: ', join('@', @returnData), "\n";
sub sub1 {
# 返回值是列表
return ('fifty-six', 'foo', 2);
}
join的三件事中,如果不想要等待子线程执行完毕,可以使用detach(),它将子线程脱离父线程,父线程不再阻塞等待。因为已经脱离,父线程也将不再为子线程收尸(子线程在执行完毕的时候自己收尸),父线程也无法收集子线程的返回值导致子线程的返回值被丢弃。当然,父子关系还在,只不过当父线程退出时,子线程会继续运行,这时才会摆脱父线程成为孤儿线程,这就像daemon进程(自己成立进程组)和父进程一样。
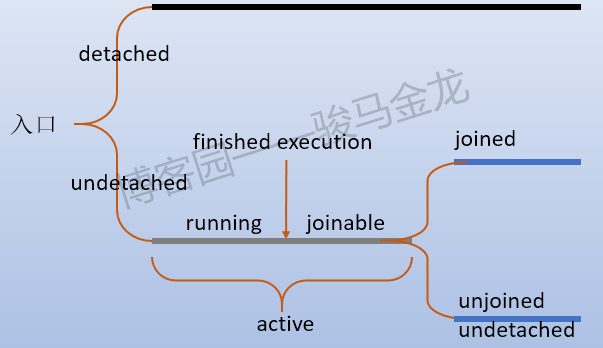
刚才使用"父线程监控的另一个列表"来解释join的行为,这是不准确的。实际上,线程有6种状态(这些状态稍后还会解释):
- detached(和joined是互斥的状态)
- joined(和detached是互斥的状态)
- finished execution(执行完但还没有返回,还没退出),其实是running状态刚结束,可以被join的阶段(joinable)
- exit
- died
- creation failed
当执行detach()后,线程的状态就变成detached,当执行join()后,线程的状态就变成joined。detached线程可以看作是粗略地看作是脱离了父线程,它无法join,父线程也不会对其有等待、收尸、收集返回值行为,只有进程退出时detached线程才默默被终止(detached状态的线程也依然是线程,是进程的内部调度单元,进程终止,线程都将终止)。
例如:
use threads;
sub mysub {
#alarm 10;
for (1..10){
print "I am detached thread\n";
sleep 1;
}
}
my $thr1 = threads->new(\&mysub)->detach();
print "main thread will exit in 2 seconds\n";
sleep 2;
上面的子线程会被detach,父线程继续运行,在2秒后进程终止,detach后的子线程会被默默终止。
更细分一点,一个线程正常执行子程序到结束可以划分为几个过程:
- 1.线程入口,开始执行子程序。执行子程序的阶段称为running状态
- 2.子程序执行完毕,但还没有返回,这个时候是running刚结束状态,也是前文提到的finished execution状态
- 如果这个线程未被detach,从这个状态开始,这个线程可以被join(除非是detached线程),也就是joinable状态,父线程在这个阶段不再阻塞
- 3.线程执行完毕
- 如果这个线程被join,则父线程对该线程收尸并收集该线程的返回值
- 如果这个线程被detach,则这个线程自己收尸并退出
- 如果这个线程未join也未detach,则父线程不会收尸,并且在进程退出时报告相关消息
所以从另一种分类角度上看,线程可以分为:active、joined、detached三种状态。其中detached线程已被脱离,所以不算是active线程,joined已经表示线程的子程序已经执行完毕了,也不算是active线程,只有unjoined、undetached线程才算是active线程,active包括running、joinable这两个过程。
整个线程的状态和过程可以参考下图:
上面一直忽略了一种情况,线程在join之前就已经运行完毕了。例如:
my $thr1 = threads->create(\&sub1);
# 父线程睡5秒,给子线程5秒的执行时间
sleep 5;
$thr1->join();
子线程先执行完毕,但是父线程还没对它进行join,这时子线程一直处于joinable的状态,其实这个时候子线程基本已经失去意义了,它的返回值和相关信息都保存在线程栈(或调用栈call stack),当父线程对其进行join()的时候,自然能从线程栈中找到返回值或某些信息的栈地址从而取得相关数据,也能从现在开始对其进行收尸行为。
实际上,解释器线程是一个双端链表结构,每个线程节点记录了自己的属性,包括自己的状态。而main线程中则包含了所有子线程的一些统计信息:
typedef struct {
/* Structure for 'main' thread
* Also forms the 'base' for the doubly-linked list of threads */
ithread main_thread;
/* Protects the creation and destruction of threads*/
perl_mutex create_destruct_mutex;
UV tid_counter; # tid计数器,可知道当前已经创建了几个线程
IV joinable_threads; # 可join的线程
IV running_threads; # 正在运行的线程
