基于WAF+Splunk+FW简单SOAR平台搭建
基于WAF+Splunk+FW简单SOAR平台搭建
目录
1 基于WAF+Splunk简单SOC平台搭建
1.1 准备环境
- Splunk安装
- WAF设备
- WAF到Splunk的syslog请自行打通
1.2 配置Splunk
WAF的日志发送请依据不同厂商进行配置。
1.2.1 配置数据源(从网络端口获取)
当添加新的网络端口输入时,也就是在后台向input.conf文件添加新的输入配置节点,Splunk服务器可包含一个或多个input.conf文件,文件位于$SPLUNK_HOME/etc/system/local,或Splunk应用程序的local目录。
-
选择:"设置"--> 数据分类:"来源类型" --> "新建来源类型" --> 配置如下
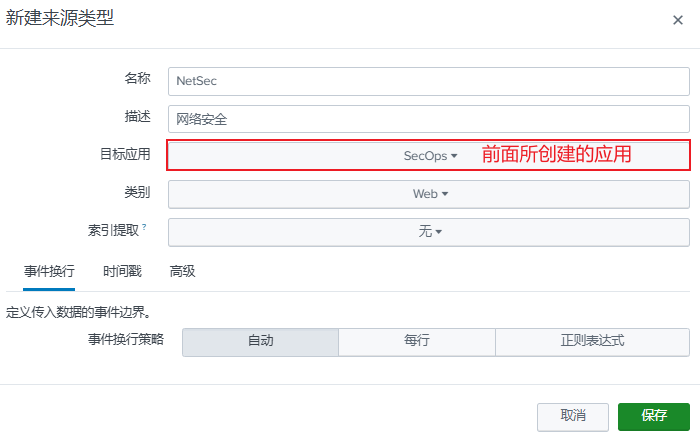
-
选择:"设置"--> "数据输入" --> "UDP" --> 配置如下
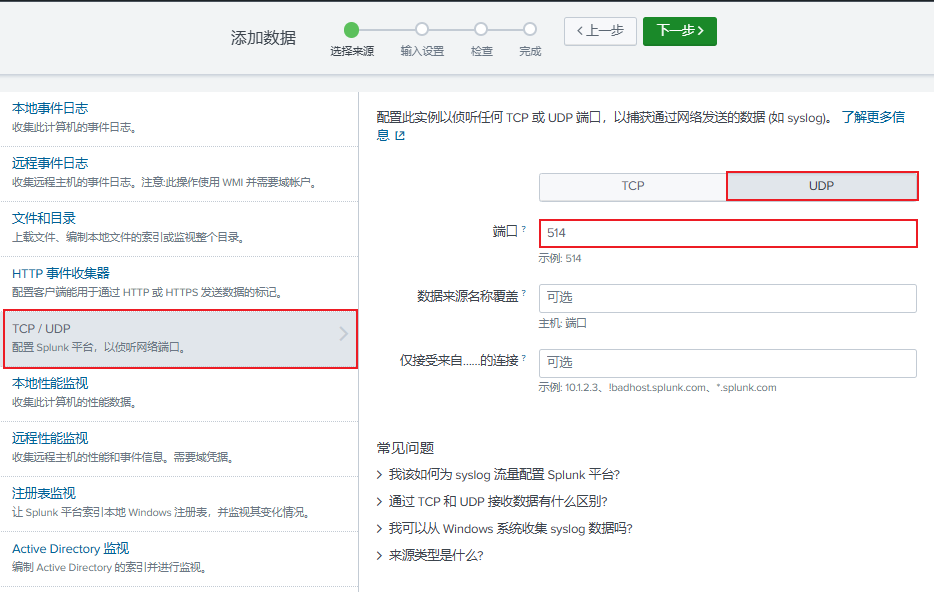
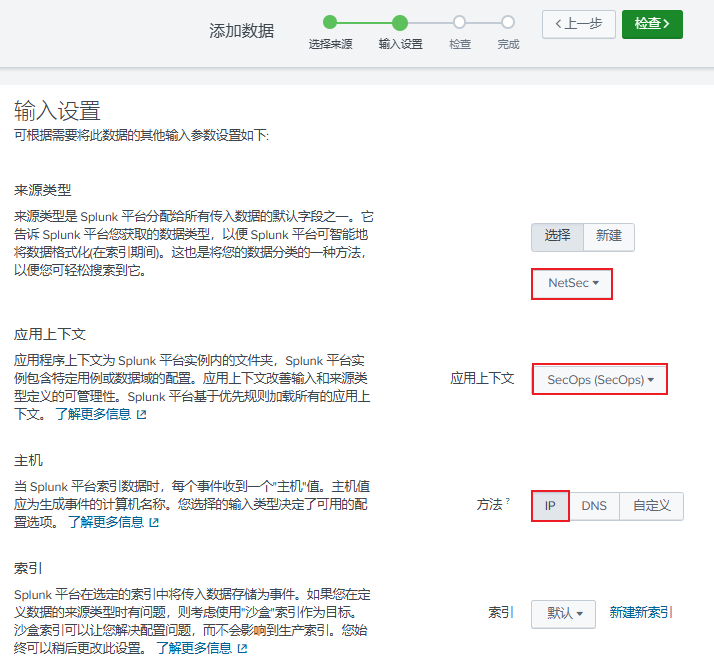
1.2.2 创建应用
Splunk 应用程序(或APP)可被看作是专门用于解决某种用例的工作区。
-
选择:"应用"--> "管理应用" --> "新建应用" --> 配置如下
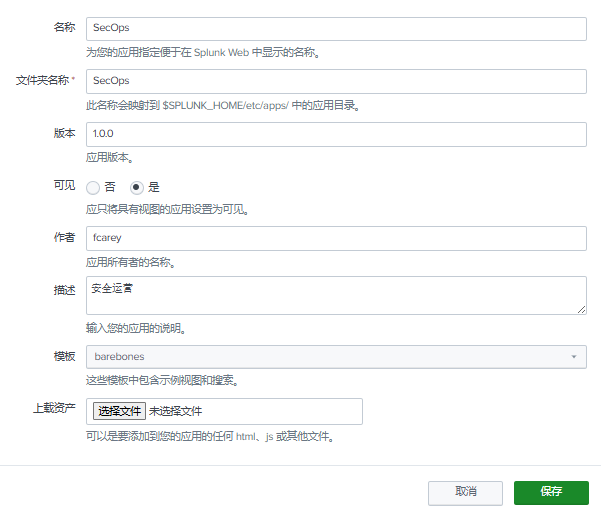
1.2.3 创建警报
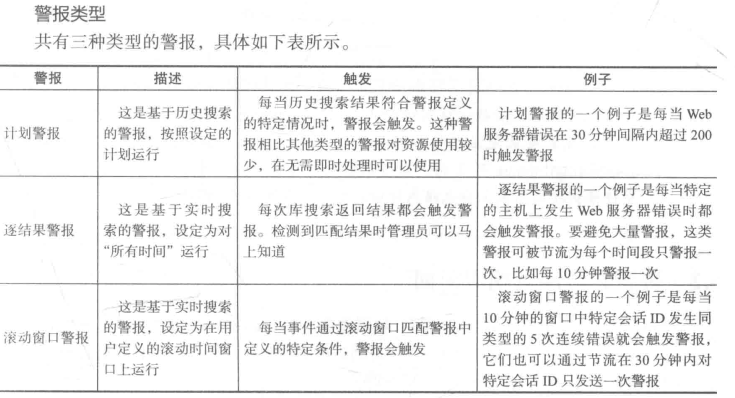
Splunk 的警报由底层搜索提供支持。这些底层搜索按计划执行历史索引的数据或在数据实时导入Splunk时实时进行。警报可以在搜索每次执行的时候触发,也可以在搜索结果符合某些条件时触发。

-
选择:"应用"--> "SecOps" --> "搜索",配置如下:
index="index_netsec" "Traffic@waf-access" | rex field=_raw "客户IP:(?<src_ip>\d+\.\d+\.\d+\.\d+).*站点名称:(?<site>.*) 协议.*资源路径:(?<site_path>.*) 查询字符串.*(?<evial_tool>(jndi|nmap))" | stats dc(jndi) AS count_01,dc(site_path) as count_02 by src_ip | where count_01>0 Or count_02>70index="index_netsec":Splunk中所有数据都保存在一个或多个索引中。建议在搜索时指定索引,能得到更精确搜索结果。"Traffic@waf-access":搜索与"Traffic@waf-access"有关的数据。rex field=_raw "客户IP:(?<src_ip>\d+\.\d+\.\d+\.\d+).*站点名称:(?<site>.*) 协议.*资源路径:(?<site_path>.*) 查询字符串.*(?<jndi>(jndi|nmap))": 创建自定义字段stats dc(jndi) AS count_01,dc(site_path) as count_02 by src_ip:stats命令将上一步的搜索结果放在管道左侧,并告知Splunk计算每个evial_tool,site_path的数量。where count_01>0 Or count_02>70:找出访问User-Agent中包含jndi,nmap与访问路径数量超过70个的IP。
-
回车或点击搜索图标后,点击""另存为"-->"告警"-->配置如下:添加触发的告警根据需要选择优先级,必选,否则不生效。
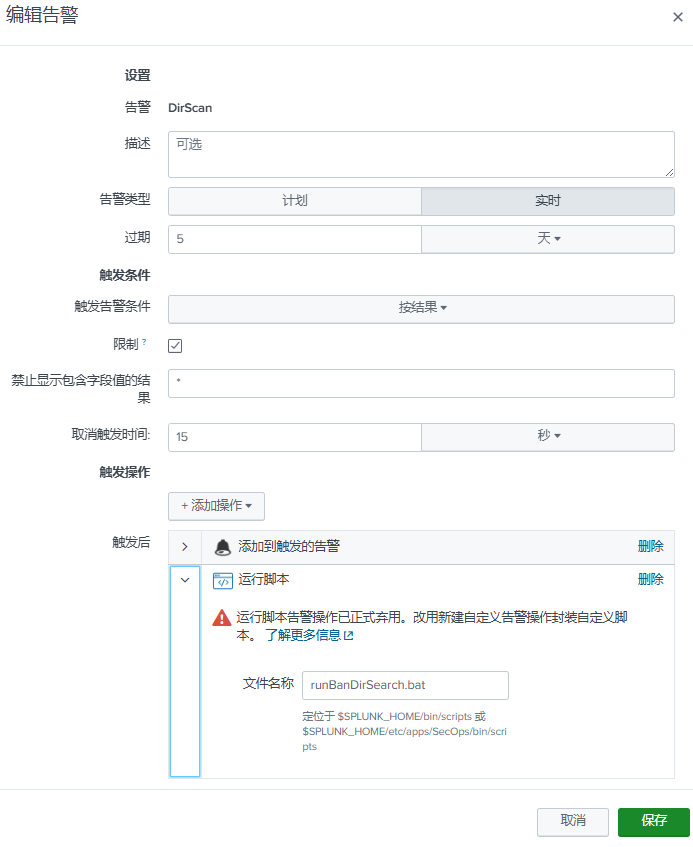
1.2.4 创建警报触发动作
-
在
