15. Kubernetes - HPA
HPA
使用 Deployment 的时候知道了可以通过 kubectl scale 的方式调整集群中 Pod 的副本数以满足业务的需求。
在生产环境中,应用的资源使用率通常都有高峰和低谷的时候,如何削峰填谷,提高集群的整体资源利用率,并且尽可能的减少人工干预。Kubernetes 提供了这样一种资源对象:Horizontal Pod Autoscaling,Pod 水平自动伸缩,即 HPA。
HPA 通过监控分析控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量,其原理如下:
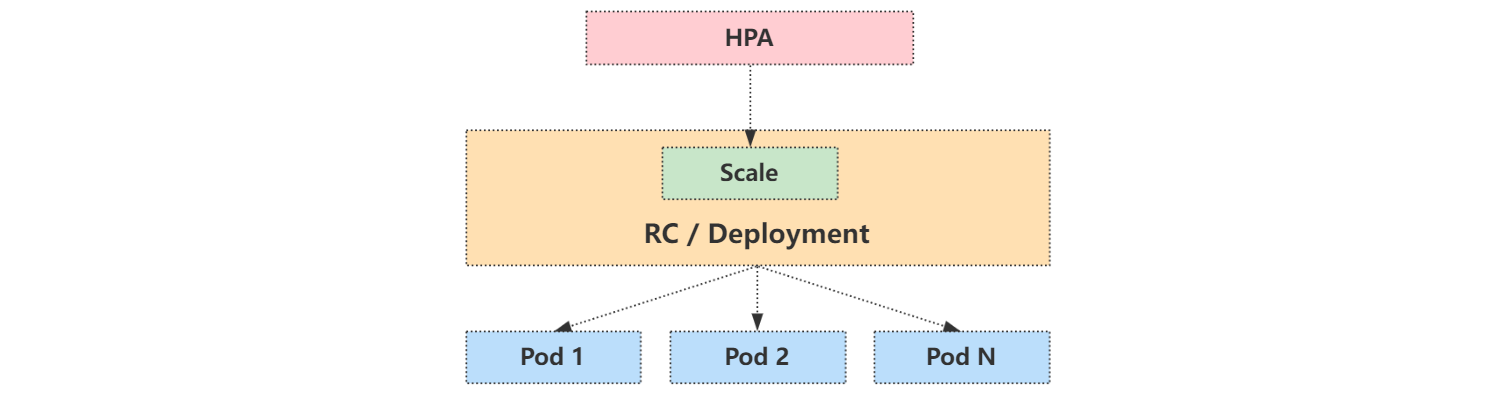
用户通过 kubectl autoscale 命令来创建一个 HPA 资源对象,该资源对象的 HPA Controller 会默认以 30s 轮询一次去查询指定的资源中的 Pod 资源使用率,并且与创建时设定的值和指标做对比,从而判断是否需要进行自动伸缩。
如果想要调整轮询时间,也可以通过 kube-controller-manager 的 --horizontal-pod-autoscaler-sync-period 参数进行调整。
Metrics Server
Kubernetes 自 1.2 版本引入 HPA 机制,到 1.6 版本之前一直是通过 kubelet 来获取监控指标进行判断是否需要扩缩容。
从 1.6 版本开始,则必须通过 API server、Heapseter 或者 kube-aggregator 来获取监控指标。
HPA 仅适用于 Deployment 和 ReplicaSet,在 v1 版本中仅支持根据 Pod 的 CPU 利用率扩缩容,需要通过 Heapster 提供 CPU 指标。从在 v1alpha 开始支持根据内存和用户自定义的 metric 扩缩容。在 HPA v2 过后就需要安装 Metrcis Server 了。
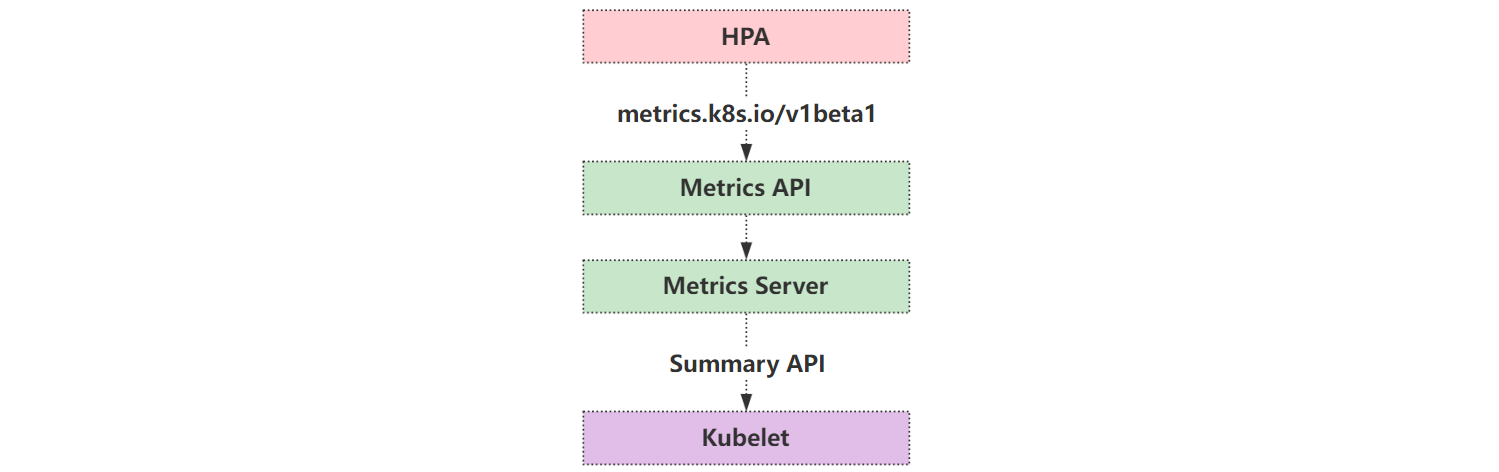
Metrics Server 可以通过标准的 Kubernetes API 把监控数据暴露出来,然后通过 API 来访问想要获取的监控数据:
https://192.168.200.100:16443/apis/metrics.k8s.io/v1beta1/namespaces/
/pods/
当访问该 API 时,用户就可以获取到该 Pod 的资源数据,这些数据其实是来自于 kubelet 的 Summary API 采集而来。
需要注意的是,虽然可以通过标准的 API 来获取资源监控数据,但这并不表示 Metrics Server 就是 APIServer 的一部分。其实质是通过 Kubernetes 提供的 Aggregator 汇聚插件来实现,Metrics Server 独立于 APIServer 之外运行。
聚合 API
Aggregator 允许开发人员编写一个自己的服务,把这个服务注册到 Kubernetes 的 APIServer 里面去,这样就可以像原生的 APIServer 提供的 API 一样去使用自己的 API。
将开发人员自己开发的服务运行在 Kubernetes 集群中,然后 Kubernetes 的 Aggregator 通过接口前缀将请求转发到对应的 Service,类似于 Nginx 的反向代理。这样做的好处有:
- 增加了 API 的扩展性,开发人员可以编写自己的 API 服务来暴露想要的 API。
- 丰富了 API,通过允许开发人员将自己的 API 作为单独的服务公开,这样就无须社区繁杂的审查,合并代码,使得 Kubernetes 变得臃肿。
- 开发分阶段实验性 API,新的 API 可以在单独的聚合服务中开发,当它稳定之后,想要再合并到 APIServer 就很容易了。
- 确保新 API 都遵循 Kubernetes 约定。
安装 Metrics Server
