python按引用赋值和深、浅拷贝
按引用赋值而不是拷贝副本
在python中,无论是直接的变量赋值,还是参数传递,都是按照引用进行赋值的。
在计算机语言中,有两种赋值方式:按引用赋值、按值赋值。其中按引用赋值也常称为按指针传值(当然,它们还是有点区别的),后者常称为拷贝副本传值。它们的区别,详细内容参见:按值传递 vs. 按指针传递。
下面仅解释python中按引用赋值的相关内容,先分析下按引用赋值的特别之处,然后分析按引用赋值是什么样的过程。
按引用赋值的特性
例如:
a = 10000
b = a
>>> a,b
(10000, 10000)
这样赋值后,b和a不仅在值上相等,而且是同一个对象,也就是说在堆内存中只有一个数据对象10000,这两个变量都指向这一个数据对象。从数据对象的角度上看,这个数据对象有两个引用,只有这两个引用都没了的时候,堆内存中的数据对象10000才会等待垃圾回收器回收。
它和下面的赋值过程是不等价的:
a = 10000
b = 10000
虽然a和b的值相等,但他们不是同一个对象,这时候在堆内存中有两个数据对象,只不过这两个数据对象的值相等。
对于不可变对象,修改变量的值意味着在内存中要新创建一个数据对象。例如:
a = 10000
b = a
a = 20000
>>> a,b
(20000, 10000)
在a重新赋值之前,b和a都指向堆内存中的同一个数据对象,但a重新赋值后,因为数值类型10000是不可变对象,不能在原始内存块中直接修改数据,所以会新创建一个数据对象保存20000,最后a将指向这个20000对象。这时候b仍然指向10000,而a则指向20000。
结论是:对于不可变对象,变量之间不会相互影响。正如上面重新赋值了a=20000,但变量b却没有任何影响,仍然指向原始数据10000。
对于可变对象,比如列表,它是在"原处修改"数据对象的(注意加了双引号)。比如修改列表中的某个元素,列表的地址不会变,还是原来的那个内存对象,所以称之为"原处修改"。例如:
L1 = [111,222,333]
L2 = L1
L1[1] = 2222
>>> L1,L2
([111, 2222, 333], [111, 2222, 333])
在L1[1]赋值的前后,数据对象[111,222,333]的地址一直都没有改变,但是这个列表的第二个元素的值已经改变了。因为L1和L2都指向这个列表,所以L1修改第二个元素后,L2的值也相应地到影响。也就是说,L1和L2仍然是同一个列表对象[111,2222,333]。
结论是:对于可变对象,变量之间是相互影响的。
按引用赋值的过程分析
当将段数据赋值给一个变量时,首先在堆内存中构建这个数据对象,然后将这个数据对象在内存中的地址保存到栈空间的变量中,这样变量就指向了堆内存中的这个数据对象。
例如,a = 10赋值后的图示:
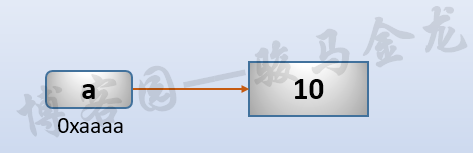
如果将变量a再赋值给变量b,即b = a,那么赋值后的图示:

因为a和b都指向对内存中的同一个数据对象,所以它们是完全等价的。这里的等价不仅仅是值的比较相等,而是更深层次的表示同一个对象。就像a=20000和c=20000,虽然值相等,但却是两个数据对象。这些内容具体的下一节解释。
在python中有可变数据对象和不可变数据对象的区分。可变的意思是可以在堆内存原始数据结构内修改数据,不可变的意思是,要修改数据,必须在堆内存中创建另一个数据对象(因为原始的数据对象不允许修改),并将这个新数据对象的地址保存到变量中。例如,数值、字符串、元组是不可变对象,列表是可变对象。
可变对象和不可变对象的赋值形式虽然一样,但是修改数据时的过程不一样。
对于不可变对象,修改数据是直接在堆内存中新创建一个数据对象。如图:
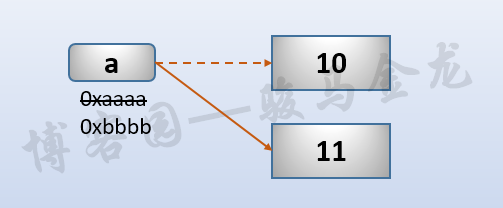
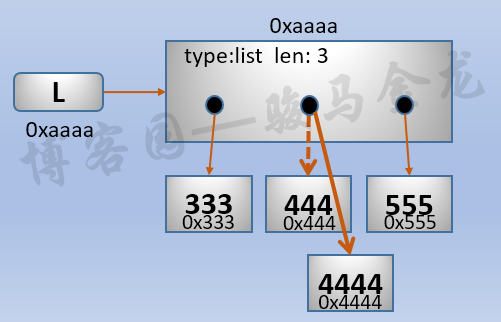
对于可变对象,修改这个可变对象中的元素时,这个可变对象的地址不会改变,所以是"原处修改"的。但需要注意的是,这个被修改的元素可能是不可变对象,可能是可变对象,如果被修改的元素是不可变对象,就会创建一个新数据对象,并引用这个新数据对象,而原始的那个元素将等待垃圾回收器回收。
>>> L=[333,444,555]
>>> id(L),id(L[1])
(56583832, 55771984)
>>> L[1]=4444
>>> id(L),id(L[1])
(56583832, 55771952)
如图所示:
早就存在的小整数
数值对象是不可变对象,理论上每个数值都会创建新对象。
但实际上并不总是如此,对于[-5,256]这个区间内的小整数,因为python内部引用过多,这些整数在python运行的时候就事先创建好并编译好对象了。所以,a=2, b=2, c=2根本不会在内存中新创建数据对象2,而是引用早已创建好的初始化数值2。