IV detached_threads; # detached状态的线程
IV total_threads; # 总线程数
IV default_stack_size; # 线程的默认栈空间大小
IV page_size;
} my_pool_t;
检查线程的状态
使用threads->list()方法可以列出未detach的线程,列表上下文下返回这些线程列表,标量上下文下返回数量。它有4种形式:
threads->list() # 返回non-detach、non-joined线程
threads->list(threads::all) # 同上
threads->list(threads::running) # non-detached、non-joined的线程对象,即正在运行的线程
threads->list(threads::joinable) # non-detached、non-joined但joinable的线程对象,即已完成子程序执行但未返回的线程
所以,list()只能统计未detach、未join的线程,::running返回的是正在运行子程序主体的线程,::joinable返回的是已完成子程序主体的线程,::all返回的是它们之和。
此外,我们还可以直接去测试线程的状态:
$thr->is_running()
如果该线程正在运行,则返回true
$thr->is_joinable()
如果该线程已经完成了子程序的主体(即running刚结束),且未detach未join,换句话说,这个线程是joinable,于是返回true
$thr->is_detached()
threads->is_detached()
测试该线程或线程自身是否已经detach
线程的上下文环境
因为解释器线程实际上是一个运行的子程序,而父线程可能需要收集子线程的返回值(join()的行为),而返回值在不同上下文中有不同的行为。
仍以前面的示例来解释:
use threads;
# my(xxx):列表上下文
# my xxx:标量上下文
my ($thr) = threads->create(\&sub1);
# join,父进程等待、收尸、收集返回值
# @arr:列表上下文
my @returnData = $thr->join();
print 'thread returned: ', join('@', @returnData), "\n";
sub sub1 {
# 返回值是列表
return ('fifty-six', 'foo', 2);
}
上面的创建子线程后,父线程将这个子线程join()时一直阻塞,直到子线程运行完毕,父线程将子线程的返回值收集到数组@returnData中。因为子程序的返回值是一个列表,所以这里join的上下文是列表上下文。
其实,子线程的上下文是在被创建出来的时候决定的,这样子程序中可以出现wantarray()。所以,在线程被创建时、在join时上下文都要指定:前者决定线程入口(即子程序)执行时所处何种上下文,后者决定子程序返回值环境。这两个地方的上下文不一定要一样,例如创建线程的时候在标量上下文环境下,表示子程序在标量上下文中执行,而join的时候可以放在空上下文表示丢弃子程序的返回值。
允许三种上下文:标量上下文、列表上下文、空上下文。
对于join时的上下文没什么好解释的,根据上下文环境将返回值进行赋值而已。但是创建线程时的上下文环境需要解释。有显式和隐式两种方式来指定创建线程时的上下文。
隐式上下文自然是通过所处上下文环境来暗示。
# 列表上下文创建线程
my ($thr) = threads->create(...);
# 标量上下文创建线程
my $thr = threads->create(...);
# 空上下文创建线程
threads->create(...);
显式上下文是在create/new创建线程的时候,在第一个参数位置上指定通过一个hash引用来指定上下文环境。也有两种方式:
# 列表上下文创建线程
my $thr = threads->create({ 'context' => 'list' }, \&sub1)
my $thr = threads->create({ 'list' => 1 }, \&sub1)
# 标量上下文创建线程
my $thr = threads->create({ 'context' => 'scalar' }, \&sub1)
my $thr = threads->create({ 'scalar' => 1 }, \&sub1)
# 空上下文创建线程
my $thr = threads->create({ 'context' => 'void' }, \&sub1)
my $thr = threads->create({ 'void' => 1 }, \&sub1)
线程的退出
正常情况并且大多情况下,线程都应该通过子程序return的方式退出线程。但是也有其它可能。
threads->exit()
线程自身可以调用threads->exit()以便在任何时间点退出。这会使得线程在标量上下文返回undef,在列表上下文返回空列表。如果是在main线程中调用`threads->exit()`,则等价于exit(0)
