Tensorflow 从文件中载入训练数据
本节包含:
- 用纯文本文件准备训练数据
- 加载文件中的训练数据
一、用纯文本文件准备训练数据
1.数据的数字化
比如,“是” —— “1”,“否” —— “0”
“优”,“中”,“差” —— 1 2 3 或者 3 2 1
2.训练数据的格式
在文本文件中,一般每行存放一条数据,一条数据中可以有多个数据项(有时称为“字段”),数据项中间一般使用英文逗号”,“ 进行分割
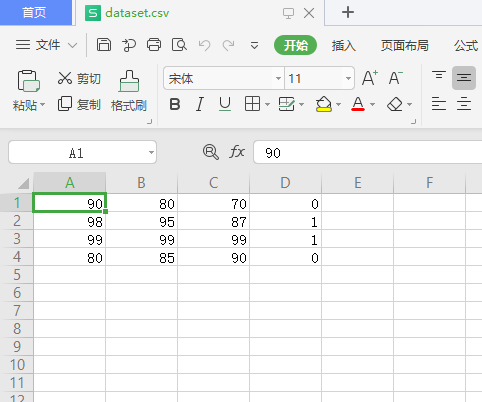
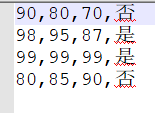
90,80,70,0
98,95,87,1
99,99,99,1
80,85,90,0
这就是三好学生评选结果问题的一组数据,每行代表一位学生的成绩和最后的评选结果
注意: 文本文件一定要以UTF-8 的编码形式来保存,逗号一定是英文的逗号,尽量不要有空格等空白字符
3.使用CSV格式文件辅助处理数据
CSV是逗号分隔值的简称,这种格式的文件中每行都是一个个用逗号分隔开的内容项
CSV格式的文件 是纯文本文件中的一种,也是 Excel 支持的文件格式,所以可以用 Excel 来处理数据
我使用的是 Notepad++ ,一款代码编辑软件

将刚才的数据保存为 .CSV 文件后,可以用Excel 打开,编辑修改
二、加载文件中的训练数据
1.加载函数
numpy包 中的 loadtxt 函数,其中第一个参数是 要读取的文件名和文件所在的目录,第二个参数 delimiter 表示数据项之间用什么字符分隔,第三个参数表示读取的数据类型
import numpy as np wholeData = np.loadtxt(r"C:\Users\DELL\Desktop\abc.txt",delimiter=",",dtype=np.float32) print(wholeData)
[[90. 80. 70. 0.] [98. 95. 87. 1.] [99. 99. 99. 1.] [80. 85. 90. 0.]]
原因分析:在windows系统当中读取文件路径可以使用\,但是在python字符串中\有转义的含义,如\t可代表TAB,\n代表换行,所以我们需要采取一些方式使得\不被解读为转义字符。
1、在路径前面加r,即保持字符原始值的意思。
sys.path.append(r'c:\Users\mshacxiang\VScode_project\web_ddt')
2、替换为双反斜杠
2、替换为双反斜杠
sys.path.append('c:\\Users\\mshacxiang\\VScode_project\\web_ddt')
3、替换为正斜杠
3、替换为正斜杠
sys.path.append('c:/Users/mshacxiang/VScode_project/web_ddt')
2.读取时舍弃非数字列
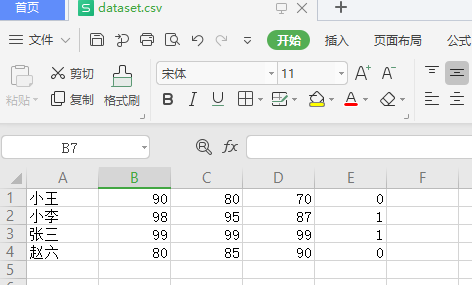
import pandas as pd import numpy as np fileData = pd.read_csv(r'C:\Users\DELL\Desktop\dataset.csv',dtype=np.float32,header=None,usecols=(1,2,3,4)) wholeData = fileData.as_matrix() print(wholeData)
[[90. 80. 70. 0.] [98. 95. 87. 1.] [99. 99. 99. 1.] [80. 85. 90. 0.]]
可见,在读取时已经舍弃了非数字列

3.非数字列与数字列的转换
import pandas as pd import numpy as np fileData = pd.read_csv(r'C:\Users\DELL\Desktop\dataset.csv',dtype=np.float32,header=None,converters={(3):lambda s:1.0 if s == "是" else 0.0}) wholeData = fileData.as_matrix() print(wholeData)
[[90. 80. 70. 0.] [98. 95. 87. 1.] [99. 99. 99. 1.] [80. 85. 90. 0.]]

