HBase的读写流程
![]()
1.1 HBase读流程
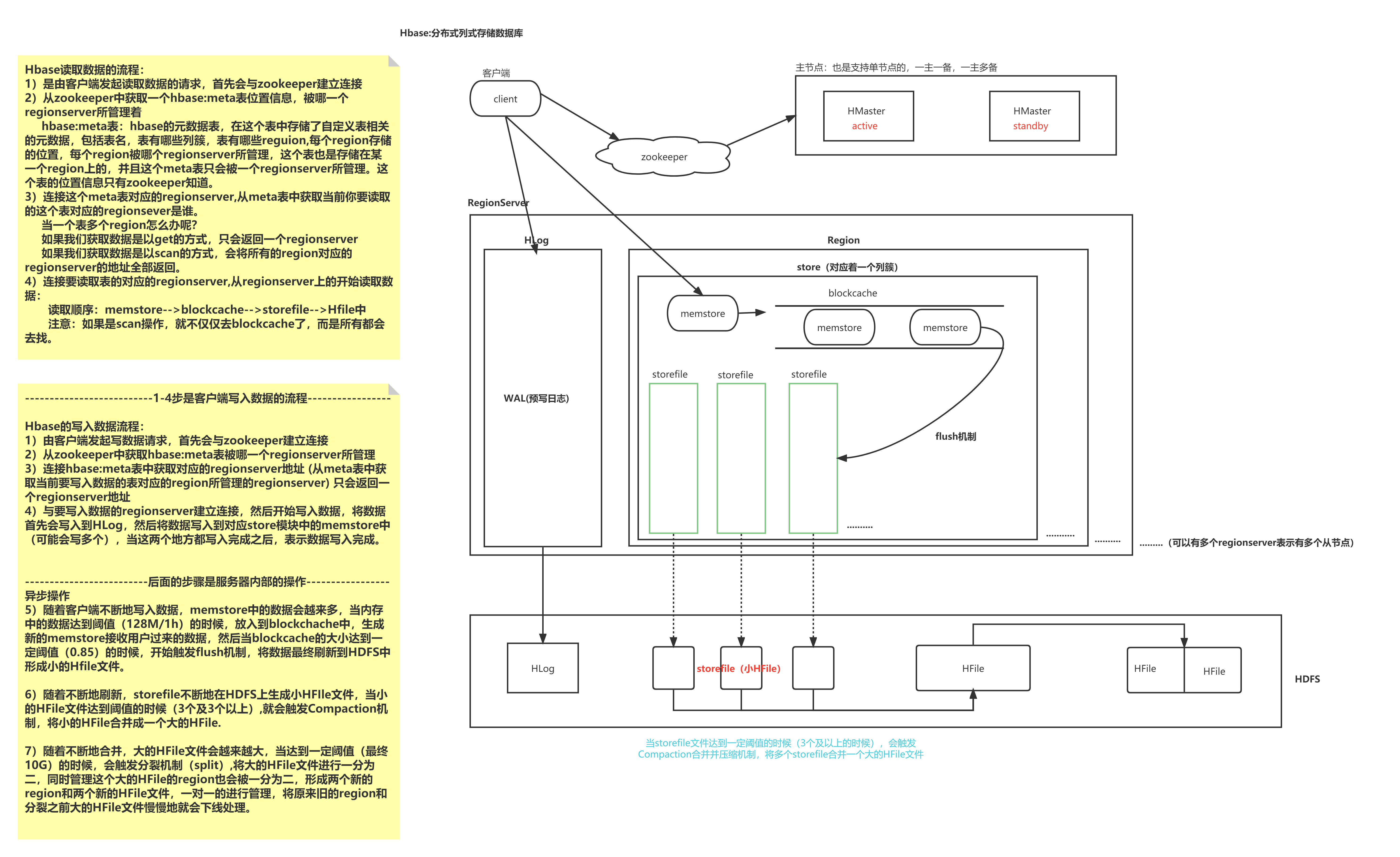
Hbase读取数据的流程:
1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接
2)从zookeeper中获取一个hbase:meta表位置信息,被哪一个regionserver所管理着
hbase:meta表:hbase的元数据表,在这个表中存储了自定义表相关的元数据,包括表名,表有哪些列簇,表有哪些reguion,每个region存储的位置,每个region被哪个regionserver所管理,这个表也是存储在某一个region上的,并且这个meta表只会被一个regionserver所管理。这个表的位置信息只有zookeeper知道。
3)连接这个meta表对应的regionserver,从meta表中获取当前你要读取的这个表对应的regionsever是谁。
当一个表多个region怎么办呢?
如果我们获取数据是以get的方式,只会返回一个regionserver
如果我们获取数据是以scan的方式,会将所有的region对应的regionserver的地址全部返回。
4)连接要读取表的对应的regionserver,从regionserver上的开始读取数据:
读取顺序:memstore-->blockcache-->storefile-->Hfile中
注意:如果是scan操作,就不仅仅去blockcache了,而是所有都会去找。
1.2 HBase写流程
--------------------------1-4步是客户端写入数据的流程-----------------
Hbase的写入数据流程:
1)由客户端发起写数据请求,首先会与zookeeper建立连接
2)从zookeeper中获取hbase:meta表被哪一个regionserver所管理
3)连接hbase:meta表中获取对应的regionserver地址 (从meta表中获取当前要写入数据的表对应的region所管理的regionserver) 只会返回一个regionserver地址
4)与要写入数据的regionserver建立连接,然后开始写入数据,将数据首先会写入到HLog,然后将数据写入到对应store模块中的memstore中
(可能会写多个),当这两个地方都写入完成之后,表示数据写入完成。
-------------------------后面的步骤是服务器内部的操作-----------------
异步操作
5)随着客户端不断地写入数据,memstore中的数据会越来多,当内存中的数据达到阈值(128M/1h)的时候,放入到blockchache中,生成新的memstore接收用户过来的数据,然后当blockcache的大小达到一定阈值(0.85)的时候,开始触发flush机制,将数据最终刷新到HDFS中形成小的Hfile文件。
6)随着不断地刷新,storefile不断地在HDFS上生成小HFIle文件,当小的HFile文件达到阈值的时候(3个及3个以上),就会触发Compaction机制,将小的HFile合并成一个大的HFile.
7)随着不断地合并,大的HFile文件会越来越大,当达到一定阈值(最终10G)的时候,会触发分裂机制(split),将大的HFile文件进行一分为二,同时管理这个大的HFile的region也会被一分为二,形成两个新的region和两个新的HFile文件,一对一的进行管理,将原来旧的region和分裂之前大的HFile文件慢慢地就会下线处理。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号