$SPLUNK_HOME\bin\scripts目录创建runBanDirSearch.bat:@echo off cd "C:\Program Files\Splunk\bin\scripts\" BanDirSearch.exe cmd
1.2.5 建议封禁的策略
- 发现Web服务探测行为
- Generic_scan
- 发现黑客工具Nmap扫描行为
- 发现扫描工具-zgrab
- 发现NMAP探测行为(SSL)
- Apache Log4j2 远程代码执行漏洞(CVE-2021-44228/CVE-2021-45046)
- 敏感信息扫描(机器学习)
- 发现黑客工具Masscan扫描行为
- 发现黑客工具-绿盟扫描器扫描行为
- 发现黑客扫描工具-httpx
- 发现黑客工具Nessus扫描行为
2 基于FW+Splunk警报实现自动化运营
2.1 编写自动划封禁脚本
# 需要在当前目录下创建以下信息:
# 1. 防火墙设备清单:device_list.csv
# 序号,厂商,设备名称,管理IP,端口
# 1,Internet-FW,hillstone,192.168.1.1,22
# 2. spl查询语句:splunkSearch.txt
# index="index_netsec" (host="192.168.1.2" "Web-security@SYS" NOT (AttackName="信息泄露" OR AttackName= "检测curl网络爬虫")) OR (host="192.168.1.3" "192.168.1.4") | stats count by src_ip
from splunklib import client
import splunklib.results as results
import csv
import sys
import os
import zipfile
import chardet
import paramiko
import time
import threading
import logging
from logging import handlers
import sqlite3
def mk_log_dir():
"""
生成日志文件夹
:return:
"""
date_time = time.strftime('%Y%m%d', time.localtime())
log_root_dir = os.path.join(script_path, 'BanIP_data_' + date_time)
if not os.path.exists(log_root_dir): # 判断目标目录是否存在
os.mkdir(log_root_dir) # 如果不存在则创建目标目录
print("已创建数据存放根目录:%s" % log_root_dir)
log_time = time.strftime('%Y%m%d%H%M%S', time.localtime())
log_dir = os.path.join(script_path, log_root_dir, '{}'.format('LogData_' + log_time))
if not os.path.exists(log_dir): # 判断目标目录是否存在
os.mkdir(log_dir) # 如果不存在则创建目标目录
print("已创建数据存放目录:%s" % log_dir)
return log_root_dir, log_dir
class Logger(object):
level_relations = {
'debug': logging.DEBUG,
'info': logging.INFO,
'warning': logging.WARNING,
'error': logging.ERROR,
'crit': logging.CRITICAL
} # 日志级别关系映射