threads->exit(status)
在线程中调用时,等价于threads->exit(),退出状态码status会被忽略。在main线程中调用时,等价于exit(status)
die()
直接调用die函数会让线程直接退出,如果设置了 $SIG{__DIE__} 的信号处理机制,则调用该处理方法,像一般情况下的die一样
exit(status)
在线程内部调用exit()函数会导致整个程序终止(进程中断),所以不建议在线程内部调用exit()。但是可以改变exit()终止整个程序的行为,见下面几个设置
use threads 'exit'=>'threads_only'
全局设置,使得在线程内部调用exit()时不会导致整个程序终止,而是只让线程终止。由于这是全局设置,所以不是很建议设置。另外,该设置对main线程无效
threads->create({'exit'=>'thread_only},\&sub1)
在创建线程的时候,就设置该线程中的exit()只退出当前线程
$thr->set_thread_exit_only(bool)
修改当前线程中的exit()效果。如果给了true值,则线程内部调用exit()将只退出该线程,给false值,则终止整个程序。对main线程无效
threads->set_thread_exit_only(bool)
类方法,给true值表示当前线程中的exit()只退出当前线程。对main线程无效
最可能需要的退出方式是threads->exit()或threads->exit(status),如果对于线程中严重错误的问题,则可能需要的是die或exit()来终止整个程序。
线程暂时放弃CPU
有时候可能想要让某个线程短暂地放弃CPU转交给其它线程,可以使用yield()类方法。
threads->yield();
yield()和操作系统平台有关,不一定真的有效,且出让CPU的时间也一定能保证。
线程的信号处理
在threads定义的解释器线程中,可以在线程内部定义信号处理器(signal handler),并通过$thr->kill(SIGNAME)的方式发送信号(对于某些自动触发的信号处理,稍后解释),kill方法会返回线程对象以便进行链式调用方法。
例如,在main线程中发送SIGKILL信号,并在线程内部处理这个信号。
use threads;
sub thr_func {
# Thread signal handler for SIGKILL
$SIG{KILL} = sub {
print "Caught Signal: SIGKILL\n";
threads->exit();
}
...
}
my $thr = threads->create('thr_func');
...
# send SIGKILL to terminate thread, then detach
# it so that it will clean up automatically
$thr->kill('KILL')->detach();
其实,threads对于线程信号的处理方式是模拟的,不是真的从操作系统发送信号(操作系统发送的信号是给进程的,会被main线程捕获)。模拟的逻辑也很简单,通过threads->kill()发送信号给指定线程,然后通过调用子程序中的%SIG中的signal handler即可。
例如上面的示例中,我们想要发送KILL信号,但这个信号不是操作系统发送的,而是模拟了一个KILL信号,表示是要终止线程的执行,于是调用线程中的SIGKILL对应的signal handler,仅此而已。
但是,有些信号是某些情况下自动触发的,比如在线程中使用一个alarm计时器,在计时结束时它会发送SIGALRM信号给进程,这会使得整个进程都退出,而不仅仅是那个单独的线程,这显然不是我们所期待的结果。
实际上,操作系统所发送的信号都会在main线程中被捕获。所以如果想要处理上面的问题,只需在main线程中定义对应操作系统发送的信号的signal handler,并在handler中重新使用threads->kill()发送这个信号给指定线程,从而间接实现"信号->线程"的机制。
例如,在线程中使用alarm并在计时结束的时候停止该线程。
use threads qw(yield);
# 带有计时器的线程
my $thr = threads->create(
sub {
threads->yield();
eval {
$SIG{ALRM} = sub {die "Timeout";};
alarm 10;
... do somework ...
};
if ( $@ =~ /Timeout/) {
warn "thread timeout";
}
}
);
$SIG{ALRM} = sub { $thr->kill('ALRM') };
... main thread continue ...
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号