简单说说双目立体视觉的原理(后面有机会再讲讲应用)
现在三维视觉越来越成为趋势,尤其和机器人结合后,相当于手臂带了眼睛,真正的活了起来。
下面简单说说最常用的双目立体视觉的原理。
都是大白话,也不秀公式了,搞工程着重怎么用,至于算法优化,留给年轻的精英学子们研究。
双目立体视觉(Binocular Stereo Vision):
基于视差原理并利用成像设备从不同的位置获取被测物体的两幅图像,通过计算图像对应点间的位置偏差,来获取物体三维几何信息的方法。
概念都比较抽象,上个图能清晰一点(图是引用来的,说的比较清晰),其实原理很简单,就是仿真人的双眼对3D物体的立体定位机制。
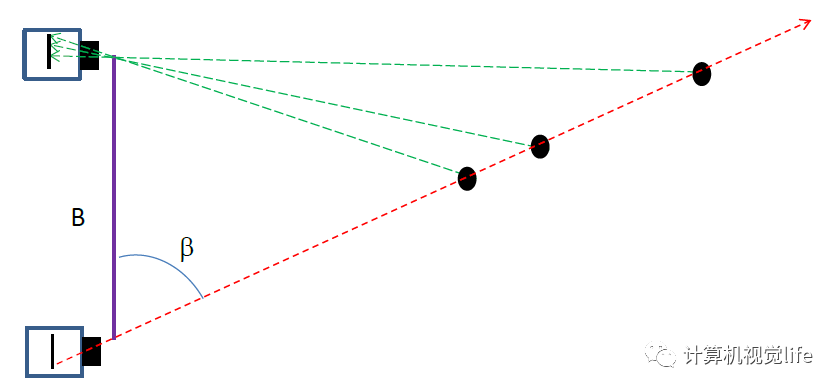
简单说就是,一个眼睛能成像但是不能确定z轴的深度,但是另一个眼睛根据成像的位置和角度,辅助计算确定深度。
毕竟两只眼睛的距离是个确定值。按三角形的原理,两个角一个边,足够算出来所有数据了,包括深度。
实际在实现的时候当然没有这么简单,我们需要知道 相机焦距,两相机基线-可以简单看成就是两相机的距离了,视差等数据。
这里还有个极线约束,名字很吓人,其实原理很简单。
已知A图中P点,查找它在B图中的位置,其实不用全图找,只需要在根据投影规律在有限范围找就可以了。这样缩小范围,减少计算。
浓缩后的原理如下
对A图中每个点
根据极线约束的规则
找到B图中对应的点
计算所有点的深度,形成深度图
然后,所有上面这些都有一个假设,就是两个相机是在同一个平面的,并且光轴要是平行的。
但是实际情况中是找不到这样的两个相机的。咋办?
先标定得到单应(homography)矩阵
然后把两图像根据矩阵校正成理想状态
最后就可以按理想状态计算深度了
一般双目立体视觉的简单步骤:
1、首先要对双目相机进行标定。
2、然后根据标定结果校正原始图像,使两张图像在同一平面且互相平行。
3、再对校正后的两张图像进行像素点的匹配。
4、根据结果计算每个像素的深度,获得深度图。
下面说说双目立体视觉法优缺点
优点
1、相机硬件要求低,成本低。使用普通的消费级RGB相机即可。但是工程上一般直接采购双目深度相机。代表有:Leap Motion, ZED, 大疆;
2、不挑环境,室内外都适用。由于直接根据环境光采集图像,适用范围广。
缺点
1、对环境光照非常敏感。
由于光照角度、强度变化影响,拍摄的两张图片亮度差别会比较大,对匹配算法提出很大的挑战。另外,在光照较强(会出现过度曝光)和较暗的情况下也会导致算法效果急剧下降。
2、需要有较好的辨识特征场景,不适用于单调缺乏纹理的场景。
由于算法是根据视觉特征进行图像匹配,所以对于弱视觉特征的场景(如平板、白墙)匹配困难,误差较大甚至失败。
3、计算复杂度高。
逐像素计算;又要保证匹配结果健壮可信,需要增加大量的错误剔除策略,对算法要求较高,想要实现可靠商用难度大,计算量较大。
4、相机基线限制了测量范围。
测量范围受限于基线(两个摄像头间距):基线越大,测量范围越远;基线越小,测量范围越近。
至于更深入的想深入了解原理的同学,可以看看大神的PPT。
详细数学原理点这里
好吧,原理就到这,后面有时间整个在Halcon中是怎么实现的出来。
看了感觉怎么样?来说说吧。。。
喜欢记得关注起来!赶紧的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号