最详细的后缀数组
写在前面:
多余的我就不提了,只是觉得网上的博客吧流程,每个数组存的是下标还是值,都讲的不是很清楚(让我这种蒟蒻很是困扰)
相信到现在这种水平的都可以知道什么是倍增,为什么能倍增都比较清楚了,但是代码实现总感觉怪怪的…… 本文的定位就是想把代码实现的部分讲清楚…… 现在请听我娓娓道来……
清爽代码:
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
const int MAX=1e6+5;
int n,m;
int tax[MAX],rak[MAX],tp[MAX],sa[MAX];
char s[MAX];
void sort(int a[],int b[]){
for(int i=0;i<=m;i++)tax[i]=0;
for(int i=1;i<=n;i++)tax[a[i]]++;
for(int i=1;i<=m;i++)tax[i]+=tax[i-1];
for(int i=n;i>=1;i--)sa[tax[a[b[i]]]--]=b[i];
}
bool comp(int r[],int a,int b,int k){
return r[a]==r[b]&&r[a+k]==r[b+k];
}
void get_sa(int a[],int b[]){
for(int i=1;i<=n;i++)
m=max(m,a[i]=s[i]-'0'),b[i]=i;
sort(a,b);
for(int p=0,j=1;p<n;j<<=1,m=p){
p=0;
for(int i=1;i<=j;i++)b[++p]=n-j+i;
for(int i=1;i<=n;i++)if(sa[i]>j)b[++p]=sa[i]-j;
sort(a,b);
int *t=a;a=b;b=t;
a[sa[1]]=p=1;
for(int i=2;i<=n;i++)
a[sa[i]]=comp(b,sa[i],sa[i-1],j)?p:++p;
}
}
int main(){
scanf("%s",s+1);
n=strlen(s+1);
get_sa(rak,tp);
for(int i=1;i<=n;i++)printf("%d ",sa[i]);
}
洛谷模板:后缀排序
一些定义:
看了上面的代码,你应该对后缀数组有了一个初步的印象吧(复杂、玄学而又美丽的代码)
我们先看看数组的定义:
- sa[i]=j ,表示第 i 名的后缀是从 j 开始的(注意存的是下标)
- rank[i]=j ,从 i 开始的后缀是第 j 名的(和 sa 互逆,是排名(值))
- tp[i] (b[i]) =j,第二关键字为 i 的后缀是从 j 开始的 (相当于是第二关键字的 sa 数组,存的是下标)
- tax[i]=j,表示第一关键字为 i 的数,有 j 个(基数排序时用的桶,是值)
知道了这些,相信你可以初步理解了吧(我都不信)
我们看看后缀排序的流程
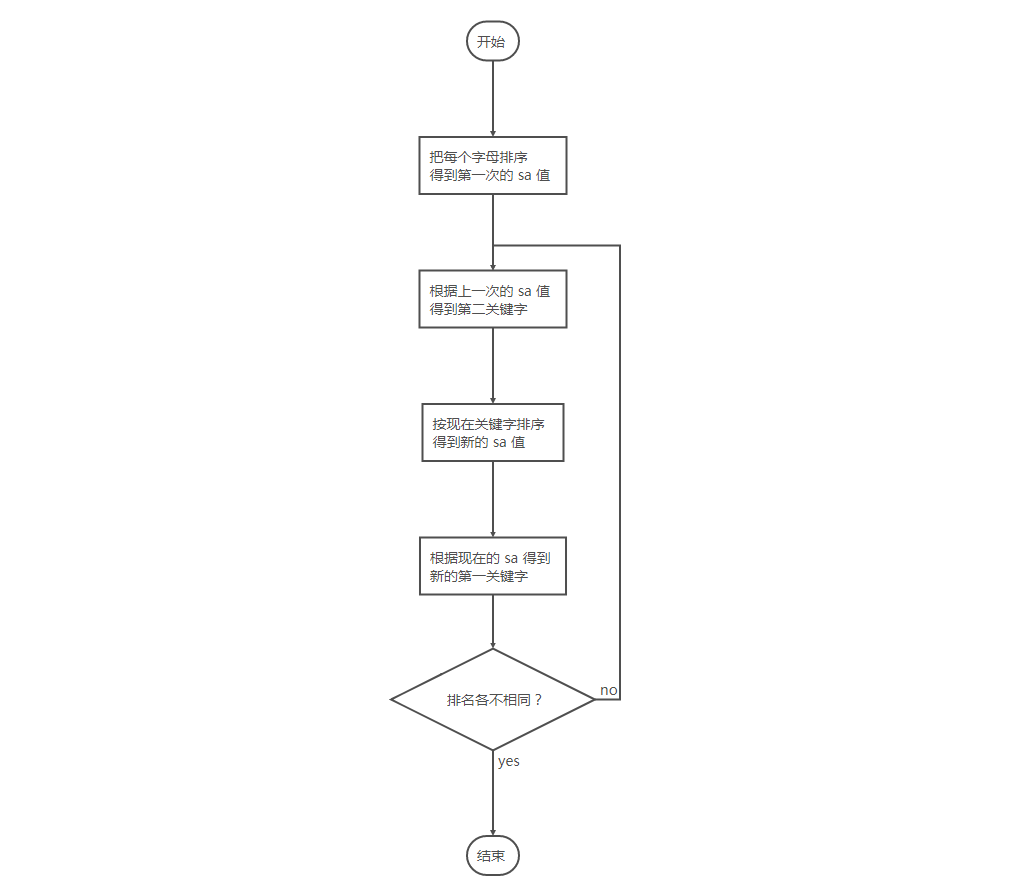
这是算法的具体流程,但是为什么跟上面的代码似乎看不出来有什么联系……
我们把现在就把代码都解剖一下,细嚼慢咽食用更佳。
基数排序
当然你可以想到,我们是否能把关键字放到 pair 里,sort 一遍不就行了?