def __init__(self, filename, level='info', when='D', back_count=3,
fmt='%(asctime)s - %(levelname)s: %(message)s'):
self.logger = logging.getLogger(filename)
format_str = logging.Formatter(fmt) # 设置日志格式
self.logger.setLevel(self.level_relations.get(level)) # 设置日志级别
sh = logging.StreamHandler() # 往屏幕上输出
sh.setFormatter(format_str) # 设置屏幕上显示的格式
th = handlers.TimedRotatingFileHandler(filename=filename, when=when, backupCount=back_count,
encoding='utf-8') # 往文件里写入#指定间隔时间自动生成文件的处理器
# 实例化TimedRotatingFileHandler
# filename是日志名
# when是间隔时间单位
# backupCount是要保留几个分割后的日志文件
# interval是时间间隔,backupCount是备份文件的个数,如果超过这个个数,就会自动删除,when是间隔的时间单位,单位有以下几种:
# S 秒
# M 分
# H 小时、
# D 天、
# W 每星期(interval==0时代表星期一)
# midnight 每天凌晨
th.setFormatter(format_str) # 设置文件里写入的格式
self.logger.addHandler(sh) # 把对象加到logger里
self.logger.addHandler(th)
def check_code(file):
"""
检查文件所属编码
:param file:文件名称
:return:文件所属编码
"""
file_text = open(file, 'rb').readline()
file_code = chardet.detect(file_text)['encoding']
# 由于windows系统的编码有可能是Windows-1254,打印出来后还是乱码,所以不直接用adchar['encoding']编码
if file_code == 'gbk' or file_code == 'GBK' or file_code == 'GB2312':
file_code = 'GB2312'
else:
file_code = 'utf-8'
return file_code
def get_all_file_path(dirpath, filepathlist):
for filename in os.listdir(dirpath):
if os.path.isfile(os.path.join(dirpath, filename)):
filepath = os.path.join(dirpath, filename)
filepathlist.append(filepath)
elif os.path.isdir(os.path.join(dirpath, filename)):
get_all_file_path(os.path.join(dirpath, filename), filepathlist)
else:
print("跳过文档: ", filename)
def Zip_File(ZIPFILE, ZipFileDir):
LogZip = zipfile.ZipFile(ZIPFILE, 'w', zipfile.ZIP_DEFLATED) # 压缩日志
logfilelist = []