所以:
>>> a=2
>>> b=2
>>> a is b
True
其实可以通过sys.getrefcount()函数查看数据对象的引用计数。例如:
>>> sys.getrefcount(2)
78
>>> a=2
>>> sys.getrefcount(2)
79
对于小整数范围内的数的引用计数都至少是几十次的,而超出小整数范围的数都是2或者3(不同执行方式得到的计数值不一样,比如交互式、文件执行)。
对于超出小整数范围的数值,每一次使用数值对象都创建一个新数据对象。例如:
>>> a=20000
>>> b=20000
>>> a is b
False
因为这里的20000是两个对象,这很合理论。但是看下面的:
>>> a=20000;b=20000
>>> a is b
True
>>> a,b=20000,20000
>>> a is b
True
为什么它们会返回True?原因是python解析代码的方式是按行解释的,读一行解释一行,创建了第一个20000时发现本行后面还要使用一个20000,于是b也会使用这个20000,所以它返回True。而前面的换行赋值的方式,在解释完一行后就会立即忘记之前已经创建过20000的数据对象,于是会为b创建另一个20000,所以它返回False。
如果是在python文件中执行,则在同意作用域内的a is b一直都会是True,而不管它们的赋值方式如何。这和代码块作用域有关:整个py文件是一个模块作用域。此处只给测试结果,不展开解释,否则篇幅太大了,如不理解下面的结果,可看我的另一篇Python作用域详述。
a = 25700
b = 25700
print(a is b) # True
def f():
c = 25700
d = 25700
print(c is d) # True
print(a is c) # False
f()
深拷贝和浅拷贝
对于下面的赋值过程:
L1 = [1,2,3]
L2 = L1
前面分析过修改L1或L2的元素时都会影响另一个的原因:按引用赋值。实际上,按引用是指直接将L1中保存的列表内存地址拷贝给L2。
再看一个嵌套的数据结构:
L1 = [1,[2,22,222],3]
L2 = L1
这里从L1拷贝给L2的也是外层列表的地址,所以L2可以找到这个外层列表包括其内元素。
下面是深、浅拷贝的概念:
- 浅拷贝:shallow copy,只拷贝第一层的数据。python中赋值操作或copy模块的copy()就是浅拷贝
- 深拷贝:deep copy,递归拷贝所有层次的数据,python中copy模块的deepcopy()是深拷贝
所谓第一层次,指的是出现嵌套的复杂数据结构时,那些引用指向的数据对象属于深一层次的数据。例如:
L = [2,22,222]
L1 = [1,2,3]
L2 = [1,L,3]
L和L1都只有一层深度,L2有两层深度。浅拷贝时只拷贝第一层的数据作为副本,深拷贝递归拷贝所有层次的数据作为副本。
例如:
>>> L=[2,22,222]
>>> L1=[1,L,3]
>>> L11 = copy.copy(L1)
>>> L11,L1
([1, [2, 22, 222], 3], [1, [2, 22, 222], 3])
>>> L11 is L1
False
>>> id(L1),id(L11) # 不相等
(17788040, 17786760)
>>> id(L1[1]),id(L11[1]) # 相等
(17787880, 17787880)
注意上面的L1和L11是不同的列表对象,但它们中的第二个元素是同一个对象,因为copy.copy是浅拷贝,只拷贝了这个内嵌列表的地址。
而深拷贝则完全创建新的副本对象:
>>> L111 = copy.deepcopy(L1)
>>> L1[1],L111[1]
([2, 22, 222], [2, 22, 222])
>>> id(L1[1]),id(L111[1])
(17787880, 17787800)
因为是浅拷贝,对于内嵌了可变对象的数据时,修改内嵌的可变数据,会影响其它变量。因为它们都指向同一个数据对象,这和按引用赋值是同一个道理。例如:
>>> s = [1,2,[3,33,333,3333]]
>>> s1 = copy.copy(s)
>>> s1[2][3] = 333333333
>>> s[2], s1[2]
([3, 33, 333, 333333333], [3, 33, 333, 333333333])
一般来说,浅拷贝或按引用赋值就是我们所期待的操作。只有少数时候(比如数据序列化、要传输、要持久化等),才需要深拷贝操作,但这些操作一般都内置在对应的函数中,无需我们手动去深拷贝。
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号