但是这样是 \(log^2\) 的,不是那么优秀,我们可以用一种比 sort 更快的方法——基数排序。
void sort(int a[],int b[]){
for(int i=0;i<=m;i++)tax[i]=0;
for(int i=1;i<=n;i++)tax[a[i]]++;
for(int i=1;i<=m;i++)tax[i]+=tax[i-1];
for(int i=n;i>=1;i--)sa[tax[a[b[i]]]--]=b[i];
}
别看他有这么一个高大尚的名字,其实他和桶排是同一个妈生的……
看代码:(n是字符串长度,m是数字的总数)
for(int i=0;i<=m;i++)tax[i]=0;
桶清零,不用说……
for(int i=1;i<=n;i++)tax[a[i]]++;
每个数放进各自的桶……
for(int i=1;i<=m;i++)tax[i]+=tax[i-1];
加上前边的桶的值,也就是现在这个值的排名……
for(int i=n;i>=1;i--)sa[tax[a[b[i]]]--]=b[i];
这行挺复杂
第一关键字(a 那层),第二关键字从大到小(b 那层),的桶内有多少个数(tax 那层),现在的这名,就是 b[i](sa 那层),然后桶内的数就减去一。
说的有点绕……这真心不好解释(可能是我的语言表达能力欠佳吧)
剩下的……
for(int p=0,j=1;p<n;j<<=1,m=p)
倍增嘛(又是这图)

for(int i=1;i<=j;i++)b[++p]=n-j+i;
for(int i=1;i<=n;i++)if(sa[i]>j)b[++p]=sa[i]-j;
这是更新第而关键字
第一个for,就是说后面越界的数关键字为零,当然排在前面。
第二个for,按排名,如果这个后缀在 j 后,就能做为 sa[i]-j 的第二关键字。
sort(a,b);
int *t=a;a=b;b=t;
a[sa[1]]=p=1;
for(int i=2;i<=n;i++)
a[sa[i]]=comp(b,sa[i],sa[i-1],j)?p:++p;
基数排序并更新第一关键字。
swap 一下只是因为不想多开一个数组,没有别的意思,现在 a 是新关键字,b 是旧关键字。
第一名的第一关键字肯定是 1 啦。
从二开始,如果现在的这名和前一名的两个关键字相等就是并列,否则就排到后一名。
comp 代码……
bool comp(int r[],int a,int b,int k){
return r[a]==r[b]&&r[a+k]==r[b+k];
}
完了吗?
后缀排序的部分到这里就已经结束了……
但是光有个后缀排序有什么实质性的用处吗?
了解过的同学应该知道,有这么一个 height 数组,height[i] 表示的是,排名为 i 的后缀与排名为 i-1 的后缀的 LCP(最长公共前缀)
有了这个东东,就可以在后缀数组上乱搞,许多问题都能迎刃而解……
但怎么求是个问题,朴素的 \(n^2\) …… 算了吧
我们有这样一个性质 \(height[i+1] \ge height[i]-1\)
根据这样的性质,可以 \(O(n)\) 求 height
for(int i=1,j=0;i<=n;i++){
if(j)j--;
while(s[i+j]==s[sa[rak[i]-1]+j])j++;
height[rak[i]]=j;
}
好了真的完了,这里不多说理论,目的只是填一下代码实现的坑,后缀数组的模板代码已经完了,希望有助于大家理解,再也不用痛苦的背板了……(卒)
