Java面试系列第1篇-基本类型与引用类型
这篇文章总结一下我认为面试中最应该掌握的关于基本类型和引用类型的面试题目。
面试题目1:值传递与引用传递
对于没有接触过C++这类有引用传递的Java程序员来说,很容易误将引用类型的参数传递理解为引用传递,而基本类型的传递理解为值传递,这是错误的。要理解值传递与引用传递,首先要理清值传递、引用传递与指针传递三个概念。
值传递与引用传递最重要的就是看在传递的过程中,值是否发生了复制。在Java中没有指针的概念,但是引用类型做为参数进行传递时,JVM将其实现为指针传递,那么重点就是搞清楚指针传递到底是值传递还是引用传递了。指针在传递时也会复制,所以是值传递,Java中不存在引用传递。
面试题目2:int类型的范围
Java中4种基本类型表示的范围如下图所示。
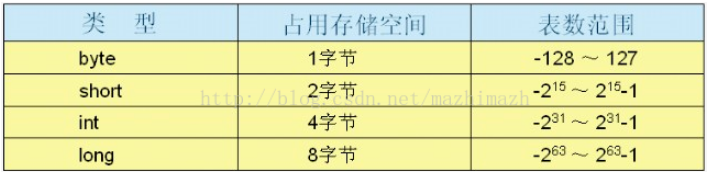
Java中不能明确指示某个数为无符号类型,所以最高位一般为符号位。拿占一个字节的byte来说,由于最高位需要表示符号,所以只能用剩下的7位来表示数。所以最大可表示的数为
0111 1111(二进制)
max = (2^0+2^1+2^2+...+2^6) = 127
最小可表示数的范围用二进制表示应该为:
1111 1111(二进制)
但是对于计算机来说,负数其实是用补码表示的,也就是反码加1,所以在计算机中存储的二进制为1000 0001(补码),这个值才是-127。
我们要对待一种特殊情况,如下:
1000 0000(原码)
1111 1111(反码)
1000 0000(补码)
如果1000 0000表示0的话,那岂不是有了0和-0之分了,所以可以用1000 0000表示-128。
由于符号位的存在,所以在许多的情况下,我们其实只是想保持二进制位的原样,而不是十进制的值。举个例子如下:
public static void main(String[] args) {
byte b = -127;//10000001
int a = b;
System.out.println(a);
a = b & 0xff;
System.out.println(a);
}
输出结果-127,129。
byte类型在转换为int类型时,符号位发生扩展,所以第一次打印a的值时,十进制保持一致,二进制表示为
1111 1111 1111 1111 1111 1111 1000 0001
现在将b和&0xff做与后,十进制已经无法保持一致,因为此时的二进制表示为
0000 0000 0000 0000 0000 0000 1000 0001
这个值是129。有什么用呢?其实在实际操作中,我们经常看到读取字节流时,转换过程中要加&0xff,就是为了保持二进制的原有样子,因为此时关注的并不是十进制值。
面试题目3:Java中对基本类型的赋值是原子操作吗?引用类型呢?
根据虚拟机规范:(https://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html#jls-17.7)
For the purposes of the Java programming language memory model, a single write to a non-volatile
longordoublevalue is treated as two separate writes: one to each 32-bit half. This can result in a situation where a thread sees the first 32 bits of a 64-bit value from one write, and the second 32 bits from another write.Writes and reads of volatile
longanddoublevalues are always atomic.Writes to and reads of references are always atomic, regardless of whether they are implemented as 32-bit or 64-bit values.
Some implementations may find it convenient to divide a single write action on a 64-bit
longordoublevalue into two write actions on adjacent 32-bit values. For efficiency's sake, this behavior is implementation-specific; an implementation of the Java Virtual Machine is free to perform writes tolonganddoublevalues atomically or in two parts.Implementations of the Java Virtual Machine are encouraged to avoid splitting 64-bit values where possible. Programmers are encouraged to declare shared 64-bit values as
volatileor synchronize their programs correctly to avoid possible complications.
