TaxoRec部署与代码阅读
部署环境
- Pytorch 1.8.1
- Python 3.7.3
conda create -n pytorch-taxorec python=3.7.3
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch==1.8.1
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple geoopt==0.2.0
::根据geoot文档,geoot0.2.0以上版本安装时会安装torch1.9.0,故使用0.2.0版本
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
遇到的问题
导入模块报错
发生异常: ModuleNotFoundError
No module named 'utils'
File "C:\Users\13666\Desktop\tan\TaxoRec-master\models\model.py", line 6, in <module>
from utils.helper import default_device
ModuleNotFoundError: No module named 'utils'
解决:
当导入模块时,Python解释器会搜索 sys.path 中的所有路径,如果找不到模块所在的路径就会报错,所以自定义模块要处于 sys.path 里才能被导入。
调试的时候的model.py位于\TaxoRec-master\models\目录下,所以sys.path包含当前执行的文件目录,而不包含utils文件夹目录,故找不到utils模块。
import sys
sys.path.append('C:\\Users\\13666\\Desktop\\tan\\TaxoRec-master')
tensor类型不匹配
Traceback (most recent call last):
File "C:\Users\13666\Desktop\tan\TaxoRec-master\models\model.py", line 86, in decode
emb_in = h[idx[:, 0]]
IndexError: tensors used as indices must be long, byte or bool tensors
解决:
将idx转化为long类型,修改所有类似的代码
emb_in = h[idx[:, 0].long()]
UnboundLocalError
Traceback (most recent call last):
File "C:\Users\13666\Desktop\tan\TaxoRec-master\models\model.py", line 169, in cluster_loss
scores = scores / scores.max()
UnboundLocalError: local variable 'scores' referenced before assignment
出错代码:
if len(node) == 0 or len(node) == 1:
continue
try:
scores = node_list[i].scores.cuda(default_device())
except Exception as e:
print(node_list[i].term_ids, k, i)
scores = scores / scores.max()
一个不太明白的报错,这里scores在try中已经有了定义,UnboundLocalError通常是局部变量未定义就使用导致的。
解决:
if len(node) == 0 or len(node) == 1:
continue
try:
scores = node_list[i].scores.cuda(default_device())
except Exception as e:
print(node_list[i].term_ids, k, i)
continue #test
scores = scores / scores.max()
不知道这样修改有没有隐式的风险。
代码运行
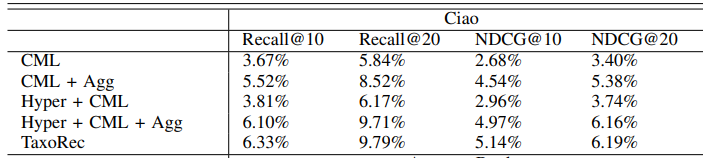
Epoch: 0799 6.710 time: 2.0359s
0.0356 0.0588 0.0968 0.1589
0.042 0.0482 0.0605 0.0784
best_eval [0.06039383853310364, 0.09928730412048004, 0.04828638527394727, 0.0614728631325225]
best_eval [0.06039383853310364, 0.09928730412048004, 0.04828638527394727, 0.0614728631325225]
输出解读与代码思路
第一行输出代码
print(" ".join(['Epoch: {:04d}'.format(epoch),
'{:.3f}'.format(avg_loss),
'time: {:.4f}s'.format(time.time() - t)]), end=' ')
799为轮数,6.710为平均损失,2.0359s为第799轮训练时间
第二到五行输出代码
results = eval_rec(pred_matrix, data)
...
print('\t'.join([str(round(x, 4)) for x in results[0]]))
print('\t'.join([str(round(x, 4)) for x in results[-1]]))
print('best_eval', best_metric)
if unchange == 200:
print('best_eval', best_metric)
break
这里的eval_rec函数返回了recall和 ndcg两个列表,分别代表了
Recall@5, Recall@10, Recall@20, Recall@50
以及
NDCG@5, NDCG@10, NDCG@20, NDCG@50的数值,即
0.0356 0.0588 0.0968 0.1589
0.042 0.0482 0.0605 0.0784
best_eval指的是整个系统的最佳性能,根据前面
recalls = results[0]
if recalls[1] > best_metric[0]:
best_metric[0] = recalls[1]
best_metric[2] = results[1][1]
torch.save(model.state_dict(), save_path)
unchange = 0
if recalls[2] > best_metric[1]:
best_metric[1] = recalls[2]
best_metric[3] = results[1][2]
torch.save(model.state_dict(), save_path)
unchange = 0
else:
unchange += args.eval_freq
可以得出best_metric中存储的分别为[Recall@10,Recall@20,NDCG@10,NDCG@20]的最大值,和数据基本吻合。
参考资料:
Melinda315/TaxoRec (github.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号