get_all_file_path(dirpath=ZipFileDir, filepathlist=logfilelist)
for file in logfilelist:
LogZip.write(file)
# os.remove(ZipFileDir + '\\' + filename) # 压缩完成后删除文件,以便后续删除原始目录
LogZip.close()
# os.removedirs(ZipFileDir) # 压缩成功后,删除原始目录
return ZIPFILE
def ssh_login(hostname, host, user, passwd, port=22):
"""
实例化ssh登陆
:return:
"""
ssh_client = paramiko.SSHClient()
ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy)
try:
ssh_client.connect(hostname=host, username=user, password=passwd, port=port, timeout=10,
look_for_keys=False, allow_agent=False)
except (TimeoutError, Exception) as e:
message = '{}\t无法访问,登录超时。'.format(hostname) + str(e)
log.logger.error(message)
pool_sema.release() # 解锁
sys.exit(1)
else:
message = '{}\t登录成功。'.format(hostname)
log.logger.warning(message)
return ssh_client
def process_ssh_patrol_data(host, session, cmds: list, savefile):
"""
:param session: 实例化的ssh
:param cmds: 命令列表
:param savefile: 需要保存的文件名称
:return:
"""
# invoke_shell()函数类似shell终端,可以将执行结果分批次返回,看到任务的执行情况,不会因为执行一个很长的脚本而不知道是否执行成功
shell = session.invoke_shell()
for patrol_cmd in cmds:
print('正在处理{0}: {1}'.format(host, patrol_cmd))
shell.send(patrol_cmd + '\n')
if "show" or "display " in patrol_cmd.lower():
time.sleep(1)
# 确认是否还有数据需要返回
recv_flag = shell.recv_ready()
while recv_flag:
result = shell.recv(65535).decode(encoding='utf-8', errors='ignore')
savefile.write(result)
savefile.flush()
# time.sleep(0.5)
recv_flag = shell.recv_ready()
shell.close()
def get_cmdlist_from_splunk(conn, cursor):
# 配置Splunk服务器信息
HOST = "127.0.0.1"
PORT = 8089
USERNAME = "Splunk-Username"
PASSWORD = "Splunk-Password"
# 创建Service实例
service = client.connect(
host=HOST,
port=PORT,
username=USERNAME,
password=PASSWORD
)