4.行数据的拆分 及 喂给训练过程
由于从文件中读取的数据是一个第二维有4项的二维数组,而我们原来的数据有两个,一个是分数,每行3项,另一个是评选结果,只有一个数,所以,需要将新的数据格式 拆分后再 喂给神经网络
import tensorflow as tf import numpy as np import pandas as pd fileData = pd.read_csv(r'C:\Users\DELL\Desktop\abc.txt', dtype=np.float32, header=None) wholeData = fileData.as_matrix() #将文件中的数据转换成二维数组 wholeData rowCount = int(wholeData.size / wholeData[0].size) #获取一共多少条数据 # wholeData.size 获得的是 数据的所有项的个数,本题是 4 * 4 = 16 # wholeData[0].size 获得的是第一行的项数,本题是 4 # 所以 行数 = 16 / 4 = 4 goodCount = 0 # 用一个循环统计 符合三号学生条件的数据条数,并放入 goodCount 中 for i in range(rowCount): if wholeData[i][0] * 0.6 + wholeData[i][1] * 0.3 + wholeData[i][2] * 0.1 >= 95: goodCount = goodCount + 1 print("wholeData = %s" % wholeData) print("行数rowCount = %d" % rowCount) print("三好数goodCount = %d" % goodCount) # 定义模型 x = tf.placeholder(dtype=tf.float32) yTrain = tf.placeholder(dtype=tf.float32) w = tf.Variable(tf.zeros([3]), dtype=tf.float32) b = tf.Variable(80, dtype=tf.float32) wn = tf.nn.softmax(w) n1 = wn * x n2 = tf.reduce_sum(n1) - b y = tf.nn.sigmoid(n2) loss = tf.abs(yTrain - y) optimizer = tf.train.RMSPropOptimizer(0.1) train = optimizer.minimize(loss) sess = tf.Session() sess.run(tf.global_variables_initializer()) for i in range(2): for j in range(rowCount): result = sess.run([train, x, yTrain, wn, b, n2, y, loss], feed_dict={x: wholeData[j][0:3], yTrain: wholeData[j][3]}) print(result)

wholeData = [[90. 80. 70. 0.] [98. 95. 87. 1.] [99. 99. 99. 1.] [80. 85. 90. 0.]] 行数rowCount = 4 三好数goodCount = 2 [None, array([90., 80., 70.], dtype=float32), array(0., dtype=float32), array([0.33333334, 0.33333334, 0.33333334], dtype=float32), 80.02626, 0.0, 0.5, 0.5] [None, array([98., 95., 87.], dtype=float32), array(1., dtype=float32), array([0.30555207, 0.33253884, 0.3619091 ], dtype=float32), 80.02626, 12.995125, 0.99999774, 2.2649765e-06] [None, array([99., 99., 99.], dtype=float32), array(1., dtype=float32), array([0.3055522 , 0.33253887, 0.3619089 ], dtype=float32), 80.02626, 18.97374, 1.0, 0.0] [None, array([80., 85., 90.], dtype=float32), array(0., dtype=float32), array([0.3055522 , 0.33253887, 0.3619089 ], dtype=float32), 80.02689, 5.2555237, 0.9948085, 0.9948085] [None, array([90., 80., 70.], dtype=float32), array(0., dtype=float32), array([0.30587256, 0.33257753, 0.36154988], dtype=float32), 80.05657, -0.58367157, 0.3580882, 0.3580882] [None, array([98., 95., 87.], dtype=float32), array(1., dtype=float32), array([0.27762243, 0.32822776, 0.39414987], dtype=float32), 80.05657, 12.6231, 0.99999666, 3.33786e-06] [None, array([99., 99., 99.], dtype=float32), array(1., dtype=float32), array([0.27762258, 0.32822785, 0.39414948], dtype=float32), 80.05657, 18.94342, 1.0, 0.0] [None, array([80., 85., 90.], dtype=float32), array(0., dtype=float32), array([0.27762258, 0.32822785, 0.39414948], dtype=float32), 80.05717, 5.5260544, 0.9960341, 0.9960341]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号