Java虚拟机规范表示,Java 基础类型中,long 和 double 是 64 位长的。32 位架构 CPU 的算术逻辑单元(ALU)宽度是 32 位的,在处理大于 32 位操作时需要处理两次。所以有可能在读long的高32位时,低32位被另外一个并发的线程写了,读出的值可就谁也说不准了。对于引用类型来说是原子操作。
举个例子如下:
public class P1 {
private long b = 0;
public void set1() {
b = 0;
}
public void set2() {
b = -1;
}
public void check() {
System.out.println(b);
if (0 != b && -1 != b) {
System.err.println("Error");
}
}
}
在32位下跑这个程序,可能会打印Error,原因就是上面提到的。引起这个问题的最主要原因就是并发,所以如果要解决这个问题,可以让线程序列化访问b,也就是通过加锁来实现;可以使用AtomicLong对长整形进行原子操作;根据虚拟机规范所说,还可以加volatile关键字。
这里只所以volatile关键字能解决这个原子性,其实还是因为为了保证可见性而对内存进行了独占访问,这样在独占操作时,就不会有其它线程改写其中的值了。
面试题目4:关于字符串的面试题
首先来看一下下面的面试题:
另外一个高频的问题就是字符串创建了多少个对象的问题,如下:
String str = new String("ab");
上面一行代码将会创建1或2个字符串。如果在字符串常量池中已经有一个字符串“ab”,那么就只会创建一个“ab”字符串。如果字符串常量池中没有“ab”,那么首先会在字符串池中创建,然后才在堆内存中创建,这种情况就会创建2个对象。
再来看一下下面的面试题:
String a = "ab"; String b = "a" + "b"; a == b
如上的代码会对b进行常量折叠,所以相当于如下程序:
String a = "ab"; String b = "ab"; System.out.println(a == b)
对于Java来说,==对基本类型比较的是值,而对于引用类型比较的是地址,所以要想让a==b输出true,那只能a和b指向同一个对象。"ab" 属于字符串字面量,因此编译时期会在常量池中创建一个字符串对象,如果常量池中已经存在该字符串对象则直接引用,所以最终的结果为true。
String类型的常量池比较特殊。它的主要使用方法有两种:
(1)直接使用双引号声明出来的String对象会直接存储在常量池中。
(2)如果不是用双引号声明String对象,可以使用 String 提供的 intern()方法。它的作用是: 如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用; 如果没有,则在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用。
举个例子如下:
String s1 = new String("ab");// s1保存堆中的引用
String s2 = s1.intern(); // s2保存的是字符串常量池中的引用
String s3 = "ab"; // s3保持的是字符串常量池中的引用
System.out.println(s1 == s2);// false,因为一个是堆内存中的String对象一个是常量池中的String对象,
System.out.println(s2 == s3);// true, s1,s2指向常量池中的”ab“
面试题目5:- 什么情况下用+运算符进行字符串连接比调用StringBuffer/StringBuilder 对象的 append 方法连接字符串性能更好?
当+两边连接的是字符串常量时,Java前端编译器会直接进行优化,看成一个字符串。
当+的一边是引用的时候,创建StringBuilder,利用append方法进行连接操作。由于+一般会转换为StringBuilder的操作,所以在循环中使用时会造成性能差异。例如:
String s = "";
Random rand = new Random();
for (int i = 0; i < 10; i++){
s = s + rand.nextInt(1000) + " ";
}
这个代码就相当于转换为了如下格式的代码:
String s = "";
Random rand = new Random();
for(int i = 0; i < 10; i++)
s = (new StringBuilder(String.valueOf(s))).append(rand.nextInt(1000)).append(" ").toString();
每次都会创建一个StringBuilder对象。所以建议直接用StringBuilder来解决这个事情。如下:
Random rand = new Random();
StringBuilder result = new StringBuilder();
for (int i = 0; i < 10; i++){
result.append(rand.nextInt(1000));
result.append(" ");
}
面试题目6:String怎么保证不变性?为什么要保证不变性?
在java的世界里,String是作为类出现的,核心的一个域就是一个char数组,内部就是通过维护一个不可变的char数组,来向外部输出的。
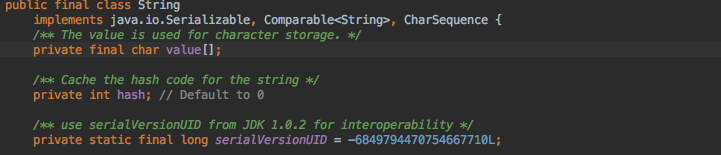
这是jdk一段String类定义,首先类是final,表明类不可被继承;
核心域是private final的,final表明这个引用所指向的内存地址不会改变,但这还不足说明value[]是不可变的;
因为引用所指向的内存的值有可能发生变化,但是jdk是不会让这样的事情发生的。private 保证这个域对外部来说是不可见的,这还不够,对value还要进行 保护性拷贝 。
举一个简单的例子:
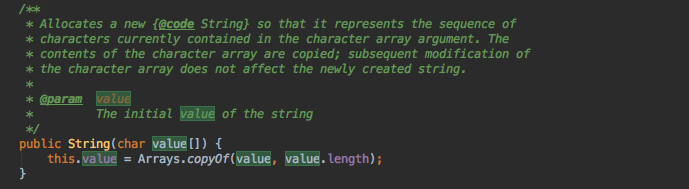
这是一个String的构造函数,参数是一个char数组引用,它并没有把这个数组引用直接赋值给实例对象的value成员变量,而是通过一个Arrays.copyOf的方式拷贝一个数组再给到对象的成员变量。为什么呢?假设它这里是直接一个赋值,那String的不可变性就彻底被破坏了,因为如此一来,存在一个外部引用与实例对象value引用指向相同的内存地址,通过外部引用就可以改变这个char数组对象,最终导致的结果就是String不再不可变。幸好JDK中所有的对value的操作都是保护性拷贝操作,不管是被赋值,还是赋值给其它外部引用。
说了这么多,为什么JAVA要String保持一个不可变的状态呢?原因其实很简单,因为String太常用了,设计成不可变可以减少大量的同步锁的开销。但是要注意 并不是声明成final的类一定是不可变的 。
根据effective java一书中提到,类不变需遵循五条规则:
- 不提供任何机会修改对象状态的方法
- 保证类不被扩展
- 所有域都是私有的、final的
- 确保对于任何可变组件的互斥访问

 浙公网安备 33010602011771号
浙公网安备 33010602011771号