# 设置查询语句
# 查询5分钟前到此刻的数据
kwargs_oneshot = {"earliest_time": "-5m@m", "latest_time": "now"}
# 设置查询语句
spl = os.path.join(script_path, 'splunkSearch.txt')
with open(spl, 'r', encoding='utf-8') as spl_f:
spl_data = spl_f.read()
searchquery_oneshot = "search " + spl_data
# 运行并保存运行结果,以Json格式输出数据
oneshotsearch_results = service.jobs.oneshot(searchquery_oneshot, **kwargs_oneshot, output_mode='json')
# 使用JSONResultsReader方法获取数据
reader = results.JSONResultsReader(oneshotsearch_results)
iplist = []
for result in reader:
if isinstance(result, results.Message):
# 调试数据使用会话形式展示
log.logger.info(f'{result.type}: {result.message}')
elif isinstance(result, dict):
# Normal events are returned as dicts
banDate = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
sql_search = cursor.execute("SELECT IP FROM BanIP WHERE IP = '%s';" % result['src_ip'].strip()).fetchone()
if sql_search is None:
sql_insert = "INSERT INTO BanIP (IP,Ban_date) select '{0}','{1}';".format(result['src_ip'].strip(),
banDate)
cursor.execute(sql_insert)
conn.commit()
iplist.append('ip {}/32'.format(result['src_ip'].strip()))
log.logger.info(f'获取如下更新数据:\n\t' + '\n\t'.join(ip for ip in iplist))
conn.close()
return iplist
def run(cmdlist, hostIP, hostname, port=22):
"""
获取返回数据
:return:
"""
user = 'FW-Username'
passwd = 'FW-Password'
session = ssh_login(hostname, hostIP, user, passwd, port)
logfile = os.path.join(logDir, hostIP + '_' + hostname + '.txt')
# 巡检命令信息采集
with open(logfile, 'w', encoding='utf-8',
newline='') as patrol_data:
process_ssh_patrol_data(host=hostIP, session=session, cmds=cmdlist, savefile=patrol_data)
log.logger.info('%s 命令执行完成' % hostIP)
session.close()
pool_sema.release() # 解锁
if __name__ == '__main__':