要使用 HPA,就需要在集群中安装 Metrics Server 服务,要安装 Metrics Server,就需要开启 Aggregator。
如果集群是通过 Kubeadm 搭建的,默认已经开启了,如果是二进制方式安装的集群,还需要单独配置 kube-apsierver 添加如下参数并重启:
--requestheader-client-ca-file=<path to aggregator CA cert>
--requestheader-allowed-names=aggregator
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--proxy-client-cert-file=<path to aggregator proxy cert>
--proxy-client-key-file=<path to aggregator proxy key>
如果是按照我写的二进制安装方法,默认是已经配置了这些参数的。如果不是,可能需要单独再签发对应的证书,然后再进行配置。
如果 kube-proxy 没有和 APIServer 运行在同一台主机上,则需要增加 kube-apsierver 的启动参数:
--enable-aggregator-routing=true
Metrics Server 官方仓库地址如下:
任意 Master 节点下载最新的 Metrics Server 高可用资源清单,高可用的好处在于会部署多个 Pod,避免单节点故障:
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/high-availability.yaml
修改资源清单内容,具体需要修改的地方如下:
# 修改 Deployment 部分的内容
apiVersion: apps/v1
kind: Deployment
...
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
# 新增下面证书相关认证,1.25+ 中跳过认证好像有问题
- --kubelet-insecure-tls
# 这个证书是需要被挂载在容器中去,如果没配置证书会报错 x509
- --requestheader-client-ca-file=/ezops/certs/front-proxy-ca.pem
- --requestheader-username-headers=X-Remote-User
- --requestheader-group-headers=X-Remote-Group
- --requestheader-extra-headers-prefix=X-Remote-Extra-
# 修改成能访问到的镜像,这里使用 docker hub 上的镜像替换
image: bitnami/metrics-server:0.6.1
...
volumeMounts:
...
# 新增挂载证书目录,如果是 kubeadm 安装,则修改为 /etc/kubernetes/pki
- mountPath: /ezops/certs
name: ssl-dir
...
volumes:
...
# 声明证书目录,将 Pod 运行节点之前分发的证书挂载到容器中去
- name: ssl-dir
hostPath:
path: /ezops/certs
...
# 如果是 Kubernetes 1.25+ 版本,需要将这里的 apiVersion 从 policy/v1beta1 更换为 policy/v1
# 否则会报错:no matches for kind "PodDisruptionBudget" in version "policy/v1beta1"
apiVersion: policy/v1
kind: PodDisruptionBudget
...
创建资源清单:
kubectl apply -f high-availability.yaml
如图所示:

此时会在 kube-system 名称空间中创建两个 Pod:

查看聚合到 apiserver 中的效果:
kubectl get apiservice
如图所示:

查看获取到的资源数据:
kubectl top nodes
如图所示:

到此,Metrics Server 安装完成!
创建 HPA(命令)
首先创建一个 Deployment 资源清单,通过它实现 HPA 自动扩容:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-demo
namespace: default
sepc:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
version: v1.0
spec:
containers:
- name: demo
image: nginx
ports:
- containerPort: 80
通过 apply 将 Pod 创建出来,然后基于它创建 HPA 资源对象:
# 创建 HPA
kubectl autoscale deploy deploy-demo --cpu-percent=10 --min=1 --max=3
# 查看 HPA
kubectl get hpa
如图所示:

通过命令创建了一个关联 Deployment 资源的 HPA,最小的 Pod 副本数为 1,最大为 3。HPA 会根据设定的 cpu 使用率(10%)动态的增加或者减少 Pod 数量。
查看 HPA 信息:
kubectl describe hpa deploy-demo
出现报错:the HPA was unable to compute the replica count: failed to get cpu utilization: missing request for cpu
这是因为上面创建的 Pod 对象没有添加 requests 资源声明,这样导致 HPA 读取不到 CPU 指标信息,无法判断是否应该扩缩容。所以如果要想让 HPA 生效,对应的 Pod 资源必须添加 requests 资源声明,资源清单文件需要修改为:
apiVersion: apps/v1
...
spec:
containers:
...
# 新增 resources 的 requests 配置
resources:
requests:
memory: 50Mi
cpu: 50m
增加了 resources 的 requests 限制,删除 hpa 后重建生效。
kubectl delete hpa deploy-demo
此时再次运行 kubectl get hpa 后 TAGETS 字段就不再有 unknow 了。
测试 HPA
通过访问 Pod 中的 Nginx 来提升 CPU 使用量:
while true; do wget -q -O- 172.16.222.36;done
可以看到 Pod 数量从 1 个变成了三个:

停掉请求之后,Pod 在第一时间也不会降下来,需要 5 分钟的观察期,这相当于一种保护机制,避免因为临时降低而反复创建删除 Pod。
想要修改 HPA 缩放时间,可以在 kube-controller-manager 中修改相关配置 --horizontal-pod-autoscaler-downscale-stabilization,默认 5 分钟。
创建 HPA(资源清单)
删除上面创建的 HPA,然后使用资源清单重建 HPA:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-mem-demo
spec:
# 指定 Deployment
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deploy-demo
# 设置扩缩容副本数
minReplicas: 1
maxReplicas: 3
metrics:
- type: Resource
resource:
# 指定指标
name: memory
target:
# 指定阈值,为了便于测试,将值调整很低
averageUtilization: 5
通过 apply 创建 HPA 之后可以看到:

由于阈值很低,直接就触发了扩容:

除了 HPA 以外,还有 VPA,也就是垂直扩容,和 HPA 不同在于不是增加 Pod 而是在原有 Pod 身上增加资源配置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号