
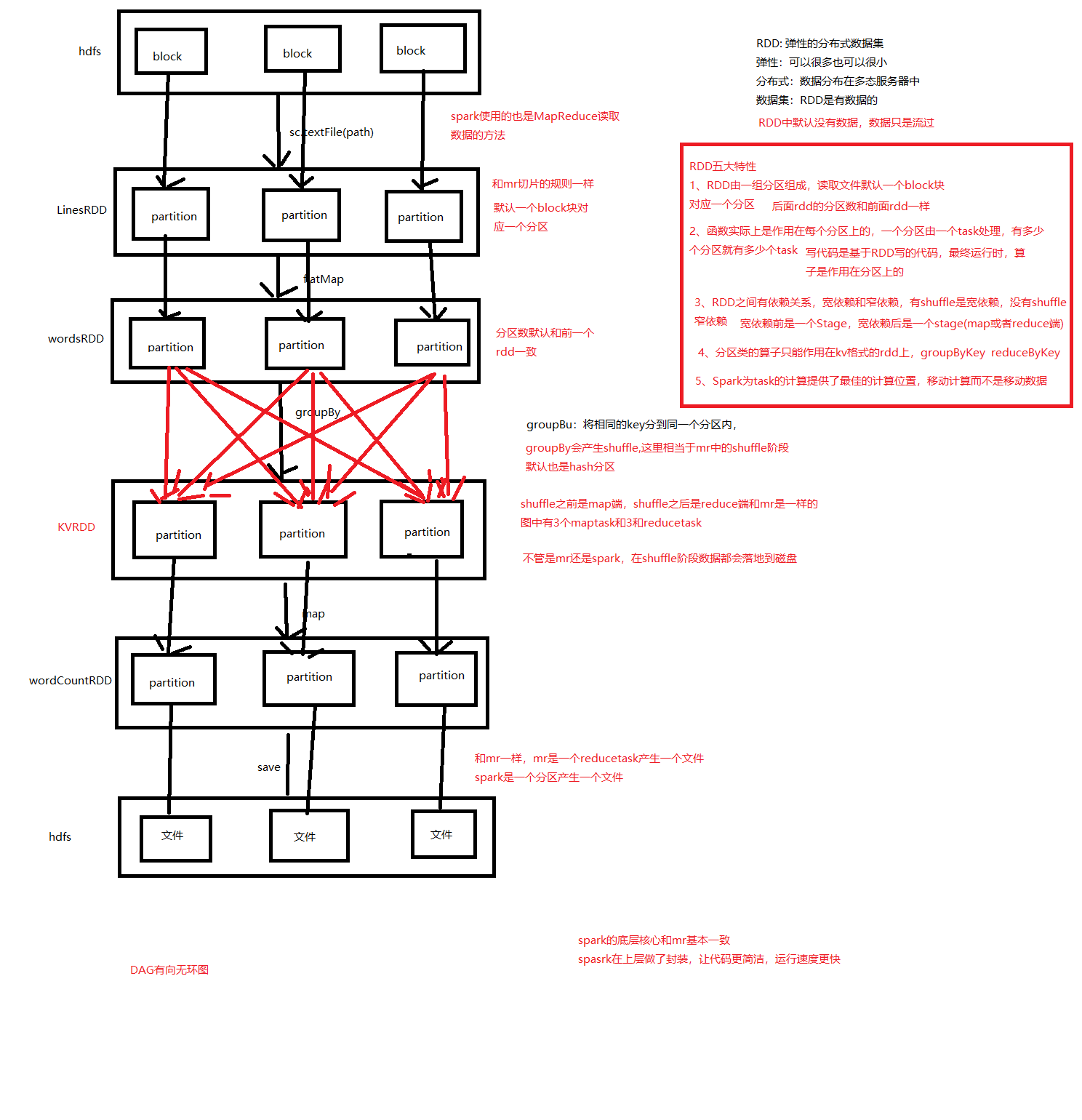
Spark WordCount
WordCount基本流程和spark实现
基本流程
1.创建spark环境
2.创建创建spark上下文对象,也就是spark写代码的入口
3.读取文件中的数据
4.首先将每一行数据展开,让每一个word单独一行
5.将word进行分组
6.对word出现的次数分别统计
7.将结果保存在新的文件中
代码实现
object Demo1WordCount {
def main(args: Array[String]): Unit = {
/**
* 1、创建spark环境
*
*/
//spark环境配置对象
val conf = new SparkConf()
//设置spark任务的名称
conf.setAppName("WordCount")
//设置spark运行模式,local:本地运行
conf.setMaster("local")
//创建spark上下文对象,sc是spark写代码的入口
val sc = new SparkContext(conf)
//读取数据
val linesRDD: RDD[String] = sc.textFile("data/words.txt")
//将数据展开
val splitRDD: RDD[String] = linesRDD.flatMap((line: String) => line.split(","))
//将word进行分组
val groupByRDD: RDD[(String, Iterable[String])] = splitRDD.groupBy((word: String) => word)
//计算word出现的次数
val wordCount: RDD[(String, Int)] = groupByRDD.map {
case (word: String, words: Iterable[String]) =>
(word, words.size)
}
/**
* 6、保持数据
*
*/
wordCount.saveAsTextFile("data/wordCount")
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号