# user = input('请输入用户名:')
# passwd = getpass.getpass('请输入密码:')
# while True:
# try:
# thread_num = int(input('同时处理的设备数量(默认5台):') or 5)
# except:
# print('请输入数字后回车!')
# continue
# script_path = os.path.split(os.path.realpath(__file__))[0]
script_path = os.path.dirname(os.path.realpath(sys.executable))
print('script_path >: ',script_path)
logpath = os.path.join(script_path, 'BanIP.log')
log = Logger(logpath, level='debug')
DB = os.path.join(script_path, 'BanIP.db')
conn = sqlite3.connect(DB)
cursor = conn.cursor()
# 数据库创建表可以自动执行
cursor.execute("""CREATE TABLE IF NOT EXISTS BanIP (
ID INTEGER PRIMARY KEY AUTOINCREMENT,
IP VARCHAR(20),
Ban_date VARCHAR(20))""")
cmdlist = get_cmdlist_from_splunk(conn, cursor)
if len(cmdlist) == 0:
log.logger.info('无更新数据,程序退出。')
sys.exit(0)
else:
cmdlist.append('show config address "Addr_HWBlackIP_01"')
cmdlist.append('save')
cmdlist.append('y')
cmdlist.append('\n')
cmdlist.insert(0, 'terminal length 0')
cmdlist.insert(1, 'terminal width 512')
cmdlist.insert(2, 'config')
cmdlist.insert(3, 'address "Addr_HWBlackIP_01"')
thread_num = 5
device_file = os.path.join(script_path, 'device_list.csv')
threads_list = []
logRootDir, logDir = mk_log_dir()
pool_sema = threading.BoundedSemaphore(thread_num)
with open(device_file, 'r', encoding='utf-8') as f:
data = csv.reader(f)
next(data)
for dev_data in data:
try:
pool_sema.acquire()
mythread = threading.Thread(
target=run, args=(cmdlist, dev_data[3], dev_data[1], dev_data[4]))
mythread.start()
threads_list.append(mythread)
except IndexError:
pass
for t in threads_list:
t.join()
print('正在打包日志数据。。。')
Zip_File(ZIPFILE=logRootDir.split()[-1] + ".zip", ZipFileDir=logRootDir)
print('打包日志数据完成!')
-
自动去读取事件警报的数据,保存在数据库中的同时,也对已有的数据进行筛选,去除重复项后,生成IP封禁名单。
-
读取当前目录下文件名为
device_list.csv文件,用于在对应防火墙上封禁对应策略。此处只针对于山石防火墙。
2.2 打包脚本为可执行文件
pyinstaller.exe -F .\BanDirSearch.py
2.3 编写shell/bat脚本调用执行文件
# linux
#!/bin/bash
/opt/splunk/bin/scripts/banip
# Windows
rem 关闭回显
@echo off
rem 切换路径到要执行的脚本文件目录位置
cd /d D:\splunk\bin\scripts
rem 执行python文件
banip.exe
- 当事件触发时,即可触发脚本执行。
- windows 脚本基础可以参考:最全Windows下通过bat脚本执行python程序(从编写到执行到拓展到更换图标全过程)_bat脚本编写python运行命令-CSDN博客

